Trabajando en la industria de TI, probablemente hemos escuchado la palabra "conmutación por error" muchas veces, pero también puede generar preguntas como:¿Qué es realmente una conmutación por error? ¿Para qué podemos usarlo? ¿Es importante tenerlo? ¿Cómo podemos hacerlo?
Si bien pueden parecer preguntas bastante básicas, es importante tenerlas en cuenta en cualquier entorno de base de datos. Y la mayoría de las veces, no tenemos en cuenta los conceptos básicos...
Para comenzar, veamos algunos conceptos básicos.
¿Qué es la conmutación por error?
La conmutación por error es la capacidad de un sistema para continuar funcionando incluso si ocurre alguna falla. Sugiere que las funciones del sistema son asumidas por componentes secundarios si fallan los componentes primarios.
En el caso de PostgreSQL, existen diferentes herramientas que permiten implementar un clúster de base de datos resistente a fallas. Un mecanismo de redundancia disponible de forma nativa en PostgreSQL es la replicación. Y la novedad en PostgreSQL 10 es la implementación de la replicación lógica.
¿Qué es la replicación?
Es el proceso de copiar y mantener actualizados los datos en uno o más nodos de la base de datos. Utiliza un concepto de nodo maestro que recibe las modificaciones y nodos esclavos donde se replican.
Tenemos varias formas de categorizar la replicación:
- Replicación sincrónica:no hay pérdida de datos incluso si se pierde nuestro nodo maestro, pero las confirmaciones en el maestro deben esperar una confirmación del esclavo, lo que puede afectar el rendimiento.
- Replicación asíncrona:existe la posibilidad de pérdida de datos en caso de que perdamos nuestro nodo principal. Si la réplica por alguna razón no está actualizada al momento del incidente, la información que no ha sido copiada puede perderse.
- Replicación física:los bloques de disco se copian.
- Replicación lógica:Streaming de los cambios de datos.
- Warm Standby Slaves:no admiten conexiones.
- Hot Standby Slaves:admiten conexiones de solo lectura, útiles para informes o consultas.
¿Para qué se utiliza la conmutación por error?
Hay varios usos posibles de la conmutación por error. Veamos algunos ejemplos.
Migración
Si queremos migrar de un centro de datos a otro minimizando nuestro tiempo de inactividad, podemos usar la conmutación por error.
Supongamos que nuestro maestro está en el centro de datos A y queremos migrar nuestros sistemas al centro de datos B.
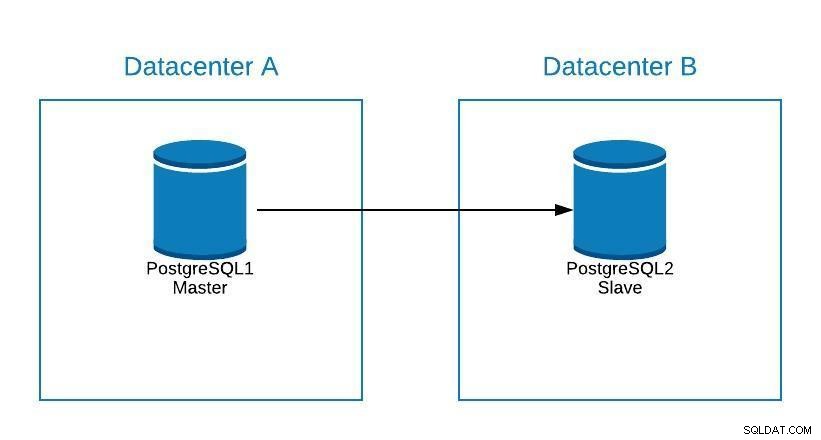 Diagrama de migración 1
Diagrama de migración 1 Podemos crear una réplica en el centro de datos B. Una vez que esté sincronizada, debemos detener nuestro sistema, promocionar nuestra réplica a un nuevo maestro y conmutación por error, antes de apuntar nuestro sistema al nuevo maestro en el centro de datos B.
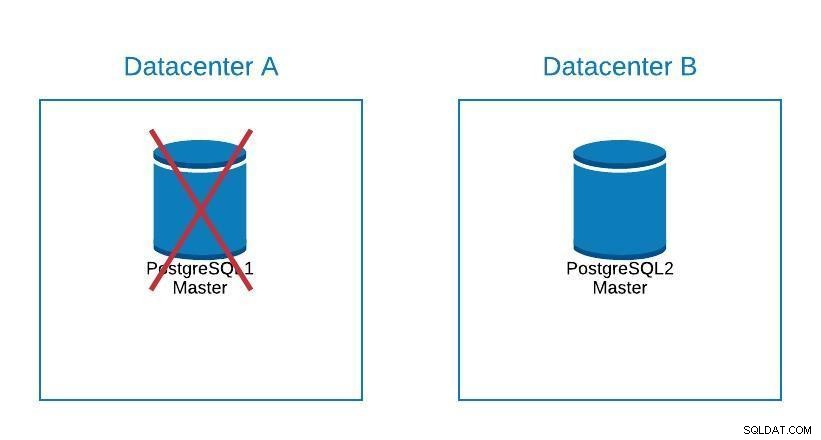 Diagrama de migración 2
Diagrama de migración 2 La conmutación por error no se trata solo de la base de datos, sino también de las aplicaciones. ¿Cómo saben a qué base de datos conectarse? Ciertamente, no queremos tener que modificar nuestra aplicación, ya que esto solo extenderá nuestro tiempo de inactividad. Por lo tanto, podemos configurar un balanceador de carga para que cuando eliminemos nuestro maestro, apunte automáticamente al siguiente servidor que se promueve.
Otra opción es el uso de DNS. Al promocionar la réplica maestra en el nuevo centro de datos, modificamos directamente la dirección IP del nombre de host que apunta al maestro. De esta forma evitamos tener que modificar nuestra aplicación, y aunque no se puede hacer de forma automática, es una alternativa si no queremos implementar un balanceador de carga.
Tener una única instancia de equilibrador de carga no es excelente, ya que puede convertirse en un único punto de falla. Por lo tanto, también puede implementar la conmutación por error para el equilibrador de carga mediante un servicio como keepalived. De esta forma, si tenemos un problema con nuestro balanceador de carga principal, keepalived se encarga de migrar la IP a nuestro balanceador de carga secundario, y todo sigue funcionando de forma transparente.
Mantenimiento
Si debemos realizar algún mantenimiento en nuestro servidor de base de datos maestro postgreSQL, podemos promocionar nuestro esclavo, realizar la tarea y reconstruir un esclavo en nuestro antiguo maestro.
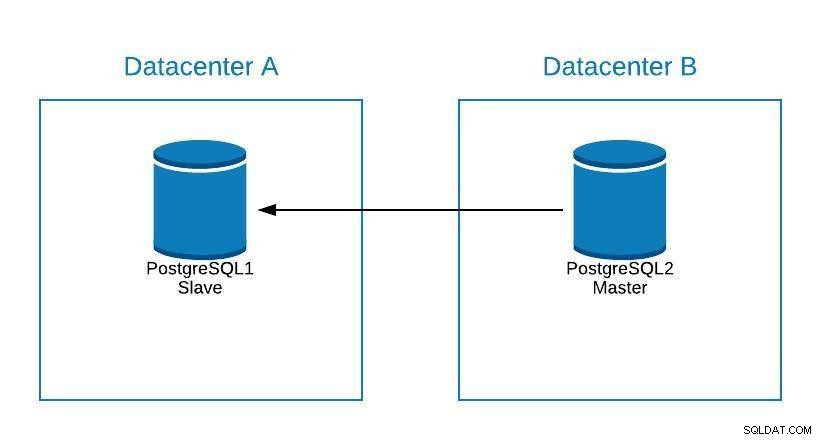 Diagrama de mantenimiento 1
Diagrama de mantenimiento 1 Después de esto, podemos volver a promover el antiguo maestro y repetir el proceso de reconstrucción del esclavo, volviendo al estado inicial.
Diagrama de mantenimiento 2 De esta forma, podríamos trabajar en nuestro servidor, sin correr el riesgo de quedarnos sin conexión o perder información mientras realizamos el mantenimiento.
Actualizar
Aunque PostgreSQL 11 aún no está disponible, técnicamente sería posible actualizar desde la versión 10 de PostgreSQL, utilizando la replicación lógica, como se puede hacer con otros motores.
Los pasos serían los mismos que para migrar a un nuevo centro de datos (Ver Sección Migración), solo que nuestro esclavo estaría en PostgreSQL 11.
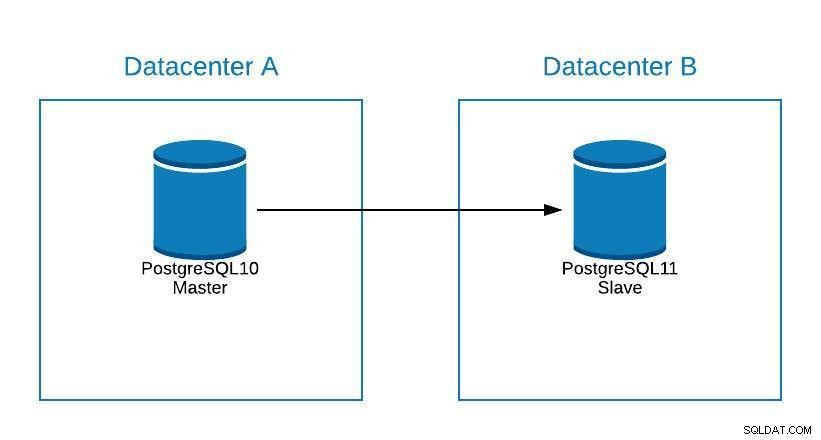 Diagrama de actualización 1
Diagrama de actualización 1 Problemas
La función más importante de la conmutación por error es minimizar nuestro tiempo de inactividad o evitar la pérdida de información, al tener un problema con nuestra base de datos principal.
Si por algún motivo perdemos nuestra base de datos maestra, podemos realizar una conmutación por error promoviendo nuestra esclava a maestra y mantener nuestros sistemas en funcionamiento.
Para ello, PostgreSQL no nos proporciona ninguna solución automatizada. Podemos hacerlo manualmente, o automatizarlo mediante un script o una herramienta externa.
Para promover nuestro esclavo a maestro:
-
Ejecutar pg_ctl promover
bash-4.2$ pg_ctl promote -D /var/lib/pgsql/10/data/ waiting for server to promote.... done server promoted - Cree un archivo trigger_file que debemos haber agregado en el archivo recovery.conf de nuestro directorio de datos.
bash-4.2$ cat /var/lib/pgsql/10/data/recovery.conf standby_mode = 'on' primary_conninfo = 'application_name=pgsql_node_0 host=postgres1 port=5432 user=replication password=****' recovery_target_timeline = 'latest' trigger_file = '/tmp/failover.trigger' bash-4.2$ touch /tmp/failover.trigger
Para implementar una estrategia de conmutación por error, debemos planificarla y probarla exhaustivamente en diferentes escenarios de falla. Como las fallas pueden ocurrir de diferentes maneras, la solución idealmente debería funcionar para la mayoría de los escenarios comunes. Si estamos buscando una forma de automatizar esto, podemos echar un vistazo a lo que ClusterControl tiene para ofrecer.
ClusterControl para conmutación por error de PostgreSQL
ClusterControl tiene una serie de funciones relacionadas con la replicación de PostgreSQL y la conmutación por error automatizada.
Agregar esclavo
Si queremos agregar un esclavo en otro centro de datos, ya sea como una contingencia o para migrar sus sistemas, podemos ir a Acciones del clúster y seleccionar Agregar esclavo de replicación.
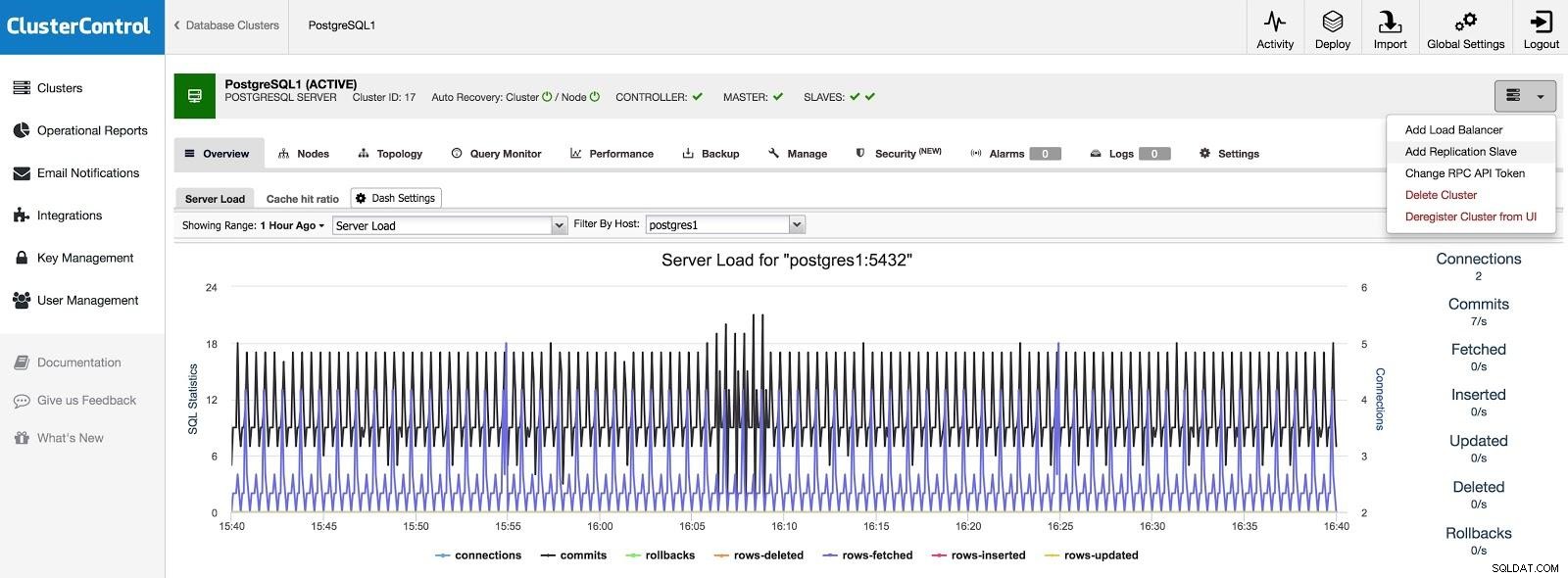 ClusterControl Agregar esclavo 1
ClusterControl Agregar esclavo 1 Necesitaremos ingresar algunos datos básicos, como IP o nombre de host, directorio de datos (opcional), esclavo síncrono o asíncrono. Deberíamos tener nuestro esclavo listo y funcionando después de unos segundos.
En el caso de utilizar otro centro de datos, recomendamos crear un esclavo asíncrono, ya que de lo contrario la latencia puede afectar considerablemente el rendimiento.
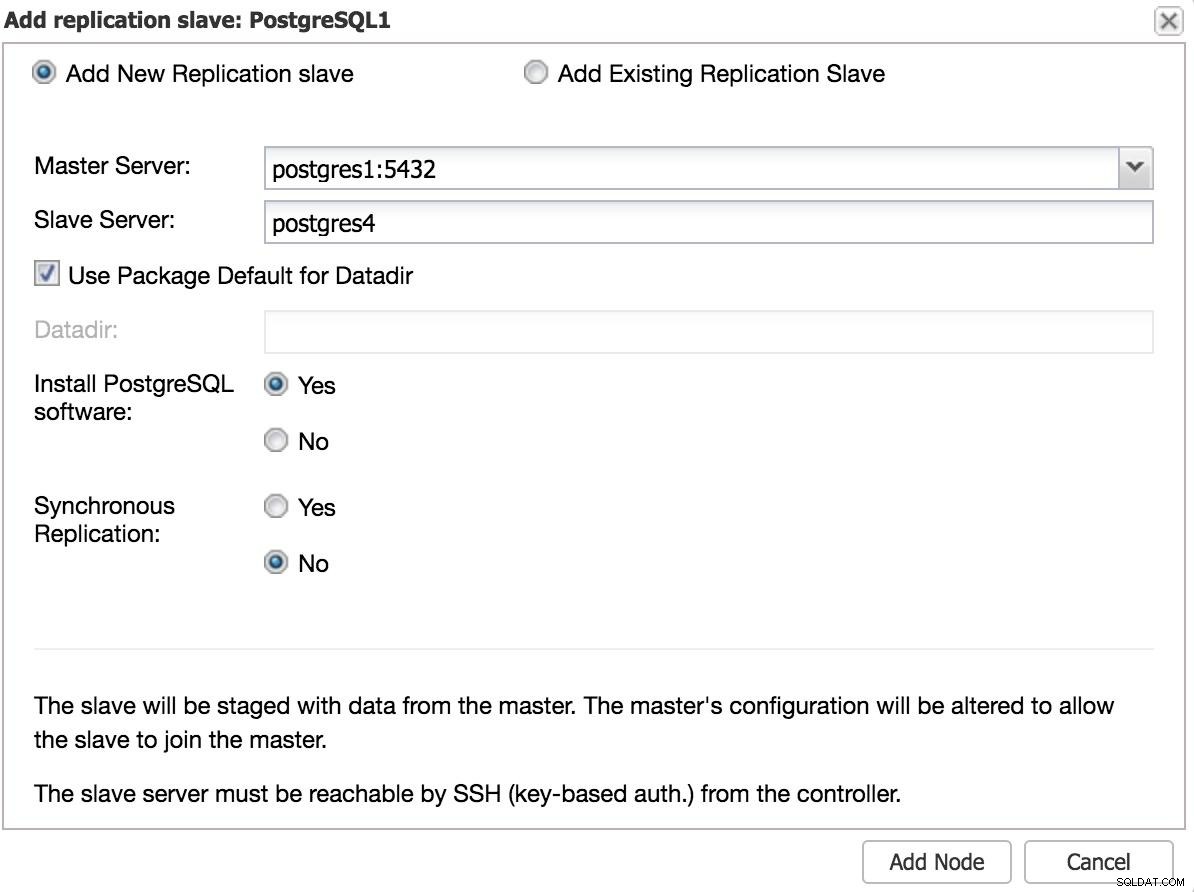 ClusterControl Agregar esclavo 2
ClusterControl Agregar esclavo 2 Conmutación por error manual
Con ClusterControl, la conmutación por error se puede realizar de forma manual o automática.
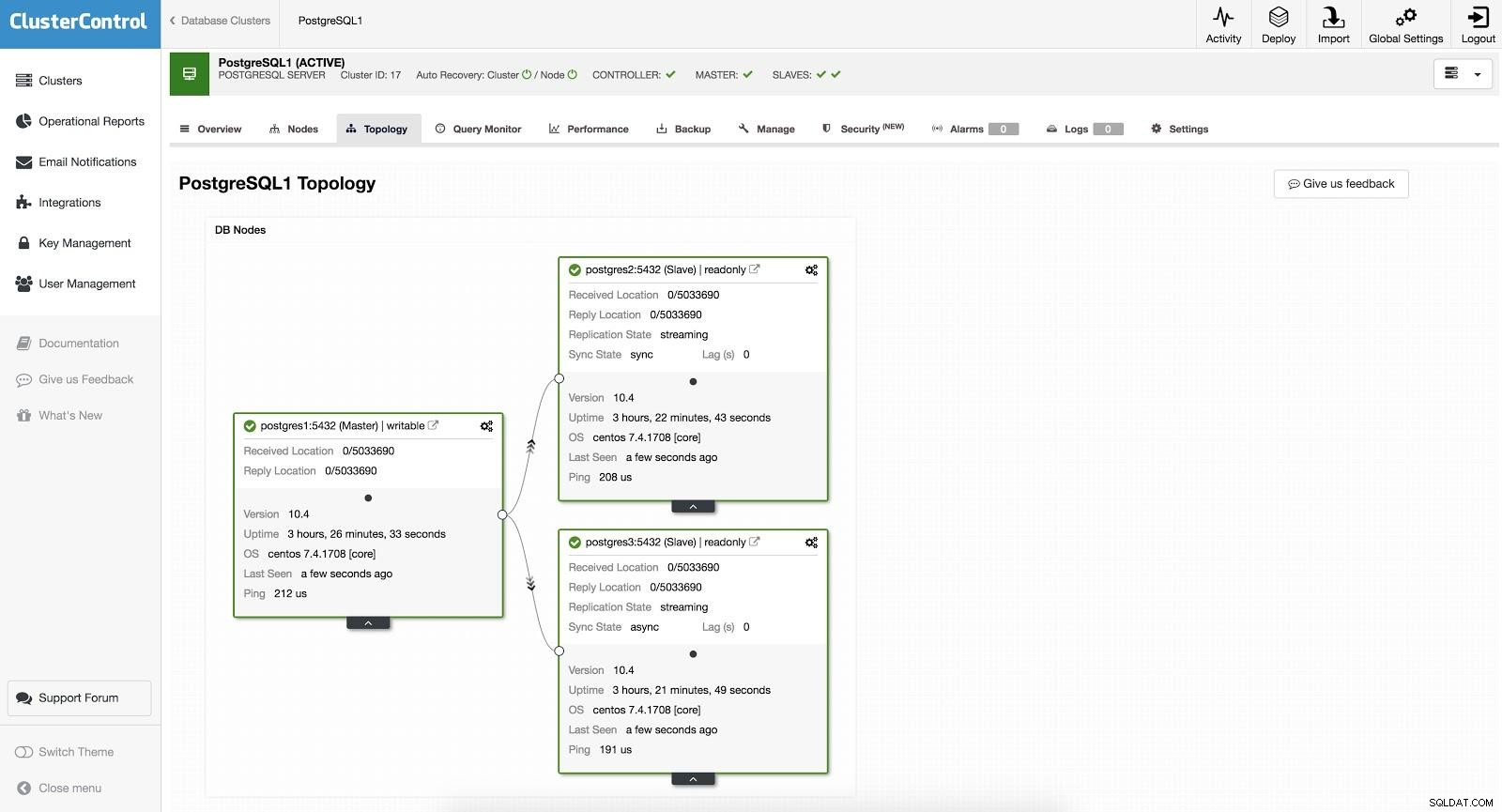 Conmutación por error de ClusterControl 1
Conmutación por error de ClusterControl 1 Para realizar una conmutación por error manual, vaya a ClusterControl -> Seleccionar clúster -> Nodos, y en el Nodo de acción de uno de nuestros esclavos, seleccione "Promocionar esclavo". De esta forma, pasados unos segundos, nuestro esclavo se convierte en amo, y lo que antes era nuestro amo, se convierte en esclavo.
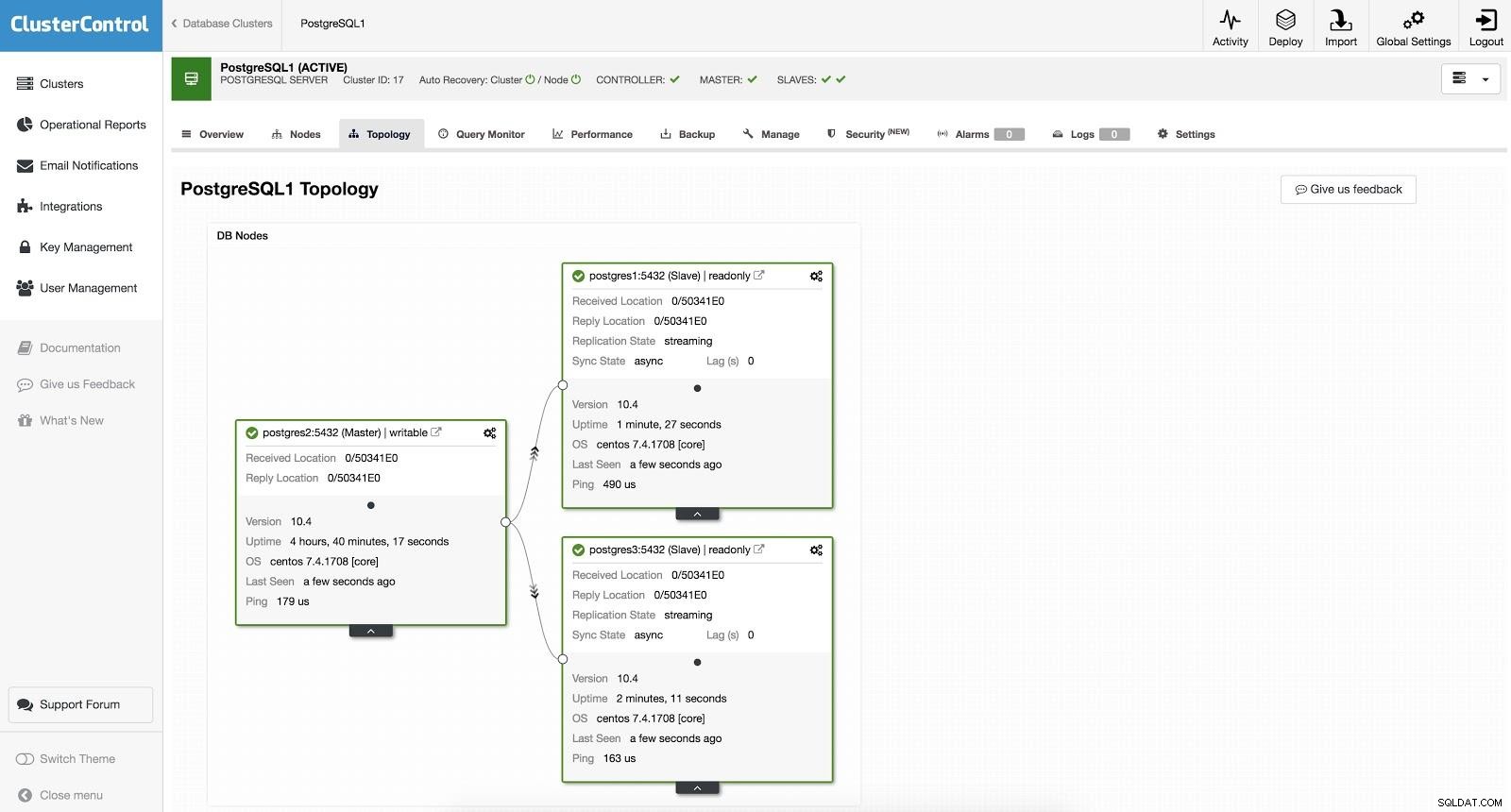 Conmutación por error de ClusterControl 2
Conmutación por error de ClusterControl 2 Lo anterior es útil para las tareas de migración, mantenimiento y actualizaciones que vimos anteriormente.
Conmutación por error automática
En el caso de la conmutación por error automática, ClusterControl detecta fallas en el maestro y promueve un esclavo con los datos más actuales como el nuevo maestro. También funciona en el resto de los esclavos para que se repliquen desde el nuevo maestro.
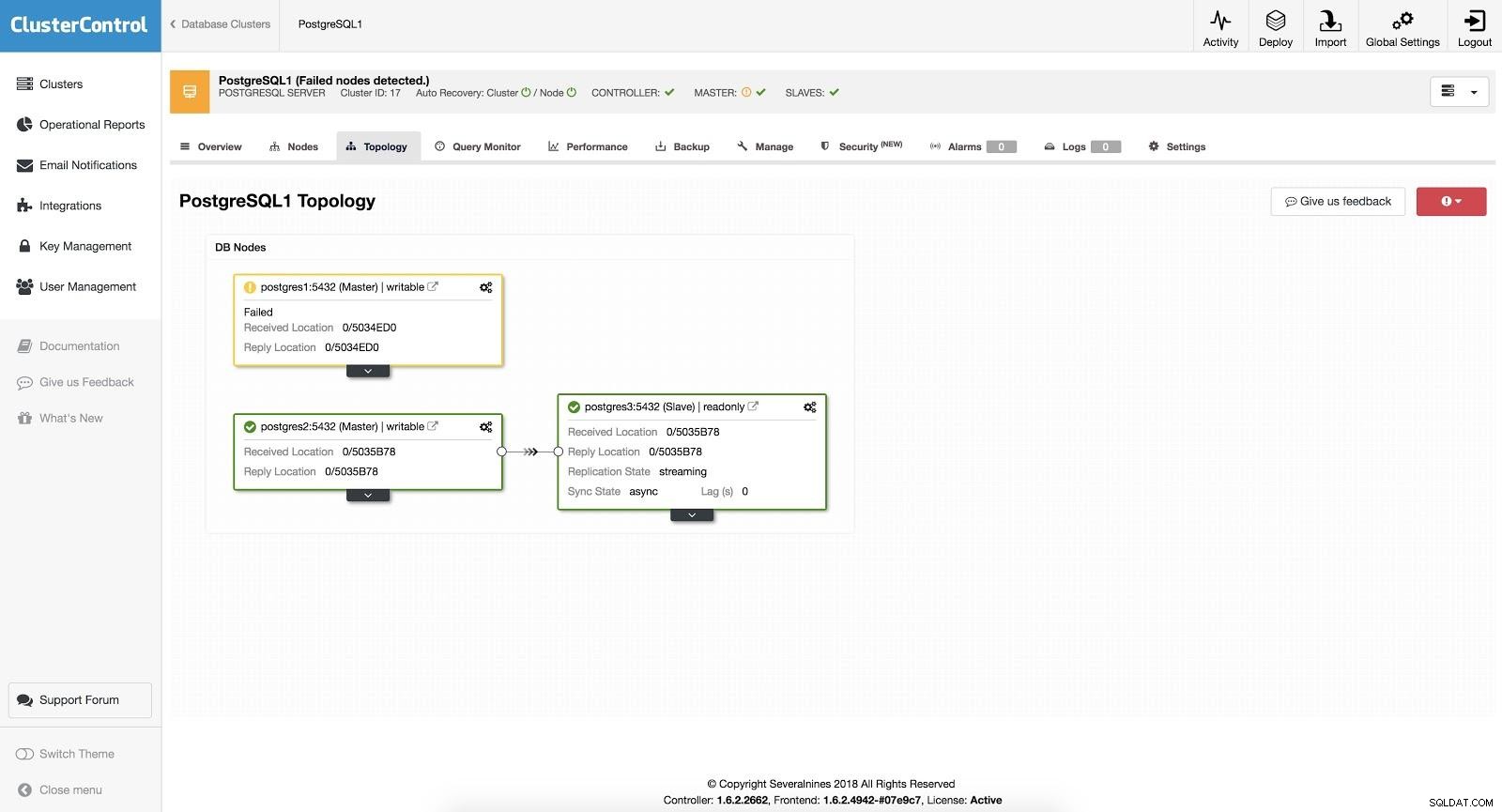 ClusterControl Failover 3
ClusterControl Failover 3 Con la opción "Recuperación automática" activada, nuestro ClusterControl realizará una conmutación por error automática y nos notificará el problema. De esta manera, nuestros sistemas pueden recuperarse en segundos y sin nuestra intervención.
Cluster Control nos ofrece la posibilidad de configurar una lista blanca/lista negra para definir cómo queremos que se tengan (o no) en cuenta nuestros servidores a la hora de decidir sobre un candidato a maestro.
De los disponibles según la configuración anterior, ClusterControl escogerá el esclavo más avanzado, utilizando para ello pg_current_xlog_location (PostgreSQL 9+) o pg_current_wal_lsn (PostgreSQL 10+) dependiendo de la versión de nuestra base de datos.
ClusterControl también realiza varias comprobaciones sobre el proceso de conmutación por error para evitar algunos errores comunes. Un ejemplo es que si logramos recuperar nuestro antiguo maestro fallido, NO se reintroducirá automáticamente al clúster, ni como maestro ni como esclavo. Tenemos que hacerlo manualmente. Esto evitará la posibilidad de pérdida de datos o inconsistencia en el caso de que nuestro esclavo (que promocionamos) se retrasara en el momento de la falla. Es posible que también queramos analizar el problema en detalle, pero al agregarlo a nuestro clúster, es posible que perdamos información de diagnóstico.
Además, si falla la conmutación por error, no se realizan más intentos, se requiere la intervención manual para analizar el problema y realizar las acciones correspondientes. Esto es para evitar la situación en la que ClusterControl, como administrador de alta disponibilidad, intenta promocionar el siguiente esclavo y el siguiente. Es posible que haya un problema y no queremos empeorar las cosas intentando varias conmutaciones por error.
Equilibradores de carga
Como mencionamos anteriormente, el equilibrador de carga es una herramienta importante a tener en cuenta para nuestra conmutación por error, especialmente si queremos utilizar la conmutación por error automática en nuestra topología de base de datos.
Para que la conmutación por error sea transparente tanto para el usuario como para la aplicación, necesitamos un componente intermedio, ya que no es suficiente promover un maestro a un esclavo. Para ello podemos utilizar HAProxy + Keepalived.
¿Qué es HAProxy?
HAProxy es un balanceador de carga que distribuye el tráfico desde un origen a uno o más destinos y puede definir reglas y/o protocolos específicos para esta tarea. Si alguno de los destinos deja de responder, se marca como fuera de línea y el tráfico se envía al resto de destinos disponibles. Esto evita que el tráfico se envíe a un destino inaccesible y evita la pérdida de este tráfico al dirigirlo a un destino válido.
¿Qué es Keepalive?
Keepalived le permite configurar una IP virtual dentro de un grupo de servidores activo/pasivo. Esta IP virtual se asigna a un servidor "Principal" activo. Si este servidor falla, la IP se migra automáticamente al servidor “Secundario” que resultó ser pasivo, lo que le permite seguir trabajando con la misma IP de forma transparente para nuestros sistemas.
Para implementar esta solución con ClusterControl, comenzamos como si fuéramos a agregar un esclavo. Vaya a Acciones del clúster y seleccione Agregar balanceador de carga (consulte la imagen Agregar esclavo 1 de ClusterControl).
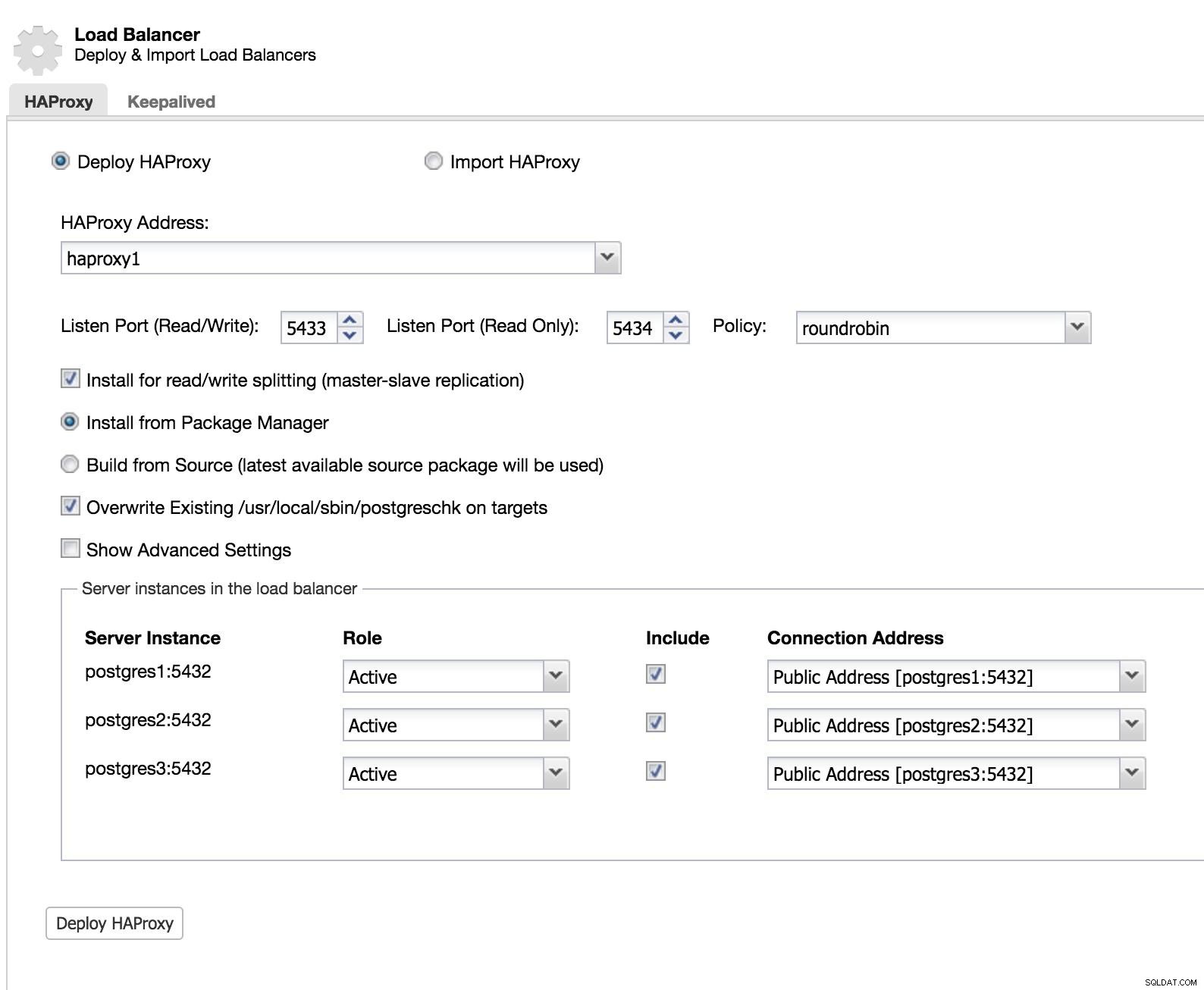 Equilibrador de carga de ClusterControl 1
Equilibrador de carga de ClusterControl 1 Añadimos la información de nuestro nuevo balanceador de carga y cómo queremos que se comporte (Policy).
En el caso de querer implementar failover para nuestro balanceador de carga, debemos configurar al menos dos instancias.
Luego podemos configurar Keepalived (Seleccione Clúster -> Administrar -> Equilibrador de carga -> Keepalived).
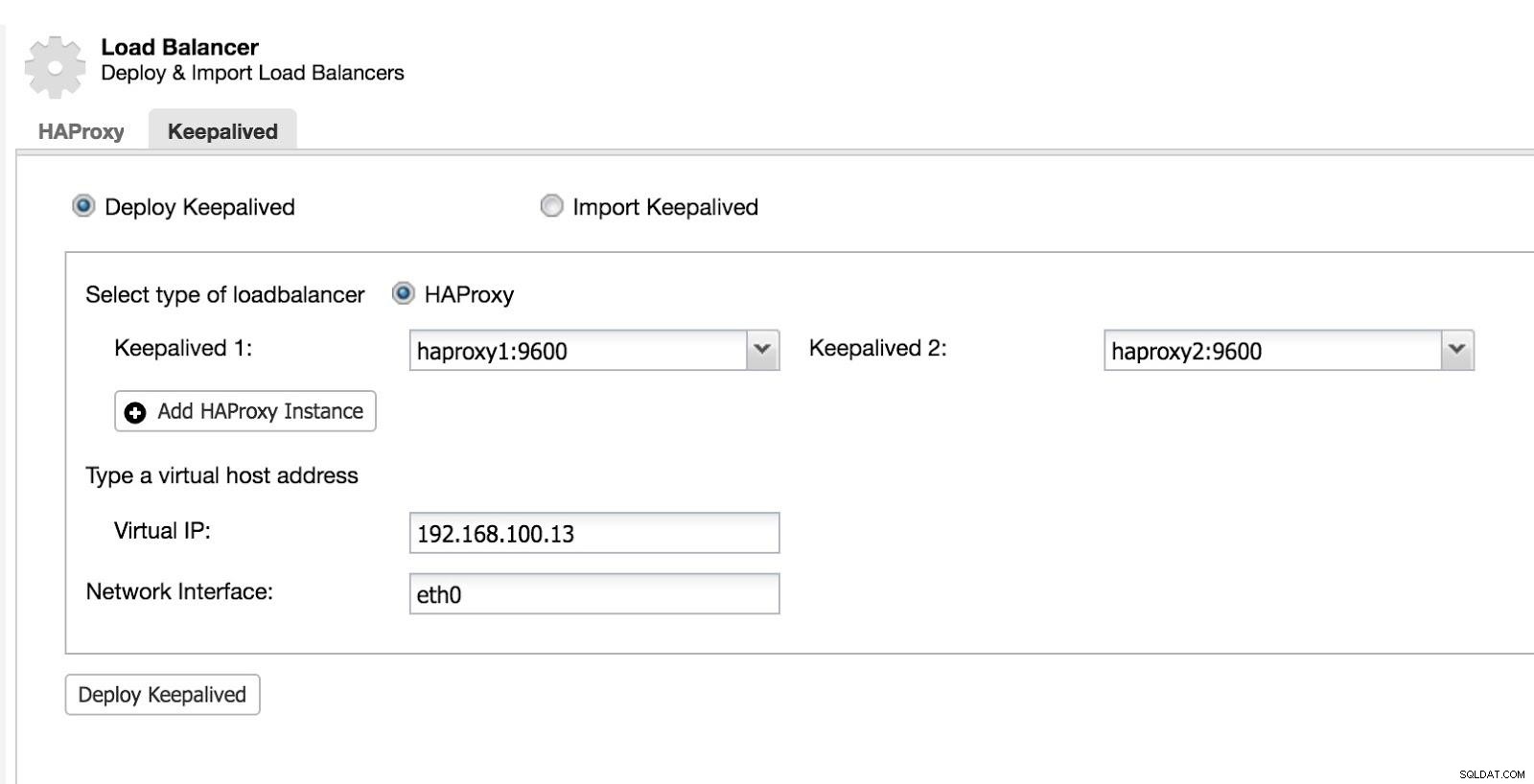 Equilibrador de carga de ClusterControl 2
Equilibrador de carga de ClusterControl 2 Después de esto, tenemos la siguiente topología:
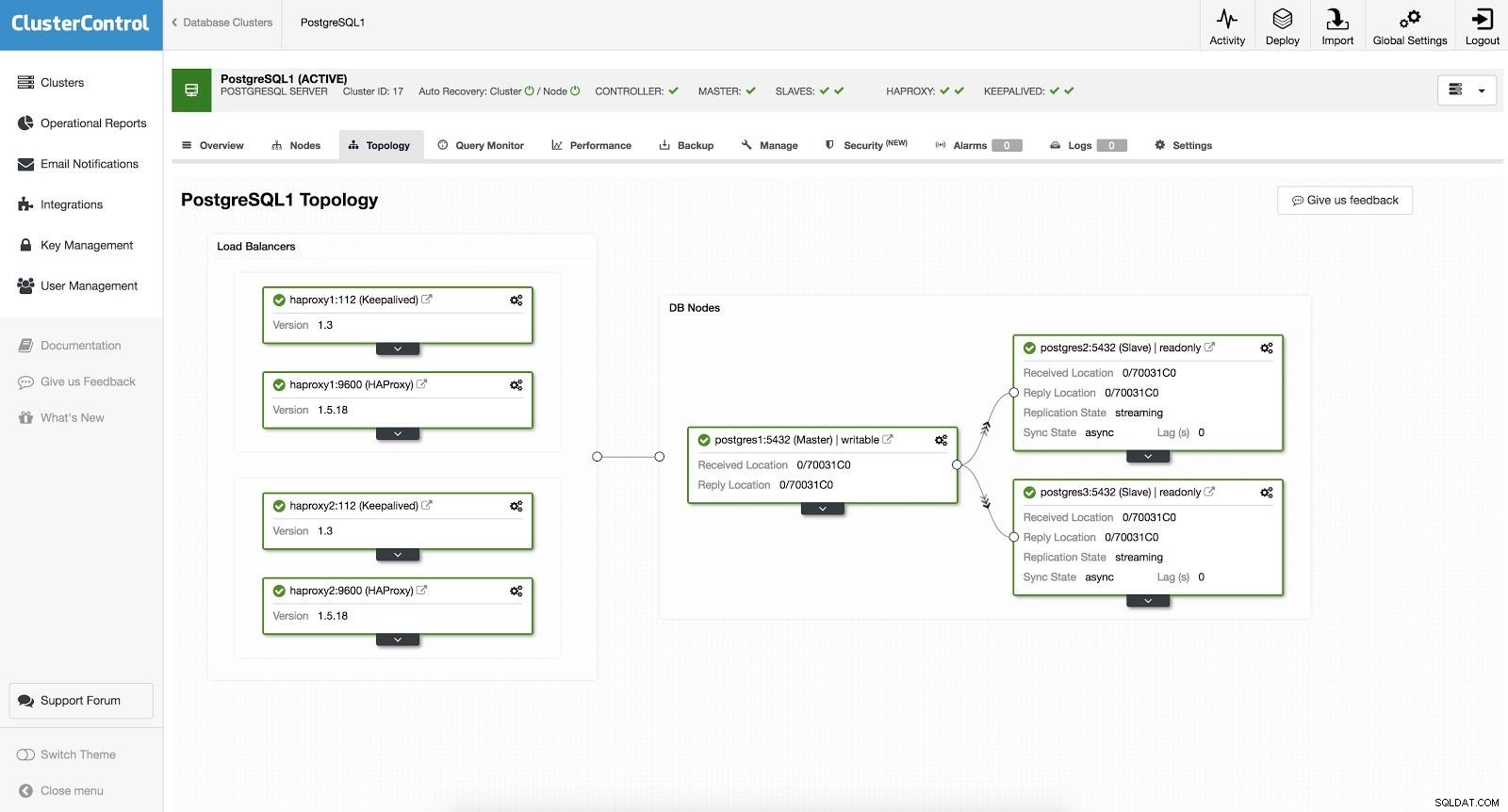 Equilibrador de carga de ClusterControl 3
Equilibrador de carga de ClusterControl 3 HAProxy está configurado con dos puertos diferentes, uno de lectura y escritura y otro de solo lectura.
En nuestro puerto de lectura y escritura, tenemos nuestro servidor maestro en línea y el resto de nuestros nodos en línea. En el puerto de solo lectura, tenemos tanto el maestro como los esclavos en línea. De esta forma podemos equilibrar el tráfico de lectura entre nuestros nodos. Al escribir, se utilizará el puerto de lectura y escritura, que apuntará al maestro.
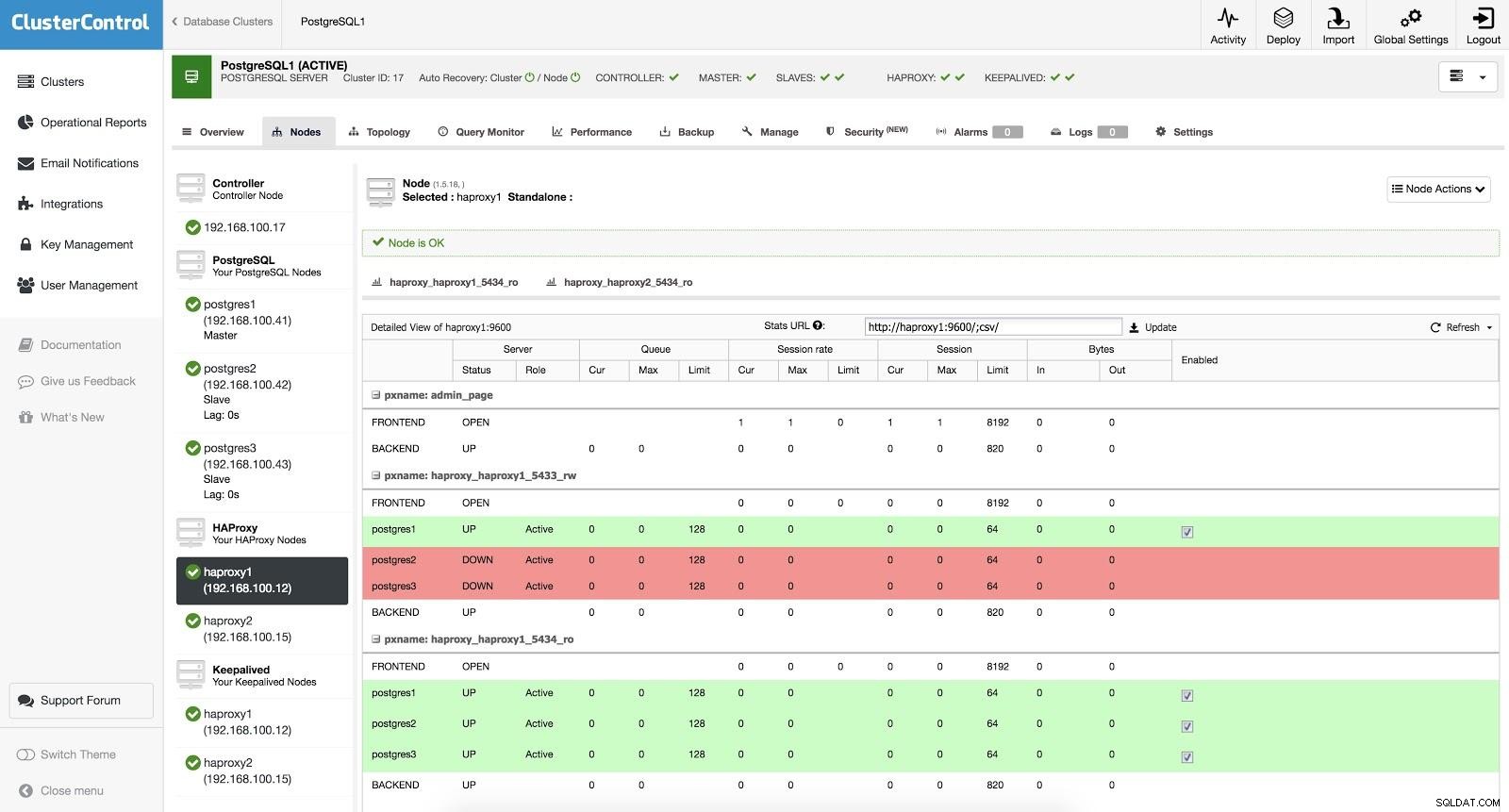 Equilibrador de carga de ClusterControl 3
Equilibrador de carga de ClusterControl 3 Cuando HAProxy detecta que uno de nuestros nodos, ya sea maestro o esclavo, no está accesible, automáticamente lo marca como fuera de línea. HAProxy no le enviará ningún tráfico. Esta verificación se realiza mediante secuencias de comandos de verificación de estado configuradas por ClusterControl en el momento de la implementación. Estos comprueban si las instancias están activas, si se están recuperando o si son de solo lectura.
Cuando ClusterControl promueve un esclavo a maestro, nuestro HAProxy marca al antiguo maestro como fuera de línea (para ambos puertos) y pone el nodo promovido en línea (en el puerto de lectura y escritura). De esta forma, nuestros sistemas siguen funcionando con normalidad.
Si nuestro HAProxy activo (al que se le asigna una dirección IP virtual a la que se conectan nuestros sistemas) falla, Keepalived migra esta IP a nuestro HAProxy pasivo automáticamente. Esto significa que nuestros sistemas pueden continuar funcionando normalmente.
Conclusión
Como pudimos ver, el failover es una parte fundamental de cualquier base de datos de producción. Puede ser útil al realizar tareas comunes de mantenimiento o migraciones. Esperamos que este blog te haya sido útil como introducción al tema, para que puedas seguir investigando y crear tus propias estrategias de failover.