Ahora, nuestra comunidad de análisis de big data ha comenzado a utilizar Apache Spark a pleno rendimiento para el procesamiento de big data. El procesamiento podría ser para consultas ad-hoc, consultas preconstruidas, procesamiento de gráficos, aprendizaje automático e incluso para la transmisión de datos.
Por lo tanto, la comprensión de Spark Job Submission es muy vital para la comunidad. Extienda a ese feliz de compartir con usted los aprendizajes de los pasos involucrados en el envío de trabajos de Apache Spark.
Básicamente tiene dos pasos,

Envío de trabajos
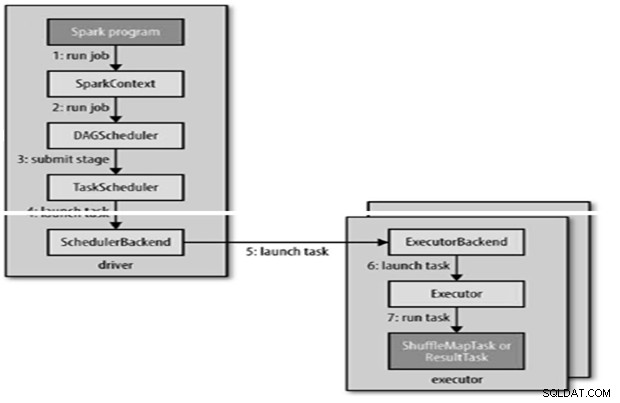
El trabajo de Spark se envía automáticamente cuando se realiza una acción como contar () en un RDD.
RunJob() internamente para ser llamado en SparkContext y luego llamar al programador que se ejecuta como parte del derivador.
El programador se compone de 2 partes:Programador DAG y Programador de tareas.
Construcción DAG
Hay dos tipos de construcciones DAG,

- El trabajo de Spark simple es aquel que no necesita una mezcla y, por lo tanto, tiene una sola etapa compuesta de tareas de resultado, como el trabajo de solo mapa en MapReduce
- El trabajo Spark complejo involucra operaciones de agrupación y requiere una o más etapas de reproducción aleatoria.
- El planificador DAG de Spark convierte el trabajo en dos etapas.
- El programador de DAG es responsable de dividir una etapa en tareas para enviarlas al programador de tareas.
- El programador de DAG le da a cada tarea una preferencia de ubicación para permitir que el programador de tareas aproveche la ubicación de los datos.
- Las etapas secundarias solo se envían una vez que sus padres las han completado con éxito.
Programación de tareas
- El programador de tareas enviará un conjunto de tareas; utiliza su lista de ejecutores que se ejecutan para la aplicación y crea una asignación de tareas a ejecutores que tiene en cuenta las preferencias de ubicación.
- El programador de tareas se asigna a ejecutores que tienen núcleos libres, a cada tarea se le asigna un núcleo de forma predeterminada. Se puede cambiar mediante el parámetro spark.task.cpus.
- Spark utiliza Akka, que es una plataforma basada en actores para crear aplicaciones distribuidas impulsadas por eventos altamente escalables.
- Spark no usa Hadoop RPC para llamadas remotas.
Ejecución de tareas
Un ejecutor ejecuta una tarea de la siguiente manera,
- Se asegura de que las dependencias de archivo y JAR para la tarea estén actualizadas.
- Deserializa el código de la tarea.
- El código de la tarea se ejecuta.
- Task devuelve resultados al controlador, que se ensambla en un resultado final para devolver al usuario.
Referencia
- La guía definitiva de Hadoop
- Comunidad de análisis y Big Data de código abierto
Este artículo apareció originalmente aquí. Republicado con permiso. Envíe sus quejas de derechos de autor aquí.