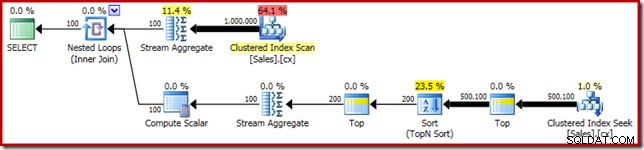
En enero de 2015, mi buen amigo y colega MVP de SQL Server, Rob Farley, escribió sobre una solución novedosa al problema de encontrar la mediana en las versiones de SQL Server anteriores a 2012. Además de ser una lectura interesante en sí misma, resulta ser un gran ejemplo para demostrar algunos análisis avanzados del plan de ejecución y para resaltar algunos comportamientos sutiles del optimizador de consultas y el motor de ejecución.
Mediana única
Aunque el artículo de Rob se enfoca específicamente en un cálculo de la mediana agrupada, voy a comenzar aplicando su método a un gran problema de cálculo de la mediana única, porque resalta los problemas importantes con mayor claridad. Una vez más, los datos de muestra provendrán del artículo original de Aaron Bertrand:
CREATE TABLE dbo.obj
(
id integer NOT NULL IDENTITY(1,1),
val integer NOT NULL
);
INSERT dbo.obj WITH (TABLOCKX)
(val)
SELECT TOP (10000000)
AO.[object_id]
FROM sys.all_columns AS AC
CROSS JOIN sys.all_objects AS AO
CROSS JOIN sys.all_objects AS AO2
WHERE AO.[object_id] > 0
ORDER BY
AC.[object_id];
CREATE UNIQUE CLUSTERED INDEX cx
ON dbo.obj(val, id); La aplicación de la técnica de Rob Farley a este problema da el siguiente código:
-- 5800ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(0E + f.val)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS t
ORDER BY
t.val DESC
) AS f;
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Como de costumbre, comenté el conteo del número de filas en la tabla y lo reemplacé con una constante para evitar una fuente de variación de rendimiento. El plan de ejecución para la consulta importante es el siguiente:

Esta consulta se ejecuta durante 5800 ms en mi máquina de prueba.
El tipo de derrame
La causa principal de este rendimiento deficiente debería quedar clara al observar el plan de ejecución anterior:la advertencia en el operador Sort muestra que una asignación de memoria de espacio de trabajo insuficiente provocó un derrame de nivel 2 (pasadas múltiples) en tempdb disco:
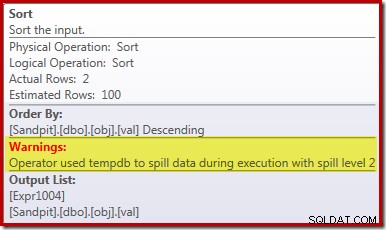
En las versiones de SQL Server anteriores a 2012, necesitaría monitorear por separado los eventos de derrame de clasificación para ver esto. De todos modos, la reserva de memoria de clasificación insuficiente se debe a un error de estimación de cardinalidad, como muestra el plan de ejecución previa (estimado):

La estimación de cardinalidad de 100 filas en la entrada Ordenar es una suposición (muy imprecisa) del optimizador, debido a la expresión de la variable local en el operador superior anterior:

Tenga en cuenta que este error de estimación de cardinalidad no es un problema de objetivo de fila. La aplicación de la marca de seguimiento 4138 eliminará el efecto de objetivo de fila debajo del primer Top, pero la estimación posterior al Top seguirá siendo una conjetura de 100 filas (por lo que la reserva de memoria para Ordenar seguirá siendo demasiado pequeña):

Sugiriendo el valor de la variable local
Hay varias formas de resolver este problema de estimación de cardinalidad. Una opción es utilizar una pista para proporcionar al optimizador información sobre el valor contenido en la variable:
-- 3250ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(0E + f.val)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS t
ORDER BY
t.val DESC
) AS f
OPTION (MAXDOP 1, OPTIMIZE FOR (@Count = 11000000)); -- NEW!
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); El uso de la sugerencia mejora el rendimiento a 3250 ms desde 5800ms. El plan posterior a la ejecución muestra que el género ya no se derrama:

Sin embargo, hay un par de desventajas en esto. Primero, este nuevo plan de ejecución requiere 388 MB concesión de memoria:memoria que, de lo contrario, podría ser utilizada por el servidor para almacenar en caché planes, índices y datos:
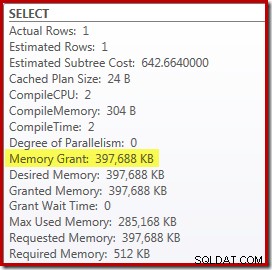
En segundo lugar, puede ser difícil elegir un buen número para la sugerencia que funcione bien para todas las ejecuciones futuras, sin reservar memoria innecesariamente.
Observe también que tuvimos que sugerir un valor para la variable que sea un 10 % más alto que el valor real de la variable para eliminar el derrame por completo. Esto no es poco común, porque el algoritmo de clasificación general es bastante más complejo que una simple clasificación en el lugar. Reservar una memoria equivalente al tamaño del conjunto que se ordenará no siempre (ni siquiera en general) será suficiente para evitar un derrame en el tiempo de ejecución.
Incrustación y recompilación
Otra opción es aprovechar la Optimización de incrustación de parámetros habilitada agregando una sugerencia de recompilación de nivel de consulta en SQL Server 2008 SP1 CU5 o posterior. Esta acción permitirá que el optimizador vea el valor de tiempo de ejecución de la variable y optimice en consecuencia:
-- 3150ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(0E + f.val)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS t
ORDER BY
t.val DESC
) AS f
OPTION (MAXDOP 1, RECOMPILE);
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());
Esto mejora el tiempo de ejecución a 3150ms – 100 ms mejor que usar OPTIMIZE FOR insinuación. La razón de esta pequeña mejora adicional se puede discernir en el nuevo plan posterior a la ejecución:

La expresión (2 – @Count % 2) – como se vio anteriormente en el segundo operador superior – ahora se puede plegar a un único valor conocido. Una reescritura posterior a la optimización puede combinar el Top con el Sort, lo que da como resultado un solo Top N Sort. Esta reescritura no era posible anteriormente porque colapsar Top + Sort en Top N Sort solo funciona con un valor Top literal constante (no variables ni parámetros).
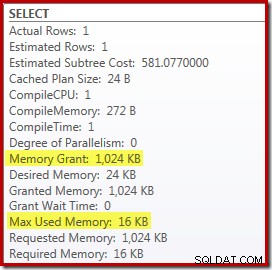
Reemplazar Top and Sort con Top N Sort tiene un pequeño efecto beneficioso en el rendimiento (100 ms aquí), pero también elimina casi por completo el requisito de memoria, porque Top N Sort solo tiene que realizar un seguimiento de los N más altos (o más bajos) filas, en lugar de todo el conjunto. Como resultado de este cambio en el algoritmo, el plan posterior a la ejecución de esta consulta muestra que el mínimo 1 MB la memoria estaba reservada para Top N Sort en este plan, y solo 16 KB se usó en tiempo de ejecución (recuerde, el plan de clasificación completa requería 388 MB):
Evitar la recompilación
El inconveniente (obvio) de usar la sugerencia de consulta de recompilación es que requiere una compilación completa en cada ejecución. En este caso, la sobrecarga es bastante pequeña:alrededor de 1 ms de tiempo de CPU y 272 KB de memoria. Aun así, hay una forma de modificar la consulta de modo que obtengamos los beneficios de una clasificación Top N sin usar ninguna sugerencia y sin volver a compilar.
La idea surge de reconocer que un máximo Se requerirán dos filas para el cálculo de la mediana final. Puede ser una fila, o pueden ser dos en tiempo de ejecución, pero nunca pueden ser más. Esta información significa que podemos agregar un paso intermedio superior (2) lógicamente redundante a la consulta de la siguiente manera:
-- 3150ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(0E + f.val)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (2) -- NEW!
z.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS z
ORDER BY z.val DESC
) AS t
ORDER BY
t.val DESC
) AS f
OPTION (MAXDOP 1);
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); El nuevo Top (con el literal constante de suma importancia) significa que el plan de ejecución final presenta el operador Top N Sort deseado sin volver a compilar:

El rendimiento de este plan de ejecución no ha cambiado con respecto a la versión con sugerencias de recompilación en 3150 ms y el requisito de memoria es el mismo. Sin embargo, tenga en cuenta que la falta de incrustación de parámetros significa que las estimaciones de cardinalidad debajo de la clasificación son conjeturas de 100 filas (aunque eso no afecta el rendimiento aquí).
La conclusión principal en esta etapa es que si desea una clasificación Top N con poca memoria, debe usar un literal constante o habilitar el optimizador para ver un literal a través de la optimización de incrustación de parámetros.
El cálculo escalar
Eliminando los 388 MB La concesión de memoria (al mismo tiempo que mejora el rendimiento de 100 ms) ciertamente vale la pena, pero hay una ganancia de rendimiento mucho mayor disponible. El objetivo improbable de esta mejora final es Compute Scalar justo encima de Clustered Index Scan.
Este cálculo escalar se relaciona con la expresión (0E + f.val) contenido en el AVG agregado en la consulta. En caso de que le parezca extraño, este es un truco de redacción de consultas bastante común (como multiplicar por 1,0) para evitar la aritmética de números enteros en el cálculo promedio, pero tiene algunos efectos secundarios muy importantes.
Aquí hay una secuencia particular de eventos que debemos seguir paso a paso.
Primero, observe que 0E es un cero literal constante, con un flotante tipo de datos. Para agregar esto a la columna de entero val, el procesador de consultas debe convertir la columna de entero a flotante (de acuerdo con las reglas de precedencia de tipos de datos). Sería necesario un tipo similar de conversión si hubiéramos elegido multiplicar la columna por 1.0 (un literal con un tipo de datos numérico implícito). El punto importante es que este truco de rutina introduce una expresión .
Ahora, SQL Server generalmente intenta empujar expresiones hacia abajo el árbol del plan en la medida de lo posible durante la compilación y la optimización. Esto se hace por varios motivos, entre ellos, para facilitar la coincidencia de expresiones con columnas calculadas y para facilitar las simplificaciones mediante el uso de información de restricciones. Esta política pushdown explica por qué Compute Scalar aparece mucho más cerca del nivel de hoja del plan de lo que sugeriría la posición textual original de la expresión en la consulta.
Un riesgo de realizar este empuje hacia abajo es que la expresión podría terminar calculándose más veces de las necesarias. La mayoría de los planes cuentan con un recuento de filas reducido a medida que avanzamos en el árbol del plan, debido al efecto de las uniones, la agregación y los filtros. Empujar expresiones hacia abajo en el árbol, por lo tanto, corre el riesgo de evaluar esas expresiones más veces (es decir, en más filas) de las necesarias.
Para mitigar esto, SQL Server 2005 introdujo una optimización mediante la cual Compute Scalars puede simplemente definir una expresión, con el trabajo de realmente evaluar la expresión diferida hasta que un operador posterior en el plan requiera el resultado. Cuando esta optimización funciona según lo previsto, el efecto es obtener todos los beneficios de empujar expresiones hacia abajo en el árbol, mientras que en realidad solo se evalúa la expresión tantas veces como sea necesario.
Qué significa todo esto de Compute Scalar
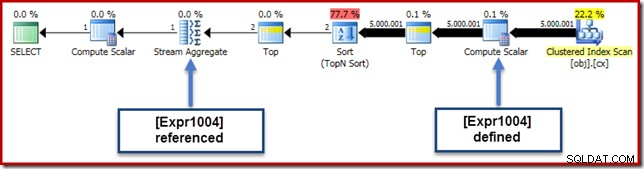
En nuestro ejemplo en ejecución, 0E + val expresión se asoció originalmente con el AVG agregado, por lo que podríamos esperar verlo en (o un poco después) del agregado de flujo. Sin embargo, esta expresión fue reducida el árbol para convertirse en un nuevo Compute Scalar justo después del escaneo, con la expresión etiquetada como [Expr1004].
Si observamos el plan de ejecución, podemos ver que [Expr1004] está referenciado por Stream Aggregate (extracto de la pestaña Expresiones del Explorador de planes que se muestra a continuación):

En igualdad de condiciones, la evaluación de la expresión [Expr1004] sería diferida hasta que el agregado necesite esos valores para la suma del cálculo del promedio. Dado que el agregado solo puede encontrar una o dos filas, esto debería resultar en que [Expr1004] se evalúe solo una o dos veces:
Desafortunadamente, no es así como funciona aquí. El problema es el operador de clasificación de bloqueo:
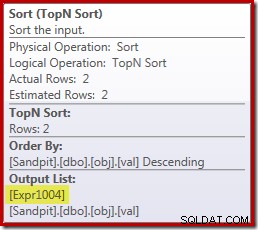
Esto fuerza la evaluación de [Expr1004], por lo que en lugar de evaluarse solo una o dos veces en Stream Aggregate, Sort significa que terminamos convirtiendo el val columna a un flotante y añadiéndole cero 5,000,001 veces!
Una solución alternativa
Idealmente, SQL Server sería un poco más inteligente con todo esto, pero no es así como funciona hoy. No hay ninguna sugerencia de consulta para evitar que las expresiones se desplacen hacia abajo en el árbol del plan, y tampoco podemos forzar el cálculo de escalares con una guía del plan. Hay, inevitablemente, una marca de seguimiento no documentada, pero no es una de la que pueda hablar responsablemente en el contexto actual.
Entonces, para bien o para mal, esto nos deja tratando de encontrar una reescritura de consulta que impida que SQL Server separe la expresión del agregado y la empuje más allá de Ordenar, sin cambiar el resultado de la consulta. Esto no es tan fácil como podría pensar, pero la modificación (ciertamente un poco extraña) a continuación logra esto usando un CASE expresión en una función intrínseca no determinista:
-- 2150ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
-- NEW!
Median = AVG(CASE WHEN GETDATE() >= {D '1753-01-01'} THEN 0E + f.val END)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (2)
z.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS z
ORDER BY z.val DESC
) AS t
ORDER BY
t.val DESC
) AS f
OPTION (MAXDOP 1);
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); El plan de ejecución para esta forma final de la consulta se muestra a continuación:

Observe que Compute Scalar ya no aparece entre el Clustered Index Scan y el Top. El 0E + val expresión ahora se calcula en Stream Aggregate en un máximo de dos filas (¡en lugar de cinco millones!) y el rendimiento aumenta en un 32 % adicional. de 3150ms a 2150ms como resultado.
Esto todavía no se compara tan bien con el rendimiento de subsegundos del OFFSET y soluciones dinámicas de cálculo de la mediana del cursor, pero aún representa una mejora muy significativa con respecto a los 5800ms originales para este método en un gran conjunto de problemas de mediana única.
Por supuesto, no se garantiza que el truco CASE funcione en el futuro. La conclusión no se trata tanto del uso de trucos extraños de expresión de casos, sino de las posibles implicaciones de rendimiento de Compute Scalars. Una vez que conozca este tipo de cosas, podría pensarlo dos veces antes de multiplicar por 1,0 o agregar un cero flotante dentro de un cálculo promedio.
Actualización: consulte el primer comentario para ver una buena solución de Robert Heinig que no requiere ningún truco no documentado. Algo a tener en cuenta la próxima vez que tenga la tentación de multiplicar un número entero por uno decimal (o flotante) en un agregado promedio.
Mediana agrupada
Para completar, y para vincular este análisis más estrechamente con el artículo original de Rob, terminaremos aplicando las mismas mejoras a un cálculo de la mediana agrupada. Los tamaños de conjunto más pequeños (por grupo) significan que los efectos serán más pequeños, por supuesto.
Los datos de la muestra mediana agrupados (nuevamente como los creó originalmente Aaron Bertrand) comprenden diez mil filas para cada uno de los cien vendedores imaginarios:
CREATE TABLE dbo.Sales
(
SalesPerson integer NOT NULL,
Amount integer NOT NULL
);
WITH X AS
(
SELECT TOP (100)
V.number
FROM master.dbo.spt_values AS V
GROUP BY
V.number
)
INSERT dbo.Sales WITH (TABLOCKX)
(
SalesPerson,
Amount
)
SELECT
X.number,
ABS(CHECKSUM(NEWID())) % 99
FROM X
CROSS JOIN X AS X2
CROSS JOIN X AS X3;
CREATE CLUSTERED INDEX cx
ON dbo.Sales
(SalesPerson, Amount); La aplicación directa de la solución de Rob Farley da como resultado el siguiente código, que se ejecuta en 560 ms en mi máquina.
-- 560ms Original
DECLARE @s datetime2 = SYSUTCDATETIME();
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT S.SalesPerson, COUNT_BIG(*) AS y
FROM dbo.Sales AS S
GROUP BY S.SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + f.Amount)
FROM
(
SELECT TOP (2 - d.y % 2)
t.Amount
FROM
(
SELECT TOP (d.y / 2 + 1)
z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount ASC
) AS t
ORDER BY t.Amount DESC
) AS f
) AS w (Median)
OPTION (MAXDOP 1);
SELECT DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); El plan de ejecución tiene similitudes obvias con la mediana única:
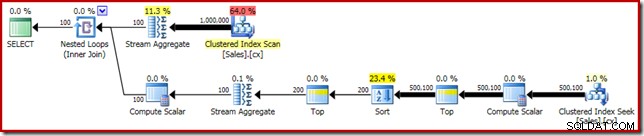
Nuestra primera mejora es reemplazar el ordenamiento con un ordenamiento superior N, agregando un inicio explícito (2). Esto mejora ligeramente el tiempo de ejecución de 560 ms a 550 ms .
-- 550ms
DECLARE @s datetime2 = SYSUTCDATETIME();
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT S.SalesPerson, COUNT_BIG(*) AS y
FROM dbo.Sales AS S
GROUP BY S.SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + f.Amount)
FROM
(
SELECT TOP (2 - d.y % 2)
q.Amount
FROM
(
-- NEW!
SELECT TOP (2) t.Amount
FROM
(
SELECT TOP (d.y / 2 + 1)
z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount ASC
) AS t
ORDER BY t.Amount DESC
) AS q
ORDER BY q.Amount DESC
) AS f
) AS w (Median)
OPTION (MAXDOP 1);
SELECT DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); El plan de ejecución muestra la ordenación Top N como se esperaba:
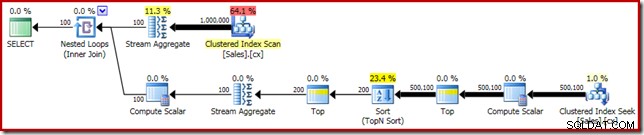
Finalmente, implementamos la expresión CASE de aspecto extraño para eliminar la expresión Compute Scalar insertada. Esto mejora aún más el rendimiento a 450 ms (una mejora del 20 % con respecto al original):
-- 450ms
DECLARE @s datetime2 = SYSUTCDATETIME();
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT S.SalesPerson, COUNT_BIG(*) AS y
FROM dbo.Sales AS S
GROUP BY S.SalesPerson
) AS d
CROSS APPLY
(
-- NEW!
SELECT AVG(CASE WHEN GETDATE() >= {D '1753-01-01'} THEN 0E + Amount END)
FROM
(
SELECT TOP (2 - d.y % 2)
q.Amount
FROM
(
SELECT TOP (2) t.Amount
FROM
(
SELECT TOP (d.y / 2 + 1)
z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount ASC
) AS t
ORDER BY t.Amount DESC
) AS q
ORDER BY q.Amount DESC
) AS f
) AS w (Median)
OPTION (MAXDOP 1);
SELECT DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); El plan de ejecución terminado es el siguiente: