Este artículo es la quinta parte de una serie sobre errores, trampas y mejores prácticas de T-SQL. Anteriormente cubrí el determinismo, las subconsultas, las uniones y las ventanas. Este mes, cubro pivotar y no pivotar. ¡Gracias Erland Sommarskog, Aaron Bertrand, Alejandro Mesa, Umachandar Jayachandran (UC), Fabiano Neves Amorim, Milos Radivojevic, Simon Sabin, Adam Machanic, Thomas Grohser, Chan Ming Man y Paul White por compartir sus sugerencias!
En mis ejemplos, usaré una base de datos de muestra llamada TSQLV5. Puede encontrar el script que crea y completa esta base de datos aquí, y su diagrama ER aquí.
Agrupación implícita con PIVOT
Cuando las personas quieren pivotar datos usando T-SQL, usan una solución estándar con una consulta agrupada y expresiones CASE, o el operador de tabla PIVOT patentado. El principal beneficio del operador PIVOT es que tiende a generar un código más corto. Sin embargo, este operador tiene algunas deficiencias, entre ellas una trampa de diseño inherente que puede generar errores en su código. Aquí describiré la trampa, el error potencial y una mejor práctica que previene el error. También describiré una sugerencia para mejorar la sintaxis del operador PIVOT de una manera que ayude a evitar el error.
Cuando pivotea datos, hay tres pasos que están involucrados en la solución, con tres elementos asociados:
- Grupo basado en un elemento de agrupación/en filas
- Difusión basada en un elemento de difusión/en columnas
- Agregar en función de una agregación/elemento de datos
La siguiente es la sintaxis del operador PIVOT:
SELECTFROM PIVOT( ( ) FOR IN( ) ) AS ;
El diseño del operador PIVOT requiere que especifique explícitamente los elementos de agregación y dispersión, pero permite que SQL Server determine implícitamente el elemento de agrupación por eliminación. Cualesquiera que sean las columnas que aparecen en la tabla de origen que se proporciona como entrada para el operador PIVOT, implícitamente se convierten en el elemento de agrupación.
Suponga, por ejemplo, que desea consultar la tabla Sales.Orders en la base de datos de muestra TSQLV5. Desea devolver los ID del remitente en las filas, los años de envío en las columnas y el recuento de pedidos por remitente y año como agregado.
Muchas personas tienen dificultades para descifrar la sintaxis del operador PIVOT, y esto a menudo resulta en la agrupación de datos por elementos no deseados. Como ejemplo de nuestra tarea, suponga que no se da cuenta de que el elemento de agrupación está determinado implícitamente y se le ocurre la siguiente consulta:
SELECT shipperid, [2017], [2018], [2019]FROM Sales.Orders CROSS APPLY( VALUES(YEAR(shippeddate)) ) AS D(shippedyear) PIVOT( COUNT(shippeddate) FOR shippingyear IN([2017] , [2018], [2019]) ) AS P;
Solo hay tres remitentes presentes en los datos, con los ID de remitente 1, 2 y 3. Por lo tanto, espera ver solo tres filas en el resultado. Sin embargo, el resultado de la consulta real muestra muchas más filas:
shipperid 2017 2018 2019----------- ----------- ----------- ---------- -3 1 0 01 1 0 02 1 0 01 1 0 02 1 0 02 1 0 02 1 0 03 1 0 02 1 0 03 1 0 0...3 0 1 03 0 1 03 0 1 01 0 1 03 0 1 01 0 1 03 0 1 03 0 1 03 0 1 01 0 1 0...3 0 0 11 0 0 12 0 0 11 0 0 12 0 0 11 0 0 13 0 0 13 0 0 12 0 1 0...(830 filas afectadas)
¿Qué pasó?
Puede encontrar una pista que lo ayude a descubrir el error en el código mirando el plan de consulta que se muestra en la Figura 1.
 Figura 1:Plan para consulta dinámica con agrupación implícita
Figura 1:Plan para consulta dinámica con agrupación implícita
No permita que el uso del operador CROSS APPLY con la cláusula VALUES en la consulta lo confunda. Esto se hace simplemente para calcular la columna de resultado del año de envío en función de la columna de fecha de envío de origen, y lo maneja el primer operador Compute Scalar del plan.
La tabla de entrada del operador PIVOT contiene todas las columnas de la tabla Ventas.Pedidos, además de la columna de resultado año de envío. Como se mencionó, SQL Server determina el elemento de agrupación implícitamente mediante la eliminación en función de lo que no especificó como los elementos de agregación (fecha de envío) y expansión (año de envío). Tal vez esperaba intuitivamente que la columna de ID de envío fuera la columna de agrupación porque aparece en la lista SELECCIONAR, pero como puede ver en el plan, en la práctica obtuvo una lista de columnas mucho más larga, incluido ID de pedido, que es la columna de clave principal en la tabla de origen. Esto significa que en lugar de obtener una fila por remitente, obtiene una fila por pedido. Dado que en la lista SELECT especificó solo las columnas shipperid, [2017], [2018] y [2019], no ve el resto, lo que aumenta la confusión. Pero el resto sí participó en la agrupación implícita.
Lo que podría ser genial es si la sintaxis del operador PIVOT admite una cláusula en la que puede indicar explícitamente el elemento de agrupación/en filas. Algo como esto:
SELECTFROM PIVOT( ( ) FOR IN( ) ON ROWS ) AS ;
Según esta sintaxis, usaría el siguiente código para manejar nuestra tarea:
SELECT shipperid, [2017], [2018], [2019]FROM Sales.Orders CROSS APPLY( VALUES(YEAR(shippeddate)) ) AS D(shippedyear) PIVOT( COUNT(shippeddate) FOR shippingyear IN([2017] , [2018], [2019]) ON ROWS shipperid ) COMO P;
Puede encontrar un elemento de comentarios con una sugerencia para mejorar la sintaxis del operador PIVOT aquí. Para que esta mejora sea un cambio permanente, esta cláusula se puede hacer opcional, siendo el comportamiento existente el predeterminado. Hay otras sugerencias para mejorar la sintaxis del operador PIVOT haciéndolo más dinámico y admitiendo múltiples agregados.
Mientras tanto, hay una mejor práctica que puede ayudarlo a evitar el error. Use una expresión de tabla como un CTE o una tabla derivada donde proyecte solo los tres elementos que necesita para participar en la operación de pivote y luego use la expresión de tabla como entrada para el operador PIVOT. De esta manera, usted controla completamente el elemento de agrupación. Aquí está la sintaxis general siguiendo esta mejor práctica:
WITHAS( SELECT , , FROM )SELECT FROM PIVOT( ( ) FOR IN( ) ) COMO ;
Aplicado a nuestra tarea, utiliza el siguiente código:
WITH C AS( SELECCIONE id de envío, AÑO (fecha de envío) AS año de envío, fecha de envío FROM Ventas.Pedidos) SELECCIONE id de envío, [2017], [2018], [2019] DE C PIVOT ( COUNT (fecha de envío) FOR año de envío IN ([ 2017], [2018], [2019]) ) AS P;
Esta vez obtienes solo tres filas de resultados como se esperaba:
shipperid 2017 2018 2019----------- ----------- ----------- ---------- -3 51 125 731 36 130 792 56 143 116
Otra opción es usar la solución estándar antigua y clásica para pivotar usando una consulta agrupada y expresiones CASE, así:
SELECCIONE id del envío, CUENTA(CASO CUANDO año de envío =2017 ENTONCES 1 FIN) COMO [2017], CUENTA(CASO CUANDO año de envío =2018 ENTONCES 1 FIN) COMO [2018], CUENTA(CASO CUANDO año de envío =2019 ENTONCES 1 FIN) COMO [2019]FROM Sales.Orders CROSS APPLY(VALUES(YEAR(shippeddate)) ) AS D(shippedyear)WHERE shippingdate IS NOT NULLGROUP BY shipperid;
Con esta sintaxis, los tres pasos pivotantes y sus elementos asociados deben ser explícitos en el código. Sin embargo, cuando tiene una gran cantidad de valores de dispersión, esta sintaxis tiende a ser detallada. En tales casos, la gente suele preferir usar el operador PIVOT.
Eliminación implícita de NULL con UNPIVOT
El siguiente elemento de este artículo es más una trampa que un error. Tiene que ver con el operador T-SQL UNPIVOT patentado, que le permite descentrar datos de un estado de columnas a un estado de filas.
Usaré una tabla llamada CustOrders como mis datos de muestra. Utilice el siguiente código para crear, completar y consultar esta tabla para mostrar su contenido:
DROP TABLE IF EXISTS dbo.CustOrders;IR CON C AS( SELECT custid, YEAR(orderdate) AS orderyearyear, val FROM Sales.OrderValues)SELECT custid, [2017], [2018], [2019]INTO dbo.CustOrdersFROM C PIVOT( SUM(val) FOR orderyearyear IN([2017], [2018], [2019]) ) AS P; SELECCIONE * DESDE dbo.PedidosCust;
Este código genera el siguiente resultado:
custid 2017 2018 2019------- ---------- ---------- ----------1 NULL 2022.50 2250.502 88.80 799.75 514.403 403.20 5960.78 660.004 1379.00 6406.90 5604.755 4324.40 13849.02 6754.166 NULL 1079.80 2160.007 9986.20 7817.88 730.008 982.00 3026.85 224.009 4074.28 11208.36 6680.6110 1832.80 7630.25 11338.5611 479.40 3179.50 2431.0012 NULL 238.00 1576.8013 100.80 NULL NULL14 1674.22 6516.40 4158.2615 2169.00 1128.00 513.7516 NULL 787.60 931.5017 533.60 420.00 2809.6118 268.80 487.00 860.1019 950.00 4514.35 9296.6920 15568.07 48096.27 41210.65...
Esta tabla contiene los valores totales de pedido por cliente y año. Los valores NULL representan casos en los que un cliente no tuvo ninguna actividad de pedido en el año objetivo.
Suponga que desea anular la dinámica de los datos de la tabla CustOrders, devolviendo una fila por cliente y año, con una columna de resultado llamada val que contiene el valor total del pedido para el cliente y el año actuales. Cualquier tarea sin pivotar generalmente involucra tres elementos:
- Los nombres de las columnas de origen existentes que está eliminando:[2017], [2018], [2019] en nuestro caso
- Un nombre que asigne a la columna de destino que contendrá los nombres de las columnas de origen:orderyear en nuestro caso
- Un nombre que asigne a la columna de destino que contendrá los valores de la columna de origen:val en nuestro caso
Si decide usar el operador UNPIVOT para manejar la tarea no pivotante, primero descubra los tres elementos anteriores y luego use la siguiente sintaxis:
SELECT, , FROM UNPIVOT( FOR IN( ) ) AS ;
Aplicado a nuestra tarea, utiliza la siguiente consulta:
SELECT custid, orderyear, valFROM dbo.CustOrders UNPIVOT( val FOR orderyear IN([2017], [2018], [2019]) ) AS U;
Esta consulta genera el siguiente resultado:
valor del año del pedido de custid------- ---------- ----------1 2018 2022.501 2019 2250.502 2017 88.802 2018 799.752 2019 514.403 2017 403.203 2018 5960.783 2019 660.004 2017 1379.004 2018 6406.904 2019 5604.755 2017 4324.405 2018 13849.025 2019 6754.166 2018 1079.806 2019 2160.007 2017 9986.207 2018 7817.887 2019 730.00 ...
Mirando los datos de origen y el resultado de la consulta, ¿nota lo que falta?
El diseño del operador UNPIVOT implica una eliminación implícita de las filas de resultados que tienen un NULL en la columna de valores, val en nuestro caso. Si observa el plan de ejecución de esta consulta que se muestra en la Figura 2, puede ver que el operador Filter elimina las filas con valores NULL en la columna val (Expr1007 en el plan).
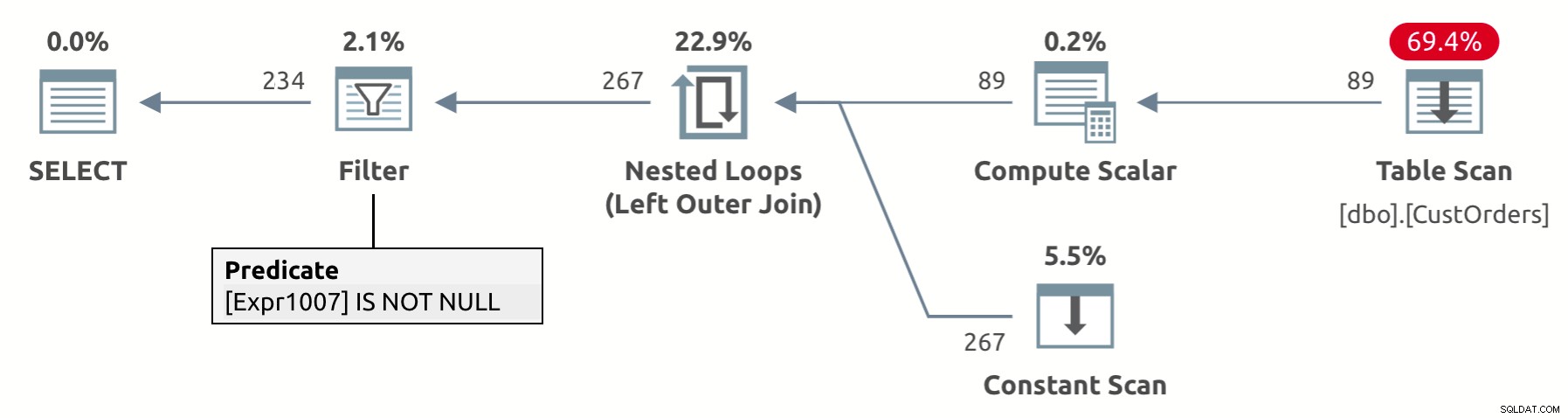 Figura 2:Plan para consultas no dinámicas con eliminación implícita de valores NULL
Figura 2:Plan para consultas no dinámicas con eliminación implícita de valores NULL
A veces, este comportamiento es deseable, en cuyo caso no necesita hacer nada especial. El problema es que a veces desea mantener las filas con NULL. El escollo es cuando desea mantener los valores NULL y ni siquiera se da cuenta de que el operador UNPIVOT está diseñado para eliminarlos.
Lo que podría ser genial es si el operador UNPIVOT tuviera una cláusula opcional que le permitiera especificar si desea eliminar o mantener NULL, siendo el primero el predeterminado para la compatibilidad con versiones anteriores. Este es un ejemplo de cómo se vería esta sintaxis:
SELECT, , FROM UNPIVOT( FOR IN( ) [REMOVE NULLS | KEEP NULLS] ) AS ;
Si quisiera mantener NULL, según esta sintaxis, usaría la siguiente consulta:
SELECT custid, orderyear, valFROM dbo.CustOrders UNPIVOT(val FOR orderyear IN([2017], [2018], [2019]) KEEP NULLS ) AS U;
Puede encontrar un elemento de comentarios con una sugerencia para mejorar la sintaxis del operador UNPIVOT de esta manera aquí.
Mientras tanto, si desea mantener las filas con NULL, debe encontrar una solución alternativa. Si insiste en usar el operador UNPIVOT, debe aplicar dos pasos. En el primer paso, define una expresión de tabla basada en una consulta que usa la función ISNULL o COALESCE para reemplazar NULL en todas las columnas no pivotadas con un valor que normalmente no puede aparecer en los datos, por ejemplo, -1 en nuestro caso. En el segundo paso, utiliza la función NULLIF en la consulta externa contra la columna de valores para reemplazar el -1 con un NULL. Aquí está el código completo de la solución:
CON C AS( SELECT custid, ISNULL([2017], -1.0) AS [2017], ISNULL([2018], -1.0) AS [2018], ISNULL([2019], -1.0) AS [2019 ] FROM dbo.CustOrders)SELECT custid, orderyear, NULLIF(val, -1.0) AS valFROM C UNPIVOT(val FOR orderyear IN([2017], [2018], [2019]) ) AS U;
Aquí está el resultado de esta consulta que muestra que se conservan las filas con valores NULL en la columna val:
valor de año de pedido de custid------- ---------- ----------1 2017 NULL1 2018 2022.501 2019 2250.502 2017 88.802 2018 799.752 2019 514.403 2017 403.203 2018 5960.783 2019 660.004 2017 1379.004 2018 6406.904 2019 5604.755 2017 4324.405 2018 13849.025 2019 6754.166 2017 NULL6 2018 1079.806 2019 2160.007 2017 9986.207 2018 7817.887 2019 730.00 ...Este enfoque es incómodo, especialmente cuando tiene una gran cantidad de columnas para anular el pivote.
Una solución alternativa utiliza una combinación del operador APPLY y la cláusula VALUES. Usted construye una fila para cada columna sin pivotar, con una columna que representa la columna de nombres de destino (orderyear en nuestro caso) y otra que representa la columna de valores de destino (val en nuestro caso). Proporcione el año constante para la columna de nombres y la columna de origen correlacionada relevante para la columna de valores. Aquí está el código completo de la solución:
SELECT custid, orderyear, valFROM dbo.CustOrders CROSS APPLY ( VALORES(2017, [2017]), (2018, [2018]), (2019, [2019]) ) AS A(orderyear, val);Lo bueno aquí es que, a menos que esté interesado en eliminar las filas con NULL en la columna val, no necesita hacer nada especial. No hay ningún paso implícito aquí que elimine las filas con NULLS. Además, dado que el alias de la columna val se crea como parte de la cláusula FROM, es accesible para la cláusula WHERE. Entonces, si está interesado en la eliminación de los NULL, puede ser explícito al respecto en la cláusula WHERE al interactuar directamente con el alias de la columna de valores, así:
SELECCIONE custid, orderyear, valFROM dbo.CustOrders CROSS APPLY ( VALORES(2017, [2017]), (2018, [2018]), (2019, [2019]) ) AS A(orderyear, val)DONDE val ES NO NULO;El punto es que esta sintaxis le da el control de si desea mantener o eliminar NULL. Es más flexible que el operador UNPIVOT de otra manera, lo que le permite manejar múltiples medidas no pivotadas, como val y qty. Sin embargo, mi enfoque en este artículo fue la trampa que involucra a los NULL, por lo que no me metí en este aspecto.
Conclusión
El diseño de los operadores PIVOT y UNPIVOT a veces genera errores y dificultades en su código. La sintaxis del operador PIVOT no le permite indicar explícitamente el elemento de agrupación. Si no se da cuenta de esto, puede terminar con elementos de agrupación no deseados. Como práctica recomendada, se recomienda que use una expresión de tabla como entrada para el operador PIVOT, y por eso controle explícitamente cuál es el elemento de agrupación.
La sintaxis del operador UNPIVOT no le permite controlar si eliminar o mantener filas con NULL en la columna de valores de resultado. Como solución alternativa, utilice una solución incómoda con las funciones ISNULL y NULLIF, o una solución basada en el operador APPLY y la cláusula VALUES.
También mencioné dos elementos de comentarios con sugerencias para mejorar los operadores PIVOT y UNPIVOT con opciones más explícitas para controlar el comportamiento del operador y sus elementos.