[ Parte 1 | Parte 2 | Parte 3 | Parte 4 ]
El MERGE declaración (introducida en SQL Server 2008) nos permite realizar una combinación de INSERT , UPDATE y DELETE operaciones usando una sola instrucción. Los problemas de protección de Halloween para MERGE son en su mayoría una combinación de los requisitos de las operaciones individuales, pero hay algunas diferencias importantes y un par de optimizaciones interesantes que se aplican solo a MERGE .
Evitar el problema de Halloween con MERGE
Comenzamos mirando de nuevo el ejemplo de demostración y puesta en escena de la segunda parte:
CREATE TABLE dbo.Demo
(
SomeKey integer NOT NULL,
CONSTRAINT PK_Demo
PRIMARY KEY (SomeKey)
);
CREATE TABLE dbo.Staging
(
SomeKey integer NOT NULL
);
INSERT dbo.Staging
(SomeKey)
VALUES
(1234),
(1234);
CREATE NONCLUSTERED INDEX c
ON dbo.Staging (SomeKey);
INSERT dbo.Demo
SELECT s.SomeKey
FROM dbo.Staging AS s
WHERE NOT EXISTS
(
SELECT 1
FROM dbo.Demo AS d
WHERE d.SomeKey = s.SomeKey
);
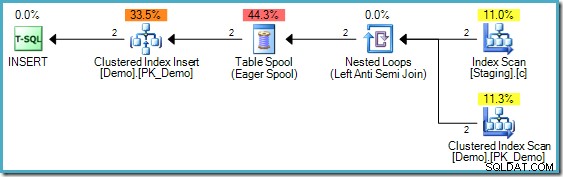
Como recordará, este ejemplo se usó para mostrar que un INSERT requiere Protección de Halloween cuando también se hace referencia a la tabla de destino de inserción en SELECT parte de la consulta (el EXISTS cláusula en este caso). El comportamiento correcto para INSERT declaración anterior es tratar de agregar ambos 1234 valores y, en consecuencia, fallar con una PRIMARY KEY violación. Sin separación de fases, el INSERT agregaría incorrectamente un valor, completando sin que se arroje un error.
El plan de ejecución INSERT
El código anterior tiene una diferencia con el utilizado en la segunda parte; se ha agregado un índice no agrupado en la tabla de etapas. El INSERT plan de ejecución todavía aunque requiere Protección de Halloween:
El plan de ejecución MERGE
Ahora intente la misma inserción lógica expresada usando MERGE sintaxis:
MERGE dbo.Demo AS d
USING dbo.Staging AS s ON
s.SomeKey = d.SomeKey
WHEN NOT MATCHED BY TARGET THEN
INSERT (SomeKey)
VALUES (s.SomeKey);
En caso de que no esté familiarizado con la sintaxis, la lógica es comparar filas en las tablas Staging y Demo en el valor SomeKey, y si no se encuentra ninguna fila coincidente en la tabla de destino (Demo), insertamos una nueva fila. Esto tiene exactamente la misma semántica que el anterior INSERT...WHERE NOT EXISTS código, por supuesto. Sin embargo, el plan de ejecución es bastante diferente:
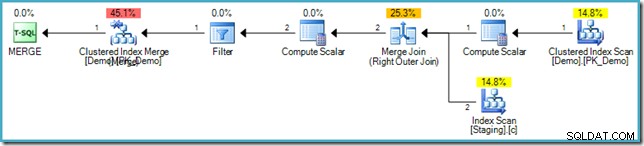
Observe la falta de un Eager Table Spool en este plan. A pesar de eso, la consulta aún genera el mensaje de error correcto. Parece que SQL Server ha encontrado una forma de ejecutar MERGE planifique iterativamente respetando la separación de fases lógica requerida por el estándar SQL.
La optimización de relleno de huecos
En las circunstancias adecuadas, el optimizador de SQL Server puede reconocer que MERGE declaración es llenar huecos , que es solo otra forma de decir que la declaración solo agrega filas donde existe un espacio en la clave de la tabla de destino.
Para que se aplique esta optimización, los valores utilizados en el WHEN NOT MATCHED BY TARGET cláusula debe exactamente coincide con el ON parte del USING cláusula. Además, la tabla de destino debe tener una clave única (un requisito satisfecho por la PRIMARY KEY en el caso presente). Cuando se cumplan estos requisitos, el MERGE declaración no requiere protección contra el Problema de Halloween.
Por supuesto, el MERGE declaración es lógicamente ni más ni menos relleno de agujeros que el original INSERT...WHERE NOT EXISTS sintaxis. La diferencia es que el optimizador tiene control total sobre la implementación de MERGE declaración, mientras que INSERT la sintaxis requeriría razonar sobre la semántica más amplia de la consulta. Un humano puede ver fácilmente que INSERT también está llenando agujeros, pero el optimizador no piensa en las cosas de la misma manera que nosotros.
Para ilustrar la coincidencia exacta requisito que mencioné, considere la siguiente sintaxis de consulta, que no Benefíciese de la optimización de llenado de agujeros. El resultado es una protección completa de Halloween proporcionada por un Eager Table Spool:
MERGE dbo.Demo AS d
USING dbo.Staging AS s ON
s.SomeKey = d.SomeKey
WHEN NOT MATCHED THEN
INSERT (SomeKey)
VALUES (s.SomeKey * 1);

La única diferencia que hay es la multiplicación por uno en los VALUES cláusula:algo que no cambia la lógica de la consulta, pero que es suficiente para evitar que se aplique la optimización de relleno de huecos.
Relleno de agujeros con bucles anidados
En el ejemplo anterior, el optimizador optó por unir las tablas mediante una combinación Merge. La optimización de relleno de agujeros también se puede aplicar cuando se elige una combinación de bucles anidados, pero esto requiere una garantía de unicidad adicional en la tabla de origen y una búsqueda de índice en el lado interno de la combinación. Para ver esto en acción, podemos borrar los datos de preparación existentes, agregar singularidad al índice no agrupado y probar MERGE de nuevo:
-- Remove existing duplicate rows
TRUNCATE TABLE dbo.Staging;
-- Convert index to unique
CREATE UNIQUE NONCLUSTERED INDEX c
ON dbo.Staging (SomeKey)
WITH (DROP_EXISTING = ON);
-- Sample data
INSERT dbo.Staging
(SomeKey)
VALUES
(1234),
(5678);
-- Hole-filling merge
MERGE dbo.Demo AS d
USING dbo.Staging AS s ON
s.SomeKey = d.SomeKey
WHEN NOT MATCHED THEN
INSERT (SomeKey)
VALUES (s.SomeKey); El plan de ejecución resultante vuelve a utilizar la optimización de relleno de huecos para evitar la Protección de Halloween, utilizando una unión de bucles anidados y una búsqueda interna en la tabla de destino:
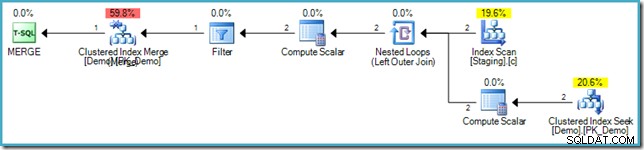
Evitar recorridos de índice innecesarios
Cuando se aplica la optimización de llenado de agujeros, el motor también puede aplicar una optimización adicional. Puede recordar la posición del índice actual mientras lee la tabla de destino (procesando una fila a la vez, recuerde) y reutilice esa información cuando realice la inserción, en lugar de buscar el árbol B para encontrar la ubicación de inserción. El razonamiento es que es muy probable que la posición de lectura actual esté en la misma página donde se debe insertar la nueva fila. Verificar que la fila de hecho pertenece a esta página es muy rápido, ya que implica verificar solo las claves más bajas y más altas actualmente almacenadas allí.
La combinación de eliminar Eager Table Spool y guardar una navegación de índice por fila puede proporcionar un beneficio significativo en las cargas de trabajo de OLTP, siempre que el plan de ejecución se recupere de la memoria caché. El costo de compilación para MERGE sentencias es algo mayor que para INSERT , UPDATE y DELETE , por lo que la reutilización del plan es una consideración importante. También es útil asegurarse de que las páginas tengan suficiente espacio libre para acomodar nuevas filas, evitando divisiones de página. Esto generalmente se logra a través del mantenimiento normal del índice y la asignación de un FILLFACTOR adecuado .
Menciono las cargas de trabajo de OLTP, que suelen presentar una gran cantidad de cambios relativamente pequeños, porque MERGE las optimizaciones pueden no ser una buena opción cuando se procesa una gran cantidad de filas por instrucción. Otras optimizaciones como INSERTs mínimamente registrados actualmente no se puede combinar con el relleno de agujeros. Como siempre, las características de rendimiento deben compararse para garantizar que se obtengan los beneficios esperados.
La optimización de relleno de huecos para MERGE las inserciones se pueden combinar con actualizaciones y eliminaciones usando MERGE adicional cláusulas; cada operación de cambio de datos se evalúa por separado para el Problema de Halloween.
Evitar la unión
La optimización final que veremos se puede aplicar donde MERGE La declaración contiene operaciones de actualización y eliminación, así como una inserción de relleno de agujeros, y la tabla de destino tiene un índice agrupado único. El siguiente ejemplo muestra un MERGE común patrón donde se insertan filas no coincidentes y las filas coincidentes se actualizan o eliminan según una condición adicional:
CREATE TABLE #T
(
col1 integer NOT NULL,
col2 integer NOT NULL,
CONSTRAINT PK_T
PRIMARY KEY (col1)
);
CREATE TABLE #S
(
col1 integer NOT NULL,
col2 integer NOT NULL,
CONSTRAINT PK_S
PRIMARY KEY (col1)
);
INSERT #T
(col1, col2)
VALUES
(1, 50),
(3, 90);
INSERT #S
(col1, col2)
VALUES
(1, 40),
(2, 80),
(3, 90);
El MERGE declaración requerida para hacer todos los cambios requeridos es notablemente compacta:
MERGE #T AS t USING #S AS s ON t.col1 = s.col1 WHEN NOT MATCHED THEN INSERT VALUES (s.col1, s.col2) WHEN MATCHED AND t.col2 - s.col2 = 0 THEN DELETE WHEN MATCHED THEN UPDATE SET t.col2 -= s.col2;
El plan de ejecución es bastante sorprendente:

Sin protección de Halloween, sin unión entre las tablas de origen y de destino, y no es frecuente que vea un operador de inserción de índice agrupado seguido de una fusión de índice agrupado en la misma tabla. Esta es otra optimización dirigida a cargas de trabajo OLTP con alta reutilización de planes e indexación adecuada.
La idea es leer una fila de la tabla de origen e inmediatamente intentar insertarla en el destino. Si se produce una violación de clave, se suprime el error, el operador Insertar genera la fila en conflicto que encontró y esa fila se procesa para una operación de actualización o eliminación utilizando el operador del plan Fusionar como de costumbre.
Si la inserción original tiene éxito (sin una violación de clave), el procesamiento continúa con la siguiente fila desde el origen (el operador Fusionar solo procesa actualizaciones y eliminaciones). Esta optimización beneficia principalmente a MERGE consultas donde la mayoría de las filas de origen dan como resultado una inserción. Nuevamente, se requiere una evaluación comparativa cuidadosa para garantizar que el rendimiento sea mejor que usar declaraciones separadas.
Resumen
El MERGE declaración ofrece varias oportunidades únicas de optimización. En las circunstancias adecuadas, puede evitar la necesidad de agregar una Protección de Halloween explícita en comparación con un INSERT equivalente. operación, o tal vez incluso una combinación de INSERT , UPDATE y DELETE declaraciones. MERGE adicionales Las optimizaciones específicas pueden evitar el recorrido del árbol b del índice que generalmente se necesita para ubicar la posición de inserción para una nueva fila, y también pueden evitar la necesidad de unir las tablas de origen y de destino por completo.
En la parte final de esta serie, veremos cómo el optimizador de consultas razona sobre la necesidad de protección de Halloween e identificaremos algunos trucos más que puede emplear para evitar la necesidad de agregar Eager Table Spools a los planes de ejecución que cambian los datos.
[ Parte 1 | Parte 2 | Parte 3 | Parte 4 ]