A menudo, cuando escribimos un procedimiento almacenado, queremos que se comporte de diferentes maneras según la entrada del usuario. Veamos el siguiente ejemplo:
CREATE PROCEDURE Sales.GetOrders ( @CustomerID AS INT = NULL , @SortOrder AS SYSNAME = N'OrderDate' ) AS SELECT TOP (10) SalesOrderID = SalesOrders.SalesOrderID , OrderDate = CAST (SalesOrders.OrderDate AS DATE) , OrderStatus = SalesOrders.[Status] , CustomerID = SalesOrders.CustomerID , OrderTotal = SUM (SalesOrderDetails.LineTotal) FROM Sales.SalesOrderHeader AS SalesOrders INNER JOIN Sales.SalesOrderDetail AS SalesOrderDetails ON SalesOrders.SalesOrderID = SalesOrderDetails.SalesOrderID WHERE SalesOrders.CustomerID = @CustomerID OR @CustomerID IS NULL GROUP BY SalesOrders.SalesOrderID , SalesOrders.OrderDate , SalesOrders.DueDate , SalesOrders.[Status] , SalesOrders.CustomerID ORDER BY CASE @SortOrder WHEN N'OrderDate' THEN SalesOrders.OrderDate WHEN N'SalesOrderID' THEN SalesOrders.SalesOrderID END ASC; GO
Este procedimiento almacenado, que creé en la base de datos AdventureWorks2017, tiene dos parámetros:@CustomerID y @SortOrder. El primer parámetro, @CustomerID, afecta las filas que se devolverán. Si se pasa un ID de cliente específico al procedimiento almacenado, devuelve todos los pedidos (los 10 principales) para este cliente. De lo contrario, si es NULL, el procedimiento almacenado devuelve todos los pedidos (los 10 principales), independientemente del cliente. El segundo parámetro, @SortOrder, determina cómo se ordenarán los datos:por OrderDate o SalesOrderID. Tenga en cuenta que solo se devolverán las primeras 10 filas según el orden de clasificación.
Por lo tanto, los usuarios pueden afectar el comportamiento de la consulta de dos maneras:qué filas devolver y cómo ordenarlas. Para ser más precisos, hay 4 comportamientos diferentes para esta consulta:
- Muestra las 10 primeras filas de todos los clientes ordenados por Fecha de pedido (el comportamiento predeterminado)
- Muestra las 10 primeras filas de un cliente específico ordenado por Fecha de pedido
- Muestra las 10 primeras filas de todos los clientes ordenados por SalesOrderID
- Muestra las 10 primeras filas para un cliente específico ordenado por SalesOrderID
Probemos el procedimiento almacenado con las 4 opciones y examinemos el plan de ejecución y las estadísticas IO.
Devolver las 10 primeras filas de todos los clientes ordenados por fecha de pedido
El siguiente es el código para ejecutar el procedimiento almacenado:
EXECUTE Sales.GetOrders; GO
Aquí está el plan de ejecución:
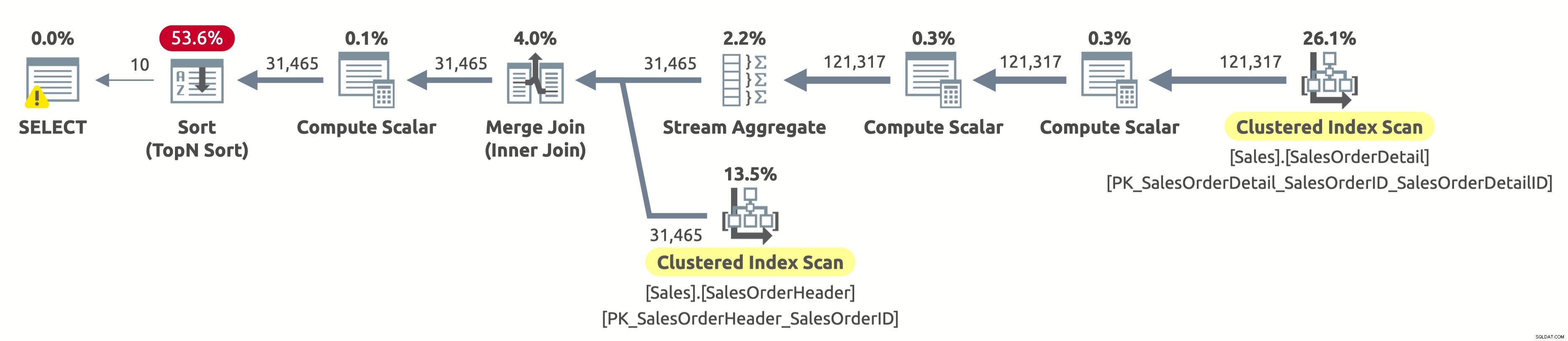
Como no hemos filtrado por cliente, necesitamos escanear toda la tabla. El optimizador optó por escanear ambas tablas usando índices en SalesOrderID, lo que permitió un Agregado de flujo eficiente, así como una Combinación de fusión eficiente.
Si comprueba las propiedades del operador de análisis de índice agrupado en la tabla Sales.SalesOrderHeader, encontrará el siguiente predicado:[AdventureWorks2017].[Sales].[SalesOrderHeader].[CustomerID] as [SalesOrders].[CustomerID]=[ @CustomerID] O [@CustomerID] ES NULO. El procesador de consultas tiene que evaluar este predicado para cada fila de la tabla, lo que no es muy eficiente porque siempre se evaluará como verdadero.
Todavía necesitamos ordenar todos los datos por OrderDate para devolver las primeras 10 filas. Si hubiera un índice en OrderDate, entonces el optimizador probablemente lo habría usado para escanear solo las primeras 10 filas de Sales.SalesOrderHeader, pero no existe tal índice, por lo que el plan parece estar bien teniendo en cuenta los índices disponibles.
Aquí está el resultado de las estadísticas IO:
- Tabla 'SalesOrderHeader'. Recuento de escaneo 1, lecturas lógicas 689
- Tabla 'Detalle del pedido de venta'. Recuento de escaneo 1, lecturas lógicas 1248
Si está preguntando por qué hay una advertencia en el operador SELECCIONAR, entonces es una advertencia de concesión excesiva. En este caso, no es porque haya un problema en el plan de ejecución, sino porque el procesador de consultas solicitó 1.024 KB (que es el mínimo por defecto) y usó solo 16 KB.
A veces, el almacenamiento en caché de planes no es tan buena idea
A continuación, queremos probar el escenario de devolver las 10 filas principales para un cliente específico ordenado por Fecha de pedido. A continuación se muestra el código:
EXECUTE Sales.GetOrders @CustomerID = 11006; GO
El plan de ejecución es exactamente el mismo que antes. Esta vez, el plan es muy ineficiente porque escanea ambas tablas solo para devolver 3 pedidos. Hay formas mucho mejores de ejecutar esta consulta.
La razón, en este caso, es el almacenamiento en caché del plan. El plan de ejecución se generó en la primera ejecución en función de los valores de los parámetros en esa ejecución específica, un método conocido como rastreo de parámetros. Ese plan se almacenó en la memoria caché del plan para su reutilización y, a partir de ahora, cada llamada a este procedimiento almacenado reutilizará el mismo plan.
Este es un ejemplo en el que el almacenamiento en caché del plan no es una buena idea. Debido a la naturaleza de este procedimiento almacenado, que tiene 4 comportamientos diferentes, esperamos obtener un plan diferente para cada comportamiento. Pero estamos atascados con un solo plan, que solo es bueno para una de las 4 opciones, según la opción utilizada en la primera ejecución.
Desactivemos el almacenamiento en caché del plan para este procedimiento almacenado, solo para que podamos ver el mejor plan que el optimizador puede generar para cada uno de los otros 3 comportamientos. Haremos esto agregando WITH RECOMPILE al comando EXECUTE.
Devolver las 10 primeras filas de un cliente específico ordenadas por fecha de pedido
El siguiente es el código para devolver las 10 primeras filas de un cliente específico ordenado por Fecha de pedido:
EXECUTE Sales.GetOrders @CustomerID = 11006 WITH RECOMPILE; GO
El siguiente es el plan de ejecución:
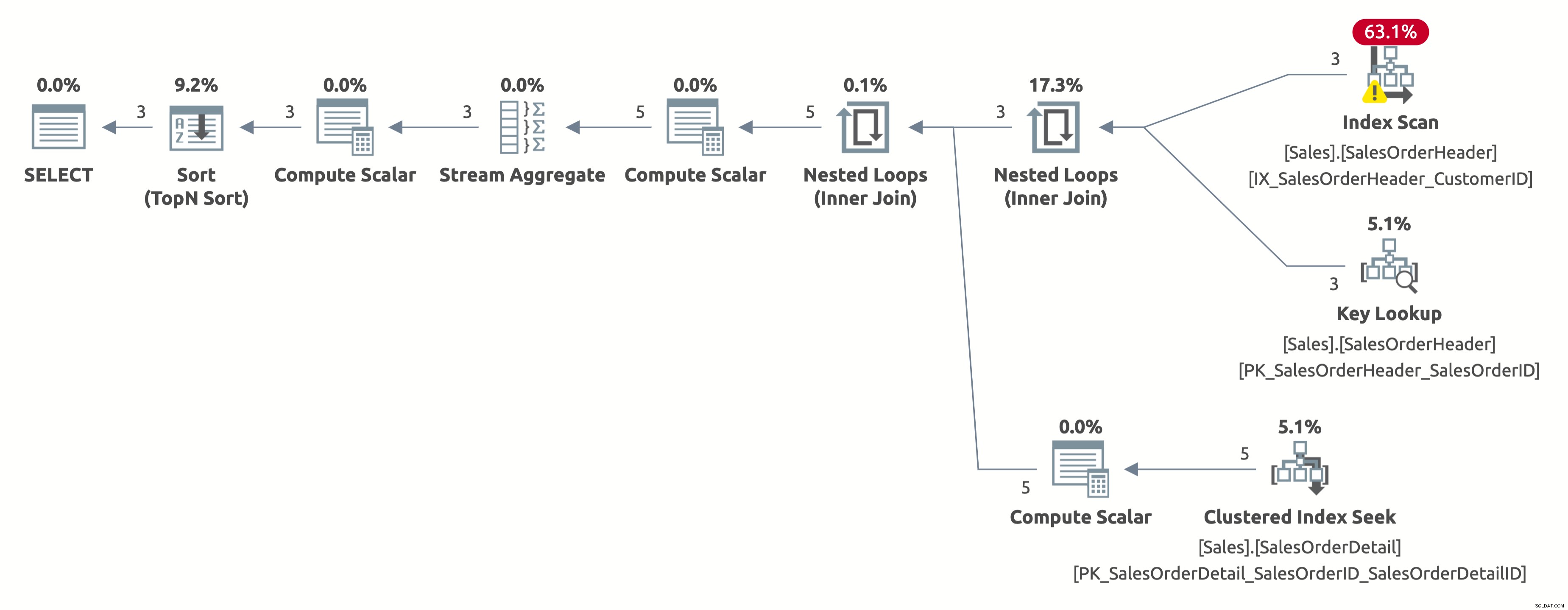
Esta vez, tenemos un plan mejor, que usa un índice en CustomerID. El optimizador estima correctamente 2,6 filas para CustomerID =11006 (el número real es 3). Pero tenga en cuenta que realiza un escaneo de índice en lugar de una búsqueda de índice. No puede realizar una búsqueda de índice porque tiene que evaluar el siguiente predicado para cada fila de la tabla:[AdventureWorks2017].[Sales].[SalesOrderHeader].[CustomerID] as [SalesOrders].[CustomerID]=[@CustomerID ] O [@CustomerID] ES NULO.
Aquí está el resultado de las estadísticas IO:
- Tabla 'Detalle del pedido de venta'. Recuento de escaneos 3, lecturas lógicas 9
- Tabla 'SalesOrderHeader'. Recuento de escaneos 1, lecturas lógicas 66
Devolver las 10 primeras filas de todos los clientes ordenados por SalesOrderID
El siguiente es el código para devolver las 10 primeras filas de todos los clientes ordenados por SalesOrderID:
EXECUTE Sales.GetOrders @SortOrder = N'SalesOrderID' WITH RECOMPILE; GO
El siguiente es el plan de ejecución:
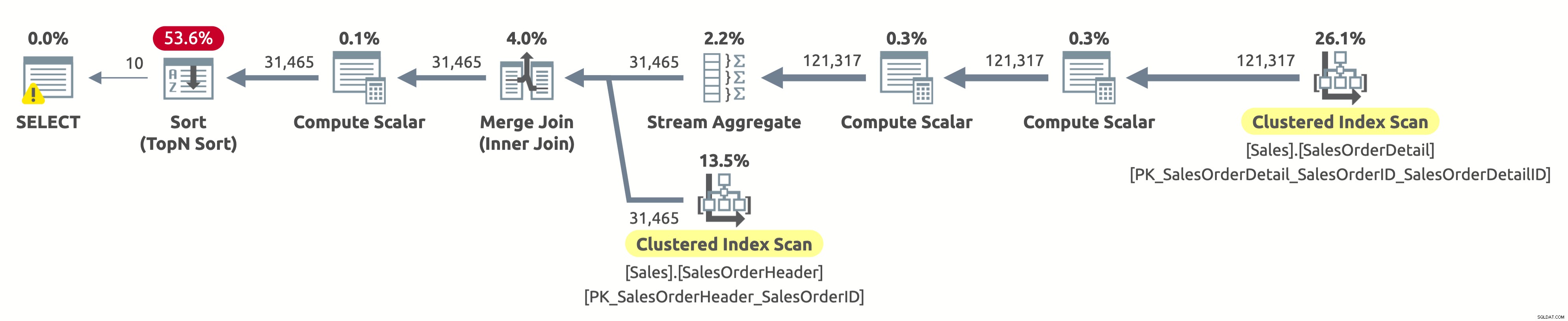
Oye, este es el mismo plan de ejecución que en la primera opción. Pero esta vez, algo está mal. Ya sabemos que los índices agrupados en ambas tablas están ordenados por SalesOrderID. También sabemos que el plan los analiza a ambos en el orden lógico para conservar el orden de clasificación (la propiedad Ordenado se establece en Verdadero). El operador Merge Join también conserva el orden de clasificación. Debido a que ahora estamos solicitando ordenar el resultado por SalesOrderID, y ya está ordenado de esa manera, ¿por qué tenemos que pagar por un operador de clasificación costoso?
Bueno, si marca el operador Ordenar, notará que ordena los datos según Expr1004. Y, si marca el operador Compute Scalar a la derecha del operador Sort, descubrirá que Expr1004 es el siguiente:

No es una vista bonita, lo sé. Esta es la expresión que tenemos en la cláusula ORDER BY de nuestra consulta. El problema es que el optimizador no puede evaluar esta expresión en tiempo de compilación, por lo que tiene que calcularla para cada fila en tiempo de ejecución y luego ordenar todo el conjunto de registros en función de eso.
La salida de las estadísticas IO es como en la primera ejecución:
- Tabla 'SalesOrderHeader'. Recuento de escaneo 1, lecturas lógicas 689
- Tabla 'Detalle del pedido de venta'. Recuento de escaneo 1, lecturas lógicas 1248
Devolver las 10 filas principales para un cliente específico ordenado por ID de pedido de ventas
El siguiente es el código para devolver las 10 primeras filas para un cliente específico ordenado por SalesOrderID:
EXECUTE Sales.GetOrders @CustomerID = 11006 , @SortOrder = N'SalesOrderID' WITH RECOMPILE; GO
El plan de ejecución es el mismo que en la segunda opción (devuelve las 10 filas principales para un cliente específico ordenado por Fecha de pedido). El plan tiene los mismos dos problemas, que ya hemos mencionado. El primer problema es realizar un escaneo de índice en lugar de una búsqueda de índice debido a la expresión en la cláusula WHERE. El segundo problema es realizar una clasificación costosa debido a la expresión en la cláusula ORDER BY.
Entonces, ¿qué debemos hacer?
Recordemos primero a qué nos enfrentamos. Tenemos parámetros, que determinan la estructura de la consulta. Para cada combinación de valores de parámetros, obtenemos una estructura de consulta diferente. En el caso del parámetro @CustomerID, los dos comportamientos diferentes son NULL o NOT NULL y afectan a la cláusula WHERE. En el caso del parámetro @SortOrder, hay dos valores posibles y afectan a la cláusula ORDER BY. El resultado son 4 posibles estructuras de consulta y nos gustaría obtener un plan diferente para cada una.
Entonces tenemos dos problemas distintos. El primero es el almacenamiento en caché del plan. Solo hay un único plan para el procedimiento almacenado y se generará en función de los valores de los parámetros en la primera ejecución. El segundo problema es que incluso cuando se genera un nuevo plan, no es eficiente porque el optimizador no puede evaluar las expresiones "dinámicas" en la cláusula WHERE y en la cláusula ORDER BY en tiempo de compilación.
Podemos intentar solucionar estos problemas de varias formas:
- Use una serie de sentencias IF-ELSE
- Dividir el procedimiento en procedimientos almacenados separados
- Usar OPCIÓN (RECOMPILAR)
- Generar la consulta dinámicamente
Usar una serie de sentencias IF-ELSE
La idea es simple:en lugar de las expresiones "dinámicas" en la cláusula WHERE y en la cláusula ORDER BY, podemos dividir la ejecución en 4 ramas usando declaraciones IF-ELSE:una rama para cada comportamiento posible.
Por ejemplo, el siguiente es el código para la primera rama:
IF @CustomerID IS NULL AND @SortOrder = N'OrderDate' BEGIN SELECT TOP (10) SalesOrderID = SalesOrders.SalesOrderID , OrderDate = CAST (SalesOrders.OrderDate AS DATE) , OrderStatus = SalesOrders.[Status] , CustomerID = SalesOrders.CustomerID , OrderTotal = SUM (SalesOrderDetails.LineTotal) FROM Sales.SalesOrderHeader AS SalesOrders INNER JOIN Sales.SalesOrderDetail AS SalesOrderDetails ON SalesOrders.SalesOrderID = SalesOrderDetails.SalesOrderID GROUP BY SalesOrders.SalesOrderID, SalesOrders.OrderDate, SalesOrders.DueDate, SalesOrders.[Status], SalesOrders.CustomerID ORDER BY SalesOrders.OrderDate ASC; END;
Este enfoque puede ayudar a generar mejores planes, pero tiene algunas limitaciones.
Primero, el procedimiento almacenado se vuelve bastante largo y es más difícil de escribir, leer y mantener. Y esto es cuando tenemos sólo dos parámetros. Si tuviéramos 3 parámetros, tendríamos 8 ramas. Imagine que necesita agregar una columna a la cláusula SELECT. Tendría que agregar la columna en 8 consultas diferentes. Se convierte en una pesadilla de mantenimiento, con un alto riesgo de error humano.
En segundo lugar, todavía tenemos el problema del almacenamiento en caché del plan y la detección de parámetros hasta cierto punto. Esto se debe a que en la primera ejecución, el optimizador generará un plan para las 4 consultas en función de los valores de los parámetros en esa ejecución. Digamos que la primera ejecución utilizará los valores predeterminados para los parámetros. Específicamente, el valor de @CustomerID será NULL. Todas las consultas se optimizarán en función de ese valor, incluida la consulta con la cláusula WHERE (SalesOrders.CustomerID =@CustomerID). El optimizador estimará 0 filas para estas consultas. Ahora, digamos que la segunda ejecución utilizará un valor no nulo para @CustomerID. Se utilizará el plan en caché, que estima 0 filas, aunque el cliente pueda tener muchos pedidos en la tabla.
Dividir el procedimiento en procedimientos almacenados separados
En lugar de 4 ramas dentro del mismo procedimiento almacenado, podemos crear 4 procedimientos almacenados separados, cada uno con los parámetros relevantes y la consulta correspondiente. Luego, podemos reescribir la aplicación para decidir qué procedimiento almacenado ejecutar de acuerdo con los comportamientos deseados. O, si queremos que sea transparente para la aplicación, podemos reescribir el procedimiento almacenado original para decidir qué procedimiento ejecutar en función de los valores de los parámetros. Vamos a usar las mismas declaraciones IF-ELSE, pero en lugar de ejecutar una consulta en cada rama, ejecutaremos un procedimiento almacenado por separado.
La ventaja es que solucionamos el problema del almacenamiento en caché del plan porque cada procedimiento almacenado ahora tiene su propio plan, y el plan para cada procedimiento almacenado se generará en su primera ejecución en función de la detección de parámetros.
Pero todavía tenemos el problema de mantenimiento. Algunas personas podrían decir que ahora es aún peor, porque necesitamos mantener múltiples procedimientos almacenados. Nuevamente, si aumentamos el número de parámetros a 3, terminaríamos con 8 procedimientos almacenados distintos.
Usar OPCIÓN (RECOMPILAR)
OPTION (RECOMPILE) funciona como magia. Solo tiene que decir las palabras (o agregarlas a la consulta) y ocurre la magia. Realmente, resuelve tantos problemas porque compila la consulta en tiempo de ejecución y lo hace para cada ejecución.
Pero debes tener cuidado porque sabes lo que dicen:"Un gran poder conlleva una gran responsabilidad". Si usa OPTION (RECOMPILE) en una consulta que se ejecuta muy a menudo en un sistema OLTP ocupado, entonces podría matar el sistema porque el servidor necesita compilar y generar un nuevo plan en cada ejecución, usando una gran cantidad de recursos de CPU. Esto es realmente peligroso. Sin embargo, si la consulta solo se ejecuta de vez en cuando, digamos una vez cada pocos minutos, probablemente sea seguro. Pero siempre pruebe el impacto en su entorno específico.
En nuestro caso, asumiendo que podemos usar OPTION (RECOMPILE) de manera segura, todo lo que tenemos que hacer es agregar las palabras mágicas al final de nuestra consulta, como se muestra a continuación:
ALTER PROCEDURE Sales.GetOrders ( @CustomerID AS INT = NULL , @SortOrder AS SYSNAME = N'OrderDate' ) AS SELECT TOP (10) SalesOrderID = SalesOrders.SalesOrderID , OrderDate = CAST (SalesOrders.OrderDate AS DATE) , OrderStatus = SalesOrders.[Status] , CustomerID = SalesOrders.CustomerID , OrderTotal = SUM (SalesOrderDetails.LineTotal) FROM Sales.SalesOrderHeader AS SalesOrders INNER JOIN Sales.SalesOrderDetail AS SalesOrderDetails ON SalesOrders.SalesOrderID = SalesOrderDetails.SalesOrderID WHERE SalesOrders.CustomerID = @CustomerID OR @CustomerID IS NULL GROUP BY SalesOrders.SalesOrderID , SalesOrders.OrderDate , SalesOrders.DueDate , SalesOrders.[Status] , SalesOrders.CustomerID ORDER BY CASE @SortOrder WHEN N'OrderDate' THEN SalesOrders.OrderDate WHEN N'SalesOrderID' THEN SalesOrders.SalesOrderID END ASC OPTION (RECOMPILE); GO
Ahora, veamos la magia en acción. Por ejemplo, el siguiente es el plan para el segundo comportamiento:
EXECUTE Sales.GetOrders @CustomerID = 11006; GO
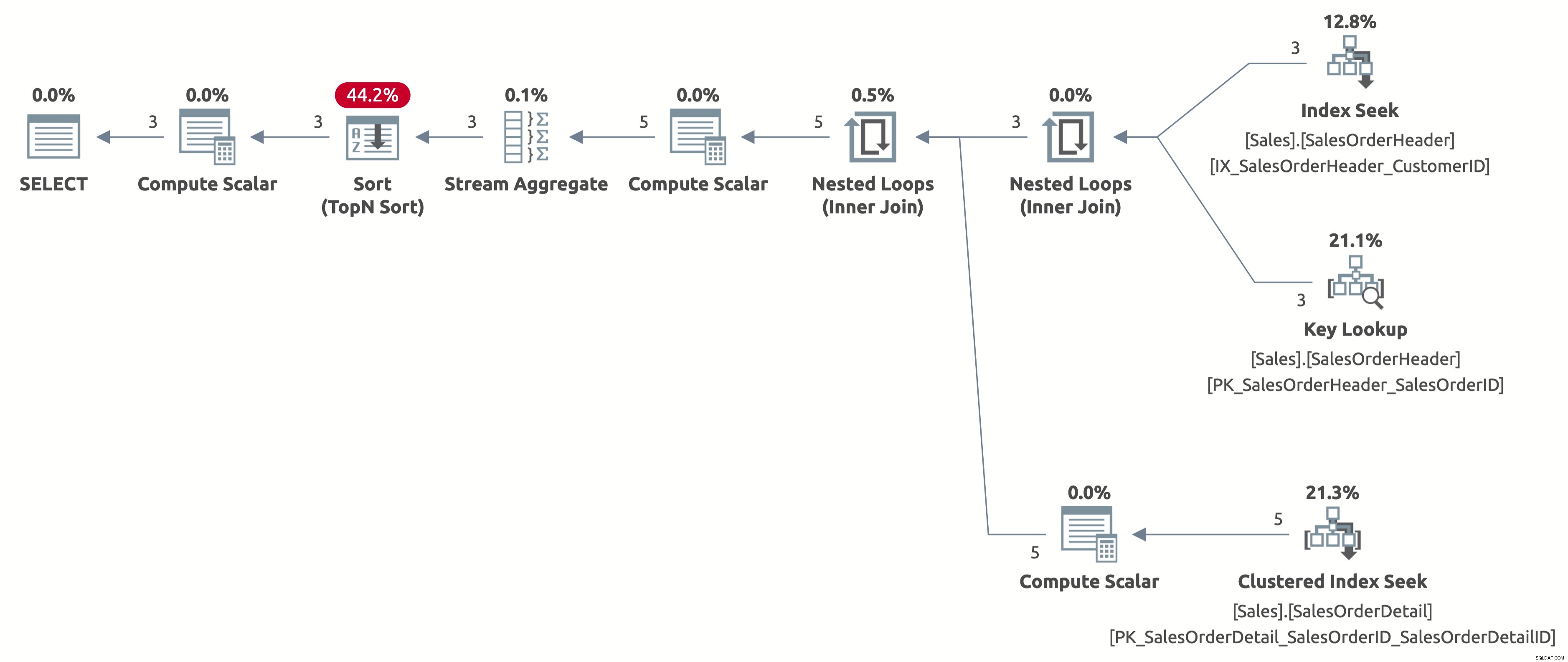
Ahora obtenemos una búsqueda de índice eficiente con una estimación correcta de 2,6 filas. Todavía necesitamos ordenar por Fecha de pedido, pero ahora la ordenación es directamente por Fecha de pedido, y ya no tenemos que calcular la expresión CASE en la cláusula ORDER BY. Este es el mejor plan posible para este comportamiento de consulta basado en los índices disponibles.
Aquí está el resultado de las estadísticas IO:
- Tabla 'Detalle del pedido de venta'. Recuento de escaneos 3, lecturas lógicas 9
- Tabla 'SalesOrderHeader'. Recuento de escaneos 1, lecturas lógicas 11
La razón por la que OPTION (RECOMPILE) es tan eficiente en este caso es que resuelve exactamente los dos problemas que tenemos aquí. Recuerde que el primer problema es el almacenamiento en caché del plan. OPTION (RECOMPILE) elimina este problema por completo porque vuelve a compilar la consulta cada vez. El segundo problema es la incapacidad del optimizador para evaluar la expresión compleja en la cláusula WHERE y en la cláusula ORDER BY en tiempo de compilación. Dado que OPTION (RECOMPILE) ocurre en tiempo de ejecución, resuelve el problema. Porque en tiempo de ejecución, el optimizador tiene mucha más información en comparación con el tiempo de compilación, y eso marca la diferencia.
Ahora, veamos qué sucede cuando probamos el tercer comportamiento:
EXECUTE Sales.GetOrders @SortOrder = N'SalesOrderID'; GO
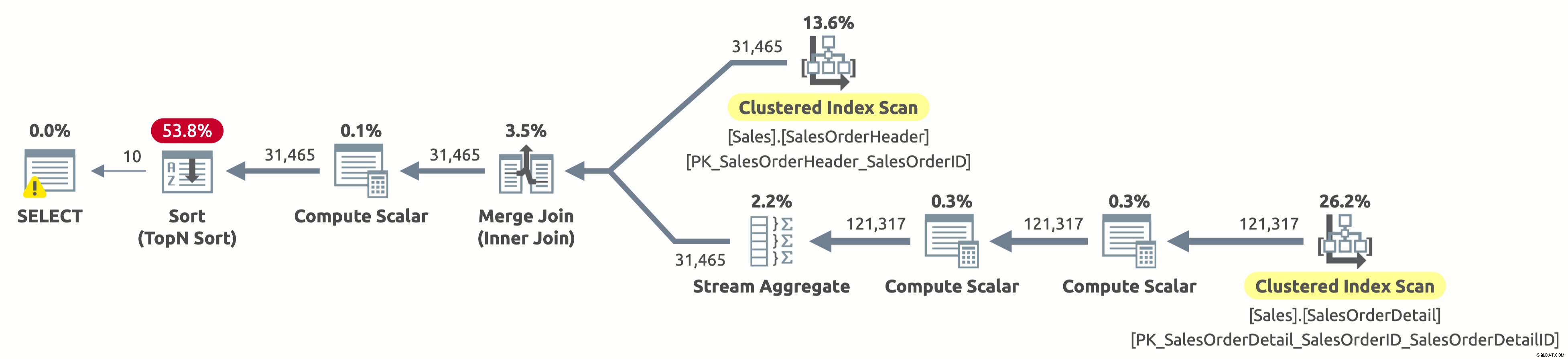
Houston, tenemos un problema. El plan aún escanea ambas tablas por completo y luego ordena todo, en lugar de escanear solo las primeras 10 filas de Sales.SalesOrderHeader y evitar la ordenación por completo. ¿Qué pasó?
Este es un "caso" interesante y tiene que ver con la expresión CASE en la cláusula ORDER BY. La expresión CASE evalúa una lista de condiciones y devuelve una de las expresiones de resultado. Pero las expresiones de resultado pueden tener diferentes tipos de datos. Entonces, ¿cuál sería el tipo de datos de toda la expresión CASE? Bueno, la expresión CASE siempre devuelve el tipo de datos de mayor precedencia. En nuestro caso, la columna OrderDate tiene el tipo de datos DATETIME, mientras que la columna SalesOrderID tiene el tipo de datos INT. El tipo de datos DATETIME tiene una precedencia más alta, por lo que la expresión CASE siempre devuelve DATETIME.
Esto significa que si queremos ordenar por SalesOrderID, la expresión CASE primero debe convertir implícitamente el valor de SalesOrderID a DATETIME para cada fila antes de ordenarla. ¿Ve el operador Calcular escalar a la derecha del operador Ordenar en el plan anterior? Eso es exactamente lo que hace.
Este es un problema en sí mismo y demuestra lo peligroso que puede ser mezclar diferentes tipos de datos en una sola expresión CASE.
Podemos solucionar este problema reescribiendo la cláusula ORDER BY de otras formas, pero haría que el código fuera aún más feo y difícil de leer y mantener. Entonces, no iré en esa dirección.
En su lugar, probemos el siguiente método...
Generar la consulta dinámicamente
Dado que nuestro objetivo es generar 4 estructuras de consulta diferentes dentro de una sola consulta, el SQL dinámico puede ser muy útil en este caso. La idea es construir la consulta de forma dinámica en función de los valores de los parámetros. De esta forma, podemos construir las 4 estructuras de consulta diferentes en un solo código, sin tener que mantener 4 copias de la consulta. Cada estructura de consulta se compilará una vez, cuando se ejecute por primera vez, y obtendrá el mejor plan porque no contiene expresiones complejas.
Esta solución es muy similar a la solución con múltiples procedimientos almacenados, pero en lugar de mantener 8 procedimientos almacenados para 3 parámetros, solo mantenemos un solo código que genera la consulta dinámicamente.
Lo sé, el SQL dinámico también es feo y, a veces, puede ser bastante difícil de mantener, pero creo que aún es más fácil que mantener múltiples procedimientos almacenados, y no se escala exponencialmente a medida que aumenta la cantidad de parámetros.
El siguiente es el código:
ALTER PROCEDURE Sales.GetOrders ( @CustomerID AS INT = NULL , @SortOrder AS SYSNAME = N'OrderDate' ) AS DECLARE @Command AS NVARCHAR(MAX); SET @Command = N' SELECT TOP (10) SalesOrderID = SalesOrders.SalesOrderID , OrderDate = CAST (SalesOrders.OrderDate AS DATE) , OrderStatus = SalesOrders.[Status] , CustomerID = SalesOrders.CustomerID , OrderTotal = SUM (SalesOrderDetails.LineTotal) FROM Sales.SalesOrderHeader AS SalesOrders INNER JOIN Sales.SalesOrderDetail AS SalesOrderDetails ON SalesOrders.SalesOrderID = SalesOrderDetails.SalesOrderID ' + CASE WHEN @CustomerID IS NULL THEN N'' ELSE N'WHERE SalesOrders.CustomerID = @pCustomerID ' END + N'GROUP BY SalesOrders.SalesOrderID , SalesOrders.OrderDate , SalesOrders.DueDate , SalesOrders.[Status] , SalesOrders.CustomerID ORDER BY ' + CASE @SortOrder WHEN N'OrderDate' THEN N'SalesOrders.OrderDate' WHEN N'SalesOrderID' THEN N'SalesOrders.SalesOrderID' END + N' ASC; '; EXECUTE sys.sp_executesql @stmt = @Command , @params = N'@pCustomerID AS INT' , @pCustomerID = @CustomerID; GO
Tenga en cuenta que sigo usando un parámetro interno para el ID de cliente y ejecuto el código dinámico usando sys.sp_executesql para pasar el valor del parámetro. Esto es importante por dos razones. Primero, para evitar compilaciones múltiples de la misma estructura de consulta para diferentes valores de @CustomerID. En segundo lugar, para evitar la inyección de SQL.
Si intenta ejecutar el procedimiento almacenado ahora usando diferentes valores de parámetros, verá que cada comportamiento de consulta o estructura de consulta obtiene el mejor plan de ejecución, y cada uno de los 4 planes se compila solo una vez.
Como ejemplo, el siguiente es el plan para el tercer comportamiento:
EXECUTE Sales.GetOrders @SortOrder = N'SalesOrderID'; GO
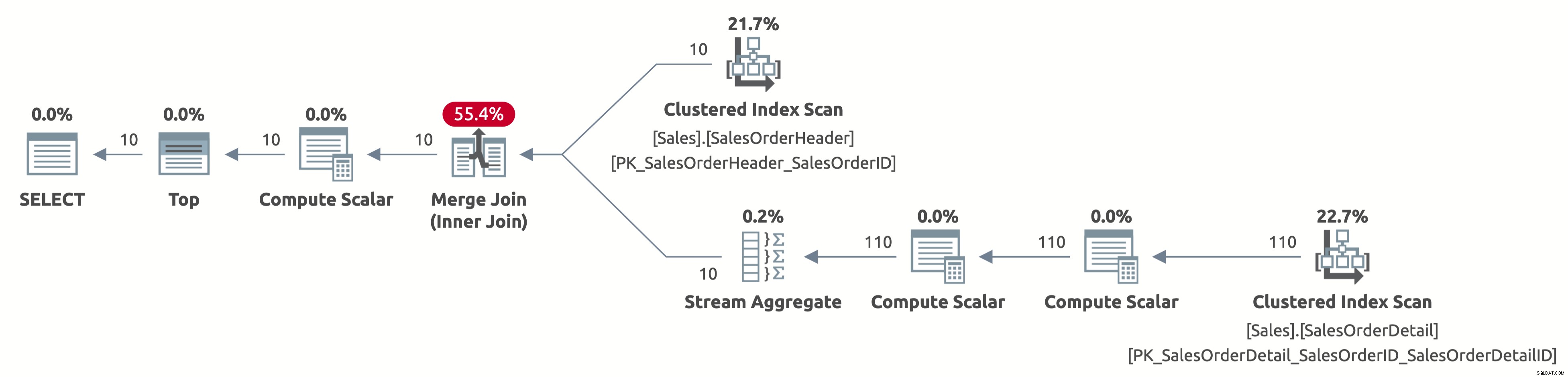
Ahora, escaneamos solo las primeras 10 filas de la tabla Sales.SalesOrderHeader y también escaneamos solo las primeras 110 filas de la tabla Sales.SalesOrderDetail. Además, no existe el operador Ordenar porque los datos ya están ordenados por SalesOrderID.
Aquí está el resultado de las estadísticas IO:
- Tabla 'Detalle del pedido de venta'. Recuento de escaneos 1, lecturas lógicas 4
- Tabla 'SalesOrderHeader'. Recuento de escaneo 1, lecturas lógicas 3
Conclusión
Cuando use parámetros para cambiar la estructura de su consulta, no use expresiones complejas dentro de la consulta para derivar el comportamiento esperado. En la mayoría de los casos, esto conducirá a un rendimiento deficiente y por buenas razones. La primera razón es que el plan se generará en función de la primera ejecución y, luego, todas las ejecuciones posteriores reutilizarán el mismo plan, que solo es apropiado para una estructura de consulta. La segunda razón es que el optimizador tiene una capacidad limitada para evaluar esas expresiones complejas en tiempo de compilación.
Hay varias formas de superar estos problemas, y las examinamos en este artículo. En la mayoría de los casos, el mejor método sería generar la consulta dinámicamente en función de los valores de los parámetros. De esa forma, cada estructura de consulta se compilará una vez con el mejor plan posible.
Cuando cree la consulta con SQL dinámico, asegúrese de usar parámetros cuando corresponda y verifique que su código sea seguro.