La semana pasada, presenté mi sesión T-SQL:malos hábitos y mejores prácticas durante la conferencia GroupBy. Una reproducción de video y otros materiales están disponibles aquí:
- T-SQL:malos hábitos y mejores prácticas
Uno de los elementos que siempre menciono en esa sesión es que generalmente prefiero GROUP BY sobre DISTINCT cuando elimino duplicados. Si bien DISTINCT explica mejor la intención y GROUP BY solo se requiere cuando hay agregaciones, en muchos casos son intercambiables.
Comencemos con algo simple usando Wide World Importers. Estas dos consultas producen el mismo resultado:
SELECT DISTINCT Description FROM Sales.OrderLines; SELECT Description FROM Sales.OrderLines GROUP BY Description;
Y, de hecho, obtenga sus resultados utilizando exactamente el mismo plan de ejecución:

Mismos operadores, mismo número de lecturas, diferencias insignificantes en CPU y duración total (se turnan para "ganar").
Entonces, ¿por qué recomendaría usar la sintaxis GROUP BY más prolija y menos intuitiva en lugar de DISTINCT? Bueno, en este caso simple, es un lanzamiento de moneda. Sin embargo, en casos más complejos, DISTINCT puede terminar haciendo más trabajo. Básicamente, DISTINCT recopila todas las filas, incluidas las expresiones que deben evaluarse, y luego elimina los duplicados. GROUP BY puede (de nuevo, en algunos casos) filtrar las filas duplicadas anteriores realizar cualquiera de esos trabajos.
Hablemos de la agregación de cadenas, por ejemplo. Mientras esté en SQL Server v.Next, podrá usar STRING_AGG (vea las publicaciones aquí y aquí), el resto de nosotros tenemos que continuar con FOR XML PATH (y antes de que me cuente lo increíbles que son los CTE recursivos para esto, por favor lee este post también). Podríamos tener una consulta como esta, que intenta devolver todos los pedidos de la tabla Sales.OrderLines, junto con las descripciones de los artículos como una lista delimitada por barras verticales:
SELECT o.OrderID, OrderItems = STUFF((SELECT N'|' + Description FROM Sales.OrderLines WHERE OrderID = o.OrderID FOR XML PATH(N''), TYPE).value(N'text()[1]', N'nvarchar(max)'),1,1,N'') FROM Sales.OrderLines AS o;
Esta es una consulta típica para resolver este tipo de problema, con el siguiente plan de ejecución (la advertencia en todos los planes es solo para la conversión implícita que sale del filtro XPath):
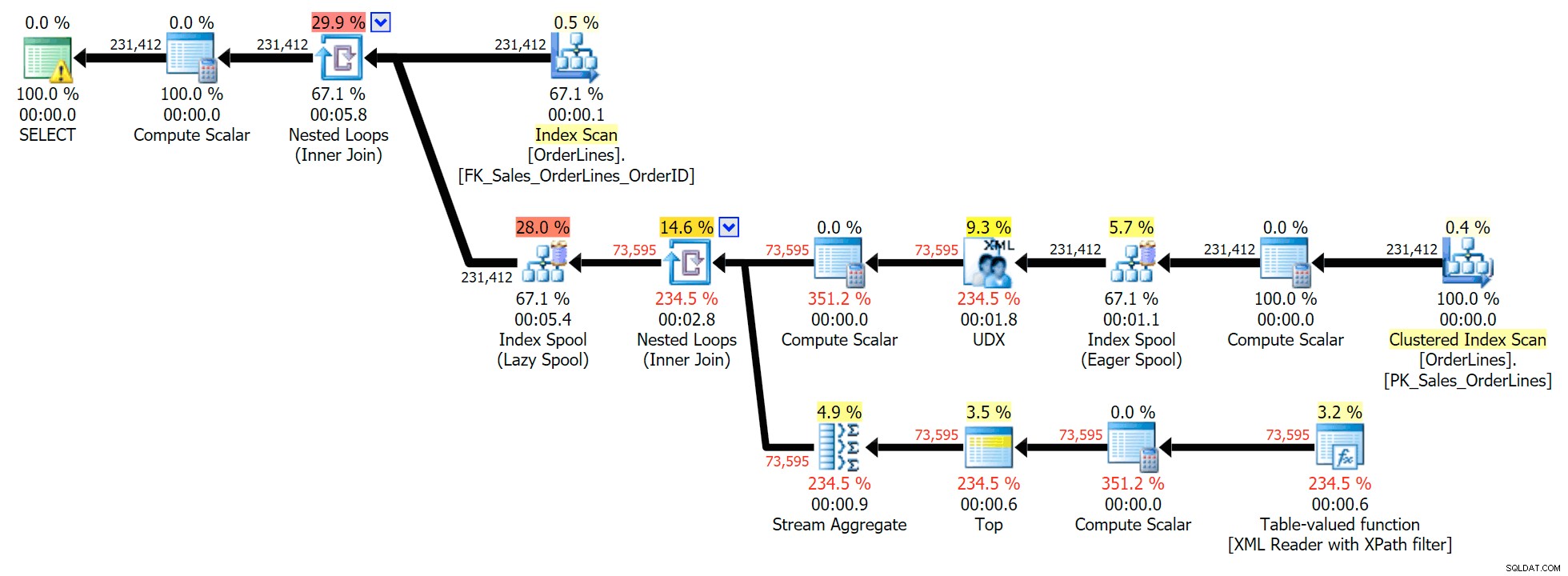
Sin embargo, tiene un problema que puede notar en el número de filas de salida. Ciertamente puede detectarlo al escanear casualmente la salida:

Para cada pedido, vemos la lista delimitada por tuberías, pero vemos una fila para cada artículo en cada orden. La reacción instintiva es lanzar DISTINCT en la lista de columnas:
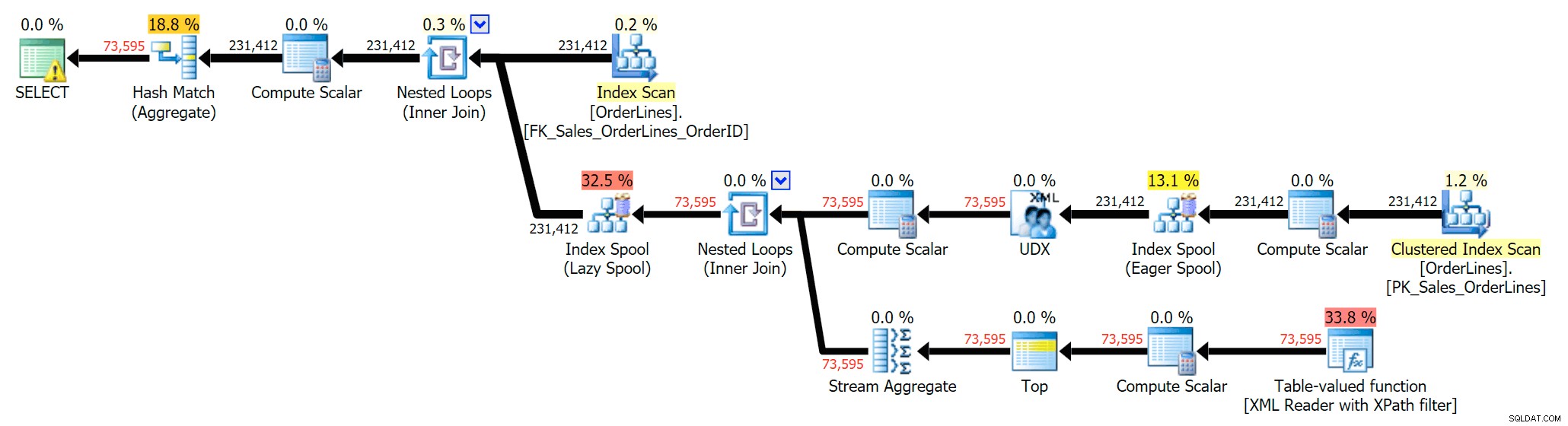
SELECT DISTINCT o.OrderID, OrderItems = STUFF((SELECT N'|' + Description FROM Sales.OrderLines WHERE OrderID = o.OrderID FOR XML PATH(N''), TYPE).value(N'text()[1]', N'nvarchar(max)'),1,1,N'') FROM Sales.OrderLines AS o;
Eso elimina los duplicados (y cambia las propiedades de ordenación en los escaneos, por lo que los resultados no aparecerán necesariamente en un orden predecible), y produce el siguiente plan de ejecución:
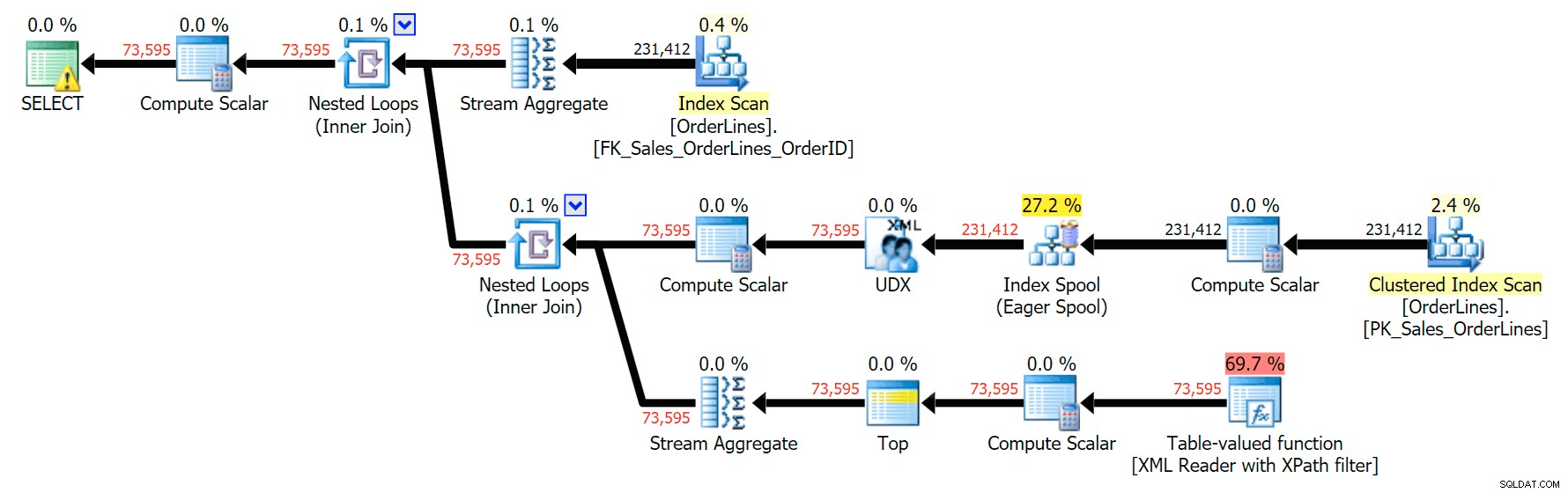
Otra forma de hacerlo es agregar un GROUP BY para OrderID (dado que la subconsulta no necesita explícitamente para ser referenciado nuevamente en el GRUPO POR):
SELECT o.OrderID, OrderItems = STUFF((SELECT N'|' + Description FROM Sales.OrderLines WHERE OrderID = o.OrderID FOR XML PATH(N''), TYPE).value(N'text()[1]', N'nvarchar(max)'),1,1,N'') FROM Sales.OrderLines AS o GROUP BY o.OrderID;
Esto produce los mismos resultados (aunque el pedido ha regresado) y un plan ligeramente diferente:
Las métricas de rendimiento, sin embargo, son interesantes para comparar.

La variación DISTINCT tardó 4 veces más, usó 4 veces la CPU y casi 6 veces las lecturas en comparación con la variación GROUP BY. (Recuerde, estas consultas devuelven exactamente los mismos resultados).
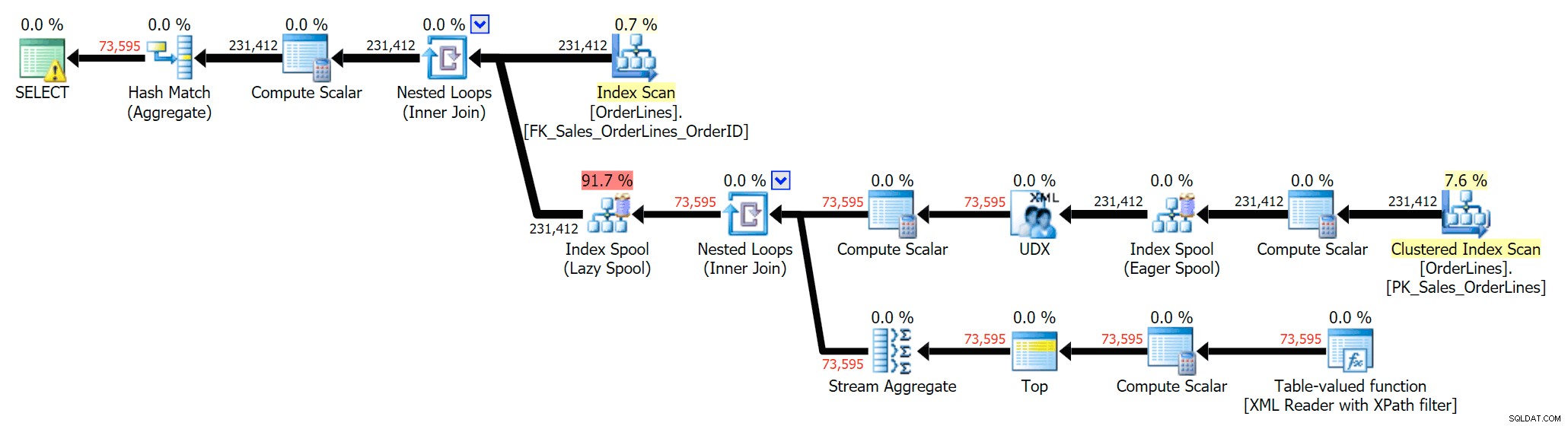
También podemos comparar los planes de ejecución cuando cambiamos los costos de CPU + E/S combinados a solo E/S, una característica exclusiva de Plan Explorer. También mostramos los valores reajustados (que se basan en el valor real) costos observados durante la ejecución de consultas, una función que también solo se encuentra en Plan Explorer). Aquí está el plan DISTINCT:
Y aquí está el plan GROUP BY:
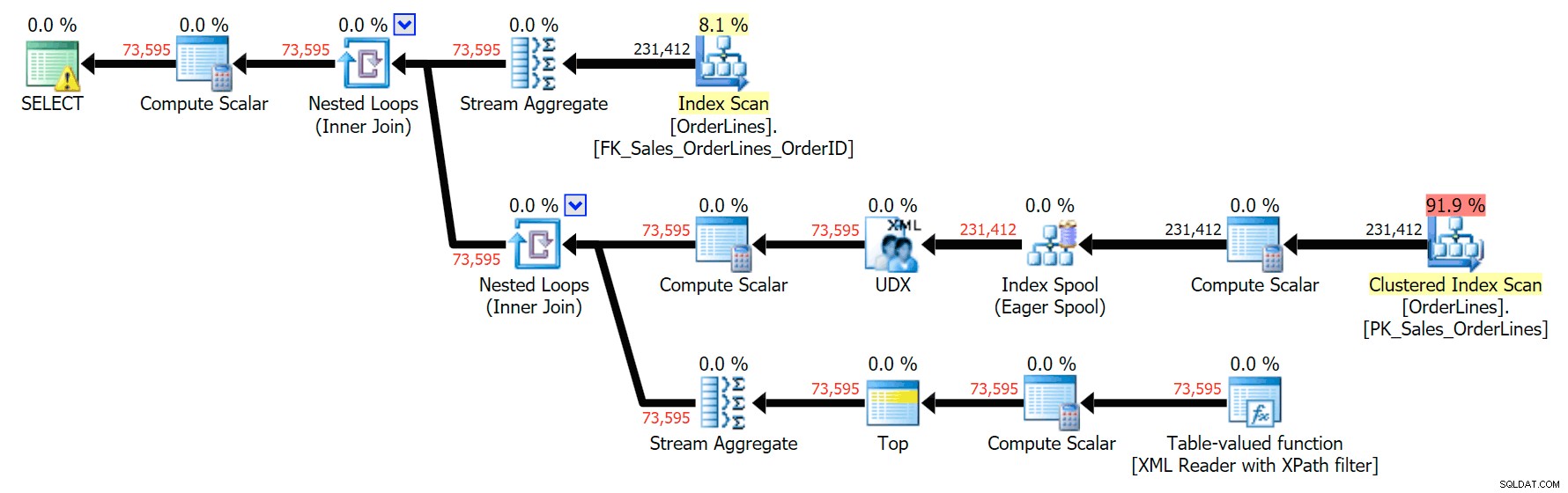
Puede ver que, en el plan GROUP BY, casi todo el costo de E/S está en los escaneos (aquí está la información sobre herramientas para el escaneo de CI, que muestra un costo de E/S de ~3.4 "dólares de consulta"). Sin embargo, en el plan DISTINCT, la mayor parte del costo de E/S está en la cola de índice (y aquí está la información sobre herramientas; el costo de E/S aquí es ~41.4 "dólares de consulta"). Tenga en cuenta que la CPU también es mucho más alta con el spool de índice. Hablaremos de "consultar dólares" en otro momento, pero el punto es que el índice de cola es más de 10 veces más caro que el escaneo, pero el escaneo sigue siendo el mismo 3.4 en ambos planes. Esta es una de las razones por las que siempre me molesta cuando la gente dice que necesita "arreglar" al operador en el plan con el costo más alto. Algún operador en el plan siempre ser el más caro; eso no significa que deba arreglarse.
@AaronBertrand esas consultas no son realmente equivalentes lógicamente:DISTINCT es en ambas columnas, mientras que GROUP BY está solo en una
— Adam Machanic (@AdamMachanic) 20 de enero de 2017
Si bien Adam Machanic tiene razón cuando dice que estas consultas son semánticamente diferentes, el resultado es el mismo:obtenemos la misma cantidad de filas, que contienen exactamente los mismos resultados, y lo hicimos con muchas menos lecturas y CPU.
Entonces, si bien DISTINCT y GROUP BY son idénticos en muchos escenarios, aquí hay un caso en el que el enfoque GROUP BY definitivamente conduce a un mejor rendimiento (a costa de una intención declarativa menos clara en la consulta misma). Me interesaría saber si cree que hay escenarios en los que DISTINCT es mejor que GROUP BY, al menos en términos de rendimiento, que es mucho menos subjetivo que el estilo o si una declaración debe ser autodocumentada.
Esta publicación encaja en mi serie de "sorpresas y suposiciones" porque muchas cosas que sostenemos como verdades basadas en observaciones limitadas o casos de uso particulares pueden probarse cuando se usan en otros escenarios. Solo tenemos que recordar tomarnos el tiempo para hacerlo como parte de la optimización de consultas SQL...
Referencias
- Concatenación agrupada en SQL Server
- Concatenación agrupada:ordenar y eliminar duplicados
- Cuatro casos prácticos de uso para la concatenación agrupada
- SQL Server v.Next:rendimiento de STRING_AGG()
- SQL Server v.Next:rendimiento de STRING_AGG, parte 2