En mis publicaciones de este año, he estado discutiendo las reacciones instintivas a varios tipos de espera, y en esta publicación continuaré con el tema de las estadísticas de espera y discutiré el PAGEIOLATCH_XX Espere. Digo "espera", pero en realidad hay varios tipos de PAGEIOLATCH espera, que he indicado con el XX al final. Los ejemplos más comunes son:
PAGEIOLATCH_SH– (SH están) esperando que una página de archivo de datos se traiga del disco al grupo de búfer para que se pueda leer su contenidoPAGEIOLATCH_EXoPAGEIOLATCH_UP– (EX exclusivo o UP fecha) esperando que una página de archivo de datos se traiga del disco al grupo de búfer para que su contenido pueda modificarse
De estos, el tipo más común con diferencia es PAGEIOLATCH_SH .
Cuando este tipo de espera es el más frecuente en un servidor, la reacción instintiva es que el subsistema de E/S debe tener un problema y ahí es donde deben centrarse las investigaciones.
Lo primero que debe hacer es comparar el PAGEIOLATCH_SH conteo de espera y duración contra su línea de base. Si el volumen de esperas es más o menos el mismo, pero la duración de cada espera de lectura se ha vuelto mucho más larga, entonces me preocuparía un problema del subsistema de E/S, como:
- Una mala configuración/mal funcionamiento en el nivel del subsistema de E/S
- Latencia de red
- Otra carga de trabajo de E/S que causa contención con nuestra carga de trabajo
- Configuración de replicación/duplicación de subsistemas de E/S sincrónicos
En mi experiencia, el patrón suele ser que el número de PAGEIOLATCH_SH esperas ha aumentado sustancialmente desde la cantidad de referencia (normal) y la duración de la espera también ha aumentado (es decir, el tiempo para una E/S de lectura ha aumentado), porque la gran cantidad de lecturas sobrecarga el subsistema de E/S. No se trata de un problema del subsistema de E/S:se trata de SQL Server que genera más E/S de las que debería. El enfoque ahora debe cambiar a SQL Server para identificar la causa de las operaciones de E/S adicionales.
Causas de un gran número de E/S de lectura
SQL Server tiene dos tipos de lecturas:E/S lógicas y E/S físicas. Cuando la parte de métodos de acceso del motor de almacenamiento necesita acceder a una página, le pide al grupo de búfer un puntero a la página en la memoria (llamada E/S lógica) y el grupo de búfer verifica sus metadatos para ver si esa página es ya en la memoria.
Si la página está en la memoria, el grupo de búfer proporciona el puntero a los métodos de acceso y la E/S sigue siendo una E/S lógica. Si la página no está en la memoria, Buffer Pool emite una E/S "real" (llamada E/S física) y el subproceso tiene que esperar a que se complete, lo que genera un PAGEIOLATCH_XX Espere. Una vez que se completa la E/S y el puntero está disponible, se notifica el subproceso y puede continuar ejecutándose.
En un mundo ideal, toda su carga de trabajo cabría en la memoria y, por lo tanto, una vez que el grupo de búfer se haya "calentado" y contenga toda la carga de trabajo, no se requieren más lecturas, solo escrituras de datos actualizados. Sin embargo, no es un mundo ideal, y la mayoría de ustedes no tienen ese lujo, por lo que algunas lecturas son inevitables. Siempre que la cantidad de lecturas se mantenga alrededor de la cantidad de referencia, no hay problema.
Cuando se requiere una gran cantidad de lecturas repentina e inesperadamente, eso es una señal de que hay un cambio significativo en la carga de trabajo, la cantidad de memoria del grupo de búfer disponible para almacenar copias de páginas en memoria, o ambos.
Estas son algunas posibles causas principales (no es una lista exhaustiva):
- La presión de la memoria externa de Windows en SQL Server hace que el administrador de memoria reduzca el tamaño del grupo de búfer
- Planifique el exceso de memoria caché que hace que se tome prestada memoria adicional del grupo de búfer
- Un plan de consulta que realiza un análisis de tabla/índice agrupado (en lugar de una búsqueda de índice) debido a:
- un aumento del volumen de la carga de trabajo
- un problema de detección de parámetros
- un índice no agrupado obligatorio que se eliminó o cambió
- una conversión implícita
Un patrón a buscar que sugeriría un análisis de tabla/índice agrupado como causa también es ver una gran cantidad de CXPACKET espera junto con el PAGEIOLATCH_SH murga. Este es un patrón común que indica que se están realizando escaneos grandes de tablas paralelas/índices agrupados.
En todos los casos, puede ver qué plan de consulta está causando el PAGEIOLATCH_SH espera usando sys.dm_os_waiting_tasks y otros DMV, y puede obtener el código para hacerlo en mi publicación de blog aquí. Si tiene disponible una herramienta de monitoreo de terceros, es posible que pueda ayudarlo a identificar al culpable sin ensuciarse las manos.
Ejemplo de flujo de trabajo con SQL Sentry y Plan Explorer
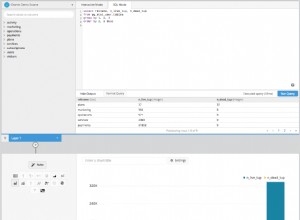
En un ejemplo simple (obviamente inventado), supongamos que estoy en un sistema cliente que usa el conjunto de herramientas de SQL Sentry y veo un pico en las esperas de E/S en la vista del tablero de SQL Sentry, como se muestra a continuación:
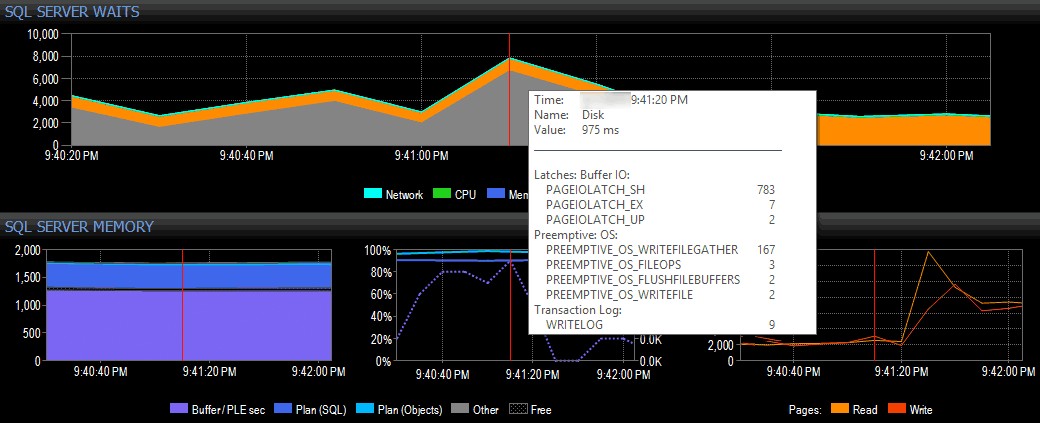
Detectar un pico en las esperas de E/S en SQL Sentry
Decido investigar haciendo clic con el botón derecho en un intervalo de tiempo seleccionado alrededor del momento del pico, luego saltando a la vista Top SQL, que me mostrará las consultas más costosas que se han ejecutado:
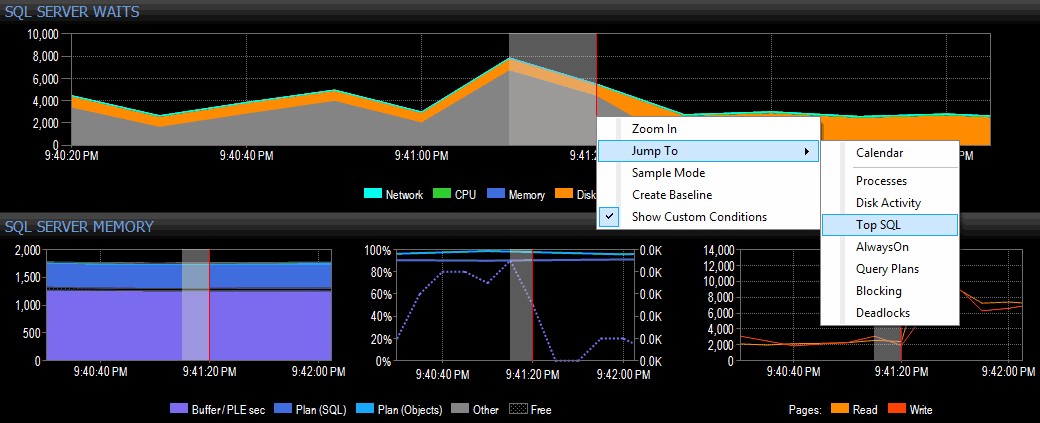
Resaltar un rango de tiempo y navegar a Top SQL
En esta vista, puedo ver qué consultas de E/S de larga duración o altas se estaban ejecutando en el momento en que se produjo el pico y, a continuación, elegir profundizar en sus planes de consulta (en este caso, solo hay una consulta de larga ejecución, que duró casi un minuto):
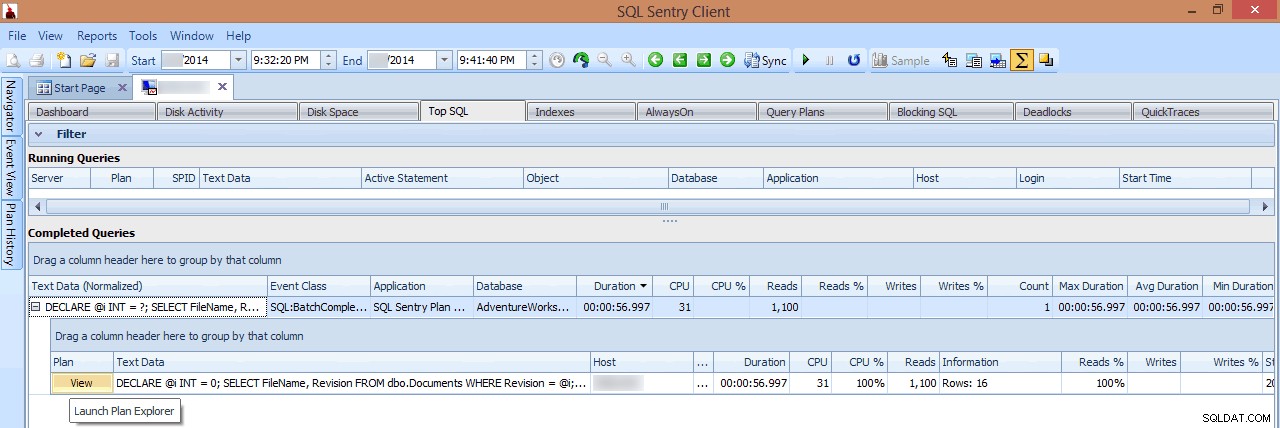
Revisar una consulta de ejecución prolongada en Top SQL
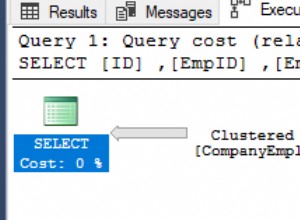
Si observo el plan en el cliente SQL Sentry o lo abro en SQL Sentry Plan Explorer, inmediatamente veo varios problemas. La cantidad de lecturas requeridas para devolver 7 filas parece demasiado alta, el delta entre las filas estimadas y las reales es grande, y el plan muestra un escaneo de índice que se produce donde hubiera esperado una búsqueda:
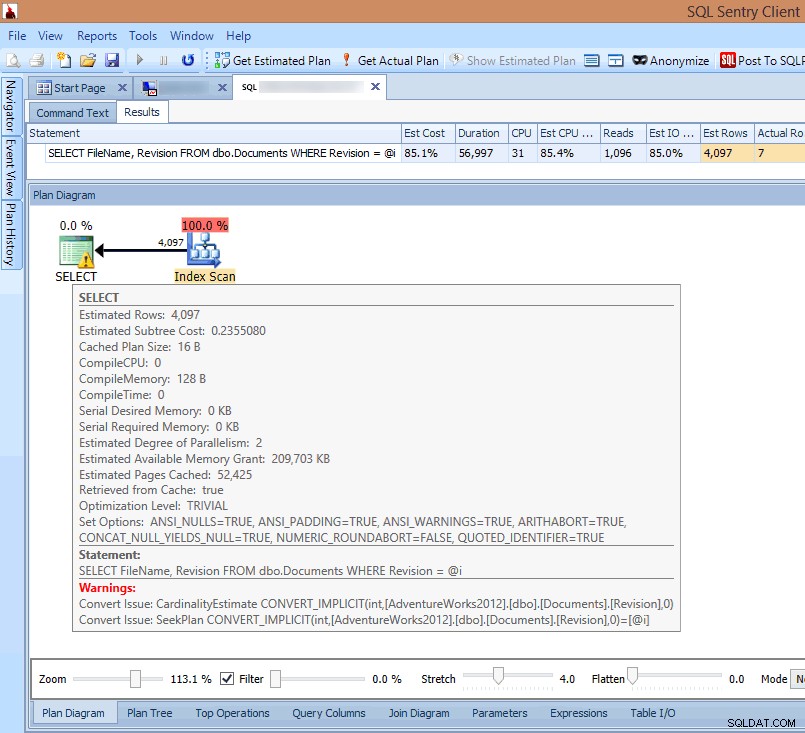
Ver advertencias de conversión implícitas en el plan de consulta
La causa de todo esto se destaca en la advertencia en el SELECT operador:¡Es una conversión implícita!
Las conversiones implícitas son un problema insidioso causado por una discrepancia entre el tipo de datos del predicado de búsqueda y el tipo de datos de la columna que se busca, o un cálculo que se realiza en la columna de la tabla en lugar del predicado de búsqueda. En cualquier caso, SQL Server no puede usar una búsqueda de índice en la columna de la tabla y debe usar un escaneo en su lugar.
Esto puede surgir en código aparentemente inocente, y un ejemplo común es usar un cálculo de fecha. Si tiene una tabla que almacena la edad de los clientes y desea realizar un cálculo para ver cuántos tienen 21 años o más hoy, puede escribir un código como este:
WHERE DATEADD (YEAR, 21, [MyTable].[BirthDate]) <= @today;
Con este código, el cálculo está en la columna de la tabla y, por lo tanto, no se puede usar una búsqueda de índice, lo que da como resultado una expresión no buscable (técnicamente conocida como expresión no SARGable) y una exploración de tabla/índice agrupado. Esto se puede resolver moviendo el cálculo al otro lado del operador:
WHERE [MyTable].[BirthDate] <= DATEADD (YEAR, -21, @today);
En cuanto a cuándo una comparación básica de columnas requiere una conversión de tipo de datos que puede causar una conversión implícita, mi colega Jonathan Kehayias escribió una excelente publicación de blog que compara cada combinación de tipos de datos y señala cuándo se requerirá una conversión implícita.
Resumen
No caigas en la trampa de pensar que un PAGEIOLATCH_XX excesivo las esperas son causadas por el subsistema de E/S. En mi experiencia, generalmente son causados por algo relacionado con SQL Server y ahí es donde comenzaría a solucionar problemas.
En lo que respecta a las estadísticas generales de espera, puede encontrar más información sobre cómo usarlas para solucionar problemas de rendimiento en:
- La serie de publicaciones de mi blog SQLskills, que comienza con las estadísticas de espera o, por favor, dígame dónde le duele
- Mi biblioteca de tipos de espera y clases de bloqueo aquí
- Curso de capacitación en línea My Pluralsight SQL Server:solución de problemas de rendimiento mediante estadísticas de espera
- Centinela SQL
En el próximo artículo de la serie, hablaré sobre otro tipo de espera que es una causa común de reacciones instintivas. Hasta entonces, ¡feliz resolución de problemas!