En 2013, escribí sobre un error en el optimizador donde los argumentos 2 y 3 para DATEDIFF() se pueden intercambiar, lo que puede dar lugar a estimaciones de recuento de filas incorrectas y, a su vez, a una mala selección del plan de ejecución:
- Sorpresas y suposiciones de rendimiento:DATEDIFF
El fin de semana pasado, me enteré de una situación similar e inmediatamente asumí que era el mismo problema. Después de todo, los síntomas parecían casi idénticos:
- Había una función de fecha/hora en
WHEREcláusula.- Esta vez fue
DATEADD()en lugar deDATEDIFF().
- Esta vez fue
- Hubo una estimación de recuento de filas obviamente incorrecta de 1, en comparación con un recuento de filas real de más de 3 millones.
- Esta fue en realidad una estimación de 0, pero SQL Server siempre redondea dichas estimaciones a 1.
- Se realizó una mala selección del plan (en este caso, se eligió una unión en bucle) debido a la baja estimación.
El patrón ofensivo se veía así:
WHERE [datetime2(7) column] >= DATEADD(DAY, -365, SYSUTCDATETIME());
El usuario probó varias variaciones, pero nada cambió; eventualmente lograron solucionar el problema cambiando el predicado a:
WHERE DATEDIFF(DAY, [column], SYSUTCDATETIME()) <= 365;
Esto obtuvo una mejor estimación (la suposición típica de desigualdad del 30%); así que no del todo bien. Y aunque eliminó la unión de bucle, hay dos problemas principales con este predicado:
- Es no la misma consulta, ya que ahora busca que hayan pasado los límites de 365 días, en lugar de ser mayor que un punto específico en el tiempo hace 365 días. ¿Estadísticamente significante? Tal vez no. Pero técnicamente, no es lo mismo.
- La aplicación de la función contra la columna hace que toda la expresión no se pueda sargable, lo que lleva a un análisis completo. Cuando la tabla solo contiene un poco más de un año de datos, esto no es gran cosa, pero a medida que la tabla se hace más grande o el predicado se vuelve más estrecho, esto se convertirá en un problema.
Nuevamente, llegué a la conclusión de que DATEADD() la operación era el problema y recomendó un enfoque que no dependía de DATEADD() – construyendo un datetime de todas las partes del tiempo actual, permitiéndome restar un año sin usar DATEADD() :
WHERE [column] >= DATETIMEFROMPARTS(
DATEPART(YEAR, SYSUTCDATETIME())-1,
DATEPART(MONTH, SYSUTCDATETIME()),
DATEPART(DAY, SYSUTCDATETIME()),
DATEPART(HOUR, SYSUTCDATETIME()),
DATEPART(MINUTE, SYSUTCDATETIME()),
DATEPART(SECOND, SYSUTCDATETIME()), 0); Además de ser voluminoso, esto tenía algunos problemas propios, a saber, que se tendría que agregar un montón de lógica para dar cuenta adecuadamente de los años bisiestos. Primero, para que no falle si se ejecuta el 29 de febrero, y segundo, para incluir exactamente 365 días en todos los casos (en lugar de 366 durante el año siguiente a un día bisiesto). Soluciones fáciles, por supuesto, pero hacen que la lógica sea mucho más fea, especialmente porque la consulta debe existir dentro de una vista, donde las variables intermedias y los pasos múltiples no son posibles.
Mientras tanto, el OP presentó un elemento de conexión, consternado por la estimación de 1 fila:
- Conexión n.º 2567628:Restricción con DateAdd() que no proporciona buenas estimaciones
Entonces apareció Paul White (@SQL_Kiwi) y, como muchas veces antes, arrojó algo de luz adicional sobre el problema. Compartió un elemento relacionado de Connect presentado por Erland Sommarskog en 2011:
- Conectar #685903:Cálculo incorrecto cuando aparece sysdatetime en una expresión dateadd()
Esencialmente, el problema es que no se puede hacer una estimación pobre simplemente cuando SYSDATETIME() (o SYSUTCDATETIME() ) aparece, como Erland informó originalmente, pero cuando cualquier datetime2 expresión está involucrada en el predicado (y quizás solo cuando DATEADD() también se usa). Y puede ir en ambos sentidos, si intercambiamos >= para <= , la estimación se convierte en toda la tabla, por lo que parece que el optimizador está mirando el SYSDATETIME() value como una constante e ignorando por completo cualquier operación como DATEADD() que se realizan en su contra.
Paul compartió que la solución es simplemente usar un datetime equivalente al calcular la fecha, antes de convertirla al tipo de datos adecuado. En este caso, podemos intercambiar SYSUTCDATETIME() y cámbielo a GETUTCDATE() :
WHERE [column] >= CONVERT(datetime2(7), DATEADD(DAY, -365, GETUTCDATE()));
Sí, esto da como resultado una pequeña pérdida de precisión, pero también podría hacerlo una partícula de polvo que ralentiza su dedo en su camino para presionar

Las lecturas son similares porque la tabla contiene datos casi exclusivamente del año pasado, por lo que incluso una búsqueda se convierte en una exploración de rango de la mayor parte de la tabla. Los recuentos de filas no son idénticos porque (a) la segunda consulta se corta a la medianoche y (b) la tercera consulta incluye un día adicional de datos debido al día bisiesto a principios de este año. En cualquier caso, esto aún demuestra cómo podemos acercarnos a las estimaciones adecuadas eliminando DATEADD() , pero la solución adecuada es eliminar la combinación directa de DATEADD() y datetime2 .
Para ilustrar mejor cómo se equivocan las estimaciones, puede ver que si pasamos diferentes argumentos e instrucciones a la consulta original y la reescritura de Paul, el número de filas estimadas para la primera siempre se basa en la hora actual:no no cambia con el número de días transcurridos (mientras que el de Paul es relativamente preciso cada vez):
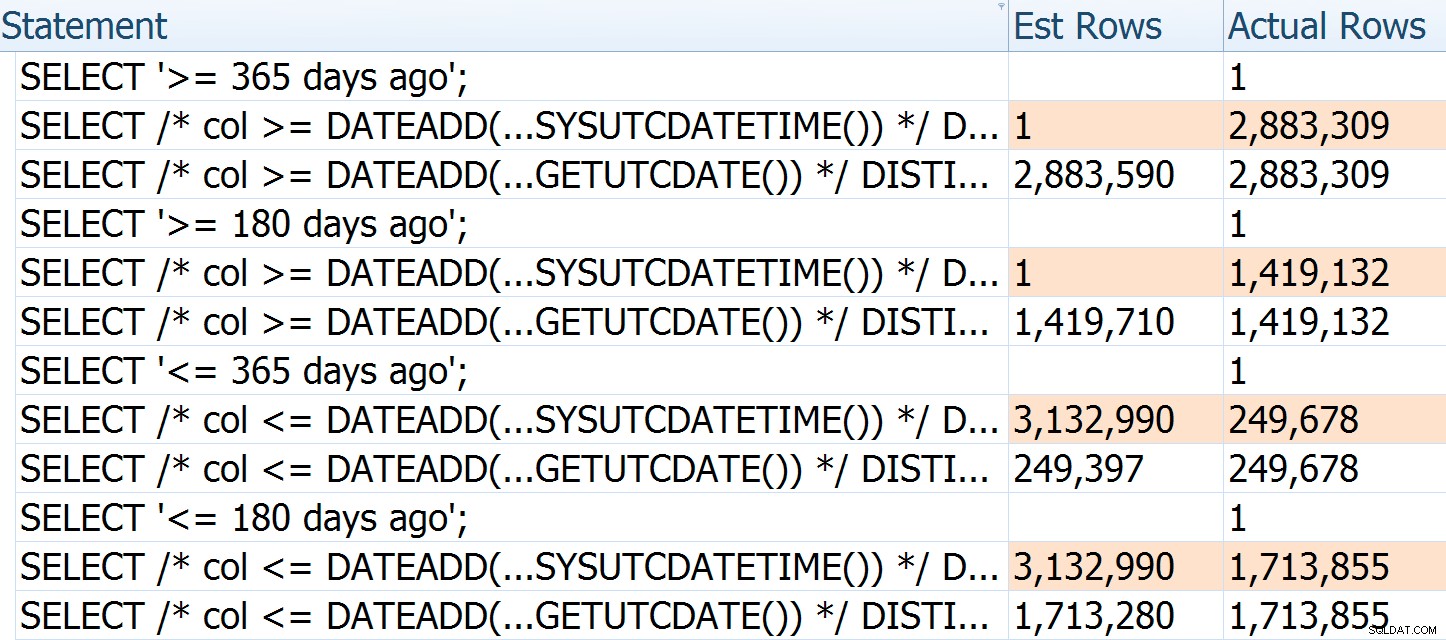 Las filas reales de la primera consulta son ligeramente más bajas porque se ejecutó después de una larga siesta
Las filas reales de la primera consulta son ligeramente más bajas porque se ejecutó después de una larga siesta
Las estimaciones no siempre serán tan buenas; mi tabla solo tiene una distribución relativamente estable. Lo llené con la siguiente consulta y luego actualicé las estadísticas con escaneo completo, en caso de que quieras probar esto por tu cuenta:
-- OP's table definition:
CREATE TABLE dbo.DateaddRepro
(
SessionId int IDENTITY(1, 1) NOT NULL PRIMARY KEY,
CreatedUtc datetime2(7) NOT NULL DEFAULT SYSUTCDATETIME()
);
GO
CREATE NONCLUSTERED INDEX [IX_User_Session_CreatedUtc]
ON dbo.DateaddRepro(CreatedUtc) INCLUDE (SessionId);
GO
INSERT dbo.DateaddRepro(CreatedUtc)
SELECT dt FROM
(
SELECT TOP (3150000) dt = DATEADD(HOUR, (s1.[precision]-ROW_NUMBER()
OVER (PARTITION BY s1.[object_id] ORDER BY s2.[object_id])) / 15, GETUTCDATE())
FROM sys.all_columns AS s1 CROSS JOIN sys.all_objects AS s2
) AS x;
UPDATE STATISTICS dbo.DateaddRepro WITH FULLSCAN;
SELECT DISTINCT SessionId FROM dbo.DateaddRepro
WHERE /* pick your WHERE clause to test */; Hice un comentario sobre el nuevo elemento Connect y probablemente regresaré y retocaré mi respuesta de Stack Exchange.
La moraleja de la historia
Trate de evitar combinar DATEADD() con expresiones que producen datetime2 , especialmente en versiones anteriores de SQL Server (esto fue en SQL Server 2012). También puede ser un problema, incluso en SQL Server 2016, cuando se usa el modelo de estimación de cardinalidad más antiguo (debido al nivel de compatibilidad más bajo o al uso explícito del indicador de seguimiento 9481). Problemas como este son sutiles y no siempre inmediatamente obvios, así que espero que esto sirva como un recordatorio (tal vez incluso para mí la próxima vez que me encuentre con un escenario similar). Como sugerí en la última publicación, si tiene patrones de consulta como este, verifique que esté obteniendo las estimaciones correctas y tome nota en algún lugar para verificarlas nuevamente cada vez que haya cambios importantes en el sistema (como una actualización o un paquete de servicio).