La estrategia de indexación de tablas es una de las claves de optimización y ajuste de rendimiento más importantes. En SQL Server, los índices (tanto los índices agrupados como los no agrupados) se crean utilizando una estructura de árbol B, en la que cada página actúa como un nodo de lista doblemente vinculado, con información sobre las páginas anterior y siguiente. Esta estructura de árbol B, denominada Exploración directa, facilita la lectura de las filas del índice mediante la exploración o la búsqueda de sus páginas desde el principio hasta el final. Aunque el escaneo directo es el método de escaneo de índice predeterminado y muy conocido, SQL Server nos brinda la capacidad de escanear las filas de índice dentro de la estructura de árbol B desde el final hasta el principio. Esta habilidad se llama Exploración hacia atrás. En este artículo, veremos cómo sucede esto y cuáles son los pros y los contras del método de escaneo hacia atrás.
SQL Server nos brinda la capacidad de leer datos del índice de la tabla al escanear los nodos de la estructura del árbol B del índice desde el principio hasta el final usando el método Forward Scan, o leyendo los nodos de la estructura del árbol B desde el final hasta el principio usando el Método de escaneo hacia atrás. Como su nombre lo indica, el escaneo hacia atrás se realiza mientras se lee en sentido opuesto al orden de la columna incluida en el índice, que se realiza con la opción DESC en la declaración de ordenación ORDER BY T-SQL, que especifica la dirección de la operación de escaneo.
En situaciones específicas, SQL Server Engine encuentra que la lectura de los datos del índice desde el final hasta el principio con el método de escaneo hacia atrás es más rápido que leerlos en su orden normal con el método de escaneo hacia adelante, lo que puede requerir un costoso proceso de clasificación por parte de SQL. Motor. Tales casos incluyen el uso de la función agregada MAX() y situaciones en las que la clasificación del resultado de la consulta es opuesta al orden del índice. El principal inconveniente del método de exploración hacia atrás es que SQL Server Query Optimizer siempre optará por ejecutarlo mediante la ejecución del plan en serie, sin poder aprovechar los beneficios de los planes de ejecución en paralelo.
Supongamos que tenemos la siguiente tabla que contendrá información sobre los empleados de la empresa. La tabla se puede crear utilizando la declaración CREATE TABLE T-SQL a continuación:
CREATE TABLE [dbo].[CompanyEmployees](
[ID] [INT] IDENTITY (1,1) ,
[EmpID] [int] NOT NULL,
[Emp_First_Name] [nvarchar](50) NULL,
[Emp_Last_Name] [nvarchar](50) NULL,
[EmpDepID] [int] NOT NULL,
[Emp_Status] [int] NOT NULL,
[EMP_PhoneNumber] [nvarchar](50) NULL,
[Emp_Adress] [nvarchar](max) NULL,
[Emp_EmploymentDate] [DATETIME] NULL,
PRIMARY KEY CLUSTERED
(
[ID] ASC
)ON [PRIMARY]))
Después de crear la tabla, la llenaremos con 10 000 registros ficticios, usando la declaración INSERT a continuación:
INSERT INTO [dbo].[CompanyEmployees]
([EmpID]
,[Emp_First_Name]
,[Emp_Last_Name]
,[EmpDepID]
,[Emp_Status]
,[EMP_PhoneNumber]
,[Emp_Adress]
,[Emp_EmploymentDate])
VALUES
(1,'AAA','BBB',4,1,9624488779,'AMM','2006-10-15')
GO 10000 Si ejecutamos la instrucción SELECT a continuación para recuperar datos de la tabla creada anteriormente, las filas se ordenarán de acuerdo con los valores de la columna ID en orden ascendente, es decir, el mismo orden del índice agrupado:
SELECT [ID]
,[EmpID]
,[Emp_First_Name]
,[Emp_Last_Name]
,[EmpDepID]
,[Emp_Status]
,[EMP_PhoneNumber]
,[Emp_Adress]
,[Emp_EmploymentDate]
FROM [SQLShackDemo].[dbo].[CompanyEmployees]
ORDER BY [ID] ASC
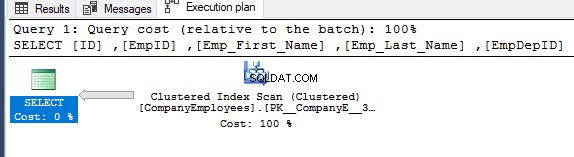
Luego, al verificar el plan de ejecución para esa consulta, se realizará un escaneo en el índice agrupado para obtener los datos ordenados del índice como se muestra en el plan de ejecución a continuación:
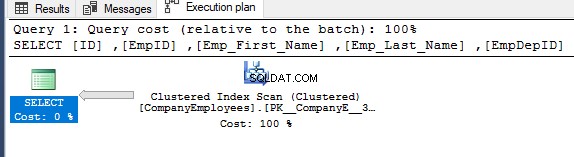
Para obtener la dirección del análisis que se realiza en el índice agrupado, haga clic con el botón derecho en el nodo de análisis del índice para examinar las propiedades del nodo. Desde las propiedades del nodo Exploración de índice agrupado, la propiedad Dirección de exploración mostrará la dirección de la exploración que se realiza en el índice dentro de esa consulta, que es Exploración directa, como se muestra en la siguiente instantánea:

La dirección de escaneo del índice también se puede recuperar del plan de ejecución XML desde la propiedad ScanDirection en el nodo IndexScan, como se muestra a continuación:
Supongamos que necesitamos recuperar el valor de ID máximo de la tabla CompanyEmployees creada anteriormente, utilizando la consulta T-SQL a continuación:
SELECT MAX([ID]) FROM [dbo].[CompanyEmployees]
Luego revise el plan de ejecución que se genera al ejecutar esa consulta. Verá que se realizará un escaneo en el índice agrupado como se muestra en el plan de ejecución a continuación:
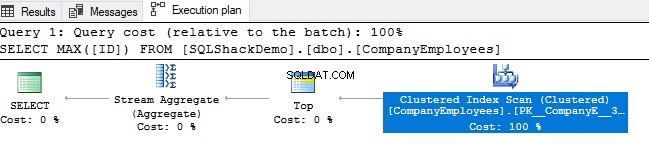
Para verificar la dirección del escaneo de índice, examinaremos las propiedades del nodo de escaneo de índice agrupado. El resultado nos mostrará que SQL Server Engine prefiere escanear el índice agrupado desde el final hasta el principio, lo que será más rápido en este caso, para obtener el valor máximo de la columna ID, debido al hecho de que el El índice ya está ordenado según la columna ID, como se muestra a continuación:
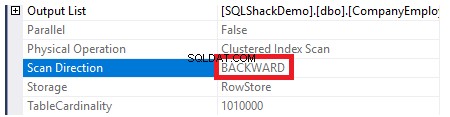
Además, si tratamos de recuperar los datos de la tabla creada previamente usando la siguiente declaración SELECT, los registros se ordenarán de acuerdo con los valores de la columna ID, pero esta vez, de manera opuesta al orden del índice agrupado, especificando la opción de clasificación DESC en ORDER Cláusula BY que se muestra a continuación:
SELECT [ID]
,[EmpID]
,[Emp_First_Name]
,[Emp_Last_Name]
,[EmpDepID]
,[Emp_Status]
,[EMP_PhoneNumber]
,[Emp_Adress]
,[Emp_EmploymentDate]
FROM [SQLShackDemo].[dbo].[CompanyEmployees]
ORDER BY [ID] DESC
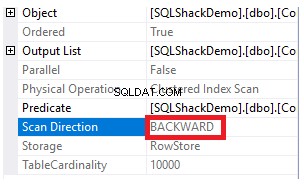
Si verifica el plan de ejecución generado después de ejecutar la consulta SELECT anterior, verá que se realizará un escaneo en el índice agrupado para obtener los registros solicitados de la tabla, como se muestra a continuación:
Las propiedades del nodo Análisis de índice agrupado mostrarán que la dirección del análisis que SQL Server Engine prefiere tomar es la dirección de Análisis hacia atrás, que es más rápida en este caso, debido a que la clasificación de los datos es opuesta a la clasificación real del índice agrupado, teniendo en cuenta que el índice ya está ordenado en orden ascendente según la columna ID, como se muestra a continuación:
Comparación de rendimiento
Suponga que tenemos las declaraciones SELECT a continuación que recuperan información sobre todos los empleados que han sido contratados a partir de 2010, dos veces; la primera vez, el conjunto de resultados devuelto se ordenará en orden ascendente de acuerdo con los valores de la columna de ID, y la segunda vez, el conjunto de resultados devuelto se ordenará en orden descendente de acuerdo con los valores de la columna de ID usando las instrucciones T-SQL a continuación:
SELECT [ID]
,[EmpID]
,[Emp_First_Name]
,[Emp_Last_Name]
,[EmpDepID]
,[Emp_Status]
,[EMP_PhoneNumber]
,[Emp_Adress]
,[Emp_EmploymentDate]
FROM [SQLShackDemo].[dbo].[CompanyEmployees]
WHERE Emp_EmploymentDate >='2010-01-01'
ORDER BY [ID] ASC
OPTION (MAXDOP 1)
GO
SELECT [ID]
,[EmpID]
,[Emp_First_Name]
,[Emp_Last_Name]
,[EmpDepID]
,[Emp_Status]
,[EMP_PhoneNumber]
,[Emp_Adress]
,[Emp_EmploymentDate]
FROM [SQLShackDemo].[dbo].[CompanyEmployees]
WHERE Emp_EmploymentDate >='2010-01-01'
ORDER BY [ID] DESC
OPTION (MAXDOP 1)
GO
Al verificar los planes de ejecución que se generan al ejecutar las dos consultas SELECT, el resultado mostrará que se realizará un escaneo en el índice agrupado en las dos consultas para recuperar los datos, pero la dirección del escaneo en la primera consulta será Adelante Escaneo debido a la clasificación de datos ASC y escaneo hacia atrás en la segunda consulta debido al uso de la clasificación de datos DESC, para reemplazar la necesidad de reordenar los datos nuevamente, como se muestra a continuación:
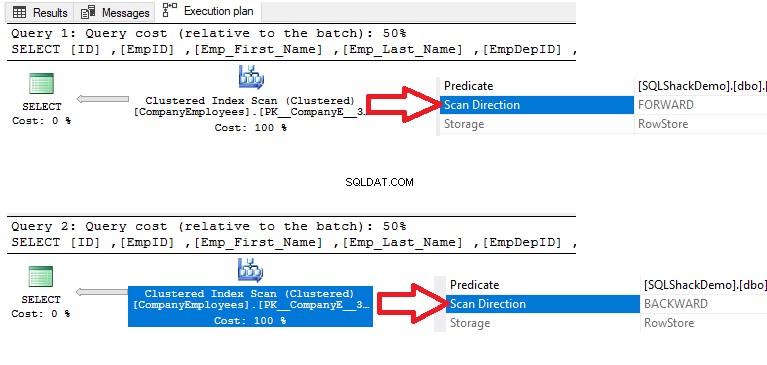
Además, si comprobamos las estadísticas de ejecución de E/S y TIEMPO de las dos consultas, veremos que ambas consultas realizan las mismas operaciones de E/S y consumen valores cercanos al tiempo de ejecución y de CPU.
Estos valores nos muestran qué tan inteligente es el motor de SQL Server al elegir la dirección de escaneo de índice más adecuada y rápida para recuperar datos para el usuario, que es escaneo hacia adelante en el primer caso y escaneo hacia atrás en el segundo caso, como se desprende de las estadísticas a continuación. :

Visitemos nuevamente el ejemplo anterior de MAX. Supongamos que necesitamos recuperar la ID máxima de los empleados que han sido contratados en 2010 y posteriores. Para esto, usaremos las siguientes instrucciones SELECT que clasificarán los datos leídos de acuerdo con el valor de la columna ID con la clasificación ASC en la primera consulta y con la clasificación DESC en la segunda consulta:
SELECT MAX([Emp_EmploymentDate]) FROM [SQLShackDemo].[dbo].[CompanyEmployees] WHERE [Emp_EmploymentDate] >='2017-01-01' GROUP BY ID ORDER BY [ID] ASC OPTION (MAXDOP 1) GO SELECT MAX([Emp_EmploymentDate]) FROM [SQLShackDemo].[dbo].[CompanyEmployees] WHERE [Emp_EmploymentDate] >='2017-01-01' GROUP BY ID ORDER BY [ID] DESC OPTION (MAXDOP 1) GO
Verá a partir de los planes de ejecución generados a partir de la ejecución de las dos declaraciones SELECT, que ambas consultas realizarán una operación de escaneo en el índice agrupado para recuperar el valor de ID máximo, pero en diferentes direcciones de escaneo; Forward Scan en la primera consulta y Backward Scan en la segunda consulta, debido a las opciones de clasificación ASC y DESC, como se muestra a continuación:
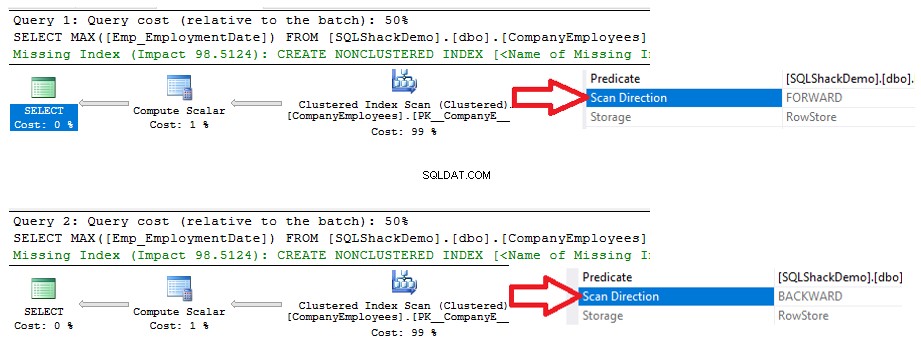
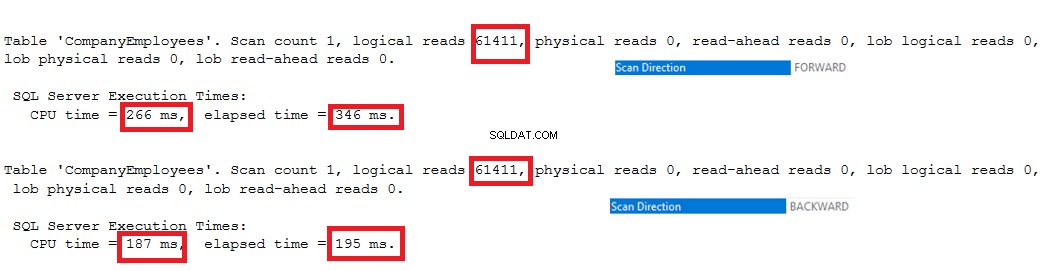
Las estadísticas de IO generadas por las dos consultas no mostrarán ninguna diferencia entre las dos direcciones de exploración. Pero las estadísticas de TIEMPO muestran una gran diferencia entre calcular el ID máximo de las filas cuando estas filas se escanean desde el principio hasta el final usando el método de escaneo hacia adelante y escanearlo desde el final hasta el principio usando el método de escaneo hacia atrás. Está claro a partir del siguiente resultado que el método de escaneo hacia atrás es el método de escaneo óptimo para obtener el valor de ID máximo:
Optimización del rendimiento
Como mencioné al comienzo de este artículo, la indexación de consultas es la clave más importante en el proceso de ajuste y optimización del rendimiento. En la consulta anterior, si hacemos arreglos para agregar un índice no agrupado en la columna Fecha de empleo de la tabla Empleados de la empresa, usando la instrucción CREATE INDEX T-SQL a continuación:
CREATE NONCLUSTERED INDEX IX_CompanyEmployees_Emp_EmploymentDate ON CompanyEmployees (Emp_EmploymentDate) After that, we will execute the same previous queries as shown below: SELECT MAX([Emp_EmploymentDate]) FROM [SQLShackDemo].[dbo].[CompanyEmployees] WHERE [Emp_EmploymentDate] >='2017-01-01' GROUP BY ID ORDER BY [ID] ASC OPTION (MAXDOP 1) GO SELECT MAX([Emp_EmploymentDate]) FROM [SQLShackDemo].[dbo].[CompanyEmployees] WHERE [Emp_EmploymentDate] >='2017-01-01' GROUP BY ID ORDER BY [ID] DESC OPTION (MAXDOP 1) GO
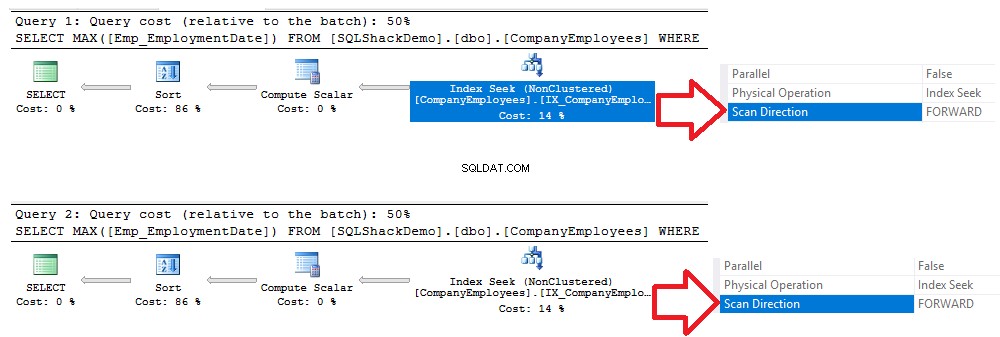
Al verificar los planes de ejecución generados después de la ejecución de las dos consultas, verá que se realizará una búsqueda en el índice no agrupado recién creado, y ambas consultas escanearán el índice desde el principio hasta el final utilizando el método Forward Scan, sin la necesidad de realizar un escaneo hacia atrás para acelerar la recuperación de datos, aunque usamos la opción de clasificación DESC en la segunda consulta. Esto ocurrió debido a que se buscó el índice directamente sin necesidad de realizar un análisis completo del índice, como se muestra en la comparación de planes de ejecución a continuación:
El mismo resultado se puede derivar de las estadísticas IO y TIME generadas a partir de las dos consultas anteriores, donde las dos consultas consumirán la misma cantidad de tiempo de ejecución, CPU y operaciones IO, con una diferencia muy pequeña, como se muestra en la instantánea de estadísticas a continuación. :

Herramienta útil:
dbForge Index Manager:práctico complemento de SSMS para analizar el estado de los índices SQL y solucionar problemas con la fragmentación de índices.