En este artículo, nos centraremos en el análisis operativo en tiempo real y cómo aplicar este enfoque a una base de datos OLTP. Cuando observamos el modelo analítico tradicional, podemos ver que OLTP y los entornos analíticos son estructuras separadas. En primer lugar, los entornos de modelos analíticos tradicionales necesitan crear tareas ETL (Extraer, Transformar y Cargar). Porque necesitamos transferir datos transaccionales al almacén de datos. Estos tipos de arquitectura tienen algunas desventajas. Son el costo, la complejidad y la latencia de los datos. Para eliminar estas desventajas, necesitamos un enfoque diferente.
Análisis operativo en tiempo real
Microsoft anunció Real-Time Operational Analytics en SQL Server 2016. La capacidad de esta función es combinar la base de datos transaccional y la carga de trabajo de consultas analíticas sin ningún problema de rendimiento. Real-Time Operational Analytics proporciona:
- estructura híbrida
- Las consultas transaccionales y de análisis se pueden ejecutar al mismo tiempo
- no causa ningún problema de rendimiento o latencia.
- una implementación sencilla.
Esta función puede superar las desventajas del entorno analítico tradicional. El tema principal de esta función es que el índice de almacenamiento de columnas mantiene una copia de los datos sin afectar el rendimiento del sistema transaccional. Este tema permite que las consultas analíticas se ejecuten sin afectar el rendimiento. Así que esto minimiza el impacto en el rendimiento. La principal limitación de esta función es que no podemos recopilar datos de diferentes fuentes de datos.
Índice de almacén de columnas no agrupadas
SQL Server 2016 presenta el "Índice de almacenamiento de columnas no agrupadas" actualizable. El índice de almacenamiento de columnas no agrupadas es un índice basado en columnas que proporciona beneficios de rendimiento para consultas analíticas. Esta característica nos permite crear el marco de análisis operativo en tiempo real. Eso significa que podemos ejecutar transacciones y consultas analíticas al mismo tiempo. Considere que necesitamos las ventas totales mensuales. En un modelo tradicional, tenemos que desarrollar tareas ETL, data mart y data warehouse. Pero en el análisis operativo en tiempo real, podemos hacerlo sin necesidad de ningún almacén de datos ni cambios en la estructura de OLTP. Solo necesitamos crear un índice de almacén de columnas no agrupado adecuado.
Arquitectura del índice de almacén de columnas no agrupadas
Veamos brevemente la arquitectura del índice de almacén de columnas no agrupadas y el mecanismo de ejecución. El índice de almacén de columnas no agrupadas contiene una copia de una parte o de todas las filas y columnas de la tabla subyacente. El tema principal del índice de almacenamiento de columnas no agrupadas es mantener una copia de los datos y usar esta copia de datos. Por lo tanto, este mecanismo minimiza el impacto en el rendimiento de la base de datos transaccional. El índice de almacenamiento de columnas no agrupadas puede crear una o más columnas y puede aplicar un filtro a las columnas.
Cuando insertamos una nueva fila en una tabla que tiene un índice de almacén de columnas no agrupadas, en primer lugar, SQL Server crea un "grupo de filas". Rowgroup es una estructura lógica que representa un conjunto de filas. Luego, SQL Server almacena estas filas en un almacenamiento temporal. El nombre de este almacenamiento temporal es "deltastore". SQL Server usa esta área de almacenamiento temporal porque este mecanismo mejora la relación de compresión y reduce la fragmentación del índice. Cuando el número de filas llega a 1 048 577, SQL Server cierra el estado del grupo de filas. SQL Server comprime este grupo de filas y cambia el estado a "comprimido".
Ahora, crearemos una tabla y agregaremos el índice de almacenamiento de columnas no agrupadas.
DROP TABLE IF EXISTS Analysis_TableTest CREATE TABLE Analysis_TableTest (ID INT PRIMARY KEY IDENTITY(1,1), Continent_Name VARCHAR(20), Country_Name VARCHAR(20), City_Name VARCHAR(20), Sales_Amnt INT, Profit_Amnt INT) GO
CREATE NONCLUSTERED COLUMNSTORE INDEX [NonClusteredColumnStoreIndex] ON [dbo].[Analysis_TableTest]
(
[Country_Name],
[City_Name] ,
Sales_Amnt
)WITH (DROP_EXISTING = OFF, COMPRESSION_DELAY = 0) ON [PRIMARY]
En este paso, insertaremos varias filas y veremos las propiedades del índice de almacén de columnas no agrupadas.
INSERT INTO Analysis_TableTest VALUES('Europe','Germany','Munich','100','12')
INSERT INTO Analysis_TableTest VALUES('Europe','Turkey','Istanbul','200','24')
INSERT INTO Analysis_TableTest VALUES('Europe','France','Paris','190','23')
INSERT INTO Analysis_TableTest VALUES('America','USA','Newyork','180','19')
INSERT INTO Analysis_TableTest VALUES('Asia','Japan','Tokyo','190','17')
GO
Esta consulta mostrará los estados del grupo de filas, el número total de tamaño de filas y otros valores.
SELECT i.object_id, object_name(i.object_id) AS TableName,
i.name AS IndexName, i.index_id, i.type_desc,
CSRowGroups.*,
100*(total_rows - ISNULL(deleted_rows,0))/total_rows AS PercentFull
FROM sys.indexes AS i
JOIN sys.column_store_row_groups AS CSRowGroups
ON i.object_id = CSRowGroups.object_id
AND i.index_id = CSRowGroups.index_id
ORDER BY object_name(i.object_id), i.name, row_group_id;

La imagen de arriba nos muestra el estado deltastore y el número total de filas que no están comprimidas. Ahora completaremos más datos en la tabla y cuando el número de filas llegue a 1 048 577, SQL Server cerrará el primer grupo de filas y abrirá un nuevo grupo de filas.
INSERT INTO Analysis_TableTest VALUES('Europe','Germany','Munich','100','12')
INSERT INTO Analysis_TableTest VALUES('Europe','Turkey','Istanbul','200','24')
INSERT INTO Analysis_TableTest VALUES('Europe','France','Paris','190','23')
INSERT INTO Analysis_TableTest VALUES('America','USA','Newyork','180','19')
INSERT INTO Analysis_TableTest VALUES('Asia','Japan','Tokyo','190','17')
GO 2000000

SQL Server comprimirá este grupo de filas y creará un nuevo grupo de filas. La opción "COMPRESSION_DELAY" nos permite controlar cuánto tiempo espera el grupo de filas en el estado cerrado.

Cuando ejecutamos los comandos de mantenimiento del índice (reorganizar, reconstruir), las filas eliminadas se eliminan físicamente y el índice se desfragmenta.

Cuando actualizamos (eliminar + insertar) algunas filas en esta tabla, las filas eliminadas se marcan como "eliminadas" y las nuevas filas actualizadas se insertan en el almacén delta.
Comparativa de rendimiento de consultas analíticas
En este encabezado, completaremos los datos en la tabla Analysis_TableTest. Inserté 4 millones de registros. (Debe probar este paso y los próximos pasos en su entorno de prueba. Pueden ocurrir problemas de rendimiento y también el comando DBCC DROPCLEANBUFFERS puede dañar el rendimiento. Este comando eliminará todos los datos del búfer en el grupo de búfer).
Ahora ejecutaremos la siguiente consulta analítica y examinaremos los valores de rendimiento.
SET STATISTICS TIME ON SET STATISTICS IO ON DBCC DROPCLEANBUFFERS select Country_Name , City_Name ,SUM(CAST(Sales_Amnt AS Float)) AS [Sales Amount] from Analysis_TableTest group by Country_Name ,City_Name

En la imagen de arriba, podemos ver el operador de escaneo de índice de almacenamiento de columna no agrupado. La siguiente tabla muestra los tiempos de CPU y ejecución. Esta consulta consume 1,765 milisegundos de CPU y se completa en 0,791 milisegundos. El tiempo de CPU es mayor que el tiempo transcurrido porque el plan de ejecución usa procesadores paralelos y distribuye tareas a 4 procesadores. Podemos verlo en las propiedades del operador "Columnstore Index Scan". El valor “Número de ejecuciones” así lo indica.

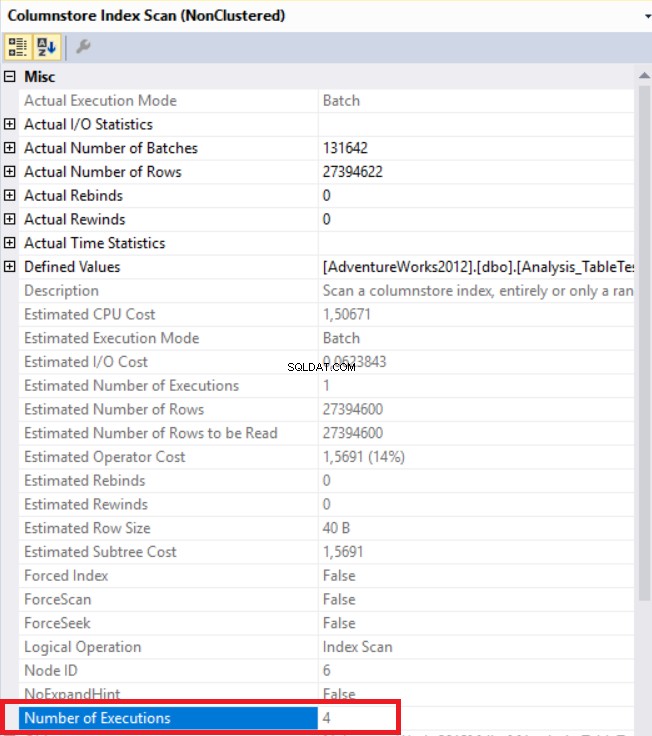
Ahora agregaremos una sugerencia a la consulta para reducir la cantidad de procesadores. No veremos ningún operador de paralelismo.
SET STATISTICS TIME ON SET STATISTICS IO ON DBCC DROPCLEANBUFFERS select Country_Name , City_Name ,SUM(CAST(Sales_Amnt AS Float)) AS [Sales Amount] from Analysis_TableTest group by Country_Name ,City_Name OPTION (MAXDOP 1)
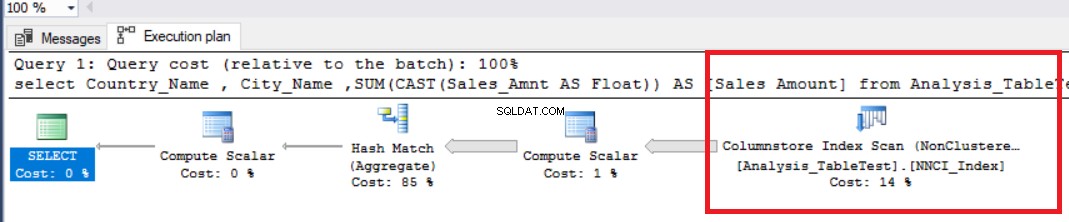

La siguiente tabla define los tiempos de ejecución. En este gráfico, podemos ver que el tiempo transcurrido es mayor que el tiempo de la CPU porque SQL Server usó solo un procesador.
Ahora deshabilitaremos el índice de almacenamiento de columnas no agrupadas y ejecutaremos la misma consulta.
ALTER INDEX [NNCI_Index] ON [dbo].[Analysis_TableTest] DISABLE GO SET STATISTICS TIME ON SET STATISTICS IO ON DBCC DROPCLEANBUFFERS select Country_Name , City_Name ,SUM(CAST(Sales_Amnt AS Float)) AS [Sales Amount] from Analysis_TableTest group by Country_Name ,City_Name OPTION (MAXDOP 1)

La tabla anterior nos muestra que el índice de almacenamiento de columnas no agrupadas proporciona un rendimiento increíble en consultas analíticas. Aproximadamente, la consulta indexada del almacén de columnas es cinco veces mejor que la otra.
Conclusión
Los análisis operativos en tiempo real brindan una flexibilidad increíble porque podemos ejecutar consultas analíticas en sistemas OLTP sin latencia de datos. Al mismo tiempo, estas consultas analíticas no afectan el rendimiento de la base de datos OLTP. Esta característica nos brinda la capacidad de administrar los datos transaccionales y las consultas analíticas en el mismo entorno.
Referencias
Índices de almacenamiento de columnas:guía de carga de datos
Comience con Column store para análisis operativos en tiempo real
Análisis operativo en tiempo real
Lecturas adicionales:
Escaneo hacia atrás del índice de SQL Server:comprensión, ajuste
Uso de índices en tablas optimizadas para memoria de SQL Server