En un hilo reciente en StackExchange, un usuario tuvo el siguiente problema:
Quiero una consulta que devuelva la primera persona de la tabla con GroupID =2. Si no existe nadie con GroupID =2, quiero la primera persona con RoleID =2.
Descartemos, por ahora, el hecho de que "primero" está terriblemente definido. En realidad, al usuario no le importaba qué persona obtenía, ya fuera de forma aleatoria, arbitraria o mediante alguna lógica explícita además de su criterio principal. Ignorando eso, digamos que tienes una tabla básica:
CREATE TABLE dbo.Users ( UserID INT PRIMARY KEY, GroupID INT, RoleID INT );
En el mundo real, probablemente haya otras columnas, restricciones adicionales, tal vez claves externas para otras tablas y, ciertamente, otros índices. Pero mantengamos esto simple y propongamos una consulta.
Soluciones probables
Con ese diseño de mesa, resolver el problema parece sencillo, ¿verdad? El primer intento que probablemente haría es:
SELECT TOP (1) UserID, GroupID, RoleID FROM dbo.Users WHERE GroupID = 2 OR RoleID = 2 ORDER BY CASE GroupID WHEN 2 THEN 1 ELSE 2 END;
Esto usa TOP y un condicional ORDER BY para tratar a aquellos usuarios con un GroupID =2 como prioridad más alta. El plan para esta consulta es bastante simple, y la mayor parte del costo ocurre en una operación de clasificación. Estas son las métricas de tiempo de ejecución en una tabla vacía:
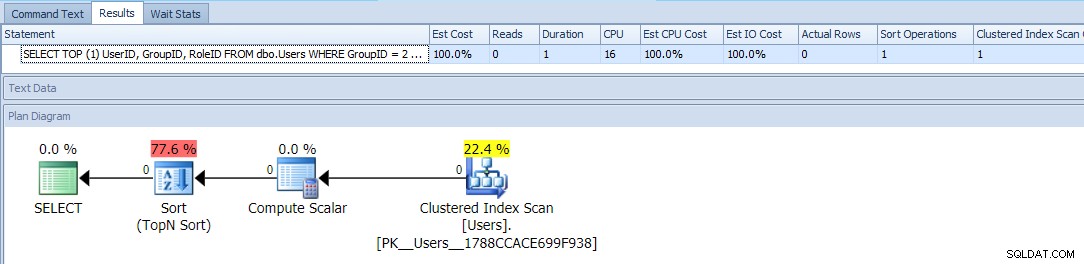
Esto parece ser lo mejor que puede hacer:un plan simple que solo escanea la tabla una vez, y aparte de un tipo molesto con el que debería poder vivir, no hay problema, ¿verdad?
Bueno, otra respuesta en el hilo ofreció esta variación más compleja:
SELECT TOP (1) UserID, GroupID, RoleID FROM ( SELECT TOP (1) UserID, GroupID, RoleID, o = 1 FROM dbo.Users WHERE GroupId = 2 UNION ALL SELECT TOP (1) UserID, GroupID, RoleID, o = 2 FROM dbo.Users WHERE RoleID = 2 ) AS x ORDER BY o;
A primera vista, probablemente pensaría que esta consulta es extremadamente menos eficiente, ya que requiere dos escaneos de índice agrupados. Definitivamente tendrías razón en eso; aquí está el plan y las métricas de tiempo de ejecución en una tabla vacía:
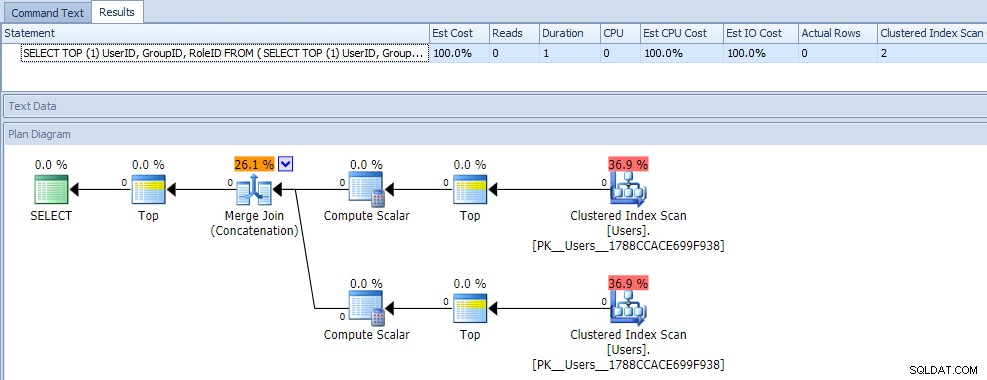
Pero ahora, agreguemos datos
Para probar estas consultas, quería usar algunos datos realistas. Entonces, primero llené 1000 filas de sys.all_objects, con operaciones de módulo contra object_id para obtener una distribución decente:
INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (1000) ABS([object_id]), ABS([object_id]) % 7, ABS([object_id]) % 4 FROM sys.all_objects ORDER BY [object_id]; SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 126 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 248 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 26 overlap
Ahora, cuando ejecuto las dos consultas, aquí están las métricas de tiempo de ejecución:

La versión UNION ALL viene con un poco menos de E/S (4 lecturas frente a 5), una duración más baja y un costo total estimado más bajo, mientras que la versión ORDER BY condicional tiene un costo de CPU estimado más bajo. Los datos aquí son bastante pequeños para sacar conclusiones; Solo lo quería como una estaca en el suelo. Ahora, cambiemos la distribución para que la mayoría de las filas cumplan al menos uno de los criterios (y a veces ambos):
DROP TABLE dbo.Users; GO CREATE TABLE dbo.Users ( UserID INT PRIMARY KEY, GroupID INT, RoleID INT ); GO INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (1000) ABS([object_id]), ABS([object_id]) % 2 + 1, SUBSTRING(RTRIM([object_id]),7,1) % 2 + 1 FROM sys.all_objects WHERE ABS([object_id]) > 9999999 ORDER BY [object_id]; SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 500 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 475 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 221 overlap
Esta vez, el pedido condicional por tiene los costos estimados más altos tanto en CPU como en E/S:

Pero nuevamente, con este tamaño de datos, hay un impacto relativamente intrascendente en la duración y las lecturas, y aparte de los costos estimados (que de todos modos se compensan en gran medida), es difícil declarar un ganador aquí.
Entonces, agreguemos muchos más datos
Aunque prefiero disfrutar creando datos de muestra a partir de las vistas del catálogo, ya que todo el mundo las tiene, esta vez voy a dibujar en la tabla Sales.SalesOrderHeaderEnlarged de AdventureWorks2012, ampliado con este script de Jonathan Kehayias. En mi sistema, esta tabla tiene 1 258 600 filas. El siguiente script insertará un millón de esas filas en nuestra tabla dbo.Users:
-- DROP and CREATE, as before INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (1000000) SalesOrderID, SalesOrderID % 7, SalesOrderID % 4 FROM Sales.SalesOrderHeaderEnlarged; SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 142,857 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 250,000 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 35,714 overlap
Bien, ahora cuando ejecutamos las consultas, vemos un problema:la variación ORDER BY se ha vuelto paralela y ha borrado tanto las lecturas como la CPU, lo que produce una diferencia de duración de casi 120X:
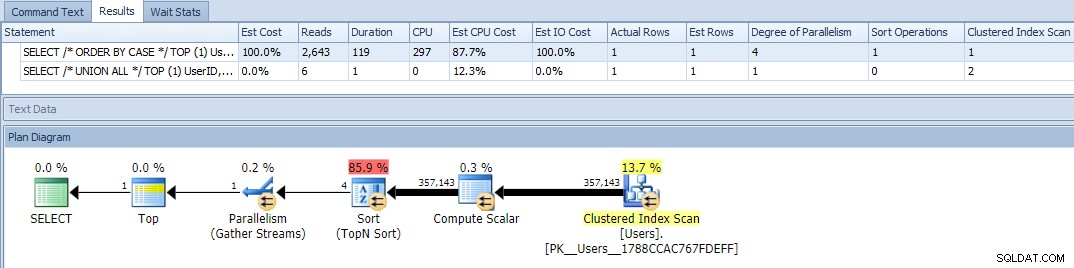
Eliminar el paralelismo (usando MAXDOP) no ayudó:
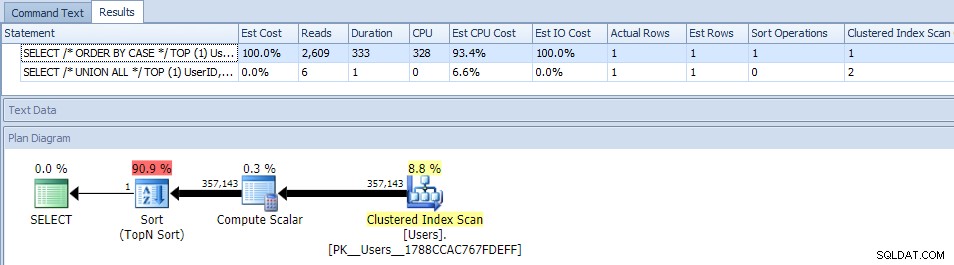
(El plan UNION ALL sigue siendo el mismo).
Y si cambiamos el sesgo para que sea uniforme, donde el 95 % de las filas cumplen al menos un criterio:
-- DROP and CREATE, as before INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (475000) SalesOrderID, 2, SalesOrderID % 7 FROM Sales.SalesOrderHeaderEnlarged WHERE SalesOrderID % 2 = 1 UNION ALL SELECT TOP (475000) SalesOrderID, SalesOrderID % 7, 2 FROM Sales.SalesOrderHeaderEnlarged WHERE SalesOrderID % 2 = 0; INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (50000) SalesOrderID, 1, 1 FROM Sales.SalesOrderHeaderEnlarged AS h WHERE NOT EXISTS (SELECT 1 FROM dbo.Users WHERE UserID = h.SalesOrderID); SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 542,851 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 542,851 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 135,702 overlap
Las consultas todavía muestran que el tipo es prohibitivamente caro:

Y con MAXDOP =1 fue mucho peor (solo mira la duración):

Finalmente, ¿qué tal un sesgo del 95% en cualquier dirección (por ejemplo, la mayoría de las filas satisfacen los criterios de GroupID, o la mayoría de las filas satisfacen los criterios de RoleID)? Este script garantizará que al menos el 95 % de los datos tengan GroupID =2:
-- DROP and CREATE, as before INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (950000) SalesOrderID, 2, SalesOrderID % 7 FROM Sales.SalesOrderHeaderEnlarged; INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (50000) SalesOrderID, SalesOrderID % 7, 2 FROM Sales.SalesOrderHeaderEnlarged AS h WHERE NOT EXISTS (SELECT 1 FROM dbo.Users WHERE UserID = h.SalesOrderID); SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 957,143 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 185,714 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 142,857 overlap
Los resultados son bastante similares (de ahora en adelante dejaré de probar MAXDOP):

Y luego, si nos inclinamos hacia el otro lado, donde al menos el 95% de los datos tienen RoleID =2:
-- DROP and CREATE, as before INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (950000) SalesOrderID, 2, SalesOrderID % 7 FROM Sales.SalesOrderHeaderEnlarged; INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (50000) SalesOrderID, SalesOrderID % 7, 2 FROM Sales.SalesOrderHeaderEnlarged AS h WHERE NOT EXISTS (SELECT 1 FROM dbo.Users WHERE UserID = h.SalesOrderID); SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 185,714 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 957,143 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 142,857 overlap
Resultados:

Conclusión
En ninguno de los casos que pude fabricar, la consulta ORDER BY "más simple", incluso con un escaneo de índice agrupado menos, superó a la consulta UNION ALL más compleja. A veces, debe tener mucho cuidado con lo que tiene que hacer SQL Server cuando introduce operaciones como ordenar en la semántica de su consulta, y no confiar solo en la simplicidad del plan (no importa cualquier sesgo que pueda tener basado en escenarios anteriores).
Su primer instinto a menudo puede ser correcto, pero apuesto a que hay momentos en que hay una mejor opción que parece, en la superficie, como si no pudiera funcionar mejor. Como en este ejemplo. Estoy mejorando un poco en cuanto a cuestionar las suposiciones que hice a partir de las observaciones, y no hacer declaraciones generales como "los escaneos nunca funcionan bien" y "las consultas más simples siempre se ejecutan más rápido". Si elimina las palabras nunca y siempre de su vocabulario, es posible que se encuentre poniendo a prueba más de esas suposiciones y declaraciones generales, y termine mucho mejor.