Un escenario común en muchas aplicaciones cliente-servidor es permitir que el usuario final dicte el orden de clasificación de los resultados. Algunas personas quieren ver primero los artículos de menor precio, otras quieren ver primero los artículos más nuevos y otras quieren verlos en orden alfabético. Esto es algo complejo de lograr en Transact-SQL porque no puede simplemente decir:
CREATE PROCEDURE dbo.SortOnSomeTable @SortColumn NVARCHAR(128) = N'key_col', @SortDirection VARCHAR(4) = 'ASC' AS BEGIN ... ORDER BY @SortColumn; -- or ... ORDER BY @SortColumn @SortDirection; END GO
Esto se debe a que T-SQL no permite variables en estas ubicaciones. Si solo usa @SortColumn, recibe:
Mensaje 1008, nivel 16, estado 1, línea xEl elemento SELECT identificado por ORDER BY número 1 contiene una variable como parte de la expresión que identifica una posición de columna. Las variables solo se permiten cuando se ordenan por una expresión que hace referencia a un nombre de columna.
(Y cuando el mensaje de error dice "una expresión que hace referencia a un nombre de columna", es posible que lo encuentre ambiguo y estoy de acuerdo. Pero puedo asegurarle que esto no significa que una variable sea una expresión adecuada).
Si intenta agregar @SortDirection, el mensaje de error es un poco más opaco:
Mensaje 102, Nivel 15, Estado 1, Línea xSintaxis incorrecta cerca de '@SortDirection'.
Hay algunas formas de evitar esto, y su primer instinto podría ser usar SQL dinámico o introducir la expresión CASE. Pero como con la mayoría de las cosas, hay complicaciones que pueden obligarte a tomar un camino u otro. Entonces, ¿cuál deberías usar? Exploremos cómo podrían funcionar estas soluciones y comparemos los impactos en el rendimiento de algunos enfoques diferentes.
Datos de muestra
Usando una vista de catálogo que probablemente todos entendemos bastante bien, sys.all_objects, creé la siguiente tabla basada en una combinación cruzada, limitando la tabla a 100,000 filas (quería datos que llenaran muchas páginas pero que no tomó mucho tiempo para consultar y prueba):
CREATE DATABASE OrderBy;
GO
USE OrderBy;
GO
SELECT TOP (100000)
key_col = ROW_NUMBER() OVER (ORDER BY s1.[object_id]), -- a BIGINT with clustered index
s1.[object_id], -- an INT without an index
name = s1.name -- an NVARCHAR with a supporting index
COLLATE SQL_Latin1_General_CP1_CI_AS,
type_desc = s1.type_desc -- an NVARCHAR(60) without an index
COLLATE SQL_Latin1_General_CP1_CI_AS,
s1.modify_date -- a datetime without an index
INTO dbo.sys_objects
FROM sys.all_objects AS s1
CROSS JOIN sys.all_objects AS s2
ORDER BY s1.[object_id]; (El truco COLLATE se debe a que muchas vistas de catálogo tienen diferentes columnas con diferentes intercalaciones, y esto asegura que las dos columnas coincidirán para los propósitos de esta demostración).
Luego creé un par de índices agrupados / no agrupados típicos que podrían existir en dicha tabla, antes de la optimización (no puedo usar object_id para la clave, porque la unión cruzada crea duplicados):
CREATE UNIQUE CLUSTERED INDEX key_col ON dbo.sys_objects(key_col); CREATE INDEX name ON dbo.sys_objects(name);
Casos de uso
Como se mencionó anteriormente, es posible que los usuarios deseen ver estos datos ordenados de varias maneras, así que establezcamos algunos casos de uso típicos que queremos admitir (y por asistencia me refiero a demostrar):
- Ordenado por key_col ascendente ** predeterminado si al usuario no le importa
- Ordenado por object_id (ascendente/descendente)
- Ordenados por nombre (ascendente/descendente)
- Ordenado por type_desc (ascendente/descendente)
- Ordenado por modificar_fecha (ascendente/descendente)
Dejaremos el orden key_col como predeterminado porque debería ser el más eficiente si el usuario no tiene una preferencia; dado que key_col es un sustituto arbitrario que no debería significar nada para el usuario (y es posible que ni siquiera esté expuesto a él), no hay razón para permitir la ordenación inversa en esa columna.
Enfoques que no funcionan
El enfoque más común que veo cuando alguien comienza a abordar este problema por primera vez es introducir la lógica de control de flujo en la consulta. Esperan poder hacer esto:
SELECT key_col, [object_id], name, type_desc, modify_date
FROM dbo.sys_objects
ORDER BY
IF @SortColumn = 'key_col'
key_col
IF @SortColumn = 'object_id'
[object_id]
IF @SortColumn = 'name'
name
...
IF @SortDirection = 'ASC'
ASC
ELSE
DESC; Esto obviamente no funciona. A continuación, veo que CASE se introduce incorrectamente, utilizando una sintaxis similar:
SELECT key_col, [object_id], name, type_desc, modify_date
FROM dbo.sys_objects
ORDER BY CASE @SortColumn
WHEN 'key_col' THEN key_col
WHEN 'object_id' THEN [object_id]
WHEN 'name' THEN name
...
END CASE @SortDirection WHEN 'ASC' THEN ASC ELSE DESC END; Esto está más cerca, pero falla por dos razones. Una es que CASE es una expresión que devuelve exactamente un valor de un tipo de datos específico; esto fusiona tipos de datos que son incompatibles y, por lo tanto, romperá la expresión CASE. La otra es que no hay forma de aplicar condicionalmente la dirección de clasificación de esta manera sin usar SQL dinámico.
Enfoques que funcionan
Los tres enfoques principales que he visto son los siguientes:
Agrupar tipos e indicaciones compatibles
Para usar CASE con ORDER BY, debe haber una expresión distinta para cada combinación de tipos y direcciones compatibles. En este caso tendríamos que usar algo como esto:
CREATE PROCEDURE dbo.Sort_CaseExpanded
@SortColumn NVARCHAR(128) = N'key_col',
@SortDirection VARCHAR(4) = 'ASC'
AS
BEGIN
SET NOCOUNT ON;
SELECT key_col, [object_id], name, type_desc, modify_date
FROM dbo.sys_objects
ORDER BY
CASE WHEN @SortDirection = 'ASC' THEN
CASE @SortColumn
WHEN 'key_col' THEN key_col
WHEN 'object_id' THEN [object_id]
END
END,
CASE WHEN @SortDirection = 'DESC' THEN
CASE @SortColumn
WHEN 'key_col' THEN key_col
WHEN 'object_id' THEN [object_id]
END
END DESC,
CASE WHEN @SortDirection = 'ASC' THEN
CASE @SortColumn
WHEN 'name' THEN name
WHEN 'type_desc' THEN type_desc
END
END,
CASE WHEN @SortDirection = 'DESC' THEN
CASE @SortColumn
WHEN 'name' THEN name
WHEN 'type_desc' THEN type_desc
END
END DESC,
CASE WHEN @SortColumn = 'modify_date'
AND @SortDirection = 'ASC' THEN modify_date
END,
CASE WHEN @SortColumn = 'modify_date'
AND @SortDirection = 'DESC' THEN modify_date
END DESC;
END Podrías decir, wow, ese es un código feo, y estaría de acuerdo contigo. Creo que esta es la razón por la que mucha gente almacena en caché sus datos en la interfaz y deja que el nivel de presentación se encargue de hacer malabarismos en diferentes órdenes. :-)
Puede colapsar esta lógica un poco más al convertir todos los tipos que no son cadenas en cadenas que se ordenarán correctamente, por ejemplo,
CREATE PROCEDURE dbo.Sort_CaseCollapsed
@SortColumn NVARCHAR(128) = N'key_col',
@SortDirection VARCHAR(4) = 'ASC'
AS
BEGIN
SET NOCOUNT ON;
SELECT key_col, [object_id], name, type_desc, modify_date
FROM dbo.sys_objects
ORDER BY
CASE WHEN @SortDirection = 'ASC' THEN
CASE @SortColumn
WHEN 'key_col' THEN RIGHT('000000000000' + RTRIM(key_col), 12)
WHEN 'object_id' THEN
RIGHT(COALESCE(NULLIF(LEFT(RTRIM([object_id]),1),'-'),'0')
+ REPLICATE('0', 23) + RTRIM([object_id]), 24)
WHEN 'name' THEN name
WHEN 'type_desc' THEN type_desc
WHEN 'modify_date' THEN CONVERT(CHAR(19), modify_date, 120)
END
END,
CASE WHEN @SortDirection = 'DESC' THEN
CASE @SortColumn
WHEN 'key_col' THEN RIGHT('000000000000' + RTRIM(key_col), 12)
WHEN 'object_id' THEN
RIGHT(COALESCE(NULLIF(LEFT(RTRIM([object_id]),1),'-'),'0')
+ REPLICATE('0', 23) + RTRIM([object_id]), 24)
WHEN 'name' THEN name
WHEN 'type_desc' THEN type_desc
WHEN 'modify_date' THEN CONVERT(CHAR(19), modify_date, 120)
END
END DESC;
END Aún así, es un lío bastante feo, y tienes que repetir las expresiones dos veces para lidiar con las diferentes direcciones de clasificación. También sospecho que el uso de OPTION RECOMPILE en esa consulta evitaría que el rastreo de parámetros lo pique. Excepto en el caso predeterminado, no es que la mayor parte del trabajo que se realiza aquí vaya a ser de compilación.
Aplicar una clasificación usando funciones de ventana
Descubrí este ingenioso truco de AndriyM, aunque es más útil en los casos en que todas las columnas de ordenamiento potenciales son de tipos compatibles; de lo contrario, la expresión utilizada para ROW_NUMBER() es igualmente compleja. La parte más inteligente es que para cambiar entre orden ascendente y descendente, simplemente multiplicamos ROW_NUMBER() por 1 o -1. Podemos aplicarlo en esta situación de la siguiente manera:
CREATE PROCEDURE dbo.Sort_RowNumber
@SortColumn NVARCHAR(128) = N'key_col',
@SortDirection VARCHAR(4) = 'ASC'
AS
BEGIN
SET NOCOUNT ON;
;WITH x AS
(
SELECT key_col, [object_id], name, type_desc, modify_date,
rn = ROW_NUMBER() OVER (
ORDER BY CASE @SortColumn
WHEN 'key_col' THEN RIGHT('000000000000' + RTRIM(key_col), 12)
WHEN 'object_id' THEN
RIGHT(COALESCE(NULLIF(LEFT(RTRIM([object_id]),1),'-'),'0')
+ REPLICATE('0', 23) + RTRIM([object_id]), 24)
WHEN 'name' THEN name
WHEN 'type_desc' THEN type_desc
WHEN 'modify_date' THEN CONVERT(CHAR(19), modify_date, 120)
END
) * CASE @SortDirection WHEN 'ASC' THEN 1 ELSE -1 END
FROM dbo.sys_objects
)
SELECT key_col, [object_id], name, type_desc, modify_date
FROM x
ORDER BY rn;
END
GO Nuevamente, OPTION RECOMPILE puede ayudar aquí. Además, es posible que observe en algunos de estos casos que los vínculos se manejan de manera diferente según los distintos planes; al ordenar por nombre, por ejemplo, generalmente verá que key_col aparece en orden ascendente dentro de cada conjunto de nombres duplicados, pero también puede ver los valores se mezclaron. Para proporcionar un comportamiento más predecible en caso de empate, siempre puede agregar una cláusula ORDER BY adicional. Tenga en cuenta que si agregara key_col al primer ejemplo, deberá convertirlo en una expresión para que key_col no aparezca en ORDER BY dos veces (puede hacerlo usando key_col + 0, por ejemplo).
SQL dinámico
Mucha gente tiene reservas sobre el SQL dinámico:es imposible de leer, es un caldo de cultivo para la inyección de SQL, conduce a la expansión del caché del plan, anula el propósito de usar procedimientos almacenados... Algunos de estos son simplemente falsos, y otros son fáciles de mitigar. He agregado algunas validaciones aquí que podrían agregarse fácilmente a cualquiera de los procedimientos anteriores:
CREATE PROCEDURE dbo.Sort_DynamicSQL
@SortColumn NVARCHAR(128) = N'key_col',
@SortDirection VARCHAR(4) = 'ASC'
AS
BEGIN
SET NOCOUNT ON;
-- reject any invalid sort directions:
IF UPPER(@SortDirection) NOT IN ('ASC','DESC')
BEGIN
RAISERROR('Invalid parameter for @SortDirection: %s', 11, 1, @SortDirection);
RETURN -1;
END
-- reject any unexpected column names:
IF LOWER(@SortColumn) NOT IN (N'key_col', N'object_id', N'name', N'type_desc', N'modify_date')
BEGIN
RAISERROR('Invalid parameter for @SortColumn: %s', 11, 1, @SortColumn);
RETURN -1;
END
SET @SortColumn = QUOTENAME(@SortColumn);
DECLARE @sql NVARCHAR(MAX);
SET @sql = N'SELECT key_col, [object_id], name, type_desc, modify_date
FROM dbo.sys_objects
ORDER BY ' + @SortColumn + ' ' + @SortDirection + ';';
EXEC sp_executesql @sql;
END Comparaciones de rendimiento
Creé un procedimiento almacenado contenedor para cada procedimiento anterior, de modo que pudiera probar fácilmente todos los escenarios. Los cuatro procedimientos de envoltorio se ven así, con el nombre del procedimiento variando, por supuesto:
CREATE PROCEDURE dbo.Test_Sort_CaseExpanded AS BEGIN SET NOCOUNT ON; EXEC dbo.Sort_CaseExpanded; -- default EXEC dbo.Sort_CaseExpanded N'name', 'ASC'; EXEC dbo.Sort_CaseExpanded N'name', 'DESC'; EXEC dbo.Sort_CaseExpanded N'object_id', 'ASC'; EXEC dbo.Sort_CaseExpanded N'object_id', 'DESC'; EXEC dbo.Sort_CaseExpanded N'type_desc', 'ASC'; EXEC dbo.Sort_CaseExpanded N'type_desc', 'DESC'; EXEC dbo.Sort_CaseExpanded N'modify_date', 'ASC'; EXEC dbo.Sort_CaseExpanded N'modify_date', 'DESC'; END
Y luego, usando SQL Sentry Plan Explorer, generé planes de ejecución reales (y las métricas correspondientes) con las siguientes consultas y repetí el proceso 10 veces para resumir la duración total:
DBCC DROPCLEANBUFFERS; DBCC FREEPROCCACHE; EXEC dbo.Test_Sort_CaseExpanded; --EXEC dbo.Test_Sort_CaseCollapsed; --EXEC dbo.Test_Sort_RowNumber; --EXEC dbo.Test_Sort_DynamicSQL; GO 10
También probé los primeros tres casos con OPTION RECOMPILE (no tiene mucho sentido para el caso de SQL dinámico, ya que sabemos que será un plan nuevo cada vez), y los cuatro casos con MAXDOP 1 para eliminar la interferencia de paralelismo. Estos son los resultados:
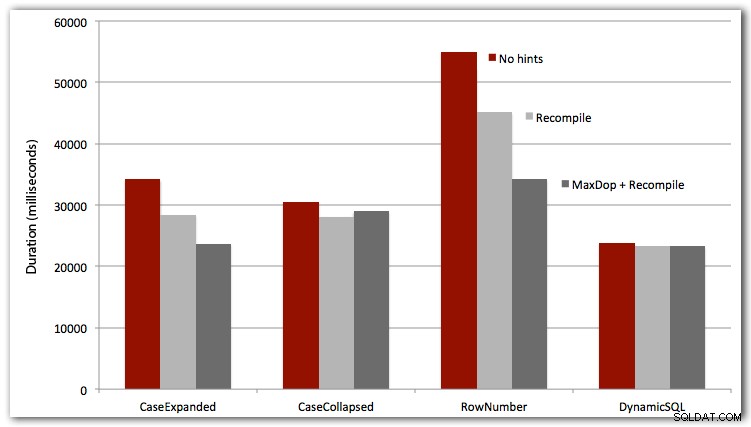
Conclusión
Para un rendimiento absoluto, el SQL dinámico siempre gana (aunque solo por un pequeño margen en este conjunto de datos). El enfoque ROW_NUMBER(), aunque inteligente, fue el perdedor en cada prueba (lo siento, AndriyM).
Se vuelve aún más divertido cuando desea introducir una cláusula WHERE, sin importar la paginación. Estos tres son como la tormenta perfecta para introducir complejidad en lo que comienza como una simple consulta de búsqueda. Cuantas más permutaciones tenga su consulta, más probable es que desee eliminar la legibilidad y usar SQL dinámico en combinación con la configuración "optimizar para cargas de trabajo ad hoc" para minimizar el impacto de los planes de un solo uso en la memoria caché de su plan.