Una de las muchas funciones nuevas introducidas en SQL Server 2008 fue la compresión de datos. La compresión a nivel de fila o de página brinda la oportunidad de ahorrar espacio en disco, con la contrapartida de requerir un poco más de CPU para comprimir y descomprimir los datos. Con frecuencia se argumenta que la mayoría de los sistemas están vinculados a IO, no a la CPU, por lo que la compensación vale la pena. ¿La captura? Tenía que estar en Enterprise Edition para usar la compresión de datos. ¡Con el lanzamiento de SQL Server 2016 SP1, eso ha cambiado! Si está ejecutando la edición estándar de SQL Server 2016 SP1 y superior, ahora puede usar la compresión de datos. También hay una nueva función incorporada para compresión, COMPRESS (y su contraparte DECOMPRESS). La compresión de datos no funciona con datos fuera de fila, por lo que si tiene una columna como NVARCHAR(MAX) en su tabla con valores que suelen tener más de 8000 bytes de tamaño, esos datos no se comprimirán (gracias a Adam Machanic por ese recordatorio) . La función COMPRESS resuelve este problema y comprime datos de hasta 2 GB de tamaño. Además, aunque diría que la función solo debe usarse para datos grandes fuera de fila, pensé que compararla directamente con la compresión de filas y páginas era un experimento que valía la pena.
CONFIGURACIÓN
Para los datos de prueba, estoy trabajando con un script que Aaron Bertrand usó anteriormente, pero hice algunos ajustes. Creé una base de datos separada para realizar pruebas, pero puede usar tempdb u otra base de datos de muestra, y luego comencé con una tabla Clientes que tiene tres columnas NVARCHAR. Pensé en crear columnas más grandes y llenarlas con cadenas de letras repetidas, pero el uso de texto legible brinda una muestra que es más realista y, por lo tanto, proporciona una mayor precisión.
Notará a continuación que después de crear la base de datos estamos habilitando Query Store. ¿Por qué crear una tabla separada para intentar realizar un seguimiento de nuestras métricas de rendimiento cuando solo podemos usar la funcionalidad integrada en SQL Server?
USE [master]; GO CREATE DATABASE [CustomerDB] CONTAINMENT = NONE ON PRIMARY ( NAME = N'CustomerDB', FILENAME = N'C:\Databases\CustomerDB.mdf' , SIZE = 4096MB , MAXSIZE = UNLIMITED, FILEGROWTH = 65536KB ) LOG ON ( NAME = N'CustomerDB_log', FILENAME = N'C:\Databases\CustomerDB_log.ldf' , SIZE = 2048MB , MAXSIZE = UNLIMITED , FILEGROWTH = 65536KB ); GO ALTER DATABASE [CustomerDB] SET COMPATIBILITY_LEVEL = 130; GO ALTER DATABASE [CustomerDB] SET RECOVERY SIMPLE; GO ALTER DATABASE [CustomerDB] SET QUERY_STORE = ON; GO ALTER DATABASE [CustomerDB] SET QUERY_STORE ( OPERATION_MODE = READ_WRITE, CLEANUP_POLICY = (STALE_QUERY_THRESHOLD_DAYS = 30), DATA_FLUSH_INTERVAL_SECONDS = 60, INTERVAL_LENGTH_MINUTES = 5, MAX_STORAGE_SIZE_MB = 256, QUERY_CAPTURE_MODE = ALL, SIZE_BASED_CLEANUP_MODE = AUTO, MAX_PLANS_PER_QUERY = 200 ); GO
Ahora configuraremos algunas cosas dentro de la base de datos:
USE [CustomerDB]; GO ALTER DATABASE SCOPED CONFIGURATION SET MAXDOP = 0; GO -- note: I removed the unique index on [Email] that was in Aaron's version CREATE TABLE [dbo].[Customers] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers] PRIMARY KEY CLUSTERED ([CustomerID]) ); GO CREATE NONCLUSTERED INDEX [Active_Customers] ON [dbo].[Customers]([FirstName],[LastName],[EMail]) WHERE ([Active]=1); GO CREATE NONCLUSTERED INDEX [PhoneBook_Customers] ON [dbo].[Customers]([LastName],[FirstName]) INCLUDE ([EMail]);
Con la tabla creada, agregaremos algunos datos, pero estamos agregando 5 millones de filas en lugar de 1 millón. Esto tarda unos ocho minutos en ejecutarse en mi computadora portátil.
INSERT dbo.Customers WITH (TABLOCKX)
(CustomerID, FirstName, LastName, EMail, [Active])
SELECT rn = ROW_NUMBER() OVER (ORDER BY n), fn, ln, em, a
FROM
(
SELECT TOP (5000000) fn, ln, em, a = MAX(a), n = MAX(NEWID())
FROM
(
SELECT fn, ln, em, a, r = ROW_NUMBER() OVER (PARTITION BY em ORDER BY em)
FROM
(
SELECT TOP (20000000)
fn = LEFT(o.name, 64),
ln = LEFT(c.name, 64),
em = LEFT(o.name, LEN(c.name)%5+1) + '.'
+ LEFT(c.name, LEN(o.name)%5+2) + '@'
+ RIGHT(c.name, LEN(o.name + c.name)%12 + 1)
+ LEFT(RTRIM(CHECKSUM(NEWID())),3) + '.com',
a = CASE WHEN c.name LIKE '%y%' THEN 0 ELSE 1 END
FROM sys.all_objects AS o CROSS JOIN sys.all_columns AS c
ORDER BY NEWID()
) AS x
) AS y WHERE r = 1
GROUP BY fn, ln, em
ORDER BY n
) AS z
ORDER BY rn;
GO Ahora crearemos tres tablas más:una para la compresión de filas, otra para la compresión de páginas y otra para la función COMPRESS. Tenga en cuenta que con la función COMPRESS, debe crear las columnas como tipos de datos VARBINARY. Como resultado, no hay índices no agrupados en la tabla (ya que no puede crear una clave de índice en una columna varbinary).
CREATE TABLE [dbo].[Customers_Page] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers_Page] PRIMARY KEY CLUSTERED ([CustomerID]) ); GO CREATE NONCLUSTERED INDEX [Active_Customers_Page] ON [dbo].[Customers_Page]([FirstName],[LastName],[EMail]) WHERE ([Active]=1); GO CREATE NONCLUSTERED INDEX [PhoneBook_Customers_Page] ON [dbo].[Customers_Page]([LastName],[FirstName]) INCLUDE ([EMail]); GO CREATE TABLE [dbo].[Customers_Row] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers_Row] PRIMARY KEY CLUSTERED ([CustomerID]) ); GO CREATE NONCLUSTERED INDEX [Active_Customers_Row] ON [dbo].[Customers_Row]([FirstName],[LastName],[EMail]) WHERE ([Active]=1); GO CREATE NONCLUSTERED INDEX [PhoneBook_Customers_Row] ON [dbo].[Customers_Row]([LastName],[FirstName]) INCLUDE ([EMail]); GO CREATE TABLE [dbo].[Customers_Compress] ( [CustomerID] [int] NOT NULL, [FirstName] [varbinary](max) NOT NULL, [LastName] [varbinary](max) NOT NULL, [EMail] [varbinary](max) NOT NULL, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers_Compress] PRIMARY KEY CLUSTERED ([CustomerID]) ); GO
A continuación, copiaremos los datos de [dbo].[Clientes] a las otras tres tablas. Este es un INSERTO directo para nuestras tablas de páginas y filas y toma de dos a tres minutos para cada INSERCIÓN, pero hay un problema de escalabilidad con la función COMPRESS:intentar insertar 5 millones de filas de una sola vez no es razonable. El siguiente script inserta filas en lotes de 50 000 y solo inserta 1 millón de filas en lugar de 5 millones. Lo sé, eso significa que no somos realmente manzanas con manzanas aquí para comparar, pero estoy de acuerdo con eso. Insertar 1 millón de filas toma 10 minutos en mi máquina; no dude en modificar el script e insertar 5 millones de filas para sus propias pruebas.
INSERT dbo.Customers_Page WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT CustomerID, FirstName, LastName, EMail, [Active] FROM dbo.Customers; GO INSERT dbo.Customers_Row WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT CustomerID, FirstName, LastName, EMail, [Active] FROM dbo.Customers; GO SET NOCOUNT ON DECLARE @StartID INT = 1 DECLARE @EndID INT = 50000 DECLARE @Increment INT = 50000 DECLARE @IDMax INT = 1000000 WHILE @StartID < @IDMax BEGIN INSERT dbo.Customers_Compress WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT top 100000 CustomerID, COMPRESS(FirstName), COMPRESS(LastName), COMPRESS(EMail), [Active] FROM dbo.Customers WHERE [CustomerID] BETWEEN @StartID AND @EndID; SET @StartID = @StartID + @Increment; SET @EndID = @EndID + @Increment; END
Con todas nuestras tablas pobladas, podemos hacer una verificación de tamaño. En este punto, no hemos implementado la compresión ROW o PAGE, pero se ha utilizado la función COMPRESS:
SELECT [o].[name], [i].[index_id], [i].[name], [p].[rows], (8*SUM([au].[used_pages]))/1024 AS [IndexSize(MB)], [p].[data_compression_desc] FROM [sys].[allocation_units] [au] JOIN [sys].[partitions] [p] ON [au].[container_id] = [p].[partition_id] JOIN [sys].[objects] [o] ON [p].[object_id] = [o].[object_id] JOIN [sys].[indexes] [i] ON [p].[object_id] = [i].[object_id] AND [p].[index_id] = [i].[index_id] WHERE [o].[is_ms_shipped] = 0 GROUP BY [o].[name], [i].[index_id], [i].[name], [p].[rows], [p].[data_compression_desc] ORDER BY [o].[name], [i].[index_id];
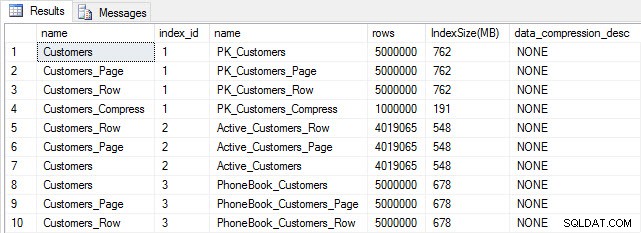 Tamaño de tabla e índice después de la inserción
Tamaño de tabla e índice después de la inserción
Como era de esperar, todas las tablas excepto Customers_Compress tienen aproximadamente el mismo tamaño. Ahora reconstruiremos los índices en todas las tablas, implementando la compresión de filas y páginas en Customers_Row y Customers_Page, respectivamente.
ALTER INDEX ALL ON dbo.Customers REBUILD; GO ALTER INDEX ALL ON dbo.Customers_Page REBUILD WITH (DATA_COMPRESSION = PAGE); GO ALTER INDEX ALL ON dbo.Customers_Row REBUILD WITH (DATA_COMPRESSION = ROW); GO ALTER INDEX ALL ON dbo.Customers_Compress REBUILD;
Si comprobamos el tamaño de la tabla después de la compresión, ahora podemos ver nuestro ahorro de espacio en disco:
SELECT [o].[name], [i].[index_id], [i].[name], [p].[rows], (8*SUM([au].[used_pages]))/1024 AS [IndexSize(MB)], [p].[data_compression_desc] FROM [sys].[allocation_units] [au] JOIN [sys].[partitions] [p] ON [au].[container_id] = [p].[partition_id] JOIN [sys].[objects] [o] ON [p].[object_id] = [o].[object_id] JOIN [sys].[indexes] [i] ON [p].[object_id] = [i].[object_id] AND [p].[index_id] = [i].[index_id] WHERE [o].[is_ms_shipped] = 0 GROUP BY [o].[name], [i].[index_id], [i].[name], [p].[rows], [p].[data_compression_desc] ORDER BY [i].[index_id], [IndexSize(MB)] DESC;
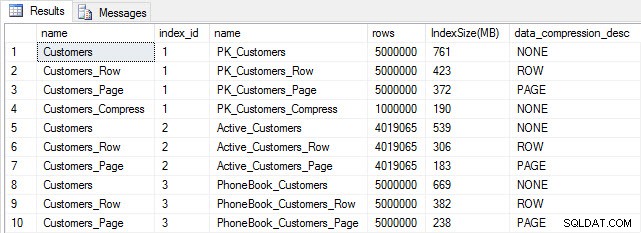
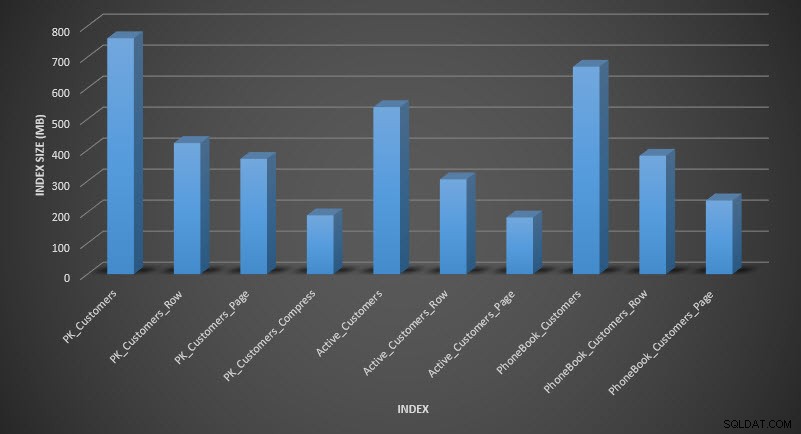 Tamaño del índice después de la compresión
Tamaño del índice después de la compresión
Como era de esperar, la compresión de filas y páginas reduce significativamente el tamaño de la tabla y sus índices. La función COMPRESS nos ahorró la mayor cantidad de espacio:el índice agrupado es una cuarta parte del tamaño de la tabla original.
EXAMINAR EL RENDIMIENTO DE LAS CONSULTAS
Antes de probar el rendimiento de las consultas, tenga en cuenta que podemos usar Query Store para ver el rendimiento de INSERT y REBUILD:
SELECT [q].[query_id], [qt].[query_sql_text], SUM([rs].[count_executions]) [ExecutionCount], AVG([rs].[avg_duration])/1000 [AvgDuration_ms], AVG([rs].[avg_cpu_time]) [AvgCPU], AVG([rs].[avg_logical_io_reads]) [AvgLogicalReads], AVG([rs].[avg_physical_io_reads]) [AvgPhysicalReads] FROM [sys].[query_store_query] [q] JOIN [sys].[query_store_query_text] [qt] ON [q].[query_text_id] = [qt].[query_text_id] LEFT OUTER JOIN [sys].[objects] [o] ON [q].[object_id] = [o].[object_id] JOIN [sys].[query_store_plan] [p] ON [q].[query_id] = [p].[query_id] JOIN [sys].[query_store_runtime_stats] [rs] ON [p].[plan_id] = [rs].[plan_id] WHERE [qt].[query_sql_text] LIKE '%INSERT%' OR [qt].[query_sql_text] LIKE '%ALTER%' GROUP BY [q].[query_id], [q].[object_id], [o].[name], [qt].[query_sql_text], [rs].[plan_id] ORDER BY [q].[query_id];
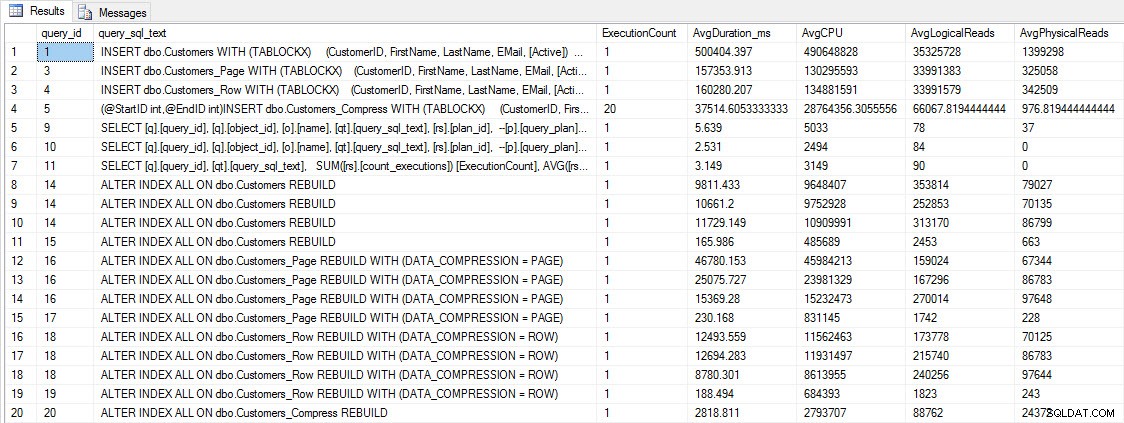 INSERTAR y RECONSTRUIR métricas de rendimiento
INSERTAR y RECONSTRUIR métricas de rendimiento
Si bien estos datos son interesantes, tengo más curiosidad acerca de cómo la compresión afecta mis consultas SELECT diarias. Tengo un conjunto de tres procedimientos almacenados, cada uno de los cuales tiene una consulta SELECT, de modo que se usa cada índice. Creé estos procedimientos para cada tabla y luego escribí una secuencia de comandos para extraer los valores de los nombres y apellidos para usarlos en las pruebas. Aquí está el script para crear los procedimientos.
Una vez que hayamos creado los procedimientos almacenados, podemos ejecutar el siguiente script para llamarlos. Inicia esto y luego espera un par de minutos...
SET NOCOUNT ON; GO DECLARE @RowNum INT = 1; DECLARE @Round INT = 1; DECLARE @ID INT = 1; DECLARE @FN NVARCHAR(64); DECLARE @LN NVARCHAR(64); DECLARE @SQLstring NVARCHAR(MAX); DROP TABLE IF EXISTS #FirstNames, #LastNames; SELECT DISTINCT [FirstName], DENSE_RANK() OVER (ORDER BY [FirstName]) AS RowNum INTO #FirstNames FROM [dbo].[Customers] SELECT DISTINCT [LastName], DENSE_RANK() OVER (ORDER BY [LastName]) AS RowNum INTO #LastNames FROM [dbo].[Customers] WHILE 1=1 BEGIN SELECT @FN = ( SELECT [FirstName] FROM #FirstNames WHERE RowNum = @RowNum) SELECT @LN = ( SELECT [LastName] FROM #LastNames WHERE RowNum = @RowNum) SET @FN = SUBSTRING(@FN, 1, 5) + '%' SET @LN = SUBSTRING(@LN, 1, 5) + '%' EXEC [dbo].[usp_FindActiveCustomer_C] @FN; EXEC [dbo].[usp_FindAnyCustomer_C] @LN; EXEC [dbo].[usp_FindSpecificCustomer_C] @ID; EXEC [dbo].[usp_FindActiveCustomer_P] @FN; EXEC [dbo].[usp_FindAnyCustomer_P] @LN; EXEC [dbo].[usp_FindSpecificCustomer_P] @ID; EXEC [dbo].[usp_FindActiveCustomer_R] @FN; EXEC [dbo].[usp_FindAnyCustomer_R] @LN; EXEC [dbo].[usp_FindSpecificCustomer_R] @ID; EXEC [dbo].[usp_FindActiveCustomer_CS] @FN; EXEC [dbo].[usp_FindAnyCustomer_CS] @LN; EXEC [dbo].[usp_FindSpecificCustomer_CS] @ID; IF @ID < 5000000 BEGIN SET @ID = @ID + @Round END ELSE BEGIN SET @ID = 2 END IF @Round < 26 BEGIN SET @Round = @Round + 1 END ELSE BEGIN IF @RowNum < 2260 BEGIN SET @RowNum = @RowNum + 1 SET @Round = 1 END ELSE BEGIN SET @RowNum = 1 SET @Round = 1 END END END GO
Después de unos minutos, mire lo que hay en Query Store:
SELECT [q].[query_id], [q].[object_id], [o].[name], [qt].[query_sql_text], SUM([rs].[count_executions]) [ExecutionCount], CAST(AVG([rs].[avg_duration])/1000 AS DECIMAL(10,2)) [AvgDuration_ms], CAST(AVG([rs].[avg_cpu_time]) AS DECIMAL(10,2)) [AvgCPU], CAST(AVG([rs].[avg_logical_io_reads]) AS DECIMAL(10,2)) [AvgLogicalReads], CAST(AVG([rs].[avg_physical_io_reads]) AS DECIMAL(10,2)) [AvgPhysicalReads] FROM [sys].[query_store_query] [q] JOIN [sys].[query_store_query_text] [qt] ON [q].[query_text_id] = [qt].[query_text_id] JOIN [sys].[objects] [o] ON [q].[object_id] = [o].[object_id] JOIN [sys].[query_store_plan] [p] ON [q].[query_id] = [p].[query_id] JOIN [sys].[query_store_runtime_stats] [rs] ON [p].[plan_id] = [rs].[plan_id] WHERE [q].[object_id] <> 0 GROUP BY [q].[query_id], [q].[object_id], [o].[name], [qt].[query_sql_text], [rs].[plan_id] ORDER BY [o].[name];
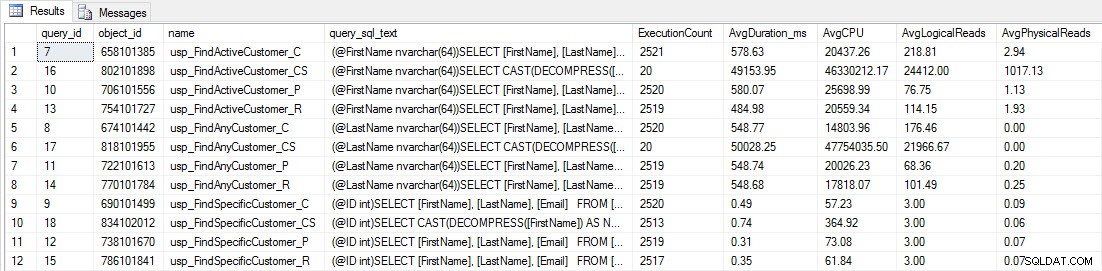
Verá que la mayoría de los procedimientos almacenados se han ejecutado solo 20 veces porque dos procedimientos contra [dbo].[Customers_Compress] son realmente lento. Esto no es una sorpresa; ni [FirstName] ni [LastName] están indexados, por lo que cualquier consulta tendrá que escanear la tabla. No quiero que esas dos consultas ralenticen mis pruebas, así que voy a modificar la carga de trabajo y comentar EXEC [dbo].[usp_FindActiveCustomer_CS] y EXEC [dbo].[usp_FindAnyCustomer_CS] y luego comenzarlo de nuevo. Esta vez, dejaré que se ejecute durante unos 10 minutos y, cuando vuelva a mirar el resultado del Almacén de consultas, ahora tengo buenos datos. Los números sin procesar se encuentran a continuación, con los gráficos favoritos de los gerentes a continuación.
 Datos de rendimiento de Query Store
Datos de rendimiento de Query Store
 Duración del procedimiento almacenado
Duración del procedimiento almacenado
 CPU de procedimiento almacenado
CPU de procedimiento almacenado
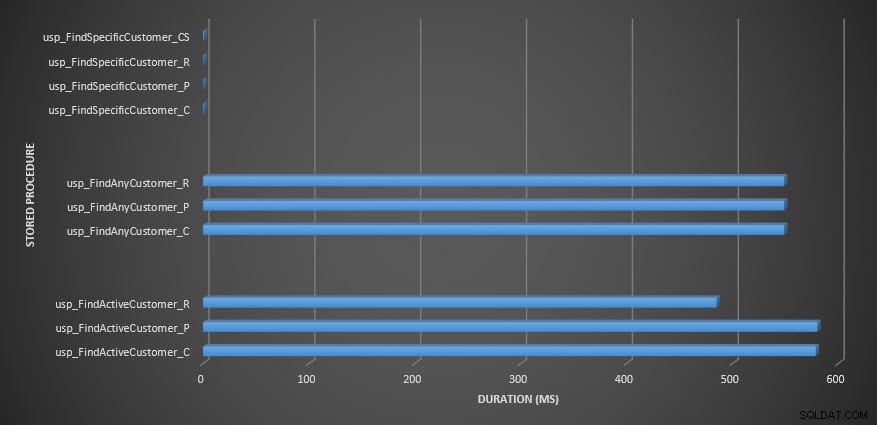
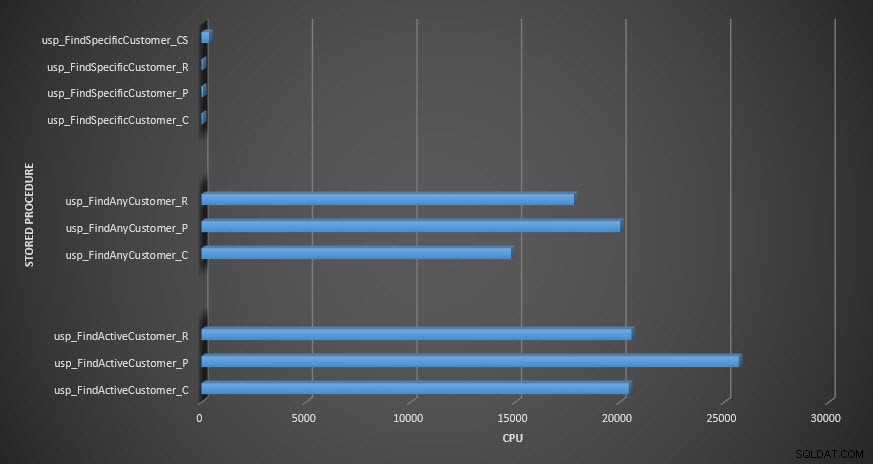
Recordatorio:Todos los procedimientos almacenados que terminan con _C son de la tabla no comprimida. Los procedimientos que terminan en _R son la tabla comprimida de filas, los que terminan en _P son de página comprimida y el que tiene _CS usa la función COMPRESS (eliminé los resultados de dicha tabla para usp_FindAnyCustomer_CS y usp_FindActiveCustomer_CS porque distorsionaron tanto el gráfico que perdimos el diferencias en el resto de los datos). Los procedimientos usp_FindAnyCustomer_* y usp_FindActiveCustomer_* utilizaron índices no agrupados y devolvieron miles de filas para cada ejecución.
Esperaba que la duración fuera mayor para los procedimientos usp_FindAnyCustomer_* y usp_FindActiveCustomer_* en tablas comprimidas de filas y páginas, en comparación con la tabla no comprimida, debido a la sobrecarga de descomprimir los datos. Los datos del Almacén de consultas no cumplen mis expectativas:la duración de esos dos procedimientos almacenados es aproximadamente la misma (¡o menos en un caso!) en esas tres tablas. El IO lógico para las consultas fue casi el mismo en las tablas no comprimidas y comprimidas en filas y páginas.
En términos de CPU, en los procedimientos almacenados usp_FindActiveCustomer y usp_FindAnyCustomer siempre fue mayor para las tablas comprimidas. La CPU era comparable para el procedimiento usp_FindSpecificCustomer, que siempre era una búsqueda única en el índice agrupado. Tenga en cuenta la CPU alta (pero la duración relativamente baja) para el procedimiento usp_FindSpecificCustomer contra la tabla [dbo].[Customer_Compress], que requería la función DECOMPRESS para mostrar los datos en un formato legible.
RESUMEN
La CPU adicional necesaria para recuperar datos comprimidos existe y se puede medir mediante Query Store o métodos tradicionales de referencia. Según esta prueba inicial, la CPU es comparable para las búsquedas de singleton, pero aumenta con más datos. Quería obligar a SQL Server a descomprimir más de 10 páginas, quería al menos 100. Ejecuté variaciones de este script, donde se devolvieron decenas de miles de filas y los hallazgos fueron consistentes con lo que ve aquí. Mi expectativa es que para ver diferencias significativas en la duración debido al tiempo de descompresión de los datos, las consultas deberían devolver cientos de miles o millones de filas. Si está en un sistema OLTP, no desea devolver tantas filas, por lo que las pruebas aquí deberían darle una idea de cómo la compresión puede afectar el rendimiento. Si está en un almacén de datos, probablemente verá una duración más alta junto con una CPU más alta cuando devuelva grandes conjuntos de datos. Si bien la función COMPRESS proporciona un ahorro de espacio significativo en comparación con la compresión de páginas y filas, el impacto en el rendimiento en términos de CPU y la incapacidad de indexar las columnas comprimidas debido a su tipo de datos, lo hacen viable solo para grandes volúmenes de datos que no serán buscado