El mes pasado publiqué un desafío para crear un generador de series de números eficiente. Las respuestas fueron abrumadoras. Hubo muchas ideas y sugerencias brillantes, con muchas aplicaciones más allá de este desafío en particular. Me hizo darme cuenta de lo maravilloso que es ser parte de una comunidad y de que se pueden lograr cosas asombrosas cuando un grupo de personas inteligentes se une. Gracias a Alan Burstein, Joe Obbish, Adam Machanic, Christopher Ford, Jeff Moden, Charlie, NoamGr, Kamil Kosno, Dave Mason y John Number2 por compartir sus ideas y comentarios.
Inicialmente pensé en escribir un solo artículo para resumir las ideas que la gente envió, pero había demasiadas. Así que dividiré la cobertura en varios artículos. Este mes me centraré principalmente en las mejoras sugeridas por Charlie y Alan Burstein a las dos soluciones originales que publiqué el mes pasado en forma de TVF en línea llamados dbo.GetNumsItzikBatch y dbo.GetNumsItzik. Llamaré a las versiones mejoradas dbo.GetNumsAlanCharlieItzikBatch y dbo.GetNumsAlanCharlieItzik, respectivamente.
¡Esto es tan emocionante!
Las soluciones originales de Itzik
Como recordatorio rápido, las funciones que cubrí el mes pasado usan un CTE base que define un constructor de valores de tabla con 16 filas. Las funciones utilizan una serie de CTE en cascada, cada uno de los cuales aplica un producto (unión cruzada) de dos instancias de su CTE anterior. De esta forma, con cinco CTE más allá del base, se puede obtener un conjunto de hasta 4.294.967.296 filas. Un CTE llamado Nums usa la función ROW_NUMBER para producir una serie de números que comienzan con 1. Finalmente, la consulta externa calcula los números en el rango solicitado entre las entradas @low y @high.
La función dbo.GetNumsItzikBatch usa una unión ficticia a una tabla con un índice de almacén de columnas para obtener el procesamiento por lotes. Aquí está el código para crear la tabla ficticia:
CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
Y aquí está el código que define la función dbo.GetNumsItzikBatch:
CREATE OR ALTER FUNCTION dbo.GetNumsItzikBatch(@low AS BIGINT, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum; Usé el siguiente código para probar la función con "Descartar resultados después de la ejecución" habilitado en SSMS:
SELECT n FROM dbo.GetNumsItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Estas son las estadísticas de rendimiento que obtuve para esta ejecución:
CPU time = 16985 ms, elapsed time = 18348 ms.
La función dbo.GetNumsItzik es similar, solo que no tiene una unión ficticia y normalmente se procesa en modo de fila en todo el plan. Aquí está la definición de la función:
CREATE OR ALTER FUNCTION dbo.GetNumsItzik(@low AS BIGINT, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; Aquí está el código que usé para probar la función:
SELECT n FROM dbo.GetNumsItzik(1, 100000000) OPTION(MAXDOP 1);
Estas son las estadísticas de rendimiento que obtuve para esta ejecución:
CPU time = 19969 ms, elapsed time = 21229 ms.
Mejoras de Alan Burstein y Charlie
Alan y Charlie sugirieron varias mejoras a mis funciones, algunas con implicaciones de rendimiento moderadas y otras más dramáticas. Comenzaré con los hallazgos de Charlie con respecto a la sobrecarga de compilación y el plegado constante. Luego cubriré las sugerencias de Alan, incluidas las secuencias basadas en 1 frente a las basadas en @low (también compartidas por Charlie y Jeff Moden), evitando ordenar innecesariamente y calculando un rango de números en orden opuesto.
Hallazgos de tiempo de compilación
Como señaló Charlie, a menudo se usa un generador de series numéricas para generar series con un número muy pequeño de filas. En esos casos, el tiempo de compilación del código puede convertirse en una parte sustancial del tiempo total de procesamiento de consultas. Eso es especialmente importante cuando se usan iTVF, ya que, a diferencia de los procedimientos almacenados, no es el código de consulta parametrizado el que se optimiza, sino el código de consulta después de que se lleva a cabo la incrustación de parámetros. En otras palabras, los parámetros se sustituyen por los valores de entrada antes de la optimización y el código con las constantes se optimiza. Este proceso puede tener implicaciones tanto negativas como positivas. Una de las implicaciones negativas es que obtiene más compilaciones a medida que se llama a la función con diferentes valores de entrada. Por esta razón, definitivamente se deben tener en cuenta los tiempos de compilación, especialmente cuando se usa la función con mucha frecuencia con rangos pequeños.
Estos son los tiempos de compilación que encontró Charlie para las distintas cardinalidades base de CTE:
2: 22ms 4: 9ms 16: 7ms 256: 35ms
Es curioso ver que entre estos, 16 es el óptimo, y que hay un salto muy dramático cuando subes al siguiente nivel, que es 256. Recuerda que las funciones dbo.GetNumsItzikBacth y dbo.GetNumsItzik usan cardinalidad base CTE de 16 .
Plegado constante
El plegado constante suele ser una implicación positiva que, en las condiciones adecuadas, puede habilitarse gracias al proceso de incorporación de parámetros que experimenta un iTVF. Por ejemplo, suponga que su función tiene una expresión @x + 1, donde @x es un parámetro de entrada de la función. Invoca la función con @x =5 como entrada. La expresión en línea luego se convierte en 5 + 1, y si es elegible para el plegado constante (más sobre esto en breve), entonces se convierte en 6. Si esta expresión es parte de una expresión más elaborada que involucra columnas y se aplica a muchos millones de filas, esto puede dan como resultado ahorros no despreciables en ciclos de CPU.
La parte complicada es que SQL Server es muy exigente con lo que debe ser constante y lo que no debe ser constante. Por ejemplo, SQL Server no constante fold col1 + 5 + 1, ni doblará 5 + col1 + 1. Pero doblará 5 + 1 + col1 a 6 + col1. Lo sé. Entonces, por ejemplo, si su función devolvió SELECT @x + col1 + 1 AS mycol1 FROM dbo.T1, podría habilitar el plegado constante con la siguiente pequeña modificación:SELECT @x + 1 + col1 AS mycol1 FROM dbo.T1. ¿No me crees? Examine los planes para las siguientes tres consultas en la base de datos de PerformanceV5 (o consultas similares con sus datos) y compruébelo usted mismo:
SELECT orderid + 5 + 1 AS myorderid FROM dbo.orders; SELECT 5 + orderid + 1 AS myorderid FROM dbo.orders; SELECT 5 + 1 + orderid AS myorderid FROM dbo.orders;
Obtuve las siguientes tres expresiones en los operadores Compute Scalar para estas tres consultas, respectivamente:
[Expr1003] = Scalar Operator([PerformanceV5].[dbo].[Orders].[orderid]+(5)+(1)) [Expr1003] = Scalar Operator((5)+[PerformanceV5].[dbo].[Orders].[orderid]+(1)) [Expr1003] = Scalar Operator((6)+[PerformanceV5].[dbo].[Orders].[orderid])
¿Ves a dónde voy con esto? En mis funciones utilicé la siguiente expresión para definir la columna de resultados n:
@low + rownum - 1 AS n
Charlie se dio cuenta de que con la siguiente pequeña alteración, puede habilitar el plegado constante:
@low - 1 + rownum AS n
Por ejemplo, el plan para la consulta anterior que proporcioné contra dbo.GetNumsItzik, con @low =1, originalmente tenía la siguiente expresión definida por el operador Compute Scalar:
[Expr1154] = Scalar Operator((1)+[Expr1153]-(1))
Después de aplicar el cambio menor anterior, la expresión en el plan se convierte en:
[Expr1154] = Scalar Operator((0)+[Expr1153])
¡Eso es genial!
En cuanto a las implicaciones de rendimiento, recuerde que las estadísticas de rendimiento que obtuve para la consulta contra dbo.GetNumsItzikBatch antes del cambio fueron las siguientes:
CPU time = 16985 ms, elapsed time = 18348 ms.
Estos son los números que obtuve después del cambio:
CPU time = 16375 ms, elapsed time = 17932 ms.
Aquí están los números que obtuve para la consulta contra dbo.GetNumsItzik originalmente:
CPU time = 19969 ms, elapsed time = 21229 ms.
Y aquí están los números después del cambio:
CPU time = 19266 ms, elapsed time = 20588 ms.
El rendimiento mejoró solo un poco en un pequeño porcentaje. ¡Pero espera hay mas! Si necesita procesar los datos pedidos, las implicaciones de rendimiento pueden ser mucho más dramáticas, como veremos más adelante en la sección sobre pedidos.
Secuencia basada en 1 versus basada en @low y números de fila opuestos
Alan, Charlie y Jeff notaron que en la gran mayoría de los casos de la vida real en los que necesita un rango de números, debe comenzar con 1 o, a veces, con 0. Es mucho menos común necesitar un punto de partida diferente. Por lo tanto, podría tener más sentido hacer que la función siempre devuelva un rango que comience con, digamos, 1, y cuando necesite un punto de partida diferente, aplique los cálculos externamente en la consulta contra la función.
A Alan se le ocurrió una idea elegante para que el TVF en línea devuelva tanto una columna que comienza con 1 (simplemente el resultado directo de la función ROW_NUMBER) con el alias rn, como una columna que comienza con @low con el alias n. Dado que la función se inserta, cuando la consulta externa interactúa solo con la columna rn, la columna n ni siquiera se evalúa y obtiene el beneficio de rendimiento. Cuando necesite que la secuencia comience con @low, interactúe con la columna n y pague el costo adicional aplicable, por lo que no es necesario agregar cálculos externos explícitos. Alan incluso sugirió agregar una columna llamada op que calcula los números en orden opuesto e interactúa con ella solo cuando se necesita dicha secuencia. La columna op se basa en el cálculo:@high + 1 – rownum. Esta columna tiene importancia cuando necesita procesar las filas en orden de números descendentes, como lo demuestro más adelante en la sección de pedidos.
Entonces, apliquemos las mejoras de Charlie y Alan a mis funciones.
Para la versión en modo por lotes, asegúrese de crear primero la tabla ficticia con el índice del almacén de columnas, si aún no está presente:
CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
Luego use la siguiente definición para la función dbo.GetNumsAlanCharlieItzikBatch:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum; Aquí hay un ejemplo para usar la función:
SELECT * FROM dbo.GetNumsAlanCharlieItzikBatch(-2, 3) AS F ORDER BY rn;
Este código genera el siguiente resultado:
rn op n --- --- --- 1 3 -2 2 2 -1 3 1 0 4 0 1 5 -1 2 6 -2 3
A continuación, pruebe el rendimiento de la función con 100 millones de filas, devolviendo primero la columna n:
SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Estas son las estadísticas de rendimiento que obtuve para esta ejecución:
CPU time = 16375 ms, elapsed time = 17932 ms.
Como puede ver, hay una pequeña mejora en comparación con dbo.GetNumsItzikBatch tanto en la CPU como en el tiempo transcurrido gracias al plegado constante que tuvo lugar aquí.
Pruebe la función, solo que esta vez devolviendo la columna rn:
SELECT rn FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Estas son las estadísticas de rendimiento que obtuve para esta ejecución:
CPU time = 15890 ms, elapsed time = 18561 ms.
El tiempo de CPU se redujo aún más, aunque el tiempo transcurrido parece haber aumentado un poco en esta ejecución en comparación con la consulta de la columna n.
La Figura 1 tiene los planes para ambas consultas.
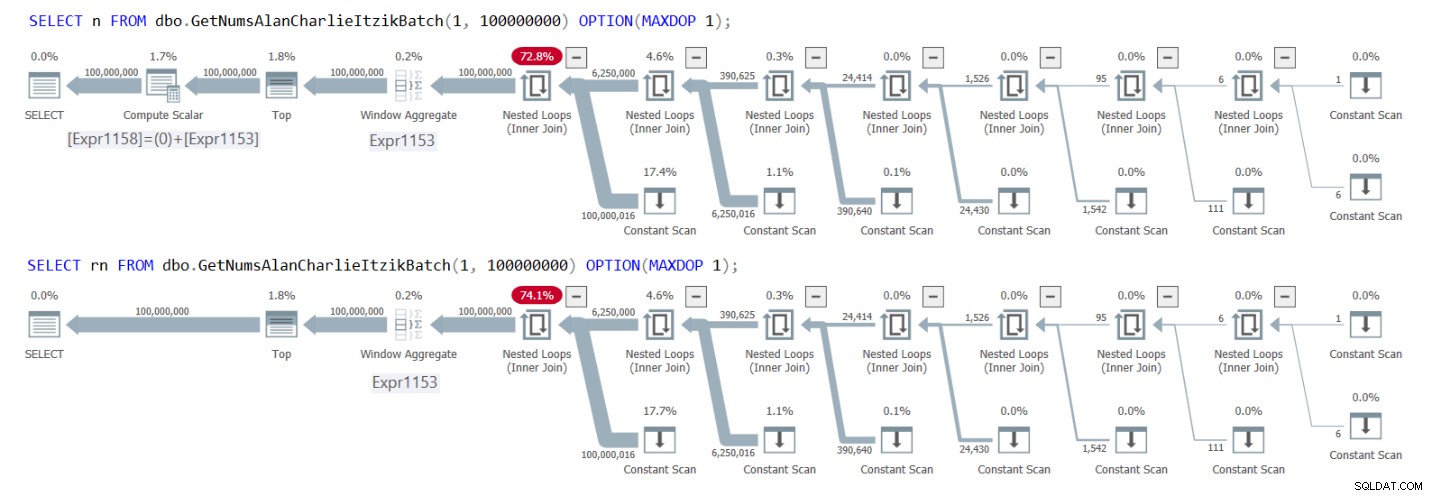 Figura 1:Planes para GetNumsAlanCharlieItzikBatch que devuelve n versus rn
Figura 1:Planes para GetNumsAlanCharlieItzikBatch que devuelve n versus rn
Puede ver claramente en los planes que al interactuar con la columna rn, no es necesario el operador Calcular escalar adicional. Observe también en el primer plan el resultado de la actividad de plegamiento constante que describí anteriormente, donde @low – 1 + número de fila se incorporó a 1 – 1 + número de fila y luego se integró en 0 + número de fila.
Esta es la definición de la versión en modo fila de la función denominada dbo.GetNumsAlanCharlieItzik:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzik(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum; Use el siguiente código para probar la función, primero consultando la columna n:
SELECT n FROM dbo.GetNumsAlanCharlieItzik(1, 100000000) OPTION(MAXDOP 1);
Estas son las estadísticas de rendimiento que obtuve:
CPU time = 19047 ms, elapsed time = 20121 ms.
Como puede ver, es un poco más rápido que dbo.GetNumsItzik.
A continuación, consulta la columna rn:
SELECT rn FROM dbo.GetNumsAlanCharlieItzik(1, 100000000) OPTION(MAXDOP 1);
Los números de rendimiento mejoran aún más tanto en la CPU como en los frentes de tiempo transcurrido:
CPU time = 17656 ms, elapsed time = 18990 ms.
Consideraciones sobre pedidos
Las mejoras antes mencionadas son ciertamente interesantes y el impacto en el rendimiento no es despreciable, pero no muy significativo. Se puede observar un impacto de rendimiento mucho más dramático y profundo cuando necesita procesar los datos ordenados por la columna de números. Esto podría ser tan simple como tener que devolver las filas ordenadas, pero es igual de relevante para cualquier necesidad de procesamiento basada en pedidos, por ejemplo, un operador Stream Aggregate para agrupar y agregar, un algoritmo Merge Join para unir, etc.
Al consultar dbo.GetNumsItzikBatch o dbo.GetNumsItzik y ordenar por n, el optimizador no se da cuenta de que la expresión de orden subyacente @low + rownum – 1 conserva el orden con respecto a número de fila. La implicación es un poco similar a la de una expresión de filtrado no SARGable, solo que con una expresión de ordenamiento esto da como resultado un operador Ordenar explícito en el plan. La clasificación adicional afecta el tiempo de respuesta. También afecta la escala, que normalmente se convierte en n log n en lugar de n.
Para demostrar esto, consulta dbo.GetNumsItzikBatch, solicitando la columna n, ordenada por n:
SELECT n FROM dbo.GetNumsItzikBatch(1,100000000) ORDER BY n OPTION(MAXDOP 1);
Obtuve las siguientes estadísticas de rendimiento:
CPU time = 34125 ms, elapsed time = 39656 ms.
El tiempo de ejecución es más del doble en comparación con la prueba sin la cláusula ORDER BY.
Pruebe la función dbo.GetNumsItzik de manera similar:
SELECT n FROM dbo.GetNumsItzik(1,100000000) ORDER BY n OPTION(MAXDOP 1);
Obtuve los siguientes números para esta prueba:
CPU time = 52391 ms, elapsed time = 55175 ms.
También aquí el tiempo de ejecución es más del doble en comparación con la prueba sin la cláusula ORDER BY.
La Figura 2 tiene los planes para ambas consultas.
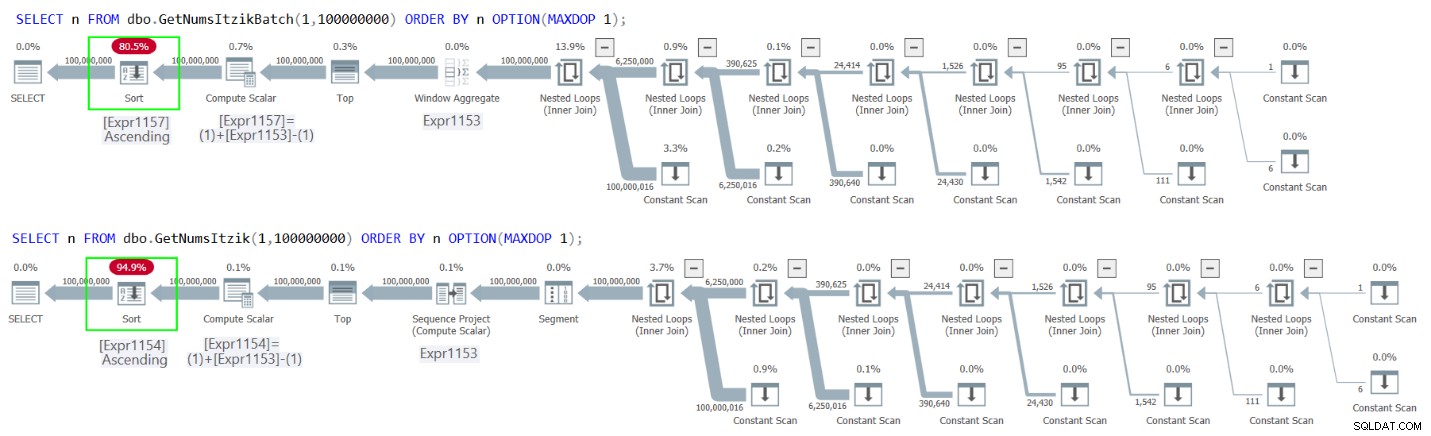 Figura 2:Planes para GetNumsItzikBatch y GetNumsItzik ordenados por n
Figura 2:Planes para GetNumsItzikBatch y GetNumsItzik ordenados por n
En ambos casos, puede ver el operador Ordenar explícito en los planes.
Al consultar dbo.GetNumsAlanCharlieItzikBatch o dbo.GetNumsAlanCharlieItzik y ordenar por rn, el optimizador no necesita agregar un operador Ordenar al plan. Entonces podría devolver n, pero ordenar por rn, y de esta manera evitar una ordenación. Sin embargo, lo que es un poco impactante, y lo digo en el buen sentido, es que la versión revisada de n que experimenta plegamiento constante, ¡preserva el orden! Es fácil para el optimizador darse cuenta de que 0 + número de fila es una expresión que conserva el orden con respecto a número de fila y, por lo tanto, evitar una ordenación.
Intentalo. Consulta dbo.GetNumsAlanCharlieItzikBatch, devuelve n y ordena por n o rn, así:
SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1,100000000) ORDER BY n -- same with rn OPTION(MAXDOP 1);
Obtuve los siguientes números de rendimiento:
CPU time = 16500 ms, elapsed time = 17684 ms.
Eso es, por supuesto, gracias al hecho de que no había necesidad de un operador Sort en el plan.
Ejecute una prueba similar contra dbo.GetNumsAlanCharlieItzik:
SELECT n FROM dbo.GetNumsAlanCharlieItzik(1,100000000) ORDER BY n -- same with rn OPTION(MAXDOP 1);
Tengo los siguientes números:
CPU time = 19546 ms, elapsed time = 20803 ms.
La Figura 3 tiene los planes para ambas consultas:
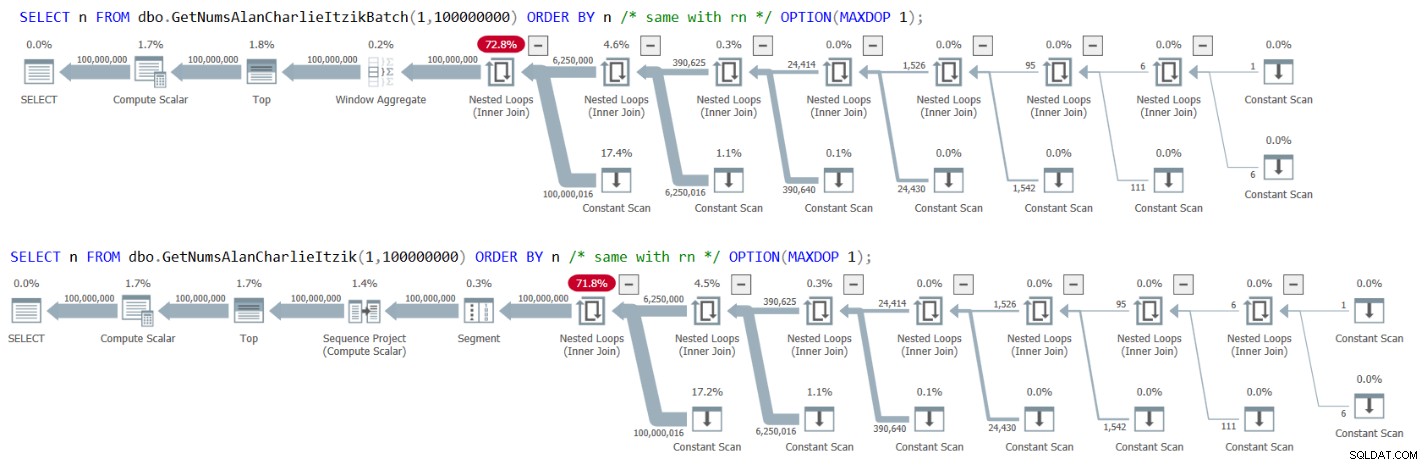
Figura 3:Planes para GetNumsAlanCharlieItzikBatch y GetNumsAlanCharlieItzik ordenados por n o rn
Observe que no hay ningún operador Sort en los planes.
Te dan ganas de cantar…
All you need is constant folding All you need is constant folding All you need is constant folding, constant folding Constant folding is all you need
¡Gracias Charly!
Pero, ¿qué sucede si necesita devolver o procesar los números en orden descendente? El intento obvio es usar ORDER BY n DESC u ORDER BY rn DESC, así:
SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1,100000000) ORDER BY n DESC OPTION(MAXDOP 1); SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1,100000000) ORDER BY rn DESC OPTION(MAXDOP 1);
Desafortunadamente, sin embargo, ambos casos dan como resultado una ordenación explícita en los planes, como se muestra en la Figura 4.
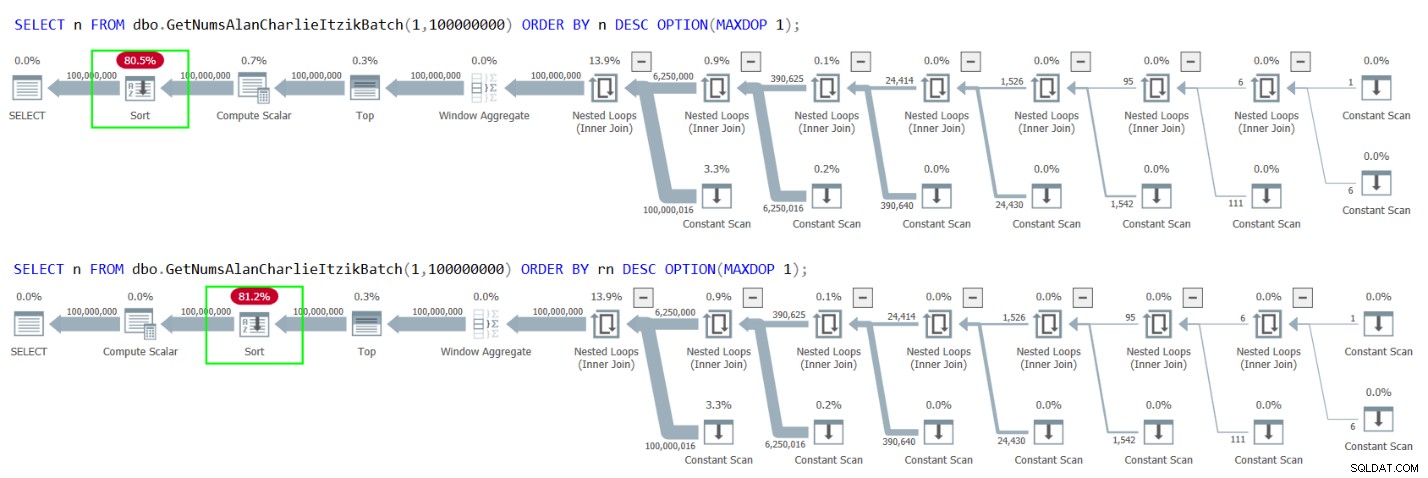 Figura 4:Planes para GetNumsAlanCharlieItzikBatch ordenando por n o rn descendente
Figura 4:Planes para GetNumsAlanCharlieItzikBatch ordenando por n o rn descendente
Aquí es donde el ingenioso truco de Alan con la operación de columna se convierte en un salvavidas. Devuelva la columna op mientras ordena por n o rn, así:
SELECT op FROM dbo.GetNumsAlanCharlieItzikBatch(1,100000000) ORDER BY n OPTION(MAXDOP 1);
El plan para esta consulta se muestra en la Figura 5.
 Figura 5:Plan para GetNumsAlanCharlieItzikBatch que regresa op y ordena por n o rn ascendente
Figura 5:Plan para GetNumsAlanCharlieItzikBatch que regresa op y ordena por n o rn ascendente
Obtiene los datos nuevamente ordenados por n descendente y no hay necesidad de ordenarlos en el plan.
¡Gracias Alan!
Resumen de rendimiento
Entonces, ¿qué hemos aprendido de todo esto?
Los tiempos de compilación pueden ser un factor, especialmente cuando se usa la función con frecuencia con rangos pequeños. En una escala logarítmica con base 2, el dulce 16 parece ser un lindo número mágico.
Comprenda las peculiaridades del plegado constante y utilícelas a su favor. Cuando un iTVF tiene expresiones que involucran parámetros, constantes y columnas, coloque los parámetros y las constantes en la parte inicial de la expresión. Esto aumentará la probabilidad de plegamiento, reducirá la sobrecarga de la CPU y aumentará la probabilidad de conservación del pedido.
Está bien tener múltiples columnas que se usan para diferentes propósitos en un iTVF y consultar las relevantes en cada caso sin preocuparse por pagar por las que no están referenciadas.
Cuando necesite que la secuencia numérica se devuelva en orden opuesto, use la columna original n o rn en la cláusula ORDER BY con orden ascendente y devuelva la columna op, que calcula los números en orden inverso.
La figura 6 resume los números de rendimiento que obtuve en las diversas pruebas.
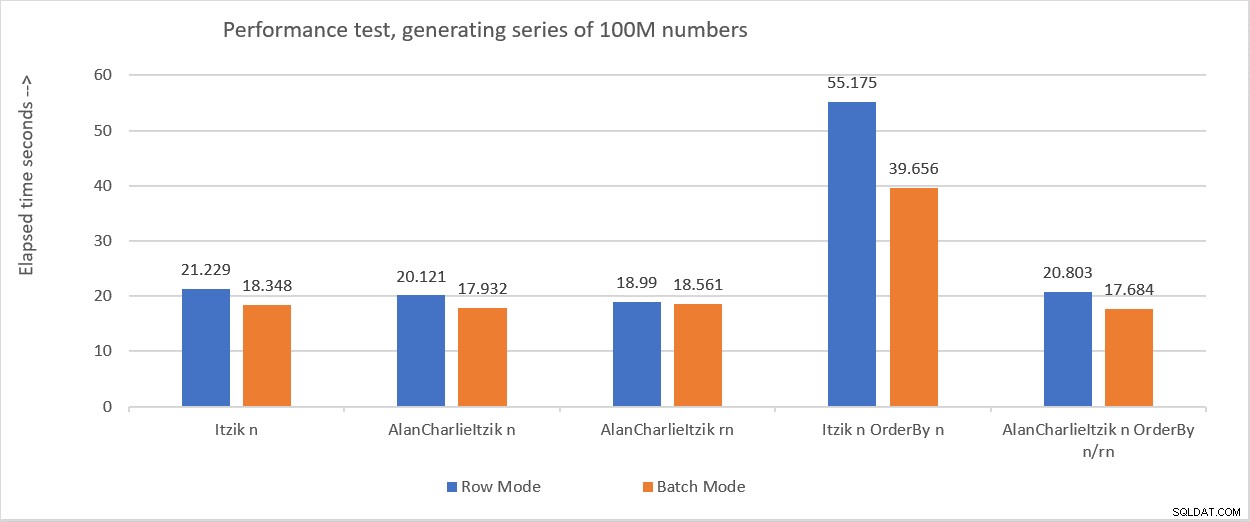 Figura 6:Resumen de rendimiento
Figura 6:Resumen de rendimiento
El próximo mes continuaré explorando ideas, conocimientos y soluciones adicionales para el desafío del generador de series numéricas.