[ Parte 1 | Parte 2 | Parte 3 | Parte 4 ]
En la parte 3 de esta serie, mostré dos soluciones para evitar ampliar una IDENTITY columna:una que simplemente te hace ganar tiempo y otra que abandona IDENTITY en total. El primero le evita tener que lidiar con dependencias externas, como claves externas, pero el segundo aún no soluciona ese problema. En esta publicación, quería detallar el enfoque que tomaría si fuera absolutamente necesario cambiar a bigint , necesitaba minimizar el tiempo de inactividad y tenía mucho tiempo para planificar.
Debido a todos los posibles bloqueadores y la necesidad de una interrupción mínima, el enfoque puede verse como un poco complejo, y solo se vuelve más complejo si se utilizan funciones exóticas adicionales (por ejemplo, partición, OLTP en memoria o replicación) .
En un nivel muy alto, el enfoque es crear un conjunto de tablas ocultas, donde todas las inserciones se dirigen a una nueva copia de la tabla (con el tipo de datos más grande), y la existencia de los dos conjuntos de tablas es transparente. como sea posible a la aplicación y sus usuarios.
A un nivel más granular, el conjunto de pasos sería el siguiente:
- Cree instantáneas de las tablas, con los tipos de datos correctos.
- Modifique los procedimientos almacenados (o el código ad hoc) para usar bigint para los parámetros. (Esto puede requerir modificaciones más allá de la lista de parámetros, como variables locales, tablas temporales, etc., pero este no es el caso aquí).
- Cambie el nombre de las tablas antiguas y cree vistas con esos nombres que unen las tablas antiguas y nuevas.
- Esas vistas tendrán en lugar de disparadores para dirigir correctamente las operaciones DML a las tablas correspondientes, de modo que los datos aún puedan modificarse durante la migración.
- Esto también requiere que SCHEMABINDING se elimine de cualquier vista indexada, que las vistas existentes tengan uniones entre tablas nuevas y antiguas, y que se modifiquen los procedimientos que dependen de SCOPE_IDENTITY().
- Migrar los datos antiguos a las nuevas tablas en fragmentos.
- Limpieza, que consta de:
- Eliminar las vistas temporales (lo que eliminará los activadores INSTEAD OF).
- Renombrar las nuevas tablas a los nombres originales.
- Arreglar los procedimientos almacenados para volver a SCOPE_IDENTITY().
- Dejar las mesas viejas, ahora vacías.
- Volver a colocar SCHEMABINDING en vistas indexadas y volver a crear índices agrupados.
Probablemente pueda evitar gran parte de las vistas y disparadores si puede controlar todo el acceso a los datos a través de procedimientos almacenados, pero dado que ese escenario es raro (e imposible de confiar al 100%), mostraré la ruta más difícil.
Esquema inicial
En un esfuerzo por mantener este enfoque lo más simple posible, sin dejar de abordar muchos de los bloqueadores que mencioné anteriormente en la serie, supongamos que tenemos este esquema:
CREATE TABLE dbo.Employees
(
EmployeeID int IDENTITY(1,1) PRIMARY KEY,
Name nvarchar(64) NOT NULL,
LunchGroup AS (CONVERT(tinyint, EmployeeID % 5))
);
GO
CREATE INDEX EmployeeName ON dbo.Employees(Name);
GO
CREATE VIEW dbo.LunchGroupCount
WITH SCHEMABINDING
AS
SELECT LunchGroup, MemberCount = COUNT_BIG(*)
FROM dbo.Employees
GROUP BY LunchGroup;
GO
CREATE UNIQUE CLUSTERED INDEX LGC ON dbo.LunchGroupCount(LunchGroup);
GO
CREATE TABLE dbo.EmployeeFile
(
EmployeeID int NOT NULL PRIMARY KEY
FOREIGN KEY REFERENCES dbo.Employees(EmployeeID),
Notes nvarchar(max) NULL
);
GO Entonces, una tabla de personal simple, con una columna de IDENTIDAD agrupada, un índice no agrupado, una columna calculada basada en la columna IDENTIDAD, una vista indexada y una tabla de recursos humanos/sucio separada que tiene una clave externa para la tabla de personal (I no estoy necesariamente alentando ese diseño, solo lo estoy usando para este ejemplo). Todas estas son cosas que hacen que este problema sea más complicado de lo que sería si tuviéramos una mesa independiente e independiente.
Con ese esquema implementado, probablemente tengamos algunos procedimientos almacenados que hacen cosas como CRUD. Estos son más por el bien de la documentación que cualquier otra cosa; Voy a realizar cambios en el esquema subyacente de modo que el cambio de estos procedimientos sea mínimo. Esto es para simular el hecho de que puede que no sea posible cambiar el SQL ad hoc de sus aplicaciones, y puede que no sea necesario (bueno, siempre y cuando no esté usando un ORM que pueda detectar una tabla frente a una vista).
CREATE PROCEDURE dbo.Employee_Add
@Name nvarchar(64),
@Notes nvarchar(max) = NULL
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.Employees(Name)
VALUES(@Name);
INSERT dbo.EmployeeFile(EmployeeID, Notes)
VALUES(SCOPE_IDENTITY(),@Notes);
END
GO
CREATE PROCEDURE dbo.Employee_Update
@EmployeeID int,
@Name nvarchar(64),
@Notes nvarchar(max)
AS
BEGIN
SET NOCOUNT ON;
UPDATE dbo.Employees
SET Name = @Name
WHERE EmployeeID = @EmployeeID;
UPDATE dbo.EmployeeFile
SET Notes = @Notes
WHERE EmployeeID = @EmployeeID;
END
GO
CREATE PROCEDURE dbo.Employee_Get
@EmployeeID int
AS
BEGIN
SET NOCOUNT ON;
SELECT e.EmployeeID, e.Name, e.LunchGroup, ed.Notes
FROM dbo.Employees AS e
INNER JOIN dbo.EmployeeFile AS ed
ON e.EmployeeID = ed.EmployeeID
WHERE e.EmployeeID = @EmployeeID;
END
GO
CREATE PROCEDURE dbo.Employee_Delete
@EmployeeID int
AS
BEGIN
SET NOCOUNT ON;
DELETE dbo.EmployeeFile WHERE EmployeeID = @EmployeeID;
DELETE dbo.Employees WHERE EmployeeID = @EmployeeID;
END
GO Ahora, agreguemos 5 filas de datos a las tablas originales:
EXEC dbo.Employee_Add @Name = N'Employee1', @Notes = 'Employee #1 is the best'; EXEC dbo.Employee_Add @Name = N'Employee2', @Notes = 'Fewer people like Employee #2'; EXEC dbo.Employee_Add @Name = N'Employee3', @Notes = 'Jury on Employee #3 is out'; EXEC dbo.Employee_Add @Name = N'Employee4', @Notes = '#4 is moving on'; EXEC dbo.Employee_Add @Name = N'Employee5', @Notes = 'I like #5';
Paso 1:tablas nuevas
Aquí crearemos un nuevo par de tablas, reflejando las originales excepto por el tipo de datos de las columnas EmployeeID, la semilla inicial para la columna IDENTIDAD y un sufijo temporal en los nombres:
CREATE TABLE dbo.Employees_New
(
EmployeeID bigint IDENTITY(2147483648,1) PRIMARY KEY,
Name nvarchar(64) NOT NULL,
LunchGroup AS (CONVERT(tinyint, EmployeeID % 5))
);
GO
CREATE INDEX EmployeeName_New ON dbo.Employees_New(Name);
GO
CREATE TABLE dbo.EmployeeFile_New
(
EmployeeID bigint NOT NULL PRIMARY KEY
FOREIGN KEY REFERENCES dbo.Employees_New(EmployeeID),
Notes nvarchar(max) NULL
); Paso 2:arreglar los parámetros del procedimiento
Los procedimientos aquí (y potencialmente su código ad hoc, a menos que ya esté usando el tipo de entero más grande) necesitarán un cambio muy pequeño para que en el futuro puedan aceptar valores de EmployeeID más allá de los límites superiores de un entero. Si bien podría argumentar que si va a modificar estos procedimientos, simplemente podría señalarlos en las nuevas tablas, estoy tratando de demostrar que puede lograr el objetivo final con una intrusión * mínima * en el existente, permanente código.
ALTER PROCEDURE dbo.Employee_Update
@EmployeeID bigint, -- only change
@Name nvarchar(64),
@Notes nvarchar(max)
AS
BEGIN
SET NOCOUNT ON;
UPDATE dbo.Employees
SET Name = @Name
WHERE EmployeeID = @EmployeeID;
UPDATE dbo.EmployeeFile
SET Notes = @Notes
WHERE EmployeeID = @EmployeeID;
END
GO
ALTER PROCEDURE dbo.Employee_Get
@EmployeeID bigint -- only change
AS
BEGIN
SET NOCOUNT ON;
SELECT e.EmployeeID, e.Name, e.LunchGroup, ed.Notes
FROM dbo.Employees AS e
INNER JOIN dbo.EmployeeFile AS ed
ON e.EmployeeID = ed.EmployeeID
WHERE e.EmployeeID = @EmployeeID;
END
GO
ALTER PROCEDURE dbo.Employee_Delete
@EmployeeID bigint -- only change
AS
BEGIN
SET NOCOUNT ON;
DELETE dbo.EmployeeFile WHERE EmployeeID = @EmployeeID;
DELETE dbo.Employees WHERE EmployeeID = @EmployeeID;
END
GO Paso 3:vistas y disparadores
Desafortunadamente, esto no puede *todo* hacerse en silencio. Podemos realizar la mayoría de las operaciones en paralelo y sin afectar el uso concurrente, pero debido a SCHEMABINDING, la vista indexada debe modificarse y el índice debe volver a crearse más tarde.
Esto es cierto para cualquier otro objeto que use SCHEMABINDING y haga referencia a cualquiera de nuestras tablas. Recomiendo cambiarlo para que sea una vista no indexada al comienzo de la operación, y simplemente reconstruir el índice una vez que se hayan migrado todos los datos, en lugar de varias veces en el proceso (ya que las tablas cambiarán de nombre varias veces). De hecho, lo que voy a hacer es cambiar la vista para unir las versiones nueva y antigua de la tabla Empleados mientras dure el proceso.
Otra cosa que debemos hacer es cambiar el procedimiento almacenado Employee_Add para usar @@IDENTITY en lugar de SCOPE_IDENTITY(), temporalmente. Esto se debe a que el disparador INSTEAD OF que controlará las nuevas actualizaciones de "Empleados" no tendrá visibilidad del valor SCOPE_IDENTITY(). Esto, por supuesto, supone que las tablas no tienen disparadores posteriores que afectarán a @@IDENTITY. Con suerte, puede cambiar estas consultas dentro de un procedimiento almacenado (donde podría simplemente apuntar INSERTAR a la nueva tabla), o el código de su aplicación no necesita depender de SCOPE_IDENTITY() en primer lugar.
Vamos a hacer esto bajo SERIALIZABLE para que ninguna transacción intente colarse mientras los objetos están cambiando. Este es un conjunto de operaciones principalmente solo de metadatos, por lo que debería ser rápido.
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
BEGIN TRANSACTION;
GO
-- first, remove schemabinding from the view so we can change the base table
ALTER VIEW dbo.LunchGroupCount
--WITH SCHEMABINDING -- this will silently drop the index
-- and will temp. affect performance
AS
SELECT LunchGroup, MemberCount = COUNT_BIG(*)
FROM dbo.Employees
GROUP BY LunchGroup;
GO
-- rename the tables
EXEC sys.sp_rename N'dbo.Employees', N'Employees_Old', N'OBJECT';
EXEC sys.sp_rename N'dbo.EmployeeFile', N'EmployeeFile_Old', N'OBJECT';
GO
-- the view above will be broken for about a millisecond
-- until the following union view is created:
CREATE VIEW dbo.Employees
WITH SCHEMABINDING
AS
SELECT EmployeeID = CONVERT(bigint, EmployeeID), Name, LunchGroup
FROM dbo.Employees_Old
UNION ALL
SELECT EmployeeID, Name, LunchGroup
FROM dbo.Employees_New;
GO
-- now the view will work again (but it will be slower)
CREATE VIEW dbo.EmployeeFile
WITH SCHEMABINDING
AS
SELECT EmployeeID = CONVERT(bigint, EmployeeID), Notes
FROM dbo.EmployeeFile_Old
UNION ALL
SELECT EmployeeID, Notes
FROM dbo.EmployeeFile_New;
GO
CREATE TRIGGER dbo.Employees_InsteadOfInsert
ON dbo.Employees
INSTEAD OF INSERT
AS
BEGIN
SET NOCOUNT ON;
-- just needs to insert the row(s) into the new copy of the table
INSERT dbo.Employees_New(Name) SELECT Name FROM inserted;
END
GO
CREATE TRIGGER dbo.Employees_InsteadOfUpdate
ON dbo.Employees
INSTEAD OF UPDATE
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
-- need to cover multi-row updates, and the possibility
-- that any row may have been migrated already
UPDATE o SET Name = i.Name
FROM dbo.Employees_Old AS o
INNER JOIN inserted AS i
ON o.EmployeeID = i.EmployeeID;
UPDATE n SET Name = i.Name
FROM dbo.Employees_New AS n
INNER JOIN inserted AS i
ON n.EmployeeID = i.EmployeeID;
COMMIT TRANSACTION;
END
GO
CREATE TRIGGER dbo.Employees_InsteadOfDelete
ON dbo.Employees
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
-- a row may have been migrated already, maybe not
DELETE o FROM dbo.Employees_Old AS o
INNER JOIN deleted AS d
ON o.EmployeeID = d.EmployeeID;
DELETE n FROM dbo.Employees_New AS n
INNER JOIN deleted AS d
ON n.EmployeeID = d.EmployeeID;
COMMIT TRANSACTION;
END
GO
CREATE TRIGGER dbo.EmployeeFile_InsteadOfInsert
ON dbo.EmployeeFile
INSTEAD OF INSERT
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.EmployeeFile_New(EmployeeID, Notes)
SELECT EmployeeID, Notes FROM inserted;
END
GO
CREATE TRIGGER dbo.EmployeeFile_InsteadOfUpdate
ON dbo.EmployeeFile
INSTEAD OF UPDATE
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
UPDATE o SET Notes = i.Notes
FROM dbo.EmployeeFile_Old AS o
INNER JOIN inserted AS i
ON o.EmployeeID = i.EmployeeID;
UPDATE n SET Notes = i.Notes
FROM dbo.EmployeeFile_New AS n
INNER JOIN inserted AS i
ON n.EmployeeID = i.EmployeeID;
COMMIT TRANSACTION;
END
GO
CREATE TRIGGER dbo.EmployeeFile_InsteadOfDelete
ON dbo.EmployeeFile
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
DELETE o FROM dbo.EmployeeFile_Old AS o
INNER JOIN deleted AS d
ON o.EmployeeID = d.EmployeeID;
DELETE n FROM dbo.EmployeeFile_New AS n
INNER JOIN deleted AS d
ON n.EmployeeID = d.EmployeeID;
COMMIT TRANSACTION;
END
GO
-- the insert stored procedure also has to be updated, temporarily
ALTER PROCEDURE dbo.Employee_Add
@Name nvarchar(64),
@Notes nvarchar(max) = NULL
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.Employees(Name)
VALUES(@Name);
INSERT dbo.EmployeeFile(EmployeeID, Notes)
VALUES(@@IDENTITY, @Notes);
-------^^^^^^^^^^------ change here
END
GO
COMMIT TRANSACTION; Paso 4:migrar los datos antiguos a la nueva tabla
Vamos a migrar datos en fragmentos para minimizar el impacto tanto en la simultaneidad como en el registro de transacciones, tomando prestada la técnica básica de una publicación anterior mía, "Dividir operaciones de eliminación grandes en fragmentos". Vamos a ejecutar estos lotes en SERIALIZABLE también, lo que significa que querrá tener cuidado con el tamaño del lote, y he omitido el manejo de errores por brevedad.
CREATE TABLE #batches(EmployeeID int);
DECLARE @BatchSize int = 1; -- for this demo only
-- your optimal batch size will hopefully be larger
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
WHILE 1 = 1
BEGIN
INSERT #batches(EmployeeID)
SELECT TOP (@BatchSize) EmployeeID
FROM dbo.Employees_Old
WHERE EmployeeID NOT IN (SELECT EmployeeID FROM dbo.Employees_New)
ORDER BY EmployeeID;
IF @@ROWCOUNT = 0
BREAK;
BEGIN TRANSACTION;
SET IDENTITY_INSERT dbo.Employees_New ON;
INSERT dbo.Employees_New(EmployeeID, Name)
SELECT o.EmployeeID, o.Name
FROM #batches AS b
INNER JOIN dbo.Employees_Old AS o
ON b.EmployeeID = o.EmployeeID;
SET IDENTITY_INSERT dbo.Employees_New OFF;
INSERT dbo.EmployeeFile_New(EmployeeID, Notes)
SELECT o.EmployeeID, o.Notes
FROM #batches AS b
INNER JOIN dbo.EmployeeFile_Old AS o
ON b.EmployeeID = o.EmployeeID;
DELETE o FROM dbo.EmployeeFile_Old AS o
INNER JOIN #batches AS b
ON b.EmployeeID = o.EmployeeID;
DELETE o FROM dbo.Employees_Old AS o
INNER JOIN #batches AS b
ON b.EmployeeID = o.EmployeeID;
COMMIT TRANSACTION;
TRUNCATE TABLE #batches;
-- monitor progress
SELECT total = (SELECT COUNT(*) FROM dbo.Employees),
original = (SELECT COUNT(*) FROM dbo.Employees_Old),
new = (SELECT COUNT(*) FROM dbo.Employees_New);
-- checkpoint / backup log etc.
END
DROP TABLE #batches; Resultados:
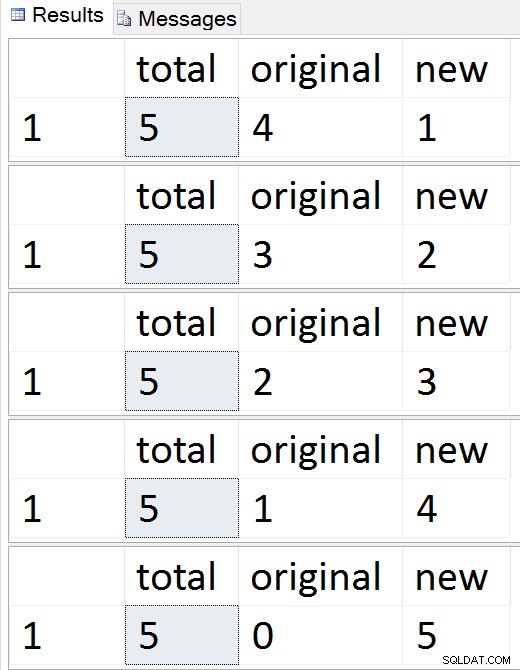 Vea las filas migrar una por una
Vea las filas migrar una por una
En cualquier momento durante esa secuencia, puede probar las inserciones, actualizaciones y eliminaciones, y deben manejarse de manera adecuada. Una vez que se completa la migración, puede continuar con el resto del proceso.
Paso 5:limpieza
Se requiere una serie de pasos para limpiar los objetos que se crearon temporalmente y restaurar Employees / EmployeeFile como ciudadanos de primera clase. Muchos de estos comandos son simplemente operaciones de metadatos; con la excepción de crear el índice agrupado en la vista indexada, todos deberían ser instantáneos.
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
BEGIN TRANSACTION;
-- drop views and restore name of new tables
DROP VIEW dbo.EmployeeFile; --v
DROP VIEW dbo.Employees; -- this will drop the instead of triggers
EXEC sys.sp_rename N'dbo.Employees_New', N'Employees', N'OBJECT';
EXEC sys.sp_rename N'dbo.EmployeeFile_New', N'EmployeeFile', N'OBJECT';
GO
-- put schemabinding back on the view, and remove the union
ALTER VIEW dbo.LunchGroupCount
WITH SCHEMABINDING
AS
SELECT LunchGroup, MemberCount = COUNT_BIG(*)
FROM dbo.Employees
GROUP BY LunchGroup;
GO
-- change the procedure back to SCOPE_IDENTITY()
ALTER PROCEDURE dbo.Employee_Add
@Name nvarchar(64),
@Notes nvarchar(max) = NULL
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.Employees(Name)
VALUES(@Name);
INSERT dbo.EmployeeFile(EmployeeID, Notes)
VALUES(SCOPE_IDENTITY(), @Notes);
END
GO
COMMIT TRANSACTION;
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
-- drop the old (now empty) tables
-- and create the index on the view
-- outside the transaction
DROP TABLE dbo.EmployeeFile_Old;
DROP TABLE dbo.Employees_Old;
GO
-- only portion that is absolutely not online
CREATE UNIQUE CLUSTERED INDEX LGC ON dbo.LunchGroupCount(LunchGroup);
GO En este punto, todo debería volver a su funcionamiento normal, aunque es posible que desee considerar las actividades de mantenimiento típicas después de cambios importantes en el esquema, como la actualización de estadísticas, la reconstrucción de índices o el desalojo de planes de la memoria caché.
Conclusión
Esta es una solución bastante compleja para lo que debería ser un problema simple. Espero que en algún momento SQL Server permita hacer cosas como agregar/eliminar la propiedad IDENTITY, reconstruir índices con nuevos tipos de datos de destino y modificar columnas en ambos lados de una relación sin sacrificar la relación. Mientras tanto, me interesaría saber si esta solución te ayuda o si tienes un enfoque diferente.
Un gran agradecimiento a James Lupolt (@jlupoltsql) por ayudarme a controlar mi cordura y ponerlo a prueba en una de sus propias mesas reales. (Salió bien. ¡Gracias, James!)
—
[ Parte 1 | Parte 2 | Parte 3 | Parte 4 ]