En este artículo, hablaremos sobre los puntos de control de SQL Server.
Para mejorar el rendimiento, SQL Server aplica modificaciones a las páginas de la base de datos en la memoria. A menudo, esta memoria se denomina caché de búfer o grupo de búfer. SQL Server no vacía estas páginas en el disco después de cada cambio. En su lugar, el motor de la base de datos realiza una operación de punto de control en cada base de datos de vez en cuando. El PUNTO DE CONTROL La operación escribe las páginas sucias (páginas modificadas en memoria actuales) y también escribe detalles sobre el registro de transacciones.
SQL Server admite cuatro tipos de puntos de control:
EXEC sp_configure 'recovery interval', 'seconds'
Bajo el modelo de recuperación SIMPLE, también se activa un punto de control automático cuando el registro de transacciones está lleno en un 70 %.
ALTER DATABASE … SET TARGET_RECOVERY_TIME =
target_recovery_time { SECONDS | MINUTES }
Al configurar esto, tenga en cuenta las capacidades del subsistema de E/S subyacente. Podría tener sentido establecer esta configuración más baja para subsistemas de E/S más rápidos (por ejemplo, SSD). Tenga cuidado, esta configuración persiste a través de la copia de seguridad y la restauración, por lo que la restauración a un hardware más lento puede causar problemas de rendimiento al generar demasiada carga de E/S.
CHECKPOINT [ checkpoint_duration ]
duración_del_punto_de_control es un número entero que se utiliza para definir la cantidad de tiempo en el que debe completarse un punto de control. Este parámetro también rige cuántos recursos se asignan a la operación de punto de control. Si no se especifica el parámetro, el punto de control se completará en el tiempo que minimice el impacto en el rendimiento.
- Se agrega o elimina un archivo de datos
- Se produce un cierre de la base de datos (por cualquier motivo)
- Se crea una copia de seguridad o una instantánea de la base de datos
- Se ejecuta un comando DBCC que crea una instantánea de base de datos oculta (o, por ejemplo, DBCC_CHECKDB, DBCC_CHECKTABLE).
¿Por qué son útiles los puntos de control?
Los puntos de control reducen el tiempo de recuperación tras un bloqueo. Esto sucede porque las páginas del archivo de datos no se escriben en el disco al mismo tiempo que los registros. Hay páginas de archivos de datos en la memoria que están más actualizadas que las páginas de archivos de datos en el disco.
Los puntos de control reducen la E/S en el disco y mejoran el rendimiento. La razón por la que las páginas del archivo de datos no se escriben en el disco en el momento en que se confirma la transacción es para reducir el número de operaciones de E/S. Imagine los varios miles de transacciones de ACTUALIZACIÓN en una sola página de datos. Es más eficiente escribir una página de datos en el disco solo una vez, durante un punto de control, en lugar de después de cada cambio.
Páginas limpias y sucias
El grupo de búfer mantiene una cantidad de páginas de datos en la memoria. Hay dos tipos de páginas de datos:limpias y sucio . Una página limpia es aquella que no ha cambiado desde que fue la última vez que se leyó del disco o se escribió en el disco. Una página sucia es una página que se ha cambiado y los cambios no se han escrito en el disco. Los puntos de control se refieren a "páginas sucias".
La información sobre la página se puede ver usando sys.dm_os_buffer_descriptors . Veamos qué devuelve esta función:
SELECT * FROM sys.dm_os_buffer_descriptors dobd; GO
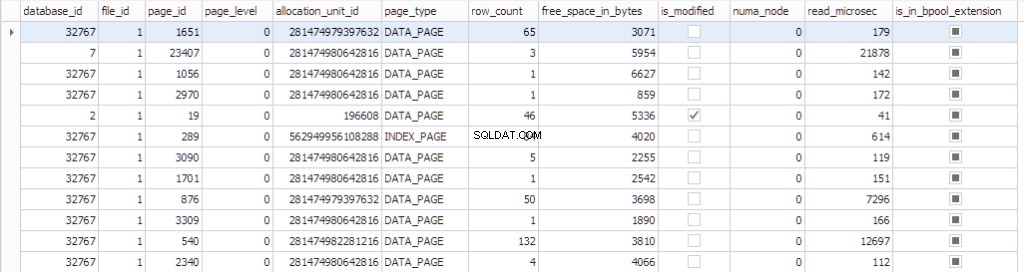
Cada página tiene una estructura de control asociada que rastrea el estado de la página:
- Una base de datos que tenga el datdabase_id 32767 es una base de datos de recursos de solo lectura que contiene todos los objetos del sistema.
- id_archivo , id_página , id_unidad_de_asignación esa página pertenece.
- Qué tipo de página es:página de datos o página de índice.
- El número de filas en la página.
- El espacio libre en la página
- Si la página está sucia o no
- El numa_node al que pertenece la página en particular
- Alguna información sobre el algoritmo Último uso reciente
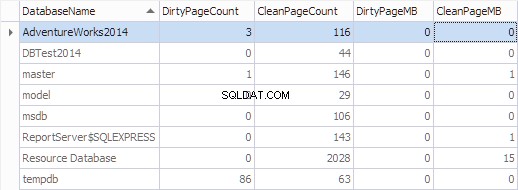
Agreguemos esta información por base de datos usando el siguiente código:
SELECT
*,
[DirtyPageCount] * 8 / 1024 AS [DirtyPageMB],
[CleanPageCount] * 8 / 1024 AS [CleanPageMB]
FROM (SELECT
(CASE
WHEN ([database_id] = 32767) THEN N'Resource Database'
ELSE DB_NAME([database_id])
END) AS [DatabaseName],
SUM(CASE
WHEN ([is_modified] = 1) THEN 1
ELSE 0
END) AS [DirtyPageCount],
SUM(CASE
WHEN ([is_modified] = 1) THEN 0
ELSE 1
END) AS [CleanPageCount]
FROM sys.dm_os_buffer_descriptors
GROUP BY [database_id]) AS [buffers]
ORDER BY [DatabaseName]
GO
Mecanismo de punto de control
Cuando se produce el punto de control, escribe todas las páginas sucias en el disco. Las páginas marcadas como sucias tan pronto como tienen algunos cambios. No importa si la transacción que realizó el cambio está confirmada o no confirmada en el momento del punto de control. Una vez que las páginas se han escrito en el disco, el bit "sucio" se borra. Cuando se produce el punto de control, se llevan a cabo las siguientes acciones:
- Un nuevo registro indica el inicio de un punto de control
- Aparecen registros de registro adicionales con información del punto de control (como el estado del registro de transacciones en el momento en que se inicia el punto de control)
- Todas las páginas sucias se escriben en el disco
- Marque el LSN del punto de control en la página de inicio de la base de datos (en dbi_checkptLSN), esto es fundamental para la recuperación de fallas
- Si se usa el modelo de recuperación SIMPLE, intente borrar el registro
- Un registro de registro final indica que el punto de control ha terminado
Es posible que los puntos de control de múltiples bases de datos ocurran en paralelo. SQL Server 2000 estaba limitado a un punto de control a la vez. Cuando el administrador de búfer escribe una página, busca páginas sucias adyacentes que se pueden incluir en una única operación de recopilación y escritura. Además, el grupo de búfer intentará asegurarse de que no sobrecargue el subsistema de E/S. Realiza un seguimiento de cuánto tiempo tarda la E/S en completarse. Si la latencia de escritura supera los 20 ms durante el punto de control, se limita solo. Durante el apagado, el umbral de regulación aumenta a 100 ms. Puedes encontrar una explicación más detallada aquí. Puede usar la opción de inicio "-kXX" no documentada para establecer la velocidad de E/S del punto de control en XX MB/s.
Cuando la página del archivo de datos se escribe en el disco mediante un punto de control, el registro de escritura anticipada garantiza que todos los registros que afectan a esa página deben escribirse primero en el registro de transacciones del disco. Se escriben todos los registros hasta el último que afectó a la página, independientemente de la transacción de la que formen parte. Los registros de registro se escriben de tres maneras:
- Cuando cualquier transacción se confirma o cancela
- Cuando la página del archivo de datos se escribe en el disco
- Cuando un bloque de registro alcanza el tamaño máximo de 60 KB y finaliza a la fuerza
Registro de registro del punto de control
Los puntos de control escriben varios registros en el registro de transacciones:
- LOP_BEGIN_CKPT — significa que el punto de control comenzó
- LOP_XACT_CKPT con contexto NULL (solo si hay transacciones no confirmadas en el momento en que se inició el punto de control):contiene un recuento del número de transacciones no confirmadas. También enumera los LSN de los registros LOP_BEGIN_XACT de las transacciones no confirmadas.
- LOP_BEGIN_CKPT con un contexto de LOP_BOOT_PAGE_CKPT (solo SQL Server 2012):significa que la página de inicio se ha actualizado.
- LOP_END_CKPT — significa el final del punto de control.
Monitoreo de puntos de control
Puede ser útil correlacionar los puntos de control que ocurren con los picos de E/S para que se puedan realizar cambios en la base de datos específica (para el subsistema de E/S) para aliviar el pico de E/S si sobrecarga el subsistema de E/S. Por ejemplo, realizar puntos de control manuales más frecuentes o configurar un intervalo de recuperación más bajo en SQL Server 2012 con puntos de control indirectos. Esto producirá una carga de E/S más constante sin picos altos que sobrecarguen el subsistema de E/S. Sin embargo, la causa principal puede ser que se realicen más E/S debido a un cambio en alguna parte, así que no acepte un aumento repentino en la actividad del punto de control sin investigar por qué ocurrió.
El administrador de búfer/páginas de puntos de control/contador de segundos no es específico de la base de datos, por lo que identificar qué base de datos está involucrada requiere marcas de rastreo o eventos extendidos.
Indicador de seguimiento 3502 escribe mensajes en el registro de errores sobre para qué punto de control de la base de datos se está produciendo.
Indicador de seguimiento 3504 escribe información más detallada sobre cuántas páginas se escribieron y la latencia de escritura promedio.
Estas banderas de rastreo son seguras para usar en producción por un tiempo limitado. Todo lo que hacen es imprimir mensajes en el registro de errores.
Si quiere usar eventos extendidos, hay dos eventos que puede usar:checkpoint_begin y checkpoint_end.
Resumen
En este artículo, hemos hablado sobre los puntos de control en SQL Server, el mecanismo principal para escribir páginas de archivos de datos en el disco después de que se hayan modificado.