[ Parte 1 | Parte 2 | Parte 3 | Parte 4 ]
En la primera parte de esta serie, vimos cómo el Problema de Halloween se aplica a UPDATE consultas Para recapitular brevemente, el problema era que un índice utilizado para ubicar registros para actualizar tenía sus claves modificadas por la operación de actualización en sí (otra buena razón para usar columnas incluidas en un índice en lugar de extender las claves). El optimizador de consultas introdujo un operador Eager Table Spool para separar los lados de lectura y escritura del plan de ejecución para evitar el problema. En esta publicación, veremos cómo el mismo problema subyacente puede afectar INSERT y DELETE declaraciones.
Insertar declaraciones
Ahora que sabemos un poco sobre las condiciones que requieren Protección de Halloween, es bastante fácil crear un INSERT ejemplo que implica leer y escribir en las claves de la misma estructura de índice. El ejemplo más simple es duplicar filas en una tabla (donde agregar nuevas filas inevitablemente modifica las claves del índice agrupado):
CREATE TABLE dbo.Demo
(
SomeKey integer NOT NULL,
CONSTRAINT PK_Demo
PRIMARY KEY (SomeKey)
);
INSERT dbo.Demo
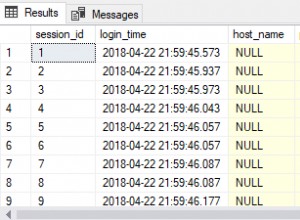
SELECT SomeKey FROM dbo.Demo; El problema es que el lado de lectura del plan de ejecución puede encontrar filas recién insertadas, lo que podría generar un bucle que agregue filas para siempre (o al menos hasta que se alcance algún límite de recursos). El optimizador de consultas reconoce este riesgo y agrega un Eager Table Spool para proporcionar la separación de fases necesaria. :
Un ejemplo más realista
Probablemente no escriba a menudo consultas para duplicar cada fila de una tabla, pero sí escribirá consultas donde la tabla de destino para un INSERT también aparece en algún lugar de SELECT cláusula. Un ejemplo es agregar filas de una tabla provisional que aún no existe en el destino:
CREATE TABLE dbo.Staging
(
SomeKey integer NOT NULL
);
-- Sample data
INSERT dbo.Staging
(SomeKey)
VALUES
(1234),
(1234);
-- Test query
INSERT dbo.Demo
SELECT s.SomeKey
FROM dbo.Staging AS s
WHERE NOT EXISTS
(
SELECT 1
FROM dbo.Demo AS d
WHERE d.SomeKey = s.SomeKey
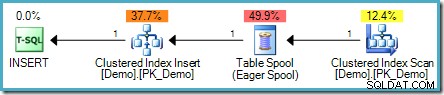
); El plan de ejecución es:
El problema en este caso es sutilmente diferente, aunque sigue siendo un ejemplo del mismo problema central. No hay ningún valor '1234' en la tabla de demostración de destino, pero la tabla de etapas contiene dos entradas de este tipo. Sin la separación de fases, el primer valor '1234' encontrado se insertaría con éxito, pero la segunda verificación encontraría que el valor '1234' ahora existe y no intentaría insertarlo nuevamente. La declaración en su conjunto se completaría con éxito.
Esto podría producir un resultado deseable en este caso particular (e incluso podría parecer intuitivamente correcto), pero no es una implementación correcta. El estándar SQL requiere que las consultas de modificación de datos se ejecuten como si las tres fases de lectura, escritura y verificación de restricciones se produjeran completamente por separado (consulte la primera parte).
Al buscar todas las filas para insertarlas como una sola operación, debemos seleccionar ambas filas '1234' de la tabla de etapas, ya que este valor aún no existe en el destino. Por lo tanto, el plan de ejecución debe tratar de insertar ambos '1234' filas de la tabla de ensayo, lo que resulta en una violación de clave principal:
Mensaje 2627, Nivel 14, Estado 1, Línea 1Violación de la restricción PRIMARY KEY 'PK_Demo'.
No se puede insertar la clave duplicada en el objeto 'dbo.Demo'.
El valor de la clave duplicada es ( 1234).
La declaración ha sido terminada.
La separación de fases proporcionada por Table Spool garantiza que todas las comprobaciones de existencia se completen antes de que se realicen cambios en la tabla de destino. Si ejecuta la consulta en SQL Server con los datos de muestra anteriores, recibirá el mensaje de error (correcto).
Se requiere protección de Halloween para declaraciones INSERT donde también se hace referencia a la tabla de destino en la cláusula SELECT.
Eliminar estados de cuenta
Podríamos esperar que el Problema de Halloween no se aplique a DELETE declaraciones, ya que realmente no debería importar si intentamos eliminar una fila varias veces. Podemos modificar nuestro ejemplo de tabla de etapas para eliminar filas de la tabla Demo que no existen en Staging:
TRUNCATE TABLE dbo.Demo;
TRUNCATE TABLE dbo.Staging;
INSERT dbo.Demo (SomeKey) VALUES (1234);
DELETE dbo.Demo
WHERE NOT EXISTS
(
SELECT 1
FROM dbo.Staging AS s
WHERE s.SomeKey = dbo.Demo.SomeKey
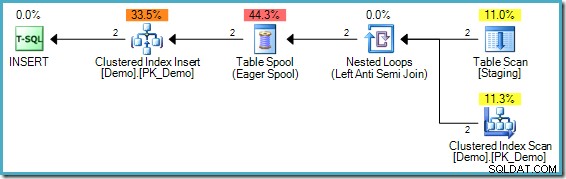
); Esta prueba parece validar nuestra intuición porque no hay Table Spool en el plan de ejecución:
Este tipo de DELETE no requiere separación de fases porque cada fila tiene un identificador único (un RID si la tabla es un montón, claves de índice agrupadas y posiblemente un uniquifier en caso contrario). Este localizador de fila único es una clave estable – no existe ningún mecanismo por el cual pueda cambiar durante la ejecución de este plan, por lo que no surge el Problema de Halloween.
ELIMINAR Protección de Halloween
Sin embargo, hay al menos un caso en el que DELETE requiere protección de Halloween:cuando el plan hace referencia a una fila en la tabla distinta a la que se está eliminando. Esto requiere una autounión, que se encuentra comúnmente cuando se modelan relaciones jerárquicas. A continuación se muestra un ejemplo simplificado:
CREATE TABLE dbo.Test
(
pk char(1) NOT NULL,
ref char(1) NULL,
CONSTRAINT PK_Test
PRIMARY KEY (pk)
);
INSERT dbo.Test
(pk, ref)
VALUES
('B', 'A'),
('C', 'B'),
('D', 'C');
Realmente debería haber una referencia de clave externa de la misma tabla definida aquí, pero ignoremos que el diseño falla por un momento:la estructura y los datos son, no obstante, válidos (y lamentablemente es bastante común encontrar claves externas omitidas en el mundo real). De todos modos, la tarea en cuestión es eliminar cualquier fila donde el ref la columna apunta a un pk inexistente valor. El DELETE natural la consulta que coincide con este requisito es:
DELETE dbo.Test
WHERE NOT EXISTS
(
SELECT 1
FROM dbo.Test AS t2
WHERE t2.pk = dbo.Test.ref
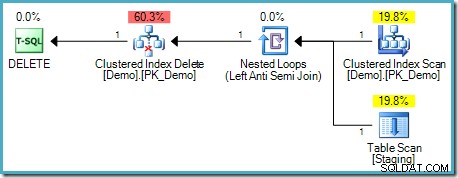
); El plan de consulta es:
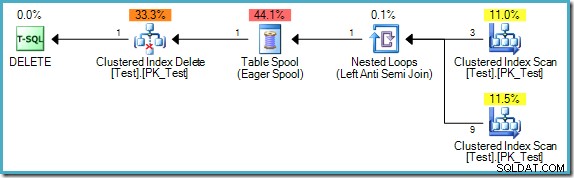
Tenga en cuenta que este plan ahora cuenta con un costoso Eager Table Spool. Aquí se requiere la separación de fases porque, de lo contrario, los resultados podrían depender del orden en que se procesan las filas:
Si el motor de ejecución comienza con la fila donde pk =B, no encontraría ninguna fila coincidente (ref =A y no hay fila donde pk =A). Si la ejecución pasa a la fila donde pk =C, también se eliminaría porque acabamos de eliminar la fila B señalada por su ref columna. El resultado final sería que el procesamiento iterativo en este orden eliminaría todas las filas de la tabla, lo que claramente es incorrecto.
Por otro lado, si el motor de ejecución procesó la fila con pk =D primero, encontraría una fila coincidente (ref =C). Suponiendo que la ejecución continuara en el pk inverso orden, la única fila eliminada de la tabla sería aquella en la que pk =B. Este es el resultado correcto (recuerde que la consulta debe ejecutarse como si las fases de lectura, escritura y validación se hubieran producido de forma secuencial y sin superposiciones).
Separación de fases para validación de restricciones
Aparte, podemos ver otro ejemplo de separación de fases si agregamos una restricción de clave externa de la misma tabla al ejemplo anterior:
DROP TABLE dbo.Test;
CREATE TABLE dbo.Test
(
pk char(1) NOT NULL,
ref char(1) NULL,
CONSTRAINT PK_Test
PRIMARY KEY (pk),
CONSTRAINT FK_ref_pk
FOREIGN KEY (ref)
REFERENCES dbo.Test (pk)
);
INSERT dbo.Test
(pk, ref)
VALUES
('B', NULL),
('C', 'B'),
('D', 'C'); El plan de ejecución para INSERT es:
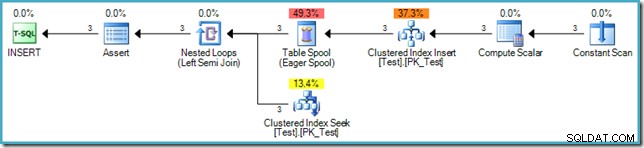
La inserción en sí no requiere protección de Halloween ya que el plan no lee de la misma tabla (el origen de datos es una tabla virtual en memoria representada por el operador Constant Scan). Sin embargo, el estándar SQL requiere que la fase 3 (verificación de restricciones) ocurra después de que se complete la fase de escritura. Por este motivo, se añade al plan un Spool de tabla ansiosa de separación de fases después el índice de índice agrupado, y justo antes de que se verifique cada fila para asegurarse de que la restricción de clave externa sigue siendo válida.
Si está empezando a pensar que traducir una consulta de modificación de SQL declarativa basada en conjuntos a un plan de ejecución física iterativo sólido es un asunto complicado, está empezando a ver por qué el procesamiento de actualizaciones (del cual Halloween Protection es solo una parte muy pequeña) es el la parte más compleja del Procesador de consultas.
Las declaraciones DELETE requieren Protección de Halloween cuando está presente una autounión de la tabla de destino.
Resumen
La protección de Halloween puede ser una característica costosa (pero necesaria) en los planes de ejecución que modifican los datos (donde "cambiar" incluye toda la sintaxis SQL que agrega, cambia o elimina filas). Se requiere protección de Halloween para UPDATE planes donde las claves de una estructura de índice común se leen y modifican, para INSERT planes donde se hace referencia a la tabla de destino en el lado de lectura del plan, y para DELETE planes donde se realiza una unión automática en la tabla de destino.
La siguiente parte de esta serie cubrirá algunas optimizaciones especiales de problemas de Halloween que se aplican solo a MERGE declaraciones.
[ Parte 1 | Parte 2 | Parte 3 | Parte 4 ]