RDBMS es una de las bases de datos más utilizadas hasta la fecha y, por lo tanto, habilidades de SQL son indispensables en la mayoría de los puestos de trabajo. En este artículo Preguntas de la entrevista de SQL, le presentaré las preguntas más frecuentes sobre SQL (lenguaje de consulta estructurado). Este artículo es la guía perfecta para que aprendas todos los conceptos relacionados con las bases de datos SQL, Oracle, MS SQL Server y MySQL. Nuestro artículo de las 65 preguntas principales de la entrevista de SQL es el recurso integral desde donde puedes impulsar tu preparación para la entrevista.
¿Quieres mejorar tus habilidades para salir adelante en tu carrera? Echa un vistazo a las tecnologías más populares .¡Empecemos!
Preguntas de la entrevista de SQL
- ¿Cuál es la diferencia entre SQL y MySQL?
- ¿Cuáles son los diferentes subconjuntos de SQL?
- ¿Qué quiere decir con DBMS? ¿Cuáles son sus diferentes tipos?
- ¿Qué quiere decir con tabla y campo en SQL?
- ¿Qué son las uniones en SQL?
- ¿Cuál es la diferencia entre los tipos de datos CHAR y VARCHAR2 en SQL?
- ¿Qué es la clave principal?
- ¿Qué son las Restricciones?
- ¿Cuál es la diferencia entre las sentencias DELETE y TRUNCATE?
- ¿Qué es una clave única?
P1. ¿Cuál es la diferencia entre SQL y MySQL?
| SQL | |
| SQL es un lenguaje estándar que significa lenguaje de consulta estructurado basado en el Idioma inglés | MySQL es un sistema de gestión de bases de datos. |
| SQL es el núcleo de la base de datos relacional que se utiliza para acceder y administrar la base de datos | MySQL es un RDMS (Sistema de gestión de bases de datos relacionales) como SQL Server, Informix etc. |
P2. ¿Cuáles son los diferentes subconjuntos de SQL?
- Lenguaje de definición de datos (DDL):le permite realizar varias operaciones en la base de datos, como CREAR, ALTERAR y ELIMINAR objetos.
- Lenguaje de manipulación de datos (DML):le permite acceder y manipular datos. Le ayuda a insertar, actualizar, eliminar y recuperar datos de la base de datos.
- Lenguaje de control de datos (DCL):le permite controlar el acceso a la base de datos. Ejemplo:otorgar, revocar permisos de acceso.
P3. ¿A qué te refieres con SGBD? ¿Cuáles son sus diferentes tipos?
 Un Sistema de gestión de bases de datos (SGBD ) es una aplicación de software que interactúa con el usuario, las aplicaciones y la propia base de datos para capturar y analizar datos. Una base de datos es una colección estructurada de datos.
Un Sistema de gestión de bases de datos (SGBD ) es una aplicación de software que interactúa con el usuario, las aplicaciones y la propia base de datos para capturar y analizar datos. Una base de datos es una colección estructurada de datos.
Un DBMS permite que un usuario interactúe con la base de datos. Los datos almacenados en la base de datos se pueden modificar, recuperar y eliminar y pueden ser de cualquier tipo, como cadenas, números, imágenes, etc.
Hay dos tipos de SGBD:
- Sistema de gestión de bases de datos relacionales :Los datos se almacenan en relaciones (tablas). Ejemplo:MySQL.
- Sistema de gestión de base de datos no relacional :No existe el concepto de relaciones, tuplas y atributos. Ejemplo:MongoDB
Pasemos a la siguiente pregunta en estas preguntas de la entrevista de SQL.
P4. ¿Qué es RDBMS? ¿En qué se diferencia de DBMS?
Un sistema de administración de bases de datos relacionales (RDBMS) es un conjunto de aplicaciones y características que permiten a los profesionales de TI y otros desarrollar, editar, administrar e interactuar con bases de datos relacionales. La mayoría de los sistemas comerciales de gestión de bases de datos relacionales utilizan el lenguaje de consulta estructurado (SQL) para acceder a la base de datos, que se almacena en forma de tablas.
El RDBMS es el sistema de base de datos más utilizado en empresas de todo el mundo. Ofrece un medio estable para almacenar y recuperar cantidades masivas de datos.
Las bases de datos, en general, contienen colecciones de datos a los que se puede acceder y utilizar en otras aplicaciones. El desarrollo, la administración y el uso de plataformas de bases de datos están respaldados por un sistema de administración de bases de datos.
Un sistema de gestión de base de datos relacional (RDBMS) es un tipo de sistema de gestión de base de datos (DBMS) que almacena datos en una estructura de tabla basada en filas que vincula componentes de datos relacionados. Un RDBMS contiene funciones que garantizan la seguridad, precisión, integridad y consistencia de los datos. Esto no es lo mismo que el almacenamiento de archivos utilizado por un sistema de administración de bases de datos.
Las siguientes son algunas distinciones adicionales entre los sistemas de administración de bases de datos y los sistemas de administración de bases de datos relacionales:
El número de usuarios que tienen permiso para utilizar el sistema
Un DBMS solo puede manejar un usuario a la vez, mientras que un RDBMS puede manejar numerosos usuarios.
Especificaciones de hardware y software
En comparación con un RDBMS, un DBMS requiere menos software y hardware.
Cantidad de información
Los RDBMS pueden manejar cualquier cantidad de datos, desde pequeños hasta enormes, mientras que los DBMS están limitados a pequeñas cantidades.
La estructura de la base de datos
Los datos se almacenan en un formato jerárquico en un DBMS, mientras que un RDBMS usa una tabla con encabezados que sirven como nombres de columna y filas que contienen los valores asociados.
Implementación del principio ACID
Los DBMS no utilizan el concepto de atomicidad, consistencia, aislamiento y durabilidad (ACID) para el almacenamiento de datos. Los RDBMS, por otro lado, usan el modelo ACID para organizar sus datos y asegurar la consistencia.
Bases de datos que se distribuyen
Un DBMS no brindará soporte completo para bases de datos distribuidas, mientras que un RDBMS sí lo hará.
Programas que se administran
Un DBMS se enfoca en mantener las bases de datos que están presentes dentro de la red informática y los discos duros del sistema, mientras que un RDBMS ayuda a administrar las relaciones entre sus tablas de datos incorporadas.
Se admite la normalización de bases de datos
Un RDBMS se puede normalizar, pero un DBMS no se puede normalizar.
P5. ¿Qué es una autounión?
Una autounión es un tipo de unión que se puede utilizar para conectar dos tablas. Como resultado, es una relación unaria. Cada fila de la tabla se adjunta a sí misma y a todas las demás filas de la misma tabla en una autocombinación. Como resultado, una autocombinación se usa principalmente para combinar y comparar filas de la misma tabla de base de datos.
P6. ¿Qué es la sentencia SELECT?
Un comando SELECT obtiene cero o más filas de una o más tablas o vistas de la base de datos. El comando de lenguaje de manipulación de datos (DML) más frecuente es SELECCIONAR en la mayoría de las aplicaciones. Las consultas SELECT definen un conjunto de resultados, pero no cómo calcularlo, porque SQL es un lenguaje de programación declarativo.
P7. ¿Cuáles son algunas de las cláusulas comunes que se usan con la consulta SELECT en SQL?
Las siguientes son algunas cláusulas SQL frecuentes que se usan junto con una consulta SELECT:
DONDE Cláusula:en SQL, la cláusula WHERE se utiliza para filtrar registros que se requieren según ciertos criterios.
ORDENAR POR Cláusula:La cláusula ORDER BY en SQL se utiliza para clasificar los datos en orden ascendente (ASC) o descendente (DESC) según los campos especificados (DESC).
AGRUPAR POR Cláusula:La cláusula GROUP BY en SQL se usa para agrupar entradas con datos idénticos y se puede usar con métodos de agregación para obtener resultados resumidos de la base de datos.
TENER La cláusula en SQL se usa para filtrar registros en combinación con la cláusula GROUP BY. Es diferente de WHERE, ya que la cláusula WHERE no puede filtrar registros agregados.
P8. ¿Qué son los comandos UNION, MINUS e INTERSECT?
El operador UNION se usa para combinar los resultados de dos tablas y al mismo tiempo eliminar las entradas duplicadas.
El operador MENOS se usa para devolver filas de la primera consulta pero no de la segunda consulta.
El operador INTERSECT se usa para combinar los resultados de ambas consultas en una sola fila.
Antes de ejecutar cualquiera de las declaraciones SQL anteriores, se deben cumplir ciertos requisitos:
Dentro de la cláusula, cada consulta SELECT debe tener la misma cantidad de columnas.
Los tipos de datos en las columnas también deben ser comparables.
En cada instrucción SELECT, las columnas deben estar en el mismo orden.
P9. ¿Qué es Cursor? ¿Cómo usar un Cursor?
Después de cualquier declaración de variable, DECLARE un cursor. Una instrucción SELECT siempre debe ir acompañada de la definición del cursor.
Para iniciar el conjunto de resultados, mueva el cursor sobre él. Antes de obtener filas del conjunto de resultados, se debe ejecutar la sentencia OPEN.
Para recuperar e ir a la siguiente fila en el conjunto de resultados, use el comando FETCH.
Para desactivar el cursor, utilice el comando CERRAR.
Finalmente, use el comando DEALLOCATE para eliminar la definición del cursor y liberar los recursos conectados con él.
P10. Enumere los diferentes tipos de relaciones en SQL.
Hay diferentes tipos de relaciones en la base de datos:
Uno a uno – Esta es una conexión entre dos tablas en la que cada registro en una tabla corresponde al máximo de un registro en la otra.
Uno a muchos y muchos a uno – Esta es la conexión más frecuente, en la que un registro de una tabla está vinculado a varios registros de otra.
Muchos a Muchos – Esto se usa cuando se define una relación que requiere varias instancias en cada lado.
Relaciones autorreferenciales – Cuando una tabla tiene que declarar una conexión consigo misma, este es el método a emplear.
P12. ¿Qué es OLTP?
OLTP, o procesamiento transaccional en línea, permite que grandes grupos de personas ejecuten cantidades masivas de transacciones de bases de datos en tiempo real, generalmente a través de Internet. Una transacción de base de datos ocurre cuando los datos en una base de datos se modifican, insertan, eliminan o consultan.
P13. ¿Cuáles son las diferencias entre OLTP y OLAP?
OLTP significa procesamiento de transacciones en línea, mientras que OLAP significa procesamiento analítico en línea. OLTP es un sistema de modificación de bases de datos en línea, mientras que OLAP es un sistema de respuesta a consultas de bases de datos en línea.
P14. ¿Cómo crear tablas vacías con la misma estructura que otra tabla?
Para crear tablas vacías:
Usando el operador INTO para obtener los registros de una tabla en una nueva tabla mientras establece una cláusula WHERE en falso para todas las entradas, es posible crear tablas vacías con la misma estructura. Como resultado, SQL crea una nueva tabla con una estructura duplicada para aceptar las entradas obtenidas, pero no se almacena nada en la nueva tabla ya que la cláusula WHERE está activa.
P15. ¿Qué es PostgreSQL?
En 1986, un equipo dirigido por el profesor de informática Michael Stonebraker creó PostgreSQL con el nombre de Postgres. Fue creado para ayudar a los desarrolladores en el desarrollo de aplicaciones de nivel empresarial al garantizar la integridad de los datos y la tolerancia a fallas en los sistemas. PostgreSQL es un sistema de administración de base de datos relacional de objetos, de código abierto, flexible, versátil y de nivel empresarial que admite cargas de trabajo variables y usuarios simultáneos. La comunidad internacional de desarrolladores lo ha respaldado constantemente. PostgreSQL ha logrado un gran atractivo entre los desarrolladores debido a sus características de tolerancia a fallas.
Es un sistema de administración de bases de datos muy confiable, con más de dos décadas de trabajo comunitario para agradecer sus altos niveles de resistencia, integridad y precisión. Muchas aplicaciones en línea, móviles, geoespaciales y de análisis utilizan PostgreSQL como su principal almacén de datos o almacenamiento de datos.
P16. ¿Qué son los comentarios de SQL?
Los comentarios de SQL se utilizan para aclarar partes de las instrucciones de SQL y para evitar que se ejecuten. Los comentarios son muy importantes en muchos lenguajes de programación. Los comentarios no son compatibles con una base de datos de Microsoft Access. Como resultado, la base de datos de Microsoft Access se usa en los ejemplos de Mozilla Firefox y Microsoft Edge.
Comentarios de una sola línea:comienza con dos guiones consecutivos (–).
Comentarios de varias líneas:comienza con /* y termina con */.
P17. ¿Cuál es el uso de la función NVL()?
Puede usar la función NVL para reemplazar los valores nulos con un valor predeterminado. La función devuelve el valor del segundo parámetro si el primer parámetro es nulo. Si el primer parámetro no es nulo, se deja solo.
Esta función se usa en Oracle, no en SQL y MySQL. En lugar de la función NVL(), MySQL tiene IFNULL() y SQL Server tiene la función ISNULL().
Pasemos a la siguiente pregunta en estas preguntas de la entrevista de SQL.
P18. ¿Explicar las funciones de manipulación de personajes? Explica sus diferentes tipos en SQL.
Cambie, extraiga y edite la cadena de caracteres mediante rutinas de manipulación de caracteres. La función realizará su acción en las cadenas de entrada y devolverá el resultado cuando se le proporcionen uno o más caracteres y palabras.
Las funciones de manipulación de caracteres en SQL son las siguientes:
A) CONCAT (unir dos o más valores):Esta función se utiliza para unir dos o más valores. La segunda cadena siempre se agrega al final de la primera cadena.
B) SUBSTR:esta función devuelve un segmento de una cadena desde un punto de inicio dado hasta un punto final dado.
C) LONGITUD:Esta función devuelve la longitud de la cadena en forma numérica, incluidos los espacios en blanco.
D) INSTR:esta función calcula la ubicación numérica precisa de un carácter o palabra en una cadena.
E) LPAD:para valores justificados a la derecha, devuelve el relleno del valor del carácter del lado izquierdo.
F) RPAD:para un valor justificado a la izquierda, devuelve el relleno del valor del carácter del lado derecho.
G) TRIM:esta función elimina todos los caracteres definidos desde el principio, el final o ambos extremos de una cadena. También redujo la cantidad de espacio desperdiciado.
H) REEMPLAZAR:Esta función reemplaza todas las instancias de una palabra o una sección de una cadena (subcadena) con el otro valor de cadena especificado.
P19. Escriba la consulta SQL para obtener el tercer salario máximo de un empleado de una tabla llamada empleados.
Mesa de empleados
| nombre_empleado | salario |
| A | 24000 |
| C | 34000 |
| D | 55000 |
| E | 75000 |
| F | 21000 |
| G | 40000 |
| H | 50000 |
SELECCIONAR * DESDE(
SELECT nombre_empleado, salario, DENSE_RANK()
OVER(ORDEN POR salario DESC)r FROM Empleado)
DONDE r=&n;
Para encontrar el tercer salario más alto conjunto n =3
P20. ¿Cuál es la diferencia entre las funciones RANK() y DENSE_RANK()?
La función RANK() en el conjunto de resultados define el rango de cada fila dentro de su partición ordenada. Si ambas filas tienen el mismo rango, el siguiente número en el ranking será el rango anterior más una cantidad de duplicados. Si tenemos tres registros en el rango 4, por ejemplo, el siguiente nivel indicado es el 7.
La función DENSE_RANK() asigna un rango distinto a cada fila dentro de una partición en función del valor de columna proporcionado, sin espacios. Siempre indica una clasificación en orden de precedencia. Esta función asignará el mismo rango a las dos filas si tienen el mismo rango, siendo el siguiente rango el siguiente número consecutivo. Si tenemos tres registros en el rango 4, por ejemplo, el siguiente nivel indicado es 5.
Una tabla es una colección de componentes de datos organizados en filas y columnas en una base de datos relacional. Una tabla también se puede considerar como una representación útil de las relaciones. La forma más básica de almacenamiento de datos es la tabla. A continuación se muestra un ejemplo de una tabla de empleados.
| ID | Nombre | Departamento | Salario |
| 1 | Raúl | Ventas | 24000 |
| 2 | Rohiní | Mercadotecnia | 34000 |
| 3 | Shylesh | Ventas | 24000 |
| 4 | Tarun | Análisis | 30000 |
Un Registro o Fila es una sola entrada en una tabla. En una tabla, un registro representa una colección de datos conectados. La tabla Empleado, por ejemplo, tiene cuatro registros.
Una tabla se compone de numerosos registros (filas), cada uno de los cuales se puede dividir en unidades más pequeñas llamadas Campos (columnas). Id., Nombre, Departamento y Salario son los cuatro campos de la tabla Empleado anterior.
P22. ¿Qué es una restricción ÚNICA?
La Restricción ÚNICA evita que valores idénticos en una columna aparezcan en dos registros. La restricción ÚNICA garantiza que cada valor en una columna sea único.
P23. ¿Qué es una autounión?
Una autounión es un tipo de unión que se puede utilizar para conectar dos tablas. Como resultado, es una relación unaria. Cada fila de la tabla se adjunta a sí misma y a todas las demás filas de la misma tabla en una autocombinación. Como resultado, una autocombinación se usa principalmente para combinar y comparar filas de la misma tabla de base de datos.
P24. ¿Qué es la sentencia SELECT?
Un comando SELECT obtiene cero o más filas de una o más tablas o vistas de la base de datos. El comando de lenguaje de manipulación de datos (DML) más frecuente es SELECCIONAR en la mayoría de las aplicaciones. Las consultas SELECT definen un conjunto de resultados, pero no cómo calcularlo, porque SQL es un lenguaje de programación declarativo.
P25. ¿Cuáles son algunas de las cláusulas comunes que se usan con la consulta SELECT en SQL?
Las siguientes son algunas cláusulas SQL frecuentes que se usan junto con una consulta SELECT:
Cláusula WHERE:en SQL, la cláusula WHERE se usa para filtrar registros que se requieren según ciertos criterios.
Cláusula ORDER BY:La cláusula ORDER BY en SQL se usa para ordenar datos en orden ascendente (ASC) o descendente (DESC) dependiendo de los campos especificados (DESC).
Cláusula GROUP BY:la cláusula GROUP BY en SQL se usa para agrupar entradas con datos idénticos y se puede usar con métodos de agregación para obtener resultados resumidos de la base de datos.
La cláusula HAVING en SQL se usa para filtrar registros en combinación con la cláusula GROUP BY. Es diferente de WHERE, ya que la cláusula WHERE no puede filtrar registros agregados.
P26. ¿Qué son los comandos UNION, MINUS e INTERSECT?
El operador UNION se usa para combinar los resultados de dos tablas y al mismo tiempo eliminar las entradas duplicadas.
El operador MENOS se usa para devolver filas de la primera consulta pero no de la segunda consulta.
El operador INTERSECT se usa para combinar los resultados de ambas consultas en una sola fila.
Antes de ejecutar cualquiera de las declaraciones SQL anteriores, se deben cumplir ciertos requisitos –
Dentro de la cláusula, cada consulta SELECT debe tener la misma cantidad de columnas.
Los tipos de datos en las columnas también deben ser comparables.
En cada instrucción SELECT, las columnas deben estar en el mismo orden.
Pasemos a la siguiente pregunta en estas preguntas de la entrevista de SQL.
P27. ¿Qué es Cursor? ¿Cómo usar un Cursor?
Después de cualquier declaración de variable, DECLARE un cursor. Una instrucción SELECT siempre debe ir acompañada de la definición del cursor.
Para iniciar el conjunto de resultados, mueva el cursor sobre él. Antes de obtener filas del conjunto de resultados, se debe ejecutar la sentencia OPEN.
Para recuperar e ir a la siguiente fila en el conjunto de resultados, use el comando FETCH.
Para desactivar el cursor, utilice el comando CERRAR.
Finalmente, use el comando DEALLOCATE para eliminar la definición del cursor y liberar los recursos conectados con él.
P28. Enumere los diferentes tipos de relaciones en SQL.
Hay diferentes tipos de relaciones en la base de datos:
Uno a uno:esta es una conexión entre dos tablas en la que cada registro en una tabla corresponde al máximo de un registro en la otra.
Uno a muchos y muchos a uno:esta es la conexión más frecuente, en la que un registro en una tabla está vinculado a varios registros en otra.
Muchos a muchos:esto se usa cuando se define una relación que requiere varias instancias en cada lado.
Relaciones autorreferenciales:cuando una tabla tiene que declarar una conexión consigo misma, este es el método a emplear.
P29. ¿Qué es un ejemplo de SQL?
SQL es un lenguaje de consulta de base de datos que le permite editar, eliminar y solicitar datos de bases de datos. Las siguientes sentencias son algunos ejemplos de sentencias SQL:
- SELECCIONAR
- INSERTAR
- ACTUALIZAR
- ELIMINAR
- CREAR BASE DE DATOS
- ALTERAR BASE DE DATOS
P30. ¿Cuáles son las habilidades básicas de SQL?
Las habilidades de SQL ayudan a los analistas de datos en la creación, el mantenimiento y la recuperación de datos de bases de datos relacionales, que dividen los datos en columnas y filas. También permite a los usuarios recuperar, actualizar, manipular, insertar y modificar datos de manera eficiente.
Las habilidades más fundamentales que debe poseer un experto en SQL son:
- Administración de bases de datos
- Estructuración de una base de datos
- Creación de cláusulas y sentencias SQL
- Habilidades del sistema SQL como MYSQL, PostgreSQL
- La experiencia en PHP es útil.
- Analizar datos SQL
- Uso de WAMP con SQL para crear una base de datos
- Habilidades OLAP
P31. ¿Qué es el esquema en SQL Server?
Un esquema es una representación visual de la base de datos que es lógica. Construye y especifica las relaciones entre las numerosas entidades de la base de datos. Se refiere a los diversos tipos de restricciones que se pueden aplicar a una base de datos. También describe los distintos tipos de datos. También se puede usar en tablas y vistas.
Los esquemas vienen en una variedad de formas y tamaños. El esquema de estrella y el esquema de copo de nieve son dos de los más populares. Las entidades en un esquema de estrella se representan en forma de estrella, mientras que las de un esquema de copo de nieve se muestran en forma de copo de nieve.
Cualquier arquitectura de base de datos se construye sobre la base de esquemas.
P32. ¿Cómo crear una tabla temporal en SQL Server?
Las tablas temporales se crean en TempDB y se borran automáticamente después de que se cierra la última conexión. Podemos utilizar tablas temporales para almacenar y procesar resultados provisionales. Cuando necesitamos almacenar datos temporales, las tablas temporales son útiles.
La siguiente es la sintaxis para crear una tabla temporal:
CREAR TABLA #Empleado (id INT, nombre VARCHAR(25))
INSERTAR EN #VALORES DE EMPLEADOS (01, 'Ashish'), (02, 'Atul')
Pasemos a la siguiente pregunta en estas preguntas de la entrevista de SQL.
P33. ¿Cómo instalar SQL Server en Windows 11?
Instale SQL Server Management Studio en Windows 11
Paso 3: Guarde este archivo en su disco local y vaya a la carpeta.
Paso 6: Cierre la ventana después de que se complete la instalación.
Paso 7: Además, vuelva a su menú de inicio y busque SQL Server Management Studio.
Paso 8: Además, haga doble clic en él y la página de inicio de sesión aparecerá una vez que aparezca.
Paso 9: Debería poder ver el nombre de su servidor. Sin embargo, si eso no está visible, haga clic en la flecha desplegable en el servidor y toque Examinar.
Paso 10: Elija su servidor SQL y haga clic en Conectar.
Después de eso, el servidor SQL se conectará y Windows 11 funcionará bien.
P34. ¿Cuál es el caso cuando en SQL Server?
La declaración CASE se usa para construir una lógica en la que el valor de una columna está determinado por los valores de otras columnas.
Al menos un conjunto de comandos CUANDO y ENTONCES constituye la instrucción CASE de SQL Server. La condición que se va a probar se especifica mediante la instrucción WHEN. Si la condición CUANDO devuelve VERDADERO, la oración ENTONCES explica qué hacer.
Cuando ninguna de las condiciones WHEN devuelve verdadero, se ejecuta la instrucción ELSE. La palabra clave END cierra la instrucción CASE.
CASE WHEN condition1 THEN result1 WHEN condition2 THEN result2 WHEN conditionN THEN resultN ELSE result END;
P35. NoSQL frente a SQL
En resumen, las siguientes son las cinco distinciones principales entre SQL y NoSQL:
Las bases de datos relacionales son SQL, mientras que las bases de datos no relacionales son NoSQL.
Las bases de datos SQL tienen un esquema específico y emplean un lenguaje de consulta estructurado. Para datos no estructurados, las bases de datos NoSQL utilizan esquemas dinámicos.
Las bases de datos SQL escalan verticalmente, pero las bases de datos NoSQL escalan horizontalmente.
Las bases de datos NoSQL son almacenes de documentos, valores clave, gráficos o columnas anchas, mientras que las bases de datos SQL están basadas en tablas.
Las bases de datos SQL se destacan en transacciones de varias filas, mientras que NoSQL se destaca en datos no estructurados, como documentos y JSON.
P36. ¿Cuál es la diferencia entre NOW() y CURRENT_DATE()?
NOW() devuelve una hora constante que indica la hora a la que comenzó a ejecutarse la sentencia. (Dentro de una función o activador almacenado, NOW() devuelve el momento en que la función o la declaración de activación comenzó a ejecutarse.
La diferencia simple entre NOW() y CURRENT_DATE() es que NOW() obtendrá la fecha y la hora actuales en formato 'YYYY-MM_DD HH:MM:SS', mientras que CURRENT_DATE() obtendrá la fecha del día actual 'YYYY -MM_DD'.
Pasemos a la siguiente pregunta en estas preguntas de la entrevista de SQL.
P37. ¿Qué es BLOB y TEXT en MySQL?
BLOB significa Binary Huge Objects y se puede usar para almacenar datos binarios, mientras que TEXT se puede usar para almacenar una gran cantidad de cadenas. BLOB puede usarse para almacenar datos binarios, que incluyen imágenes, películas, audio y aplicaciones.
Los valores BLOB funcionan de manera similar a las cadenas de bytes y carecen de un juego de caracteres. Como resultado, los valores numéricos de los bytes dependen completamente de la comparación y clasificación.
Los valores de TEXTO se comportan de manera similar a una cadena de caracteres o una cadena no binaria. La comparación/clasificación de TEXTO depende completamente de la colección de juegos de caracteres.
P38. ¿Cómo eliminar filas duplicadas en SQL?
Si la tabla SQL tiene filas duplicadas, las filas duplicadas deben eliminarse.
Asumamos la siguiente tabla como nuestro conjunto de datos:
| ID | Nombre | Edad |
| 1 | A | 21 |
| 2 | B | 23 |
| 2 | B | 23 |
| 4 | D | 22 |
| 5 | E | 25 |
| 6 | G | 26 |
| 5 | E | 25 |
La siguiente consulta SQL elimina los ID duplicados de la tabla:
ELIMINAR DE la tabla DONDE ID EN (
SELECCIONE
ID, CONTAR(ID)
DESDE la mesa
AGRUPAR POR ID
TENER
CUENTA (ID)> 1);
P39. ¿Cómo crear un procedimiento almacenado usando SQL Server?
Un procedimiento almacenado es un fragmento de código SQL preparado que puede guardar y reutilizar una y otra vez.
Por lo tanto, si tiene una consulta SQL que crea con frecuencia, guárdela como un procedimiento almacenado y luego llámela para ejecutarla.
También puede proporcionar parámetros a un procedimiento almacenado para que pueda actuar en función de los valores de los parámetros proporcionados.
Sintaxis de procedimiento almacenado
CREAR PROCEDIMIENTO nombre_procedimiento
COMO
declaración_sql
IR;
Ejecutar un Procedimiento Almacenado
EXEC nombre_procedimiento;
P40. ¿Qué es la prueba de caja negra de la base de datos?
Black Box Testing es un enfoque de prueba de software que implica probar las funciones de las aplicaciones de software sin conocer la estructura del código interno, los detalles de implementación o las rutas internas. Black Box Testing es un tipo de prueba de software que se enfoca en la entrada y salida de las aplicaciones de software y está totalmente impulsada por los requisitos y especificaciones del software. Pruebas de comportamiento es otro nombre para esto.
P41. ¿Cuáles son los diferentes tipos de sandbox de SQL?
SQL Sandbox es un entorno seguro dentro de SQL Server donde se pueden ejecutar programas que no son de confianza. Hay tres tipos diferentes de entornos limitados de SQL:
Zona de pruebas de acceso seguro:en este entorno, un usuario puede ejecutar actividades de SQL, como crear procedimientos almacenados, disparadores, etc., pero no puede acceder a la memoria ni crear archivos.
Sandbox para acceso externo:los usuarios pueden acceder a los archivos sin tener la capacidad de modificar la asignación de memoria.
Sandbox de acceso inseguro:contiene código no confiable que permite a un usuario acceder a la memoria.
Pasemos a la siguiente pregunta en estas preguntas de la entrevista de SQL.
P42. ¿Dónde se almacena la tabla MyISAM?
Antes de la introducción de MySQL 5.5 en diciembre de 2009, MyISAM era el motor de almacenamiento predeterminado para las versiones del sistema de gestión de bases de datos relacionales MySQL. Se basa en el código ISAM anterior, pero viene con muchas funciones adicionales. Cada tabla MyISAM se divide en tres archivos en el disco (si no está particionado). Los nombres de archivo comienzan con el nombre de la tabla y terminan con una extensión que indica el tipo de archivo. La definición de la tabla se almacena en un archivo.frm; sin embargo, este archivo no forma parte del motor MyISAM; en cambio, es parte del servidor. El sufijo del archivo de datos es .MYD (MYData). La extensión del archivo de índice es .MYI (MYIndex). Si pierde su archivo de índice, siempre puede restaurarlo recreando índices.
P43. ¿Cómo encontrar el enésimo salario más alto en SQL?
La pregunta de entrevista más típica es encontrar el enésimo salario más alto en una tabla. Este trabajo se puede lograr usando la función densa rank().
Mesa de empleados
| nombre_empleado | salario |
| A | 24000 |
| C | 34000 |
| D | 55000 |
| E | 75000 |
| F | 21000 |
| G | 40000 |
| H | 50000 |
SELECCIONAR * DESDE(
SELECT nombre_empleado, salario, DENSE_RANK()
OVER(ORDEN POR salario DESC)r FROM Empleado)
DONDE r=&n;
Para encontrar el segundo conjunto de salarios más alto n =2
Para encontrar el tercer salario más alto, establezca n =3 y así sucesivamente.
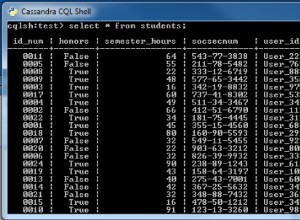
P44. ¿Qué quiere decir con tabla y campo en SQL?
Una tabla se refiere a una colección de datos de manera organizada en forma de filas y columnas. Un campo se refiere al número de columnas en una tabla. Por ejemplo:
Tabla :Información del estudiante
Campo :ID de estudiante, nombre de estudiante, marcas de estudiante
P45. ¿Qué son las uniones en SQL?
La cláusula JOIN se usa para combinar filas de dos o más tablas, en función de una columna relacionada entre ellas. Se utiliza para fusionar dos tablas o recuperar datos de allí. Hay 4 tipos de uniones, como puede consultar a continuación:
- Unión interna: La unión interna en SQL es el tipo de unión más común. Se utiliza para devolver todas las filas de varias tablas donde se cumple la condición de unión.
Unión izquierda: Left Join in SQL is used to return all the rows from the left table but only the matching rows from the right table where the join condition is fulfilled.
Right Join: Right Join in SQL is used to return all the rows from the right table but only the matching rows from the left table where the join condition is fulfilled.
Full Join: Full join returns all the records when there is a match in any of the tables. Therefore, it returns all the rows from the left-hand side table and all the rows from the right-hand side table.
Let’s move to the next question in this SQL Interview Questions.
Q46. What is the difference between CHAR and VARCHAR2 datatype in SQL?
Both Char and Varchar2 are used for characters datatype but varchar2 is used for character strings of variable length whereas Char is used for strings of fixed length. For example, char(10) can only store 10 characters and will not be able to store a string of any other length whereas varchar2(10) can store any length i.e 6,8,2 in this variable.
Q47. What is a Primary key?
- A Primary key in SQL is a column (or collection of columns) or a set of columns that uniquely identifies each row in the table.
- Uniquely identifies a single row in the table
- Null values not allowed
Example- In the Student table, Stu_ID is the primary key.
Q48. What are Constraints?
Constraints in SQL are used to specify the limit on the data type of the table. It can be specified while creating or altering the table statement. The sample of constraints are:
- NOT NULL
- CHECK
- DEFAULT
- UNIQUE
- PRIMARY KEY
- FOREIGN KEY
Q49. What is the difference between DELETE and TRUNCATE statements?
| DELETE | TRUNCATE |
| Delete command is used to delete a row in a table. | Truncate is used to delete all the rows from a table. |
| You can rollback data after using delete statement. | You cannot rollback data. |
| It is a DML command. | It is a DDL command. |
| It is slower than truncate statement. | It is faster. |
Q50. What is a Unique key?
- Uniquely identifies a single row in the table.
- Multiple values allowed per table.
- Null values allowed.
Apart from this SQL Interview Questions blog, if you want to get trained from professionals on this technology, you can opt for structured training from edureka!
Q51. What is a Foreign key in SQL?
- Foreign key maintains referential integrity by enforcing a link between the data in two tables.
- The foreign key in the child table references the primary key in the parent table.
- The foreign key constraint prevents actions that would destroy links between the child and parent tables.
Q52. What do you mean by data integrity?
Data Integrity defines the accuracy as well as the consistency of the data stored in a database. It also defines integrity constraints to enforce business rules on the data when it is entered into an application or a database.
Q53. What is the difference between clustered and non-clustered index in SQL?
The differences between the clustered and non clustered index in SQL are :
- Clustered index is used for easy retrieval of data from the database and its faster whereas reading from non clustered index is relatively slower.
- Clustered index alters the way records are stored in a database as it sorts out rows by the column which is set to be clustered index whereas in a non clustered index, it does not alter the way it was stored but it creates a separate object within a table which points back to the original table rows after searching.
One table can only have one clustered index whereas it can have many non clustered index.
Q54. Write a SQL query to display the current date?
In SQL, there is a built-in function called GetDate() which helps to return the current timestamp/date.
Q55. What do you understand by query optimization?
The phase that identifies a plan for evaluation query which has the least estimated cost is known as query optimization.
The advantages of query optimization are as follows:
- The output is provided faster
- A larger number of queries can be executed in less time
- Reduces time and space complexity
Q56. What do you mean by Denormalization?
Denormalization refers to a technique which is used to access data from higher to lower forms of a database. It helps the database managers to increase the performance of the entire infrastructure as it introduces redundancy into a table. It adds the redundant data into a table by incorporating database queries that combine data from various tables into a single table.
Q57. What are Entities and Relationships?
Entities :A person, place, or thing in the real world about which data can be stored in a database. Tables store data that represents one type of entity. For example – A bank database has a customer table to store customer information. The customer table stores this information as a set of attributes (columns within the table) for each customer.
Relationships :Relation or links between entities that have something to do with each other. For example – The customer name is related to the customer account number and contact information, which might be in the same table. There can also be relationships between separate tables (for example, customer to accounts).
Let’s move to the next question in this SQL Interview Questions.
Q58. What is an Index?
An index refers to a performance tuning method of allowing faster retrieval of records from the table. An index creates an entry for each value and hence it will be faster to retrieve data.
Q59 . Explain different types of index in SQL.
There are three types of index in SQL namely:
Unique Index:
This index does not allow the field to have duplicate values if the column is unique indexed. If a primary key is defined, a unique index can be applied automatically.
Clustered Index:
This index reorders the physical order of the table and searches based on the basis of key values. Each table can only have one clustered index.
Non-Clustered Index:
Non-Clustered Index does not alter the physical order of the table and maintains a logical order of the data. Each table can have many nonclustered indexes.
Q60. What is Normalization and what are the advantages of it?
Normalization in SQL is the process of organizing data to avoid duplication and redundancy. Some of the advantages are:
- Better Database organization
- More Tables with smaller rows
- Efficient data access
- Greater Flexibility for Queries
- Quickly find the information
- Easier to implement Security
- Allows easy modification
- Reduction of redundant and duplicate data
- More Compact Database
- Ensure Consistent data after modification
Apart from this SQL Interview Questions Blog, if you want to get trained from professionals on this technology, you can opt for structured training from edureka!
Q61. What is the difference between DROP and TRUNCATE commands?
DROP command removes a table and it cannot be rolled back from the database whereas TRUNCATE command removes all the rows from the table.
Q62. Explain different types of Normalization.
There are many successive levels of normalization. Estas se llaman formas normales . Each consecutive normal form depends on the previous one.The first three normal forms are usually adequate.
Normal Forms are used in database tables to remove or decrease duplication. The following are the many forms:
First Normal Form:
When every attribute in a relation is a single-valued attribute, it is said to be in first normal form. The first normal form is broken when a relation has a composite or multi-valued property.
Second Normal Form:
A relation is in second normal form if it meets the first normal form’s requirements and does not contain any partial dependencies. In 2NF, a relation has no partial dependence, which means it has no non-prime attribute that is dependent on any suitable subset of any table candidate key. Often, the problem may be solved by setting a single column Primary Key.
Third Normal Form:
If a relation meets the requirements for the second normal form and there is no transitive dependency, it is said to be in the third normal form.
Q63. What is OLTP?
OLTP, or online transactional processing, allows huge groups of people to execute massive amounts of database transactions in real time, usually via the internet. A database transaction occurs when data in a database is changed, inserted, deleted, or queried.
What are the differences between OLTP and OLAP?
OLTP stands for online transaction processing, whereas OLAP stands for online analytical processing. OLTP is an online database modification system, whereas OLAP is an online database query response system.
Q64. How to create empty tables with the same structure as another table?
To create empty tables:
Using the INTO operator to fetch the records of one table into a new table while setting a WHERE clause to false for all entries, it is possible to create empty tables with the same structure. As a result, SQL creates a new table with a duplicate structure to accept the fetched entries, but nothing is stored into the new table since the WHERE clause is active.
Q65. What is PostgreSQL?
In 1986, a team lead by Computer Science Professor Michael Stonebraker created PostgreSQL under the name Postgres. It was created to aid developers in the development of enterprise-level applications by ensuring data integrity and fault tolerance in systems. PostgreSQL is an enterprise-level, versatile, resilient, open-source, object-relational database management system that supports variable workloads and concurrent users. The international developer community has constantly backed it. PostgreSQL has achieved significant appeal among developers because to its fault-tolerant characteristics.
It’s a very reliable database management system, with more than two decades of community work to thank for its high levels of resiliency, integrity, and accuracy. Many online, mobile, geospatial, and analytics applications utilise PostgreSQL as their primary data storage or data warehouse.
Q66. What are SQL comments?
SQL Comments are used to clarify portions of SQL statements and to prevent SQL statements from being executed. Comments are quite important in many programming languages. The comments are not supported by a Microsoft Access database. As a result, the Microsoft Access database is used in the examples in Mozilla Firefox and Microsoft Edge.
Single Line Comments:It starts with two consecutive hyphens (–).
Multi-line Comments:It starts with /* and ends with */.
Let’s move to the next question in this SQL Interview Questions.
Q67. What is the difference between the RANK() and DENSE_RANK() functions?
The RANK() function in the result set defines the rank of each row within your ordered partition. If both rows have the same rank, the next number in the ranking will be the previous rank plus a number of duplicates. If we have three records at rank 4, for example, the next level indicated is 7.
The DENSE_RANK() function assigns a distinct rank to each row within a partition based on the provided column value, with no gaps. It always indicates a ranking in order of precedence. This function will assign the same rank to the two rows if they have the same rank, with the next rank being the next consecutive number. If we have three records at rank 4, for example, the next level indicated is 5.
Q68. What is SQL Injection?
SQL injection is a sort of flaw in website and web app code that allows attackers to take control of back-end processes and access, retrieve, and delete sensitive data stored in databases. In this approach, malicious SQL statements are entered into a database entry field, and the database becomes exposed to an attacker once they are executed. By utilising data-driven apps, this strategy is widely utilised to get access to sensitive data and execute administrative tasks on databases. SQLi attack is another name for it.
The following are some examples of SQL injection:
- Getting access to secret data in order to change a SQL query to acquire the desired results.
- UNION attacks are designed to steal data from several database tables.
- Examine the database to get information about the database’s version and structure
Q69. How many Aggregate functions are available in SQL?
SQL aggregate functions provide information about a database’s data. AVG, for example, returns the average of a database column’s values.
SQL provides seven (7) aggregate functions, which are given below:
AVG():returns the average value from specified columns.
COUNT():returns the number of table rows, including rows with null values.
MAX():returns the largest value among the group.
MIN():returns the smallest value among the group.
SUM():returns the total summed values(non-null) of the specified column.
FIRST():returns the first value of an expression.
LAST():returns the last value of an expression.
Q70. What is the default ordering of data using the ORDER BY clause? How could it be changed?
The ORDER BY clause in MySQL can be used without the ASC or DESC modifiers. The sort order is preset to ASC or ascending order when this attribute is absent from the ORDER BY clause.
Q71. How do we use the DISTINCT statement? What is its use?
The SQL DISTINCT keyword is combined with the SELECT query to remove all duplicate records and return only unique records. There may be times when a table has several duplicate records.
The DISTINCT clause in SQL is used to eliminate duplicates from a SELECT statement’s result set.
Q72. What are the syntax and use of the COALESCE function?
From a succession of expressions, the COALESCE function returns the first non-NULL value. The expressions are evaluated in the order that they are supplied, and the function’s result is the first non-null value. Only if all of the inputs are null does the COALESCE method return NULL.
The syntax of COALESCE function is COALESCE (exp1, exp2, …. expn)
Q73. What is the ACID property in a database?
ACID stands for Atomicity, Consistency, Isolation, Durability. It is used to ensure that the data transactions are processed reliably in a database system.
- Atomicity: Atomicity refers to the transactions that are completely done or failed where transaction refers to a single logical operation of a data. It means if one part of any transaction fails, the entire transaction fails and the database state is left unchanged.
- Consistency: Consistency ensures that the data must meet all the validation rules. In simple words, you can say that your transaction never leaves the database without completing its state.
- Isolation: The main goal of isolation is concurrency control.
- Durability: Durability means that if a transaction has been committed, it will occur whatever may come in between such as power loss, crash or any sort of error.
Top 10 Technologies to Learn in 2022 | Edureka
Q74. What do you mean by “Trigger” in SQL?
Trigger in SQL is are a special type of stored procedures that are defined to execute automatically in place or after data modifications. It allows you to execute a batch of code when an insert, update or any other query is executed against a specific table.
Q75. What are the different operators available in SQL?
There are three operators available in SQL, namely:
- Arithmetic Operators
- Logical Operators
- Comparison Operators
Apart from this SQL Interview Questions blog, if you want to get trained from professionals on this technology, you can opt for structured training from edureka!
Q76. Are NULL values same as that of zero or a blank space?
A NULL value is not at all same as that of zero or a blank space. NULL value represents a value which is unavailable, unknown, assigned or not applicable whereas a zero is a number and blank space is a character.
Q77. What is the difference between cross join and natural join?
The cross join produces the cross product or Cartesian product of two tables whereas the natural join is based on all the columns having the same name and data types in both the tables.
Q78. What is subquery in SQL?
Una subconsulta es una consulta dentro de otra consulta donde se define una consulta para recuperar datos o información de la base de datos. En una subconsulta, la consulta externa se llama consulta principal, mientras que la consulta interna se denomina subconsulta. Las subconsultas siempre se ejecutan primero y el resultado de la subconsulta se pasa a la consulta principal. Se puede anidar dentro de SELECCIONAR, ACTUALIZAR o cualquier otra consulta. Una subconsulta también puede usar cualquier operador de comparación como>, There are two types of subquery namely, Correlated and Non-Correlated. Correlated subquery :These are queries which select the data from a table referenced in the outer query. It is not considered as an independent query as it refers to another table and refers the column in a table. Non-Correlated subquery :This query is an independent query where the output of subquery is substituted in the main query.
Let’s move to the next question in this SQL Interview Questions. To count the number of records in a table in SQL, you can use the below commands: Apart from this SQL Interview Questions Blog, if you want to get trained from professionals on this technology, you can opt for structured training from edureka!
To display name of the employees that begin with ‘A’, type in the below command: Group functions work on the set of rows and return one result per group. Some of the commonly used group functions are:AVG, COUNT, MAX, MIN, SUM, VARIANCE. Relation or links are between entities that have something to do with each other. Relationships are defined as the connection between the tables in a database. There are various relationships, namely: NULL values in SQL can be inserted in the following ways: BETWEEN operator is used to display rows based on a range of values in a row whereas the IN condition operator is used to check for values contained in a specific set of values. SQL functions are used for the following purposes: This statement allows conditional update or insertion of data into a table. It performs an UPDATE if a row exists, or an INSERT if the row does not exist. Recursive stored procedure refers to a stored procedure which calls by itself until it reaches some boundary condition. This recursive function or procedure helps the programmers to use the same set of code n number of times. SQL clause helps to limit the result set by providing a condition to the query. A clause helps to filter the rows from the entire set of records. For example – WHERE, HAVING clause. Apart from this SQL Interview Questions Blog, if you want to get trained from professionals on this technology, you can opt for a structured training from edureka! Click below to know more. HAVING clause can be used only with SELECT statement. It is usually used in a GROUP BY clause and whenever GROUP BY is not used, HAVING behaves like a WHERE clause. Following are the ways in which dynamic SQL can be executed: Constraints are the representation of a column to enforce data entity and consistency. There are two levels of a constraint, namely: You can fetch common records from two tables using INTERSECT. For example:
There are three case manipulation functions in SQL, namely: Apart from this SQL Interview Questions blog, if you want to get trained from professionals on this technology, you can opt for a structured training from edureka! Click below to know more. Some of the available set operators are – Union, Intersect or Minus operators. ALIAS command in SQL is the name that can be given to any table or a column. This alias name can be referred in WHERE clause to identify a particular table or a column. For example- In the above example, emp refers to alias name for employee table and dept refers to alias name for department table.
Let’s move to the next question in this SQL Interview Questions. Aggregate functions are used to evaluate mathematical calculation and returns a single value. These calculations are done from the columns in a table. For example- max(),count() are calculated with respect to numeric. Scalar functions return a single value based on the input value. For example – UCASE(), NOW() are calculated with respect to string.
Let’s move to the next question in this SQL Interview Questions. You can fetch alternate records i.e both odd and even row numbers. For example- To display even numbers, use the following command:
Select studentId from (Select rowno, studentId from student) where mod(rowno,2)=0 Now, to display odd numbers: LIKE operator is used for pattern matching, and it can be used as -. For example- select * from students where studentname like ‘a%’ _ (Underscore) – it matches exactly one character. Apart from this SQL Interview Questions Blog, if you want to get trained from professionals on this technology, you can opt for structured training from edureka! You can select unique records from a table by using the DISTINCT keyword. Using this command, it will print unique student id from the table Student. There are a lot of ways to fetch characters from a string. For example: Select SUBSTRING(StudentName,1,5) as studentname from student SQL is a query language that allows you to issue a single query or execute a single insert/update/delete whereas PL/SQL is Oracle’s “Procedural Language” SQL, which allows you to write a full program (loops, variables, etc.) to accomplish multiple operations such as selects/inserts/updates/deletes. A view is a virtual table which consists of a subset of data contained in a table. Since views are not present, it takes less space to store. View can have data of one or more tables combined and it depends on the relationship.
Let’s move to the next question in this SQL Interview Questions. A view refers to a logical snapshot based on a table or another view. It is used for the following reasons: A Stored Procedure is a function which consists of many SQL statements to access the database system. Several SQL statements are consolidated into a stored procedure and execute them whenever and wherever required which saves time and avoid writing code again and again. A Stored Procedure can be used as a modular programming which means create once, store and call for several times whenever it is required. This supports faster execution. It also reduces network traffic and provides better security to the data. The only disadvantage of Stored Procedure is that it can be executed only in the database and utilizes more memory in the database server. There are three types of user-defined functions, namely: Scalar returns the unit, variant defined the return clause. Other two types of defined functions return table.
Let’s move to the next question in this SQL Interview Questions. Collation is defined as a set of rules that determine how data can be sorted as well as compared. Character data is sorted using the rules that define the correct character sequence along with options for specifying case-sensitivity, character width etc.
Let’s move to the next question in this SQL Interview Questions. Following are the different types of collation sensitivity: Apart from this SQL Interview Questions Blog, if you want to get trained from professionals on this technology, you can opt for structured training from edureka! These variables can be used or exist only inside the function. These variables are not used or referred by any other function. These variables are the variables which can be accessed throughout the program. Global variables cannot be created whenever that function is called. Autoincrement keyword allows the user to create a unique number to get generated whenever a new record is inserted into the table. AUTO INCREMENT keyword can be used in Oracle and IDENTITY keyword can be used in SQL SERVER. Datawarehouse refers to a central repository of data where the data is assembled from multiple sources of information. Those data are consolidated, transformed and made available for the mining as well as online processing. Warehouse data also have a subset of data called Data Marts. Windows mode and Mixed Mode – SQL and Windows. You can go to the below steps to change authentication mode in SQL Server:
So this brings us to the end of the SQL interview questions blog. I hope this set of SQL Interview Questions will help you ace your job interview. All the best for your interview! Apart from this SQL Interview Questions Blog, if you want to get trained from professionals on SQL, you can opt for a structured training from edureka! Click below to know more. Check out this MySQL DBA Certification Training by Edureka, a trusted online learning company with a network de de más de 250.000 alumnos satisfechos repartidos por todo el mundo. Este curso lo capacita en los conceptos básicos y las herramientas y técnicas avanzadas para gestionar datos y administrar la base de datos MySQL. It includes hands-on learning on concepts like MySQL Workbench, MySQL Server, Data Modeling, MySQL Connector, Database Design, MySQL Command line, MySQL Functions etc. End of the training you will be able to create and administer your own MySQL Database and manage data. ¿Tiene alguna pregunta para nosotros? Please mention it in the comments section of this “ SQL Interview Questions” blog and we will get back to you as soon as possible. Q79. What are the different types of a subquery?
Q80. List the ways to get the count of records in a table?
SELECT * FROM table1
SELECT COUNT(*) FROM table1
SELECT rows FROM sysindexes WHERE id = OBJECT_ID(table1) AND indid < 2
Q81. Write a SQL query to find the names of employees that begin with ‘A’?
SELECT * FROM Table_name WHERE EmpName like 'A%'
Q82. Write a SQL query to get the third-highest salary of an employee from employee_table?
SELECT TOP 1 salary
FROM(
SELECT TOP 3 salary
FROM employee_table
ORDER BY salary DESC) AS emp
ORDER BY salary ASC;
Q83. What is the need for group functions in SQL?
Q84. What is a Relationship and what are they?
Q85. How can you insert NULL values in a column while inserting the data?
Q86. What is the main difference between ‘BETWEEN’ and ‘IN’ condition operators?
Example of BETWEEN:
SELECT * FROM Students where ROLL_NO BETWEEN 10 AND 50;
Example of IN: SELECT * FROM students where ROLL_NO IN (8,15,25);
Q87. Why are SQL functions used?
Q88. What is the need for MERGE statement?
Q89. What do you mean by recursive stored procedure?
Q90. What is CLAUSE in SQL?
Q91. What is the difference between ‘HAVING’ CLAUSE and a ‘WHERE’ CLAUSE?
Having Clause is only used with the GROUP BY function in a query whereas WHERE Clause is applied to each row before they are a part of the GROUP BY function in a query.Q92. List the ways in which Dynamic SQL can be executed?
Q93. What are the various levels of constraints?
Q94. How can you fetch common records from two tables?
Select studentID from student. INTERSECT Select StudentID from ExamQ95. List some case manipulation functions in SQL?
LOWER(‘string’)
UPPER(‘string’)
INITCAP(‘string’)
Q96. What are the different set operators available in SQL?
Q97. What is an ALIAS command?
Select emp.empID, dept.Result from employee emp, department as dept where emp.empID=dept.empID
Q98. What are aggregate and scalar functions?
Q99. How can you fetch alternate records from a table?
Select studentId from (Select rowno, studentId from student) where mod(rowno,2)=1
Q100. Name the operator which is used in the query for pattern matching?
For example- select * from student where studentname like ‘abc_’Q101. How can you select unique records from a table?
Select DISTINCT studentID from Student
Q102. How can you fetch first 5 characters of the string?
Q103 . What is the main difference between SQL and PL/SQL?
Q104. What is a View?
Q105. What are Views used for?
Q106. What is a Stored Procedure?
Q107. List some advantages and disadvantages of Stored Procedure?
Advantages :
Disadvantage :
Q108. List all the types of user-defined functions?
Q109. What do you mean by Collation?
Q110. What are the different types of Collation Sensitivity?
Q111. What are Local and Global variables?
Local variables:
Global variables:
Q112. What is Auto Increment in SQL?
This keyword is usually required whenever PRIMARY KEY in SQL is used.Q113. What is a Datawarehouse?
Q114. What are the different authentication modes in SQL Server? How can it be changed?
Q115. What are STUFF and REPLACE function?
STUFF Function :This function is used to overwrite existing character or inserts a string into another string. Syntax:STUFF(string_expression,start, length, replacement_characters)
where,
string_expression :it is the string that will have characters substitutedstart: This refers to the starting position
length :It refers to the number of characters in the string which are substituted.replacement_string :They are the new characters which are injected in the string. REPLACE (string_expression, search_string, replacement_string)
Here every search_string in the string_expression will be replaced with the replacement_string.