Análisis de parámetros
La parametrización de consultas promueve la reutilización de los planes de ejecución almacenados en caché, lo que evita compilaciones innecesarias y reduce la cantidad de consultas ad-hoc en el caché del plan.
Todas estas son cosas buenas, siempre que la consulta que se parametriza realmente debería usar el mismo plan de ejecución en caché para diferentes valores de parámetros. Un plan de ejecución que es eficiente para un valor de parámetro puede no ser una buena elección para otros posibles valores de parámetros.
Cuando la detección de parámetros está habilitada (valor predeterminado), SQL Server elige un plan de ejecución basado en los valores de parámetros particulares que existen en el momento de la compilación. La suposición implícita es que las declaraciones parametrizadas se ejecutan más comúnmente con los valores de parámetro más comunes. Esto suena bastante razonable (incluso obvio) y, de hecho, a menudo funciona bien.
Puede ocurrir un problema cuando se produce una recompilación automática del plan en caché. Una recompilación puede activarse por todo tipo de razones, por ejemplo, porque se ha descartado un índice utilizado por el plan almacenado en caché (una corrección recompilación) o porque la información estadística ha cambiado (una optimidad recompilar).
Sea cual sea la causa exacta de la recopilación del plan, existe la posibilidad de que un atípico El valor se pasa como parámetro en el momento en que se genera el nuevo plan. Esto puede resultar en un nuevo plan almacenado en caché (basado en el valor de parámetro atípico rastreado) que no es bueno para la mayoría de las ejecuciones para las cuales se reutilizará.
No es fácil predecir cuándo se volverá a compilar un plan de ejecución particular (por ejemplo, porque las estadísticas han cambiado lo suficiente), lo que da como resultado una situación en la que un plan reutilizable de buena calidad puede ser reemplazado repentinamente por un plan bastante diferente optimizado para valores de parámetros atípicos.
Uno de esos escenarios ocurre cuando el valor atípico es altamente selectivo, lo que da como resultado un plan optimizado para una pequeña cantidad de filas. Dichos planes a menudo usarán ejecución de subproceso único, uniones de bucles anidados y búsquedas. Pueden surgir problemas graves de rendimiento cuando este plan se reutiliza para diferentes valores de parámetros que generan una cantidad mucho mayor de filas.
Deshabilitar el rastreo de parámetros
La detección de parámetros se puede deshabilitar mediante el indicador de seguimiento documentado 4136. El indicador de seguimiento también se admite para por consulta usar a través de QUERYTRACEON sugerencia de consulta. Ambos se aplican desde SQL Server 2005 Service Pack 4 en adelante (y un poco antes si aplica actualizaciones acumulativas al Service Pack 3).
A partir de SQL Server 2016, la detección de parámetros también se puede deshabilitar en el nivel de la base de datos , usando el PARAMETER_SNIFFING argumento para ALTER DATABASE SCOPED CONFIGURATION .
Cuando la detección de parámetros está deshabilitada, SQL Server usa una distribución promedio estadísticas para elegir un plan de ejecución.
Esto también suena como un enfoque razonable (y puede ayudar a evitar la situación en la que el plan se optimiza para un valor de parámetro inusualmente selectivo), pero tampoco es una estrategia perfecta:un plan optimizado para un valor 'promedio' bien podría terminar siendo muy por debajo del nivel óptimo para los valores de parámetros comúnmente vistos.
Considere un plan de ejecución que contenga operadores que consuman memoria, como sorts y hashes. Debido a que la memoria está reservada antes de que comience la ejecución de la consulta, un plan parametrizado basado en valores de distribución promedio puede extenderse a tempdb para valores de parámetros comunes que producen más datos de los esperados por el optimizador.
Las reservas de memoria normalmente no pueden aumentar durante la ejecución de consultas, independientemente de la cantidad de memoria libre que tenga el servidor. Ciertas aplicaciones se benefician al desactivar la detección de parámetros (consulte esta publicación de archivo del equipo de rendimiento de Dynamics AX para ver un ejemplo).
Para la mayoría de las cargas de trabajo, deshabilitar por completo la detección de parámetros es la solución incorrecta. , e incluso puede ser un desastre. La detección de parámetros es una optimización heurística:funciona mejor que usar valores promedio en la mayoría de los sistemas, la mayor parte del tiempo.
Sugerencias de consulta
SQL Server proporciona una variedad de sugerencias de consulta y otras opciones para ajustar el comportamiento de la detección de parámetros:
- El
OPTIMIZE FOR (@parameter = value)la sugerencia de consulta crea un plan reutilizable basado en un valor específico. OPTIMIZE FOR (@parameter UNKNOWN)usa estadísticas de distribución promedio para un parámetro en particular.OPTIMIZE FOR UNKNOWNusa la distribución promedio para todos los parámetros (mismo efecto que el indicador de seguimiento 4136).- El
WITH RECOMPILELa opción de procedimiento almacenado compila un nuevo plan de procedimiento para cada ejecución. - La
OPTION (RECOMPILE)la sugerencia de consulta compila un nuevo plan para una declaración individual.
La antigua técnica de “ocultación de parámetros” (asignar parámetros de procedimiento a variables locales y hacer referencia a las variables en su lugar) tiene el mismo efecto que especificar OPTIMIZE FOR UNKNOWN . Puede ser útil en instancias anteriores a SQL Server 2008 (el OPTIMIZE FOR la pista era nueva para 2008).
Se podría argumentar que cada La declaración parametrizada debe verificarse en cuanto a la sensibilidad a los valores de los parámetros y dejarse así (si el comportamiento predeterminado funciona bien) o insinuarse explícitamente usando una de las opciones anteriores.
Esto rara vez se hace en la práctica, en parte porque realizar un análisis exhaustivo de todos los valores de parámetros posibles puede llevar mucho tiempo y requiere habilidades bastante avanzadas. cuando ocurren en producción.
Esta falta de análisis previo es probablemente una de las razones principales por las que el sniffing de parámetros tiene una mala reputación. Vale la pena ser consciente de la posibilidad de que surjan problemas y realizar al menos un análisis rápido de las declaraciones que probablemente causen problemas de rendimiento cuando se vuelvan a compilar con un valor de parámetro atípico.
¿Qué es un parámetro?
Algunos dirían que un SELECT la declaración que hace referencia a una variable local es una “sentencia parametrizada” de algún tipo, pero esa no es la definición que usa SQL Server.
Se puede encontrar una indicación razonable de que una instrucción utiliza parámetros mirando las propiedades del plan (consulte la sección Parámetros). pestaña en Sentry One Plan Explorer. O haga clic en el nodo raíz del plan de consulta en SSMS, abra las Propiedades y expanda la Lista de parámetros nodo):
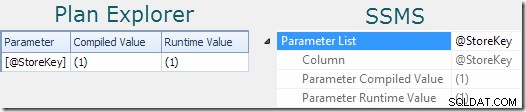
El "valor compilado" muestra el valor rastreado del parámetro utilizado para compilar el plan en caché. El 'valor de tiempo de ejecución' muestra el valor del parámetro en la ejecución particular capturada en el plan.
Cualquiera de estas propiedades puede estar en blanco o faltar en diferentes circunstancias. Si una consulta no está parametrizada, simplemente faltarán todas las propiedades.
Solo porque nada es simple en SQL Server, hay situaciones en las que se puede completar la lista de parámetros, pero la declaración aún no está parametrizada. Esto puede ocurrir cuando SQL Server intenta una parametrización simple (que se analiza más adelante) pero decide que el intento no es "seguro". En ese caso, los marcadores de parámetros estarán presentes, pero el plan de ejecución de hecho no está parametrizado.
El olfatear no es solo para procedimientos almacenados
La detección de parámetros también ocurre cuando un lote se parametriza explícitamente para su reutilización usando sp_executesql .
Por ejemplo:
EXECUTE sys.sp_executesql
N'
SELECT
P.ProductID,
P.Name,
TotalQty = SUM(TH.Quantity)
FROM Production.Product AS P
JOIN Production.TransactionHistory AS TH
ON TH.ProductID = P.ProductID
WHERE
P.Name LIKE @NameLike
GROUP BY
P.ProductID,
P.Name;
',
N'@NameLike nvarchar(50)',
@NameLike = N'K%';
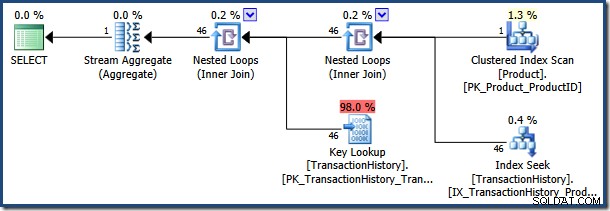
El optimizador elige un plan de ejecución basado en el valor rastreado de @NameLike parámetro. Se estima que el valor del parámetro "K%" coincide con muy pocas filas en el Product tabla, por lo que el optimizador elige una combinación de bucle anidado y una estrategia de búsqueda de clave:

Ejecutar la declaración nuevamente con un valor de parámetro de "[H-R]%" (que coincidirá con muchas más filas) reutiliza el plan parametrizado almacenado en caché:
EXECUTE sys.sp_executesql
N'
SELECT
P.ProductID,
P.Name,
TotalQty = SUM(TH.Quantity)
FROM Production.Product AS P
JOIN Production.TransactionHistory AS TH
ON TH.ProductID = P.ProductID
WHERE
P.Name LIKE @NameLike
GROUP BY
P.ProductID,
P.Name;
',
N'@NameLike nvarchar(50)',
@NameLike = N'[H-R]%';
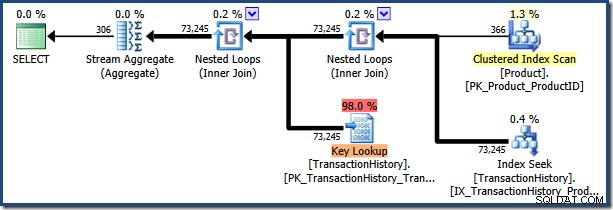

Los AdventureWorks La base de datos de muestra es demasiado pequeña para que esto sea un desastre de rendimiento, pero este plan ciertamente no es óptimo para el valor del segundo parámetro.
Podemos ver el plan que habría elegido el optimizador borrando el caché del plan y ejecutando la segunda consulta nuevamente:
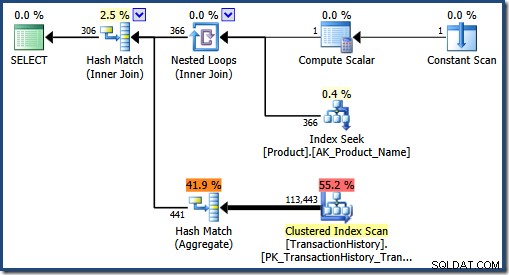

Dado que se espera una mayor cantidad de coincidencias, el optimizador determina que una unión hash y una agregación hash son mejores estrategias.
Funciones T-SQL
La detección de parámetros también ocurre con las funciones T-SQL, aunque la forma en que se generan los planes de ejecución puede hacer que esto sea más difícil de ver.
Hay buenas razones para evitar las funciones escalares y de declaraciones múltiples de T-SQL en general, por lo que solo con fines educativos, aquí hay una versión de nuestra consulta de prueba con función de valores de tabla de declaraciones múltiples de T-SQL:
CREATE FUNCTION dbo.F
(@NameLike nvarchar(50))
RETURNS @Result TABLE
(
ProductID integer NOT NULL PRIMARY KEY,
Name nvarchar(50) NOT NULL,
TotalQty integer NOT NULL
)
WITH SCHEMABINDING
AS
BEGIN
INSERT @Result
SELECT
P.ProductID,
P.Name,
TotalQty = SUM(TH.Quantity)
FROM Production.Product AS P
JOIN Production.TransactionHistory AS TH
ON TH.ProductID = P.ProductID
WHERE
P.Name LIKE @NameLike
GROUP BY
P.ProductID,
P.Name;
RETURN;
END; La siguiente consulta usa la función para mostrar información de los nombres de productos que comienzan con 'K':
SELECT
Result.ProductID,
Result.Name,
Result.TotalQty
FROM dbo.F(N'K%') AS Result; Ver el rastreo de parámetros con una función incrustada es más difícil porque SQL Server no devuelve un plan de consulta posterior a la ejecución (real) independiente para cada invocación de función. La función podría llamarse muchas veces dentro de una sola declaración, y los usuarios no se impresionarían si SSMS intentara mostrar un millón de planes de llamadas de función para una sola consulta.
Como resultado de esta decisión de diseño, el plan real devuelto por SQL Server para nuestra consulta de prueba no es muy útil:
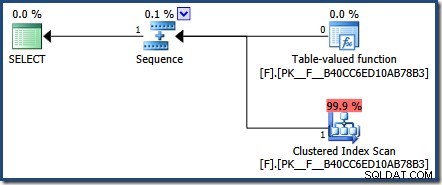
Sin embargo, hay hay formas de ver el rastreo de parámetros en acción con funciones integradas. El método que he elegido usar aquí es inspeccionar el caché del plan:
SELECT
DEQS.plan_generation_num,
DEQS.execution_count,
DEQS.last_logical_reads,
DEQS.last_elapsed_time,
DEQS.last_rows,
DEQP.query_plan
FROM sys.dm_exec_query_stats AS DEQS
CROSS APPLY sys.dm_exec_sql_text(DEQS.plan_handle) AS DEST
CROSS APPLY sys.dm_exec_query_plan(DEQS.plan_handle) AS DEQP
WHERE
DEST.objectid = OBJECT_ID(N'dbo.F', N'TF');
Este resultado muestra que el plan de funciones se ejecutó una vez, a un costo de 201 lecturas lógicas con un tiempo transcurrido de 2891 microsegundos, y la ejecución más reciente devolvió una fila. La representación del plan XML devuelta muestra que el valor del parámetro era olfateó:
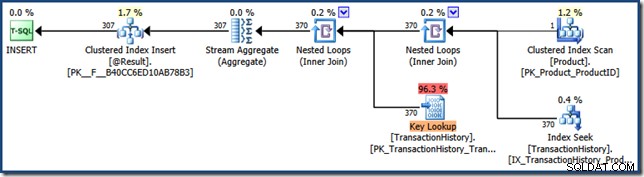

Ahora ejecute la declaración de nuevo, con un parámetro diferente:
SELECT
Result.ProductID,
Result.Name,
Result.TotalQty
FROM dbo.F(N'[H-R]%') AS Result; El plan posterior a la ejecución muestra que la función devolvió 306 filas:
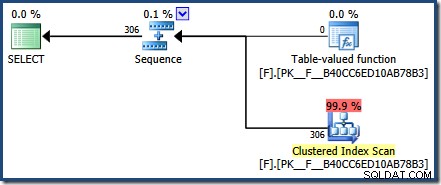
La consulta de caché del plan muestra que se ha reutilizado el plan de ejecución almacenado en caché para la función (execution_count =2):

También muestra un número mucho mayor de lecturas lógicas y un tiempo transcurrido más prolongado en comparación con la ejecución anterior. Esto es coherente con la reutilización de bucles anidados y un plan de búsqueda, pero para estar completamente seguro, el plan de funciones posterior a la ejecución se puede capturar utilizando Eventos extendidos o el Perfilador de SQL Server herramienta:
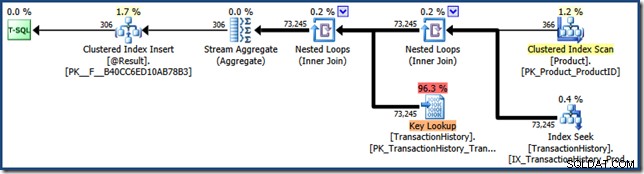

Debido a que el rastreo de parámetros se aplica a las funciones, estos módulos pueden sufrir los mismos cambios inesperados en el rendimiento comúnmente asociados con los procedimientos almacenados.
Por ejemplo, la primera vez que se hace referencia a una función, se puede almacenar en caché un plan que no usa paralelismo. Las ejecuciones posteriores con valores de parámetros que se beneficiarían del paralelismo (pero que reutilizan el plan serial almacenado en caché) mostrarán un rendimiento inesperadamente bajo.
Este problema puede ser complicado de identificar porque SQL Server no devuelve planes posteriores a la ejecución separados para las llamadas a funciones, como hemos visto. Uso de Eventos extendidos o Perfilador capturar rutinariamente los planes posteriores a la ejecución puede requerir muchos recursos, por lo que a menudo tiene sentido usar esa técnica de una manera muy específica. Las dificultades relacionadas con la depuración de los problemas de sensibilidad de los parámetros de la función significan que vale aún más la pena hacer un análisis (y codificar a la defensiva) antes de que la función llegue a la producción.
La detección de parámetros funciona exactamente de la misma manera con las funciones escalares definidas por el usuario de T-SQL (a menos que estén en línea, en SQL Server 2019 en adelante). Las funciones con valores de tabla en línea no generan un plan de ejecución separado para cada invocación, porque (como dice el nombre) están en línea en la consulta de llamada antes de la compilación.
Cuidado con los NULL detectados
Borra la caché del plan y solicita un estimado plan (previo a la ejecución) para la consulta de prueba:
SELECT
Result.ProductID,
Result.Name,
Result.TotalQty
FROM dbo.F(N'K%') AS Result; Verá dos planes de ejecución, el segundo de los cuales es para la llamada de función:
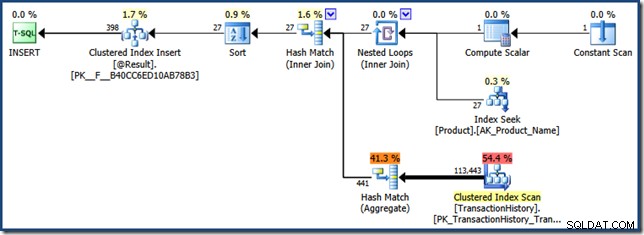
Una limitación de la detección de parámetros con funciones integradas en los planes estimados significa que el valor del parámetro se detecta como NULL (no "K%"):

En versiones de SQL Server anteriores a 2012, este plan (optimizado para un NULL parámetro) se almacena en caché para su reutilización . Esto es desafortunado, porque NULL es poco probable que sea un valor de parámetro representativo, y ciertamente no era el valor especificado en la consulta.
SQL Server 2012 (y versiones posteriores) no almacena en caché los planes resultantes de una solicitud de "plan estimado", aunque seguirá mostrando un plan de funciones optimizado para un NULL valor del parámetro en tiempo de compilación.
Parametrización Simple y Forzada
SQL Server puede parametrizar una declaración T-SQL ad-hoc que contiene valores literales constantes, ya sea porque la consulta califica para la parametrización simple o porque la opción de base de datos para la parametrización forzada está habilitada (o se usa una guía de plan con el mismo efecto).
Una declaración parametrizada de esta manera también está sujeta a un rastreo de parámetros. La siguiente consulta califica para la parametrización simple:
SELECT
A.AddressLine1,
A.City,
A.PostalCode
FROM Person.Address AS A
WHERE
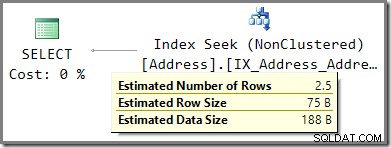
A.AddressLine1 = N'Heidestieg Straße 8664'; El plan de ejecución estimado muestra una estimación de 2,5 filas según el valor del parámetro rastreado:
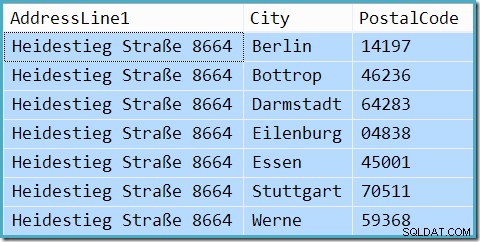
De hecho, la consulta devuelve 7 filas (la estimación de la cardinalidad no es perfecta, incluso cuando se rastrean los valores):
En este punto, es posible que se pregunte dónde está la evidencia de que esta consulta se parametrizó y se olió el valor del parámetro resultante. Ejecute la consulta por segunda vez con un valor diferente:
SELECT
A.AddressLine1,
A.City,
A.PostalCode
FROM Person.Address AS A
WHERE
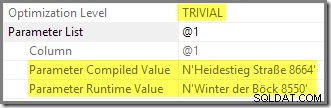
A.AddressLine1 = N'Winter der Böck 8550'; La consulta devuelve una fila:

El plan de ejecución muestra que la segunda ejecución reutilizó el plan parametrizado que se compiló usando un valor rastreado:
La parametrización y el olfateo son actividades separadas
SQL Server puede parametrizar una declaración ad-hoc sin valores de parámetros que se están olfateando.
Para demostrarlo, podemos usar el indicador de rastreo 4136 para deshabilitar el rastreo de parámetros para un lote que será parametrizado por el servidor:
DBCC FREEPROCCACHE;
DBCC TRACEON (4136);
GO
SELECT
A.AddressLine1,
A.City,
A.PostalCode
FROM Person.Address AS A
WHERE
A.AddressLine1 = N'Heidestieg Straße 8664';
GO
SELECT
A.AddressLine1,
A.City,
A.PostalCode
FROM Person.Address AS A
WHERE
A.AddressLine1 = N'Winter der Böck 8550';
GO
DBCC TRACEOFF (4136); La secuencia de comandos da como resultado declaraciones que están parametrizadas, pero el valor del parámetro no se detecta con fines de estimación de cardinalidad. Para ver esto, podemos inspeccionar el caché del plan:
WITH XMLNAMESPACES
(DEFAULT 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
SELECT
DECP.cacheobjtype,
DECP.objtype,
DECP.usecounts,
DECP.plan_handle,
parameterized_plan_handle =
DEQP.query_plan.value
(
'(//StmtSimple)[1]/@ParameterizedPlanHandle',
'NVARCHAR(100)'
)
FROM sys.dm_exec_cached_plans AS DECP
CROSS APPLY sys.dm_exec_sql_text(DECP.plan_handle) AS DEST
CROSS APPLY sys.dm_exec_query_plan(DECP.plan_handle) AS DEQP
WHERE
DEST.[text] LIKE N'%AddressLine1%'
AND DEST.[text] NOT LIKE N'%XMLNAMESPACES%'; Los resultados muestran dos entradas de caché para las consultas ad-hoc, vinculadas al plan de consulta parametrizado (preparado) por el identificador del plan parametrizado.
El plan parametrizado se usa dos veces:

El plan de ejecución muestra una estimación de cardinalidad diferente ahora que el rastreo de parámetros está deshabilitado:
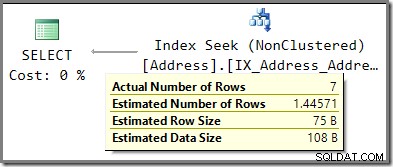
Compare la estimación de 1,44571 filas con la estimación de 2,5 filas utilizada cuando se habilitó el rastreo de parámetros.
Con el rastreo deshabilitado, la estimación proviene de la información de frecuencia promedio sobre AddressLine1 columna. Un extracto del DBCC SHOW_STATISTICS la salida para el índice en cuestión muestra cómo se calculó este número:multiplicar el número de filas en la tabla (19,614) por la densidad (7.370826e-5) da la estimación de 1.44571 filas.
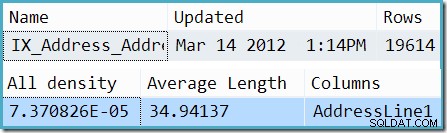
Nota al margen: Se cree comúnmente que solo las comparaciones de enteros que utilizan un índice único pueden calificar para una parametrización simple. Deliberadamente elegí este ejemplo (una comparación de cadenas usando un índice no único) para refutar eso.
CON RECOMPILE y OPTION (RECOMPILE)
Cuando se encuentra un problema de sensibilidad de parámetros, un consejo común en foros y sitios de preguntas y respuestas es "usar la recompilación" (suponiendo que las otras opciones de ajuste presentadas anteriormente no sean adecuadas). Desafortunadamente, ese consejo a menudo se malinterpreta y significa agregar WITH RECOMPILE opción al procedimiento almacenado.
Usando WITH RECOMPILE nos devuelve efectivamente al comportamiento de SQL Server 2000, donde el procedimiento almacenado completo se vuelve a compilar en cada ejecución.
Una mejor alternativa , en SQL Server 2005 y posterior, es usar la OPTION (RECOMPILE) sugerencia de consulta solo sobre la declaración que sufre el problema de detección de parámetros. Esta sugerencia de consulta da como resultado una recopilación de la declaración problemática solamente. Los planes de ejecución para otras declaraciones dentro del procedimiento almacenado se almacenan en caché y se reutilizan normalmente.
Usando WITH RECOMPILE también significa que el plan compilado para el procedimiento almacenado no se almacena en caché. Como resultado, no se mantiene información de rendimiento en DMV como sys.dm_exec_query_stats .
El uso de la sugerencia de consulta significa que un plan compilado se puede almacenar en caché y la información de rendimiento está disponible en los DMV (aunque se limita a la ejecución más reciente, solo para la declaración afectada).
Para instancias que ejecutan al menos SQL Server 2008 compilación 2746 (Service Pack 1 con actualización acumulativa 5), usando OPTION (RECOMPILE) tiene otra ventaja significativa sobre WITH RECOMPILE :Solo OPTION (RECOMPILE) habilita la optimización de incrustación de parámetros .
La optimización de incrustación de parámetros
La detección de los valores de los parámetros permite al optimizador utilizar el valor del parámetro para derivar estimaciones de cardinalidad. Ambos WITH RECOMPILE y OPTION (RECOMPILE) dan como resultado planes de consulta con estimaciones calculadas a partir de los valores reales de los parámetros en cada ejecución.
La optimización de incrustación de parámetros lleva este proceso un paso más allá. Los parámetros de consulta se reemplazan con valores constantes literales durante el análisis de consultas.
El analizador es capaz de simplificaciones sorprendentemente complejas, y la posterior optimización de consultas puede refinar las cosas aún más. Considere el siguiente procedimiento almacenado, que incluye WITH RECOMPILE opción:
CREATE PROCEDURE dbo.P
@NameLike nvarchar(50),
@Sort tinyint
WITH RECOMPILE
AS
BEGIN
SELECT TOP (5)
ProductID,
Name
FROM Production.Product
WHERE
@NameLike IS NULL
OR Name LIKE @NameLike
ORDER BY
CASE WHEN @Sort = 1 THEN ProductID ELSE NULL END ASC,
CASE WHEN @Sort = 2 THEN ProductID ELSE NULL END DESC,
CASE WHEN @Sort = 3 THEN Name ELSE NULL END ASC,
CASE WHEN @Sort = 4 THEN Name ELSE NULL END DESC;
END; El procedimiento se ejecuta dos veces, con los siguientes valores de parámetro:
EXECUTE dbo.P @NameLike = N'K%', @Sort = 1; GO EXECUTE dbo.P @NameLike = N'[H-R]%', @Sort = 4;
Porque WITH RECOMPILE se utiliza, el procedimiento se vuelve a compilar completamente en cada ejecución. Los valores de los parámetros son olfateados cada vez, y lo utiliza el optimizador para calcular estimaciones de cardinalidad.
El plan para la ejecución del primer procedimiento es exactamente correcto, estimando 1 fila:
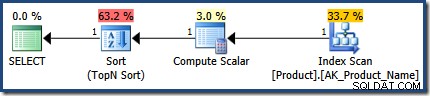
La segunda ejecución estima 360 filas, muy cerca de las 366 vistas en tiempo de ejecución:
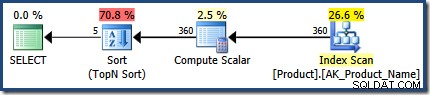
Ambos planes usan la misma estrategia de ejecución general:escanear todas las filas en un índice, aplicando el WHERE predicado de la cláusula como residual; calcular el CASE expresión utilizada en el ORDER BY cláusula; y realice una clasificación N superior sobre el resultado del CASE expresión.
OPCIÓN (RECOMPILAR)
Ahora vuelva a crear el procedimiento almacenado usando una OPTION (RECOMPILE) sugerencia de consulta en lugar de WITH RECOMPILE :
CREATE PROCEDURE dbo.P
@NameLike nvarchar(50),
@Sort tinyint
AS
BEGIN
SELECT TOP (5)
ProductID,
Name
FROM Production.Product
WHERE
@NameLike IS NULL
OR Name LIKE @NameLike
ORDER BY
CASE WHEN @Sort = 1 THEN ProductID ELSE NULL END ASC,
CASE WHEN @Sort = 2 THEN ProductID ELSE NULL END DESC,
CASE WHEN @Sort = 3 THEN Name ELSE NULL END ASC,
CASE WHEN @Sort = 4 THEN Name ELSE NULL END DESC
OPTION (RECOMPILE);
END; Ejecutar el procedimiento almacenado dos veces con los mismos valores de parámetro que antes produce dramáticamente diferente planes de ejecución.
Este es el primer plan de ejecución (con parámetros que solicitan nombres que comienzan con "K", ordenados por ProductID ascendente):
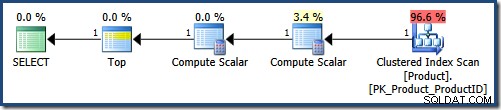
El analizador incrusta los valores de los parámetros en el texto de la consulta, lo que da como resultado la siguiente forma intermedia:
SELECT TOP (5)
ProductID,
Name
FROM Production.Product
WHERE
'K%' IS NULL
OR Name LIKE 'K%'
ORDER BY
CASE WHEN 1 = 1 THEN ProductID ELSE NULL END ASC,
CASE WHEN 1 = 2 THEN ProductID ELSE NULL END DESC,
CASE WHEN 1 = 3 THEN Name ELSE NULL END ASC,
CASE WHEN 1 = 4 THEN Name ELSE NULL END DESC;
El analizador luego va más allá, eliminando contradicciones y evaluando completamente el CASE expresiones Esto resulta en:
SELECT TOP (5)
ProductID,
Name
FROM Production.Product
WHERE
Name LIKE 'K%'
ORDER BY
ProductID ASC,
NULL DESC,
NULL ASC,
NULL DESC; Recibirá un mensaje de error si intenta enviar esa consulta directamente a SQL Server, porque no se permite ordenar por un valor constante. Sin embargo, esta es la forma producida por el analizador. Está permitido internamente porque surgió como resultado de aplicar la optimización de incrustación de parámetros . La consulta simplificada hace la vida mucho más fácil para el optimizador de consultas:
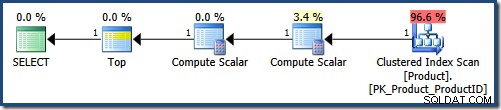
El Análisis de índice agrupado aplica el LIKE predicado como un residuo. El cálculo escalar proporciona la constante NULL valores. La parte superior devuelve las primeras 5 filas en el orden proporcionado por el Índice agrupado (evitando una especie). En un mundo perfecto, el optimizador de consultas también eliminaría el Compute Scalar que define los NULLs , ya que no se utilizan durante la ejecución de la consulta.
La segunda ejecución sigue exactamente el mismo proceso, dando como resultado un plan de consulta (para nombres que comienzan con las letras "H" a "R", ordenados por Name descendente) así:

Este plan incluye una búsqueda de índice no agrupado que cubre el LIKE rango, un LIKE residual predicado, la constante NULLs como antes, y un Top (5). El optimizador de consultas elige realizar un BACKWARD escaneo de rango en la búsqueda de índice para evitar una vez más la clasificación.
Compare el plan anterior con el producido usando WITH RECOMPILE , que no puede usar la optimización de incrustación de parámetros :
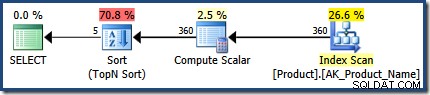
Este ejemplo de demostración podría haberse implementado mejor como una serie de IF sentencias en el procedimiento (una para cada combinación de valores de parámetro). Esto podría proporcionar beneficios de plan de consulta similares, sin incurrir en una compilación de estados de cuenta cada vez. En escenarios más complejos, la recompilación a nivel de declaración con incrustación de parámetros proporcionada por OPTION (RECOMPILE) puede ser una técnica de optimización extremadamente útil.
Una restricción de incrustación
Hay un escenario en el que se usa OPTION (RECOMPILE) no dará como resultado que se aplique la optimización de incrustación de parámetros. Si la sentencia se asigna a una variable, los valores de los parámetros no están incrustados:
CREATE PROCEDURE dbo.P
@NameLike nvarchar(50),
@Sort tinyint
AS
BEGIN
DECLARE
@ProductID integer,
@Name nvarchar(50);
SELECT TOP (1)
@ProductID = ProductID,
@Name = Name
FROM Production.Product
WHERE
@NameLike IS NULL
OR Name LIKE @NameLike
ORDER BY
CASE WHEN @Sort = 1 THEN ProductID ELSE NULL END ASC,
CASE WHEN @Sort = 2 THEN ProductID ELSE NULL END DESC,
CASE WHEN @Sort = 3 THEN Name ELSE NULL END ASC,
CASE WHEN @Sort = 4 THEN Name ELSE NULL END DESC
OPTION (RECOMPILE);
END;
Porque el SELECT instrucción ahora se asigna a una variable, los planes de consulta producidos son los mismos que cuando WITH RECOMPILE se utilizó. Los valores de los parámetros aún son rastreados y utilizados por el optimizador de consultas para la estimación de cardinalidad, y OPTION (RECOMPILE) todavía solo compila la declaración única, solo el beneficio de la incrustación de parámetros está perdido.



