Introducción
Carretes de rendimiento son carretes perezosos agregados por el optimizador para reducir el costo estimado del lado interno de uniones de bucles anidados . Vienen en tres variedades:Lazy Table Spool , Bobina de índice diferida y Lazy Row Count Spool . A continuación, se incluye una forma de plan de ejemplo que muestra una cola de rendimiento de mesa perezosa:
Las preguntas que me propuse responder en este artículo son por qué, cómo y cuándo el optimizador de consultas presenta cada tipo de cola de rendimiento.
Justo antes de comenzar, quiero enfatizar un punto importante:hay dos tipos distintos de unión de bucle anidado en los planes de ejecución. Me referiré a la variedad con referencias externas como aplicar y el tipo con un predicado de unión en el propio operador de unión como una unión de bucles anidados . Para ser claros, esta diferencia se trata de operadores del plan de ejecución , no la sintaxis de consulta de T-SQL. Para obtener más detalles, consulte mi artículo vinculado.
Carretes de rendimiento
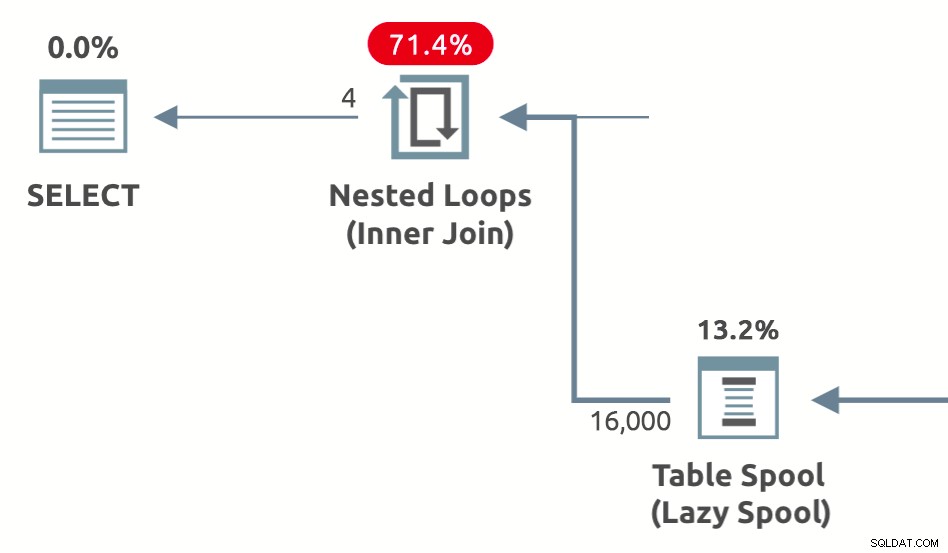
La siguiente imagen muestra el spool de rendimiento operadores del plan de ejecución como se muestra en Plan Explorer (fila superior) y SSMS 18.3 (fila inferior):
Comentarios generales
Todos los spools de rendimiento son perezosos . La mesa de trabajo de la bobina se llena gradualmente, una fila a la vez, a medida que las filas fluyen a través de la bobina. (Los carretes entusiastas, por el contrario, consumen todas las entradas de su operador secundario antes de devolver las filas a su principal).
Los carretes de rendimiento siempre aparecen en el lado interior (la entrada inferior en los planes de ejecución gráfica) de un operador de unión o aplicación de bucles anidados. La idea general es almacenar en caché y reproducir los resultados, guardando las ejecuciones repetidas de los operadores internos siempre que sea posible.
Cuando un spool puede reproducir los resultados almacenados en caché, esto se conoce como rebobinado. . Cuando el spool tiene que ejecutar sus operadores secundarios para obtener los datos correctos, un reenlace ocurre.
Puede que le resulte útil pensar en un spool rebind como un error de caché y un rebobinado como un golpe de caché.
Carrete de mesa perezoso
Este tipo de cola de rendimiento se puede usar tanto con apply y unión de bucles anidados .
Aplicar
Un reenlace (pérdida de caché) se produce cada vez que una referencia externa cambios de valor. Un carrete de mesa perezoso se vuelve a enlazar truncando su mesa de trabajo y repoblarla completamente de sus operadores secundarios.
Un rebobinado (golpe de caché) ocurre cuando el lado interno se ejecuta con el mismo valores de referencia externos como los inmediatamente anteriores iteración de bucle. Un rebobinado reproduce los resultados almacenados en caché de la mesa de trabajo del spool, lo que ahorra el costo de volver a ejecutar los operadores del plan debajo del spool.
Nota:un spool de tabla perezoso solo almacena en caché los resultados de un conjunto de aplicar referencia externa valores a la vez.
Unión de bucles anidados
El spool de la tabla diferida se llena una vez durante la primera iteración del ciclo. El carrete rebobina su contenido para cada iteración posterior de la unión. Con la combinación de bucles anidados, el lado interno de la combinación es un conjunto estático de filas porque el predicado de combinación está en la combinación misma. Por lo tanto, el conjunto de filas del lado interno estático se puede almacenar en caché y reutilizar varias veces a través del spool. Un spool de rendimiento de unión de bucles anidados nunca se vuelve a enlazar.
Lazy Row Count Spool
Un carrete de conteo de filas es poco más que un Carrete de mesa sin columnas. Almacena en caché la existencia de una fila, pero no proyecta datos de columna. Aparte de señalar su existencia y mencionar que puede ser una indicación de un error en la consulta de origen, no tendré más que decir sobre los carretes de conteo de filas.
De ahora en adelante, cada vez que vea "carrete de tabla" en el texto, léalo como "carrete de tabla (o recuento de filas)" porque son muy similares.
Carrete de índice perezoso
El carrete de índice perezoso el operador solo está disponible con apply .
El spool de índice mantiene una mesa de trabajo que no está truncada cuando referencia externa los valores cambian. En su lugar, se agregan nuevos datos a la memoria caché existente, indexados por los valores de referencia externos. Un spool de índice perezoso se diferencia de un spool de tabla perezoso en que puede reproducir resultados de cualquier iteración de bucle anterior, no solo la más reciente.
El siguiente paso para comprender cuándo aparecen los spools de rendimiento en los planes de ejecución requiere comprender un poco cómo funciona el optimizador.
Fondo del Optimizador
Una consulta de origen se convierte en una representación de árbol lógico mediante el análisis, la algebrización, la simplificación y la normalización. Cuando el árbol resultante no califica para un plan trivial, el optimizador basado en costos busca alternativas lógicas que garanticen que producirán los mismos resultados, pero a un costo estimado más bajo.
Una vez que el optimizador ha generado alternativas potenciales, implementa cada una utilizando operadores físicos apropiados y calcula los costos estimados. El plan de ejecución final se construye a partir de la opción de menor costo encontrada para cada grupo de operadores. Puede leer más detalles sobre el proceso en mi serie de análisis profundo del optimizador de consultas.
Las condiciones generales necesarias para que aparezca un spool de rendimiento en el plan final del optimizador son:
- El optimizador debe explorar una alternativa lógica que incluye un spool lógico en un sustituto generado. Esto es más complejo de lo que parece, así que desglosaré los detalles en la siguiente sección principal.
- El spool lógico debe ser implementable como un carrete físico operador en el motor de ejecución. Para las versiones modernas de SQL Server, esto significa esencialmente que todas las columnas clave en un spool de índice deben ser de un comparable tipo, no más de 900 bytes* en total, con 64 columnas clave o menos.
- El mejor El plan completo después de la optimización basada en costos debe incluir una de las alternativas de spool. En otras palabras, cualquier elección basada en costos hecha entre las opciones de carrete y no carrete debe resultar a favor del carrete.
* Este valor está codificado de forma rígida en SQL Server y no se ha cambiado tras el aumento a 1700 bytes para no agrupados claves de índice desde SQL Server 2016 en adelante. Esto se debe a que el índice de la cola es un agrupado índice, no un índice no agrupado.
Reglas del optimizador
No podemos especificar un spool usando T-SQL, por lo que obtener uno en un plan de ejecución significa que el optimizador tiene que elegir agregarlo. Como primer paso, esto significa que el optimizador debe incluir un spool lógico en una de las alternativas que elija explorar.
El optimizador no aplica de forma exhaustiva todas las reglas de equivalencia lógica que conoce a cada árbol de consulta. Esto sería un desperdicio, dado el objetivo del optimizador de producir un plan razonable rápidamente. Hay múltiples aspectos en esto. En primer lugar, el optimizador procede por etapas, probando primero las reglas más baratas y aplicables con mayor frecuencia. Si se encuentra un plan razonable en una etapa temprana, o si la consulta no califica para etapas posteriores, el esfuerzo de optimización puede terminar antes con el plan de costo más bajo encontrado hasta el momento. Esta estrategia ayuda a evitar dedicar más tiempo a la optimización del que se ahorra con las mejoras de costos incrementales.
Coincidencia de reglas
Cada operador lógico en el árbol de consulta se verifica rápidamente en busca de una coincidencia de patrón con las reglas disponibles en la etapa de optimización actual. Por ejemplo, cada regla solo coincidirá con un subconjunto de operadores lógicos y también puede requerir que existan propiedades específicas, como una entrada ordenada garantizada. Una regla puede coincidir con una operación lógica individual (un solo grupo) o varios grupos contiguos (una subsección del plan).
Una vez emparejada, se le pide a una regla candidata que genere un valor de promesa . Este es un número que representa la probabilidad de que la regla actual produzca un resultado útil, dado el contexto local. Por ejemplo, una regla puede generar un valor prometido más alto cuando el destino tiene muchos duplicados en su entrada, una gran cantidad estimada de filas, entrada ordenada garantizada o alguna otra propiedad deseable.
Una vez que se han identificado las reglas de exploración prometedoras, el optimizador las clasifica en el orden de valor prometido y comienza a pedirles que generen nuevos sustitutos lógicos. Cada regla puede generar uno o más sustitutos que luego se implementarán mediante operadores físicos. Como parte de ese proceso, se calcula un costo estimado.
El punto de todo esto, tal como se aplica a los spools de rendimiento, es que la forma y las propiedades del plan lógico deben ser propicias para hacer coincidir las reglas con capacidad de spool, y el contexto local debe producir un valor de promesa lo suficientemente alto como para que el optimizador elija generar sustitutos utilizando la regla. .
Reglas de cola
Hay una serie de reglas que exploran la unión de bucles anidados lógicos o aplicar alternativas. Algunas de estas reglas pueden producir uno o más sustitutos con un tipo particular de carrete de rendimiento. Otras reglas que coinciden con los bucles anidados se unen o se aplican nunca generan una alternativa de spool.
Por ejemplo, la regla ApplyToNL implementa una aplicación lógica como bucles físicos se unen con referencias externas. Esta regla puede generar varias alternativas cada vez que se ejecuta. Además del operador de unión física, cada sustituto puede contener un carrete de tabla diferido, un carrete de índice diferido o ningún carrete en absoluto. Los sustitutos de spool lógicos se implementan posteriormente de forma individual y se cotizan como spools físicos tipificados de forma adecuada, mediante otra regla llamada BuildSpool. .
Como segundo ejemplo, la regla JNtoIdxLookup implementa una unión lógica como una aplicación física , con un índice buscar inmediatamente en el lado interior. Esta regla nunca genera una alternativa con un componente de carrete. JNtoIdxLookup se evalúa temprano y devuelve un valor de promesa alto cuando coincide, por lo que los planes simples de búsqueda de índice se encuentran rápidamente.
Cuando el optimizador encuentra una alternativa de bajo costo como esta desde el principio, las alternativas más complejas pueden eliminarse agresivamente o omitirse por completo. El razonamiento es que no tiene sentido buscar opciones que probablemente no mejoren una alternativa de bajo costo ya encontrada. Del mismo modo, no vale la pena seguir explorando si el mejor plan completo actual ya tiene un costo total lo suficientemente bajo.
Un tercer ejemplo de regla:la regla JNtoNL es similar a ApplyToNL , pero solo implementa una unión de bucle anidado física , con un carrete de mesa perezoso o sin carrete. Esta regla nunca genera un spool de índice porque ese tipo de spool requiere una aplicación.
Generación y costeo de spool
Una regla que es capaz de generar un spool lógico no lo hará necesariamente cada vez que se invoque. Sería un desperdicio generar alternativas lógicas que casi no tienen posibilidades de ser elegidas como las más baratas. También hay un costo para generar nuevas alternativas, que a su vez pueden producir aún más alternativas, cada una de las cuales puede necesitar implementación y costos.
Para gestionar esto, el optimizador implementa una lógica común para todas las reglas con capacidad de spool para determinar qué tipo(s) de spool alternativo generar en función de las condiciones del plan local.
Unión de bucles anidados
Para una unión de bucles anidados , la posibilidad de obtener un bobina de mesa perezosa aumenta de acuerdo con:
- El número estimado de filas en la entrada externa de la unión.
- El coste estimado de operadores de plan del lado interior.
El coste de la bobina se amortiza con los ahorros realizados al evitar las ejecuciones del operador del lado interior. Los ahorros aumentan con más iteraciones internas y un mayor costo del lado interno. Esto es especialmente cierto porque el modelo de costo asigna números de costo de CPU y E/S relativamente bajos a los rebobinados de cola de tabla (aciertos de caché). Recuerde que una cola de tabla en una unión de bucles anidados solo experimenta rebobinados, porque la falta de parámetros significa que el conjunto de datos del lado interno es estático.
Un spool puede almacenar datos más densamente que los operadores que lo alimentan. Por ejemplo, un índice agrupado de tabla base podría almacenar 100 filas por página en promedio. Digamos que una consulta necesita solo un valor de columna entero único de cada fila de índice agrupado ancho. Almacenar solo el valor entero en la tabla de trabajo de la cola significa que se pueden almacenar más de 800 filas por página. Esto es importante porque el optimizador evalúa el costo de la cola de la tabla en parte utilizando una estimación del número de páginas de la mesa de trabajo. necesario. Otros factores de costos incluyen el costo de CPU por fila involucrado en escribir y leer el spool, sobre el número estimado de iteraciones de bucle.
Podría decirse que el optimizador está demasiado interesado en agregar carretes de mesa perezosos al lado interno de una unión de bucles anidados. Sin embargo, la decisión del optimizador siempre tiene sentido en términos de costo estimado. Personalmente, considero que la unión de bucles anidados es de alto riesgo , porque pueden volverse lentos rápidamente si la estimación de la cardinalidad de entrada de la unión es demasiado baja.
Un carrete de mesa puede ayudar a reducir el costo, pero no puede ocultar por completo el peor rendimiento de una combinación de bucles anidados ingenuos. Una combinación de aplicación indexada es normalmente preferible y más resistente a los errores de estimación. También es una buena idea escribir consultas que el optimizador pueda implementar con hash o merge join cuando corresponda.
Aplicar carrete de mesa perezoso
Para una solicitud , las posibilidades de obtener un bobina de mesa perezosa aumentar con el número estimado de duplicados unir valores clave en la entrada externa de la aplicación. Con más duplicados, hay un estadísticamente mayor probabilidad de que el carrete rebobine sus resultados actualmente almacenados en cada iteración. Un carrete de mesa perezoso de aplicación con un costo estimado más bajo tiene más posibilidades de aparecer en el plan de ejecución final.
Cuando las filas que llegan a la entrada externa de aplicación no tienen un orden particular, el optimizador realiza una evaluación estadística de la probabilidad de que cada iteración resulte en un rebobinado económico o un reenlace costoso. Esta evaluación utiliza datos de los pasos del histograma cuando están disponibles, pero incluso en el mejor de los casos es más una conjetura informada. Sin una garantía, el orden de las filas que llegan a la entrada externa de aplicación es impredecible.
Las mismas reglas del optimizador que generan alternativas de colas lógicas pueden también especificar que el operador de aplicación requiere filas ordenadas en su entrada exterior. Esto maximiza los rebobinados de bobina perezosa porque se garantiza que todos los duplicados se encontrarán en un bloque. Cuando se garantiza el orden de clasificación de la entrada externa, ya sea mediante un orden preservado o un Sort explícito , el costo del carrete se reduce mucho. El optimizador tiene en cuenta el impacto del orden de clasificación en la cantidad de rebobinados y reenlaces de bobinas.
Planes con un Ordenar en la entrada externa de aplicación y un Lazy Table Spool en la entrada interna son bastante comunes. La optimización de la clasificación del lado externo aún puede terminar siendo contraproducente. Por ejemplo, esto puede suceder cuando la estimación de la cardinalidad del lado externo es tan baja que la clasificación termina derramándose a tempdb .
Aplicar carrete de índice perezoso
Para una solicitud , obteniendo un spool de índice perezoso alternativa depende de la forma del plan, así como el costo.
El optimizador requiere:
- Algunos duplicados unir valores en la entrada externa.
- Una igualdad unir predicado (o un equivalente lógico que el optimizador entienda, como
x <= y AND x >= y). - Una garantía que las referencias externas son únicas debajo del carrete de índice perezoso propuesto.
En los planes de ejecución, la unicidad requerida a menudo se proporciona mediante una agrupación agregada por las referencias externas, o un agregado escalar (uno sin agrupar por). La unicidad también se puede proporcionar de otras formas, por ejemplo, mediante la existencia de un índice o restricción únicos.
A continuación se muestra un ejemplo de juguete que muestra la forma del plano:
CREATE TABLE #T1
(
c1 integer NOT NULL
);
GO
INSERT #T1 (c1)
VALUES
-- Duplicate outer rows
(1), (2), (3), (4), (5), (6),
(1), (2), (3), (4), (5), (6),
(1), (2), (3), (4), (5), (6);
GO
SELECT *
FROM #T1 AS T1
CROSS APPLY
(
SELECT COUNT_BIG(*)
FROM (SELECT T1.c1 UNION SELECT NULL) AS U
) AS CA (c);
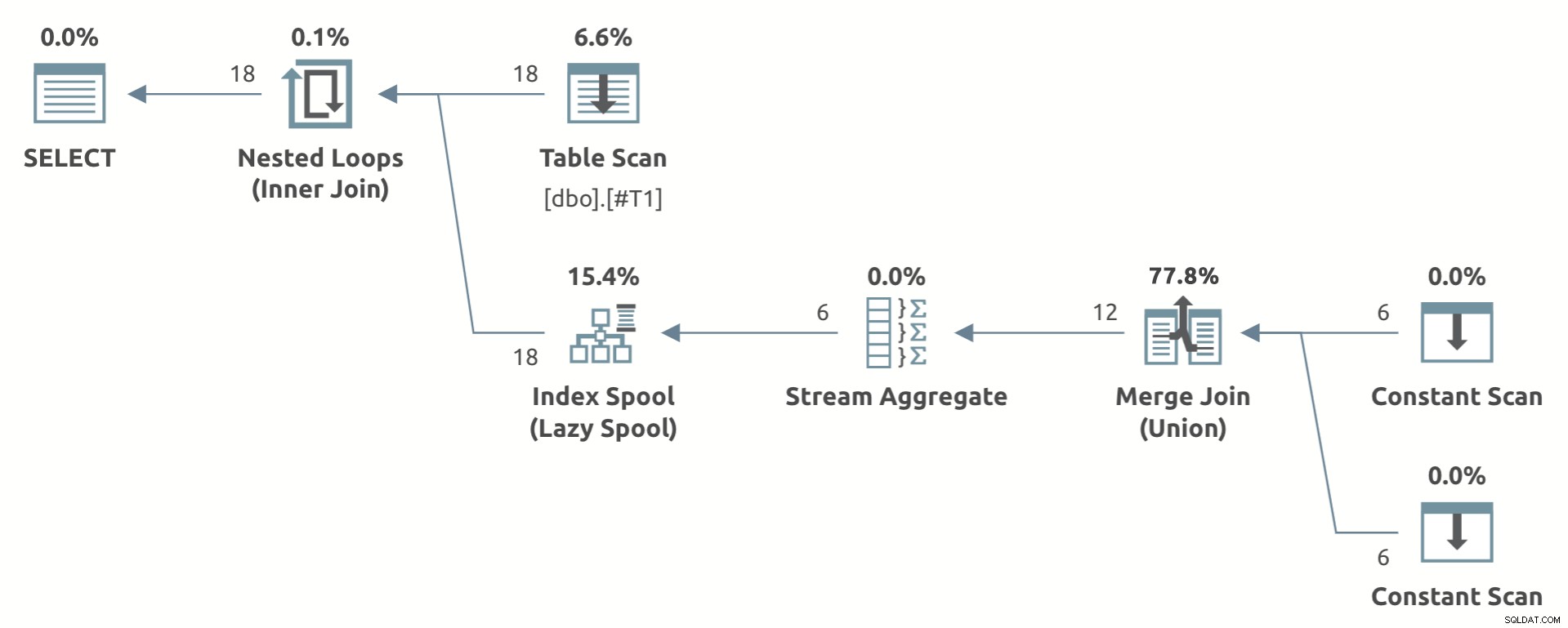
Observe el Agregado de flujo debajo del Lazy Index Spool .
Si se cumplen los requisitos de la forma del plan, el optimizador a menudo generará una alternativa de índice perezoso (sujeto a las advertencias mencionadas anteriormente). Si el plan final incluye o no un carrete de índice perezoso depende del costo.
Index Spool versus Table Spool
El número de rebobinados estimados y reenlaza para un spool de índice perezoso es lo mismo lo mismo como para un carrete de mesa perezoso sin ordenado aplicar entrada externa.
Esto puede parecer un estado de cosas bastante desafortunado. La principal ventaja de un spool de índice es que almacena en caché todos los resultados vistos anteriormente. Esto debería hacer que el carrete de índice rebobine más probable que para un carrete de mesa (sin clasificación de entrada externa) en las mismas circunstancias. Tengo entendido que esta peculiaridad existe porque sin ella, el optimizador elegiría un spool de índice con demasiada frecuencia.
Independientemente, el modelo de costos se ajusta a lo anterior hasta cierto punto mediante el uso de números de costo de CPU y E/S iniciales y de filas posteriores diferentes para los spools de tablas e índices. El efecto neto es que un carrete de índice generalmente tiene un costo más bajo que un carrete de mesa sin una entrada externa ordenada, pero recuerde los requisitos restrictivos de la forma del plan, que hacen que los carretes de índice perezosos relativamente raro.
Aún así, el principal competidor de costos de un índice de carrete perezoso es un carrete de mesa con entrada externa ordenada. La intuición para esto es bastante sencilla:la entrada externa ordenada significa que se garantiza que la cola de la tabla verá todas las referencias externas duplicadas secuencialmente. Esto significa que volverá a enlazar solo una vez por valor distinto y rebobinar para todos los duplicados. Esto es lo mismo que el comportamiento esperado de un spool de índice (al menos lógicamente hablando).
En la práctica, es más probable que se prefiera un spool de índice en lugar de un spool de tabla con clasificación optimizada para obtener menos valores de clave de aplicación duplicados. Tener menos claves duplicadas reduce el rebobinado ventaja de la cola de tabla optimizada para clasificación, en comparación con las estimaciones de cola de índice "desafortunadas" mencionadas anteriormente.
La opción de carrete de índice también se beneficia como el costo estimado de un carrete de tabla del lado externo Ordenar aumenta En la mayoría de los casos, esto estaría asociado con más filas (o más anchas) en ese punto del plan.
Rastrear indicadores y sugerencias
-
Los spools de rendimiento se pueden deshabilitar con indicador de seguimiento poco documentado 8690 , o la sugerencia de consulta documentada
NO_PERFORMANCE_SPOOLen SQL Server 2016 o posterior. -
Indicador de rastreo no documentado 8691 se puede usar (en un sistema de prueba) para añadir siempre un spool de rendimiento cuando sea posible. El tipo de spool perezoso que obtiene (recuento de filas, tabla o índice) no se puede forzar; todavía depende de la estimación de costos.
-
Indicador de rastreo no documentado 2363 se puede usar con el nuevo modelo de estimación de cardinalidad para ver la derivación de la estimación distinta en la entrada externa a una estimación de cardinalidad y aplicación en general.
-
Indicador de rastreo no documentado 9198 se puede usar para deshabilitar los spools de rendimiento del índice perezoso específicamente. En su lugar, es posible que aún obtenga una tabla perezosa o un carrete de conteo de filas (con o sin optimización de clasificación), según el costo.
-
Indicador de rastreo no documentado 2387 se puede usar para reducir el costo de la CPU de leer filas de un spool de índice perezoso . Esta bandera afecta las estimaciones generales de costos de CPU para leer un rango de filas de un árbol b. Esta bandera tiende a hacer más probable la selección de carretes indexados, por razones de costo.
Se pueden encontrar otros indicadores de rastreo y métodos para determinar qué reglas del optimizador se activaron durante la compilación de la consulta en mi serie Query Optimizer Deep Dive.
Pensamientos finales
Hay una gran cantidad de detalles internos que afectan si el plan de ejecución final usa un spool de rendimiento o no. He tratado de cubrir las consideraciones principales en este artículo, sin profundizar demasiado en los detalles extremadamente intrincados de las fórmulas de costos de los operadores de colas. Con suerte, aquí hay suficientes consejos generales para ayudarlo a determinar las posibles razones de un tipo de cola de rendimiento particular en un plan de ejecución (o falta de él).
Los carretes de rendimiento a menudo tienen mala reputación, creo que es justo decirlo. Algo de esto es sin duda merecido. Muchos de ustedes habrán visto una demostración en la que un plan se ejecuta más rápido sin un "spool de rendimiento" que con él. Hasta cierto punto, eso no es inesperado. Existen casos extremos, el modelo de costos no es perfecto y, sin duda, las demostraciones a menudo presentan planes con estimaciones de cardinalidad deficientes u otros problemas que limitan el optimizador.
Dicho esto, a veces deseo que SQL Server proporcione algún tipo de advertencia u otro comentario cuando recurra a agregar un spool de tabla perezoso a una unión de bucles anidados (o una aplicación sin un índice del lado interno de soporte utilizado). Como se mencionó en el cuerpo principal, estas son las situaciones en las que encuentro que la mayoría de las veces salen mal, cuando las estimaciones de cardinalidad resultan ser terriblemente bajas.
Tal vez algún día el optimizador de consultas tendrá en cuenta algún concepto de riesgo para planificar las opciones, o brindará capacidades más "adaptativas". Mientras tanto, vale la pena admitir sus uniones de bucles anidados con índices útiles y evitar escribir consultas que solo se pueden implementar mediante bucles anidados cuando sea posible. Por supuesto, estoy generalizando, pero el optimizador tiende a funcionar mejor cuando tiene más opciones, un esquema razonable, buenos metadatos y declaraciones T-SQL manejables para trabajar. Al igual que yo, ahora que lo pienso.
Otros artículos de spool
Los spools de no rendimiento se utilizan para muchos propósitos dentro de SQL Server, incluidos:
- Protección de Halloween
- Algunas funciones de ventana en modo fila
- Cálculo de múltiples agregados
- Optimización de sentencias que modifican datos