En el último mes, me he comprometido con numerosos clientes que han tenido problemas de conversión implícita del lado de la columna asociados con sus cargas de trabajo OLTP. En dos ocasiones, el efecto acumulado de las conversiones implícitas del lado de la columna fue la causa subyacente del problema de rendimiento general del servidor SQL que se está revisando y, lamentablemente, no hay una configuración mágica o una opción de configuración que podamos modificar para mejorar la situación. cuando este es el caso. Si bien podemos ofrecer sugerencias para corregir otras frutas al alcance de la mano que podrían estar afectando el rendimiento general, el efecto de las conversiones implícitas del lado de la columna es algo que requiere un cambio de diseño de esquema para corregirlo o un cambio de código para evitar que la columna- la conversión secundaria se produzca contra el esquema de la base de datos actual por completo.
Las conversiones implícitas son el resultado de que el motor de la base de datos compare valores de diferentes tipos de datos durante la ejecución de la consulta. Puede encontrar una lista de las posibles conversiones implícitas que podrían ocurrir dentro del motor de base de datos en el tema Conversión de tipos de datos (motor de base de datos) de Books Online. Las conversiones implícitas siempre ocurren en función de la precedencia del tipo de datos para los tipos de datos que se comparan durante la operación. El orden de precedencia del tipo de datos se puede encontrar en el tema Precedencia del tipo de datos (Transact-SQL) de los Libros en pantalla. Recientemente escribí en un blog sobre las conversiones implícitas que dan como resultado un escaneo de índice y proporcioné gráficos que también se pueden usar para determinar las conversiones implícitas más problemáticas.
Configuración de las pruebas
Para demostrar la sobrecarga de rendimiento asociada con las conversiones implícitas del lado de la columna que dan como resultado un escaneo de índice, ejecuté una serie de pruebas diferentes en la base de datos AdventureWorks2012 usando la tabla Sales.SalesOrderDetail para crear tablas de prueba y conjuntos de datos. La conversión implícita del lado de la columna más común que veo como consultor ocurre cuando el tipo de columna es char o varchar, y el código de la aplicación pasa un parámetro que es nchar o nvarchar y filtra en la columna char o varchar. Para simular este tipo de escenario, creé una copia de la tabla SalesOrderDetail (llamada SalesOrderDetail_ASCII) y cambié la columna CarrierTrackingNumber de nvarchar a varchar. Además, agregué un índice no agrupado en la columna CarrierTrackingNumber a la tabla original SalesOrderDetail, así como la nueva tabla SalesOrderDetail_ASCII.
USE [AdventureWorks2012]
GO
-- Add CarrierTrackingNumber index to original Sales.SalesOrderDetail table
IF NOT EXISTS
(
SELECT 1 FROM sys.indexes
WHERE [object_id] = OBJECT_ID(N'Sales.SalesOrderDetail')
AND name=N'IX_SalesOrderDetail_CarrierTrackingNumber'
)
BEGIN
CREATE INDEX IX_SalesOrderDetail_CarrierTrackingNumber
ON Sales.SalesOrderDetail (CarrierTrackingNumber);
END
GO
IF OBJECT_ID('Sales.SalesOrderDetail_ASCII') IS NOT NULL
BEGIN
DROP TABLE Sales.SalesOrderDetail_ASCII;
END
GO
CREATE TABLE Sales.SalesOrderDetail_ASCII
(
SalesOrderID int NOT NULL,
SalesOrderDetailID int NOT NULL IDENTITY (1, 1),
CarrierTrackingNumber varchar(25) NULL,
OrderQty smallint NOT NULL,
ProductID int NOT NULL,
SpecialOfferID int NOT NULL,
UnitPrice money NOT NULL,
UnitPriceDiscount money NOT NULL,
LineTotal AS (isnull(([UnitPrice]*((1.0)-[UnitPriceDiscount]))*[OrderQty],(0.0))),
rowguid uniqueidentifier NOT NULL ROWGUIDCOL,
ModifiedDate datetime NOT NULL
);
GO
SET IDENTITY_INSERT Sales.SalesOrderDetail_ASCII ON;
GO
INSERT INTO Sales.SalesOrderDetail_ASCII
(
SalesOrderID, SalesOrderDetailID, CarrierTrackingNumber,
OrderQty, ProductID, SpecialOfferID, UnitPrice,
UnitPriceDiscount, rowguid, ModifiedDate
)
SELECT
SalesOrderID, SalesOrderDetailID, CONVERT(varchar(25), CarrierTrackingNumber),
OrderQty, ProductID, SpecialOfferID, UnitPrice,
UnitPriceDiscount, rowguid, ModifiedDate
FROM Sales.SalesOrderDetail WITH (HOLDLOCK TABLOCKX);
GO
SET IDENTITY_INSERT Sales.SalesOrderDetail_ASCII OFF;
GO
ALTER TABLE Sales.SalesOrderDetail_ASCII ADD CONSTRAINT
PK_SalesOrderDetail_ASCII_SalesOrderID_SalesOrderDetailID
PRIMARY KEY CLUSTERED (SalesOrderID, SalesOrderDetailID);
CREATE UNIQUE NONCLUSTERED INDEX AK_SalesOrderDetail_ASCII_rowguid
ON Sales.SalesOrderDetail_ASCII (rowguid);
CREATE NONCLUSTERED INDEX IX_SalesOrderDetail_ASCII_ProductID
ON Sales.SalesOrderDetail_ASCII (ProductID);
CREATE INDEX IX_SalesOrderDetail_ASCII_CarrierTrackingNumber
ON Sales.SalesOrderDetail_ASCII (CarrierTrackingNumber);
GO La nueva tabla SalesOrderDetail_ASCII tiene 121 317 filas y tiene un tamaño de 17,5 MB, y se usará para evaluar la sobrecarga de una tabla pequeña. También creé una tabla que es diez veces más grande, utilizando una versión modificada de la secuencia de comandos Ampliación de las bases de datos de ejemplo de AdventureWorks de mi blog, que contiene 1 334 487 filas y tiene un tamaño de 190 MB. El servidor de prueba para esto es la misma VM de 4 vCPU con 4 GB de RAM, que ejecuta Windows Server 2008 R2 y SQL Server 2012, con Service Pack 1 y Cumulative Update 3, que he usado en artículos anteriores, por lo que las tablas caben por completo en la memoria. , lo que evita que la sobrecarga de E/S del disco afecte a las pruebas que se están ejecutando.
La carga de trabajo de prueba se generó utilizando una serie de scripts de PowerShell que seleccionan la lista de CarrierTrackingNumbers de la tabla SalesOrderDetail creando una ArrayList y luego seleccionan aleatoriamente un CarrierTrackingNumber de ArrayList para consultar la tabla SalesOrderDetail_ASCII usando un parámetro varchar y luego un parámetro nvarchar, y luego consultar la tabla SalesOrderDetail usando un parámetro nvarchar para proporcionar una comparación de dónde la columna y el parámetro son nvarchar. Cada una de las pruebas individuales ejecuta la declaración 10 000 veces para permitir medir la sobrecarga de rendimiento en una carga de trabajo sostenida.
#No Implicit Conversions
$loop = 10000;
Write-Host "Small table no conversion start time:"
[DateTime]::Now
$query = @"SELECT * FROM Sales.SalesOrderDetail_ASCII "
"WHERE CarrierTrackingNumber = @CTNumber;";
while($loop -gt 0)
{
$Value = Get-Random -InputObject $Results;
$SqlCmd = $SqlConn.CreateCommand();
$SqlCmd.CommandText = $query;
$SqlCmd.CommandType = [System.Data.CommandType]::Text;
$SqlParameter = $SqlCmd.Parameters.AddWithValue("@CTNumber", $Value);
$SqlParameter.SqlDbType = [System.Data.SqlDbType]::VarChar;
$SqlParameter.Size = 30;
$SqlCmd.ExecuteNonQuery() | Out-Null;
$loop--;
}
Write-Host "Small table no conversion end time:"
[DateTime]::Now
Sleep -Seconds 10;
#Small table implicit conversions
$loop = 10000;
Write-Host "Small table implicit conversions start time:"
[DateTime]::Now
$query = @"SELECT * FROM Sales.SalesOrderDetail_ASCII "
"WHERE CarrierTrackingNumber = @CTNumber;";
while($loop -gt 0)
{
$Value = Get-Random -InputObject $Results;
$SqlCmd = $SqlConn.CreateCommand();
$SqlCmd.CommandText = $query;
$SqlCmd.CommandType = [System.Data.CommandType]::Text;
$SqlParameter = $SqlCmd.Parameters.AddWithValue("@CTNumber", $Value);
$SqlParameter.SqlDbType = [System.Data.SqlDbType]::NVarChar;
$SqlParameter.Size = 30;
$SqlCmd.ExecuteNonQuery() | Out-Null;
$loop--;
}
Write-Host "Small table implicit conversions end time:"
[DateTime]::Now
Sleep -Seconds 10;
#Small table unicode no implicit conversions
$loop = 10000;
Write-Host "Small table unicode no implicit conversion start time:"
[DateTime]::Now
$query = @"SELECT * FROM Sales.SalesOrderDetail "
"WHERE CarrierTrackingNumber = @CTNumber;"
while($loop -gt 0)
{
$Value = Get-Random -InputObject $Results;
$SqlCmd = $SqlConn.CreateCommand();
$SqlCmd.CommandText = $query;
$SqlCmd.CommandType = [System.Data.CommandType]::Text;
$SqlParameter = $SqlCmd.Parameters.AddWithValue("@CTNumber", $Value);
$SqlParameter.SqlDbType = [System.Data.SqlDbType]::NVarChar;
$SqlParameter.Size = 30;
$SqlCmd.ExecuteNonQuery() | Out-Null;
$loop--;
}
Write-Host "Small table unicode no implicit conversion end time:"
[DateTime]::Now Se ejecutó un segundo conjunto de pruebas en las tablas SalesOrderDetailEnlarged_ASCII y SalesOrderDetailEnlarged usando la misma parametrización que el primer conjunto de pruebas para mostrar la diferencia de gastos generales a medida que el tamaño de los datos almacenados en la tabla aumenta con el tiempo. También se ejecutó un conjunto final de pruebas en la tabla SalesOrderDetail utilizando la columna ProductID como columna de filtro con tipos de parámetro de int, bigint y luego smallint para proporcionar una comparación de la sobrecarga de conversiones implícitas que no dan como resultado un escaneo de índice. para comparar.
Nota:Todos los scripts se adjuntan a este artículo para permitir la reproducción de las pruebas de conversión implícitas para una mayor evaluación y comparación.
Resultados de la prueba
Durante cada una de las ejecuciones de prueba, el Monitor de rendimiento se configuró para ejecutar un conjunto de recopiladores de datos que incluía los contadores Procesador\% de tiempo de procesador y SQL Server:SQLStatisitics\Batch Requests/sec para realizar un seguimiento de la sobrecarga de rendimiento de cada una de las pruebas. Además, Extended Events se configuró para rastrear el evento rpc_completed para permitir el seguimiento de la duración promedio, cpu_time y lecturas lógicas para cada una de las pruebas.
Resultados de número de seguimiento del transportista de mesa pequeña
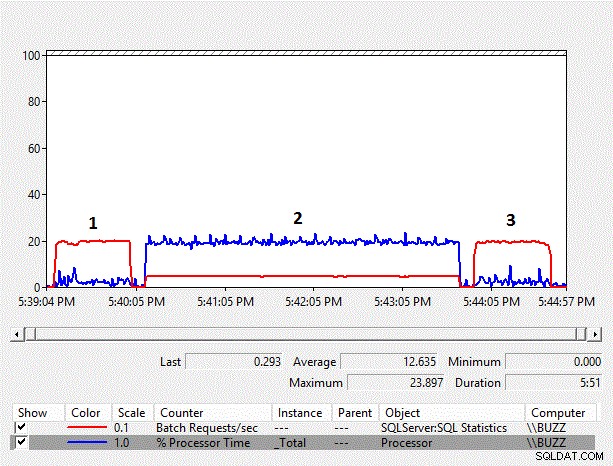
Figura 1:gráfico de contadores del monitor de rendimiento
| ID de prueba | Tipo de datos de columna | Tipo de datos de parámetro | Porcentaje promedio de tiempo de procesamiento | Promedio de solicitudes por lote/seg | Duración h:mm:ss |
|---|---|---|---|---|---|
| 1 | Varchar | Varchar | 2.5 | 192.3 | 0:00:51 |
| 2 | Varchar | Nvarchar | 19.4 | 46.7 | 0:03:33 |
| 3 | Nvarchar | Nvarchar | 2.6 | 192.3 | 0:00:51 |
Tabla 2:Promedios de datos del Monitor de rendimiento
A partir de los resultados, podemos ver que la conversión implícita del lado de la columna de varchar a nvarchar y la exploración del índice resultante tiene un impacto significativo en el rendimiento de la carga de trabajo. El % de tiempo de procesador promedio para la prueba de conversión implícita del lado de la columna (TestID =2) es casi diez veces mayor que el de las otras pruebas en las que no se produjo la conversión implícita del lado de la columna, lo que resultó en un escaneo de índice. Además, el promedio de solicitudes por segundo por lote para la prueba de conversión implícita del lado de la columna fue un poco menos del 25 % de las otras pruebas. La duración de las pruebas en las que no ocurrieron conversiones implícitas tomó 51 segundos, aunque los datos se almacenaron como nvarchar en la prueba número 3 usando un tipo de datos nvarchar, lo que requiere el doble de espacio de almacenamiento. Esto se esperaba porque la tabla aún es más pequeña que el grupo de búfer.
| ID de prueba | Promedio de tiempo_cpu (µs) | Duración media (µs) | Promedio de lecturas lógicas |
|---|---|---|---|
| 1 | 40.7 | 154,9 | 51.6 |
| 2 | 15.640,8 | 15.760,0 | 385.6 |
| 3 | 45.3 | 169.7 | 52.7 |
Tabla 3:Promedios de eventos extendidos
Los datos recopilados por el evento rpc_completed en eventos extendidos muestran que el cpu_time promedio, la duración y las lecturas lógicas asociadas con las consultas que no realizan una conversión implícita del lado de la columna son aproximadamente equivalentes, donde la conversión implícita del lado de la columna incurre en una CPU significativa sobrecarga, así como una duración promedio más larga con lecturas significativamente más lógicas.
Resultados de número de seguimiento de operador de tabla ampliada
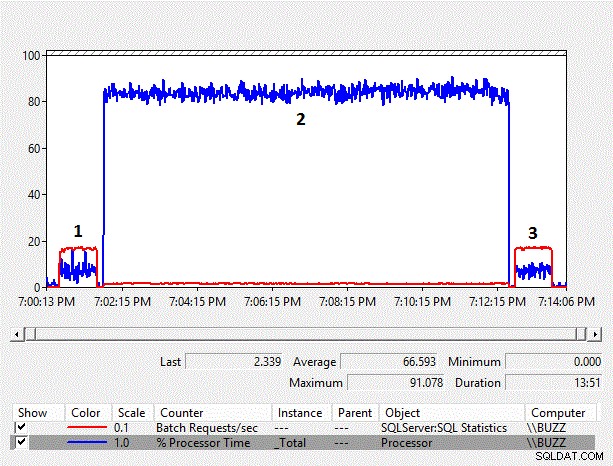
Figura 4:gráfico de contadores del monitor de rendimiento
| ID de prueba | Tipo de datos de columna | Tipo de datos de parámetro | Porcentaje promedio de tiempo de procesamiento | Promedio de solicitudes por lote/seg | Duración h:mm:ss |
|---|---|---|---|---|---|
| 1 | Varchar | Varchar | 7.2 | 164.0 | 0:01:00 |
| 2 | Varchar | Nvarchar | 83.8 | 15.4 | 0:10:49 |
| 3 | Nvarchar | Nvarchar | 7.0 | 166.7 | 0:01:00 |
Tabla 5:Promedios de datos del Monitor de rendimiento
A medida que aumenta el tamaño de los datos, también aumenta la sobrecarga de rendimiento de la conversión implícita del lado de la columna. El % de tiempo de procesador promedio para la prueba de conversión implícita del lado de la columna (TestID =2) es, de nuevo, casi diez veces mayor que el de las otras pruebas en las que no se produjo la conversión implícita del lado de la columna que dio como resultado un escaneo de índice. Además, el promedio de solicitudes por segundo por lote para la prueba de conversión implícita del lado de la columna fue un poco menos del 10 % de las otras pruebas. La duración de las pruebas en las que no se produjeron conversiones implícitas tomó un minuto, mientras que la prueba de conversión implícita del lado de la columna requirió cerca de once minutos para ejecutarse.
| ID de prueba | Promedio de tiempo_cpu (µs) | Duración media (µs) | Promedio de lecturas lógicas |
|---|---|---|---|
| 1 | 728.5 | 1.036,5 | 569.6 |
| 2 | 214.174,6 | 59.519,1 | 4358,2 |
| 3 | 821.5 | 1.032,4 | 553.5 |
Tabla 6:Promedios de eventos extendidos
Los resultados de Extended Events realmente comienzan a mostrar la sobrecarga de rendimiento causada por las conversiones implícitas del lado de la columna para la carga de trabajo. El cpu_time promedio por ejecución salta a más de 214 ms y es más de 200 veces el cpu_time para las declaraciones que no tienen las conversiones implícitas del lado de la columna. La duración también es casi 60 veces mayor que la de las declaraciones que no tienen las conversiones implícitas del lado de la columna.
Resumen
A medida que el tamaño de los datos continúa aumentando, la sobrecarga asociada con las conversiones implícitas del lado de la columna que dan como resultado un escaneo de índice para la carga de trabajo también seguirá creciendo, y lo importante para recordar es que en algún momento, ninguna cantidad de hardware será capaz de hacer frente a la sobrecarga de rendimiento. Las conversiones implícitas son fáciles de evitar cuando existe un buen diseño de esquema de base de datos y los desarrolladores siguen buenas técnicas de codificación de aplicaciones. En situaciones en las que las prácticas de codificación de la aplicación dan como resultado una parametrización que aprovecha la parametrización de nvarchar, es mejor hacer coincidir el diseño del esquema de la base de datos con la parametrización de la consulta que usar columnas varchar en el diseño de la base de datos e incurrir en la sobrecarga de rendimiento de la conversión implícita del lado de la columna.
Descargue los scripts de demostración:Implicit_Conversion_Tests.zip (5 KB)