Todos los productos tienen errores y SQL Server no es una excepción. Usar las características del producto de una manera un poco inusual (o combinar características relativamente nuevas) es una excelente manera de encontrarlas. Los errores pueden ser interesantes e incluso educativos, pero tal vez parte de la alegría se pierda cuando el descubrimiento hace que su localizador suene a las 4 a. m., tal vez después de una noche particularmente social con amigos...
El error que es el tema de esta publicación probablemente sea razonablemente raro en la naturaleza, pero no es un caso extremo clásico. Sé de al menos un consultor que lo ha encontrado en un sistema de producción. En un tema completamente ajeno, debería aprovechar esta oportunidad para saludar al Grumpy Old DBA (blog).
Comenzaré con algunos antecedentes relevantes sobre las uniones de fusión. Si está seguro de que ya sabe todo lo que hay que saber sobre la combinación de combinación, o simplemente quiere ir al grano, siéntase libre de desplazarse hacia abajo hasta la sección titulada "El error".
Fusionar unirse
Fusionar y unir no es algo terriblemente complicado y puede ser muy eficiente en las circunstancias adecuadas. Requiere que sus entradas estén ordenadas en las claves de unión y funciona mejor en modo uno a muchos (donde al menos una de sus entradas es única en las claves de unión). Para combinaciones de uno a varios de tamaño moderado, la combinación de combinación en serie no es una mala elección, siempre que los requisitos de clasificación de entrada se puedan cumplir sin realizar una clasificación explícita.
La mayoría de las veces, evitar una ordenación se logra explotando la ordenación proporcionada por un índice. La unión por fusión también puede aprovechar el orden de clasificación preservado de una clasificación anterior e inevitable. Lo bueno de la combinación de combinación es que puede dejar de procesar las filas de entrada tan pronto como cualquiera de las entradas se quede sin filas. Una última cosa:a merge join no le importa si el orden de entrada es ascendente o descendente (aunque ambas entradas deben ser iguales). El siguiente ejemplo utiliza una tabla de números estándar para ilustrar la mayoría de los puntos anteriores:
CREATE TABLE #T1 (col1 integer CONSTRAINT PK1 PRIMARY KEY (col1 DESC)); CREATE TABLE #T2 (col1 integer CONSTRAINT PK2 PRIMARY KEY (col1 DESC)); INSERT #T1 SELECT n FROM dbo.Numbers WHERE n BETWEEN 10000 AND 19999; INSERT #T2 SELECT n FROM dbo.Numbers WHERE n BETWEEN 18000 AND 21999;
Tenga en cuenta que los índices que imponen las claves principales en esas dos tablas se definen como descendentes. El plan de consulta para INSERT tiene una serie de características interesantes:
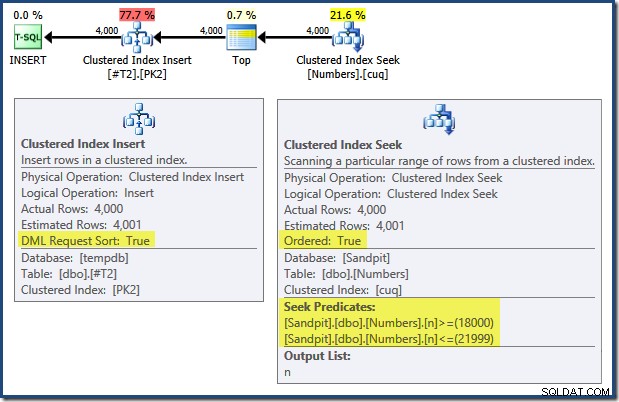
Al leer de izquierda a derecha (¡como es sensato!), la inserción de índice agrupado tiene establecida la propiedad "Ordenación de solicitud DML". Esto significa que el operador requiere filas en orden de clave de índice agrupado. El índice agrupado (que impone la clave principal en este caso) se define como DESC , por lo que las filas con valores más altos deben llegar primero. El índice agrupado en mi tabla Numbers es ASC , por lo que el optimizador de consultas evita una ordenación explícita al buscar primero la coincidencia más alta en la tabla Numbers (21 999) y luego buscar la coincidencia más baja (18 000) en orden de índice inverso. La vista "Árbol del plan" en SQL Sentry Plan Explorer muestra claramente el escaneo inverso (hacia atrás):
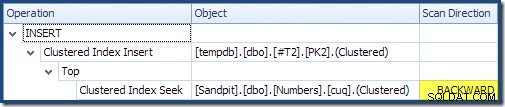
La exploración hacia atrás invierte el orden natural del índice. Un escaneo hacia atrás de un ASC la clave de índice devuelve filas en orden de clave descendente; un escaneo hacia atrás de un DESC index key devuelve filas en orden de clave ascendente. La "dirección de escaneo" no indica el orden de la clave devuelta por sí misma; debe saber si el índice es ASC o DESC para tomar esa determinación.
Usando estas tablas de prueba y datos (T1 tiene 10.000 filas numeradas del 10.000 al 19.999 inclusive; T2 tiene 4000 filas numeradas del 18 000 al 21 999), la siguiente consulta une las dos tablas y devuelve los resultados en orden descendente de ambas claves:
SELECT
T1.col1,
T2.col1
FROM #T1 AS T1
JOIN #T2 AS T2
ON T2.col1 = T1.col1
ORDER BY
T1.col1 DESC,
T2.col1 DESC; La consulta devuelve las 2000 filas coincidentes correctas como cabría esperar. El plan posterior a la ejecución es el siguiente:
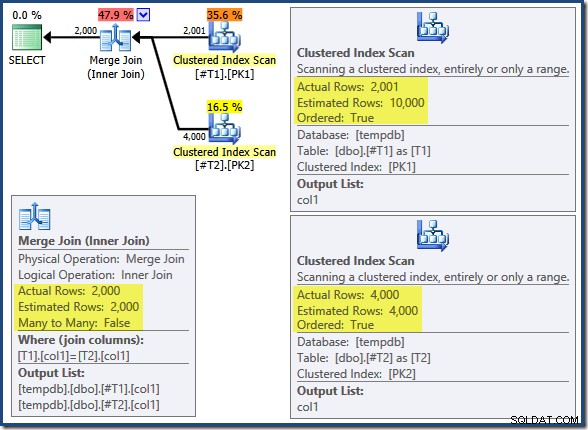
Merge Join no se ejecuta en modo muchos a muchos (la entrada superior es única en las claves de combinación) y la estimación de cardinalidad de 2000 filas es exactamente correcta. La exploración del índice agrupado de la tabla T2 está ordenado (aunque tenemos que esperar un momento para descubrir si ese orden es hacia adelante o hacia atrás) y la cardinalidad estimada de 4000 filas también es exactamente correcta. La exploración del índice agrupado de la tabla T1 también se ordena, pero solo se leyeron 2.001 filas mientras que se estimaron 10.000. La vista de árbol del plan muestra que ambos escaneos de índices agrupados están ordenados hacia adelante:
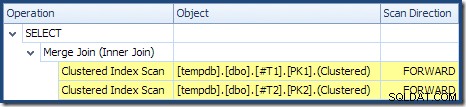
Recuerda que leer un DESC índice FORWARD producirá filas en orden de clave inverso. Esto es exactamente lo que requiere ORDER BY T1.col DESC, T2.col1 DESC cláusula, por lo que no es necesaria una ordenación explícita. El pseudocódigo para Merge Join de uno a muchos (reproducido del blog Merge Join de Craig Freedman) es:

El escaneo en orden descendente de T1 devuelve filas que comienzan en 19 999 y van descendiendo hasta 10 000. El escaneo en orden descendente de T2 devuelve filas que comienzan en 21 999 y van descendiendo hasta 18 000. Las 4000 filas en T2 finalmente se leen, pero el proceso iterativo de fusión se detiene cuando se lee el valor de clave 17,999 de T1 , porque T2 se queda sin filas. Por lo tanto, el procesamiento de combinación se completa sin leer completamente T1 . Lee filas desde 19.999 hasta 17.999 inclusive; un total de 2001 filas como se muestra en el plan de ejecución anterior.
Siéntase libre de volver a ejecutar la prueba con ASC índices en su lugar, también cambiando el ORDER BY cláusula de DESC a ASC . El plan de ejecución producido será muy similar y no se necesitarán ordenaciones.
Para resumir los puntos que serán importantes en un momento, Merge Join requiere entradas ordenadas por clave de unión, pero no importa si las claves están ordenadas de forma ascendente o descendente.
El bicho
Para reproducir el error, al menos una de nuestras tablas debe particionarse. Para mantener los resultados manejables, este ejemplo usará solo una pequeña cantidad de filas, por lo que la función de partición también necesita límites pequeños:
CREATE PARTITION FUNCTION PF (integer) AS RANGE RIGHT FOR VALUES (5, 10, 15); CREATE PARTITION SCHEME PS AS PARTITION PF ALL TO ([PRIMARY]);
La primera tabla contiene dos columnas y está dividida en PRIMARY KEY:
CREATE TABLE dbo.T1
(
T1ID integer IDENTITY (1,1) NOT NULL,
SomeID integer NOT NULL,
CONSTRAINT [PK dbo.T1 T1ID]
PRIMARY KEY CLUSTERED (T1ID)
ON PS (T1ID)
);
La segunda tabla no está dividida. Contiene una clave principal y una columna que se unirá a la primera tabla:
CREATE TABLE dbo.T2
(
T2ID integer IDENTITY (1,1) NOT NULL,
T1ID integer NOT NULL,
CONSTRAINT [PK dbo.T2 T2ID]
PRIMARY KEY CLUSTERED (T2ID)
ON [PRIMARY]
); Los datos de muestra
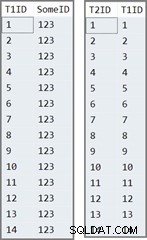
La primera tabla tiene 14 filas, todas con el mismo valor en SomeID columna. SQL Server asigna la IDENTITY valores de columna, numerados del 1 al 14.
INSERT dbo.T1
(SomeID)
VALUES
(123), (123), (123),
(123), (123), (123),
(123), (123), (123),
(123), (123), (123),
(123), (123);
La segunda tabla simplemente se completa con la IDENTITY valores de la tabla uno:
INSERT dbo.T2 (T1ID) SELECT T1ID FROM dbo.T1;
Los datos en las dos tablas se ven así:
La consulta de prueba
La primera consulta simplemente une ambas tablas, aplicando un solo predicado de cláusula WHERE (que coincide con todas las filas en este ejemplo muy simplificado):
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123; El resultado contiene las 14 filas, como se esperaba:

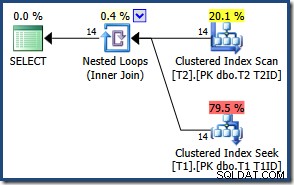
Debido al pequeño número de filas, el optimizador elige un plan de combinación de bucles anidados para esta consulta:
Los resultados son los mismos (y siguen siendo correctos) si forzamos una combinación hash o merge:
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123
OPTION (HASH JOIN);
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123
OPTION (MERGE JOIN);
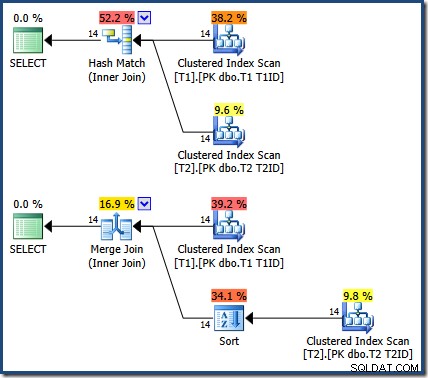
El Merge Join allí es de uno a muchos, con una ordenación explícita en T1ID requerido para la tabla T2 .
El problema del índice descendente
Todo va bien hasta que un día (por buenas razones que no nos conciernen aquí) otro administrador agrega un índice descendente en SomeID columna de la tabla 1:
CREATE NONCLUSTERED INDEX [dbo.T1 SomeID] ON dbo.T1 (SomeID DESC);
Nuestra consulta continúa produciendo resultados correctos cuando el optimizador elige un bucle anidado o una combinación hash, pero es una historia diferente cuando se utiliza una combinación combinada. Lo siguiente aún usa una sugerencia de consulta para forzar la combinación de combinación, pero esto es solo una consecuencia del recuento bajo de filas en el ejemplo. El optimizador elegiría naturalmente el mismo plan Merge Join con diferentes datos de tabla.
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123
OPTION (MERGE JOIN); El plan de ejecución es:
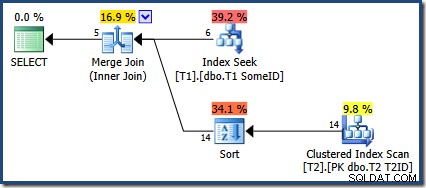
El optimizador eligió usar el nuevo índice, pero la consulta ahora produce solo cinco filas de salida:

¿Qué pasó con las otras 9 filas? Para ser claros, este resultado es incorrecto. Los datos no han cambiado, por lo que se deben devolver las 14 filas (como todavía lo son con un plan de bucles anidados o unión hash).
Causa y explicación
El nuevo índice no agrupado en SomeID no se declara como único, por lo que la clave de índice agrupado se agrega silenciosamente a todos los niveles de índice no agrupados. SQL Server agrega el T1ID columna (la clave agrupada) al índice no agrupado como si hubiéramos creado el índice así:
CREATE NONCLUSTERED INDEX [dbo.T1 SomeID] ON dbo.T1 (SomeID DESC, T1ID);
Observe la falta de un DESC calificador en el T1ID agregado silenciosamente llave. Las claves de índice son ASC por defecto. Esto no es un problema en sí mismo (aunque contribuye). Lo segundo que le sucede a nuestro índice automáticamente es que se particiona de la misma manera que la tabla base. Entonces, la especificación completa del índice, si tuviéramos que escribirlo explícitamente, sería:
CREATE NONCLUSTERED INDEX [dbo.T1 SomeID] ON dbo.T1 (SomeID DESC, T1ID ASC) ON PS (T1ID);
Esta es ahora una estructura bastante compleja, con claves en todo tipo de órdenes diferentes. Es lo suficientemente complejo como para que el optimizador de consultas se equivoque al razonar sobre el orden de clasificación proporcionado por el índice. Para ilustrar, considere la siguiente consulta simple:
SELECT
T1ID,
PartitionID = $PARTITION.PF(T1ID)
FROM dbo.T1
WHERE
SomeID = 123
ORDER BY
T1ID ASC;
La columna adicional solo nos mostrará a qué partición pertenece la fila actual. De lo contrario, es solo una consulta simple que devuelve T1ID valores en orden ascendente, WHERE SomeID = 123 . Desafortunadamente, los resultados no son los especificados por la consulta:
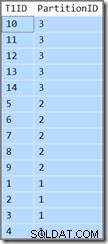
La consulta requiere que T1ID los valores deben devolverse en orden ascendente, pero eso no es lo que obtenemos. Obtenemos valores en orden ascendente por partición , ¡pero las particiones mismas se devuelven en orden inverso! Si las particiones se devolvieron en orden ascendente (y el T1ID los valores permanecieron ordenados dentro de cada partición como se muestra), el resultado sería correcto.
El plan de consulta muestra que el DESC principal confundió al optimizador clave del índice, y pensé que necesitaba leer las particiones en orden inverso para obtener resultados correctos:
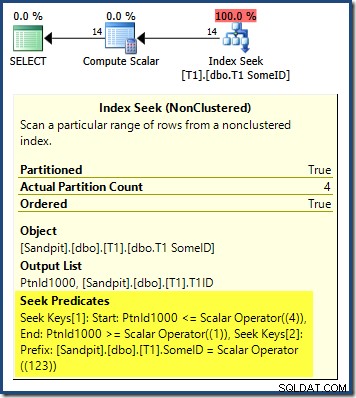
La búsqueda de partición comienza en la partición más a la derecha (4) y continúa hacia atrás hasta la partición 1. Podría pensar que podríamos solucionar el problema ordenando explícitamente el número de partición ASC en el ORDER BY cláusula:
SELECT
T1ID,
PartitionID = $PARTITION.PF(T1ID)
FROM dbo.T1
WHERE
SomeID = 123
ORDER BY
PartitionID ASC, -- New!
T1ID ASC; Esta consulta devuelve los mismos resultados (esto no es un error tipográfico o un error de copiar/pegar):
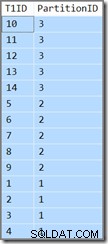
La identificación de la partición todavía está en descendente orden (no ascendente, como se especifica) y T1ID solo se ordena de forma ascendente dentro de cada partición. Tal es la confusión del optimizador, que realmente piensa (respire hondo ahora) que escanear el índice de clave principal-descendente particionado en una dirección hacia adelante, pero con las particiones invertidas, dará como resultado el orden especificado por la consulta.
Para ser sincero, no lo culpo, las diversas consideraciones del orden de clasificación también me duelen la cabeza.
Como ejemplo final, considere:
SELECT
T1ID
FROM dbo.T1
WHERE
SomeID = 123
ORDER BY
T1ID DESC; Los resultados son:

Nuevamente, el T1ID orden de clasificación dentro de cada partición desciende correctamente, pero las particiones en sí se enumeran al revés (van del 1 al 3 en las filas). Si las particiones se devolvieran en orden inverso, los resultados serían correctamente 14, 13, 12, 11, 10, 9, … 5, 4, 3, 2, 1 .
Volver a la unión de fusión
La causa de los resultados incorrectos con la consulta Merge Join ahora es evidente:
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123
OPTION (MERGE JOIN);
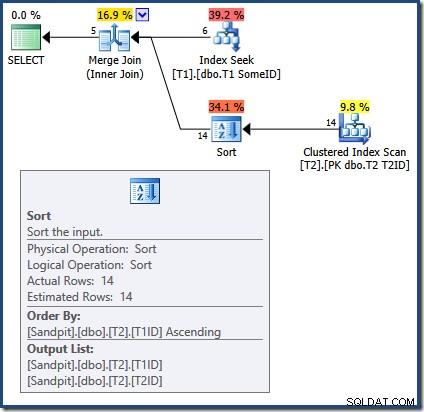
Merge Join requiere entradas ordenadas. La entrada de T2 está ordenado explícitamente por T1TD así que está bien. El optimizador razona incorrectamente que el índice en T1 puede proporcionar filas en T1ID pedido. Como hemos visto, este no es el caso. Index Seek produce el mismo resultado que una consulta que ya hemos visto:
SELECT
T1ID
FROM dbo.T1
WHERE
SomeID = 123
ORDER BY
T1ID ASC;

Solo las primeras 5 filas están en T1ID pedido. El siguiente valor (5) ciertamente no está en orden ascendente, y Merge Join interpreta esto como el final de la transmisión en lugar de producir un error (personalmente, esperaba una afirmación minorista aquí). De todos modos, el efecto es que Merge Join termina incorrectamente el procesamiento antes de tiempo. Como recordatorio, los resultados (incompletos) son:

Conclusión
Este es un error muy serio en mi opinión. Una búsqueda de índice simple puede arrojar resultados que no respetan el ORDER BY cláusula. Más concretamente, el razonamiento interno del optimizador está completamente roto para índices no agrupados no únicos particionados con una clave inicial descendente.
Sí, esto es un ligeramente arreglo inusual. Pero, como hemos visto, los resultados correctos pueden ser reemplazados repentinamente por resultados incorrectos solo porque alguien agregó un índice descendente. Recuerde que el índice agregado parecía lo suficientemente inocente:sin ASC/DESC explícito discrepancia de clave y sin partición explícita.
El error no se limita a Merge Joins. Potencialmente, cualquier consulta que involucre una tabla particionada y que se base en el orden de clasificación del índice (explícito o implícito) podría ser víctima. Este error existe en todas las versiones de SQL Server desde 2008 hasta 2014 CTP 1 inclusive. La base de datos de Windows SQL Azure no admite la creación de particiones, por lo que el problema no surge. SQL Server 2005 usó un modelo de implementación diferente para la partición (basado en APPLY ) y tampoco sufre de este problema.
Si tiene un momento, considere votar en mi elemento Connect para este error.
Resolución
La solución para este problema ya está disponible y documentada en un artículo de la base de conocimientos. Tenga en cuenta que la solución requiere una actualización de código y un indicador de rastreo 4199 , que habilita una variedad de otros cambios en el procesador de consultas. Es inusual que se solucione un error de resultados incorrectos en 4199. Pedí una aclaración al respecto y la respuesta fue:
Aunque este problema implica resultados incorrectos, como otras revisiones relacionadas con el Procesador de consultas, solo habilitamos esta corrección bajo el indicador de seguimiento 4199 para SQL Server 2008, 2008 R2 y 2012. Sin embargo, esta corrección está "activada" por predeterminado sin el indicador de seguimiento en SQL Server 2014 RTM.