Mencioné brevemente que los datos del modo por lotes están normalizados en mi último artículo Mapas de bits en modo por lotes en SQL Server. Todos los datos de un lote se representan mediante un valor de ocho bytes en este formato normalizado particular, independientemente del tipo de datos subyacente.
Sin duda, esa declaración plantea algunas preguntas, sobre todo acerca de cómo es posible que los datos con una longitud mucho mayor que ocho bytes se almacenen de esa manera. Este artículo explora la representación normalizada de datos por lotes, explica por qué no todos los tipos de datos de ocho bytes pueden caber en 64 bits y muestra un ejemplo de cómo todo esto afecta el rendimiento del modo por lotes.
Demostración
Voy a comenzar con un ejemplo que muestra que el formato de datos por lotes marca una diferencia importante en un plan de ejecución. Necesitará SQL Server 2016 (o posterior) y Developer Edition (o equivalente) para reproducir los resultados que se muestran aquí.
Lo primero que necesitaremos es una tabla de bigint números del 1 al 102.400 inclusive. Estos números se usarán para llenar una tabla de almacén de columnas en breve (el número de filas es el mínimo necesario para obtener un único segmento comprimido).
DROP TABLE IF EXISTS #Numbers;
GO
CREATE TABLE #Numbers (n bigint NOT NULL PRIMARY KEY);
GO
INSERT #Numbers (n)
SELECT
n = ROW_NUMBER() OVER (ORDER BY @@SPID)
FROM master.dbo.spt_values AS SV1
CROSS JOIN master.dbo.spt_values AS SV2
ORDER BY
n
OFFSET 0 ROWS
FETCH FIRST 102400 ROWS ONLY
OPTION (MAXDOP 1); Inserción agregada exitosa
El siguiente script usa la tabla de números para crear otra tabla que contenga los mismos números compensados por un valor específico. Esta tabla usa el almacén de columnas como su almacenamiento principal para producir una ejecución en modo por lotes más adelante.
DROP TABLE IF EXISTS #T;
GO
CREATE TABLE #T (c1 bigint NOT NULL);
GO
DECLARE
@Start bigint = CONVERT(bigint, -4611686018427387905);
INSERT #T (c1)
SELECT
c1 = @Start + N.n
FROM #Numbers AS N;
GO
CREATE CLUSTERED COLUMNSTORE INDEX c ON #T
WITH (MAXDOP = 1); Ejecute las siguientes consultas de prueba en la nueva tabla de almacén de columnas:
SELECT
c = COUNT_BIG(*)
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SELECT
m = MAX(T.c1)
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SELECT
s = SUM(T.c1 + CONVERT(bigint, 4611686018427387904))
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
La adición dentro de SUM es evitar el desbordamiento. Puedes saltarte el WHERE cláusulas (para evitar un plan trivial) si está ejecutando SQL Server 2017.
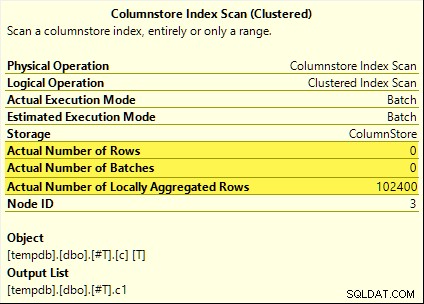
Todas esas consultas se benefician de la reducción agregada. El agregado se calcula en el Exploración del índice de almacén de columnas en lugar del hash agregado en modo por lotes operador. Los planes posteriores a la ejecución muestran cero filas emitidas por el escaneo. Las 102 400 filas se 'agregaron localmente'.
El SUM El plan se muestra a continuación como ejemplo:

Inserción agregada fallida
Ahora suelte y vuelva a crear la tabla de prueba del almacén de columnas con el desplazamiento disminuido en uno:
DROP TABLE IF EXISTS #T;
GO
CREATE TABLE #T (c1 bigint NOT NULL);
GO
DECLARE
-- Note this value has decreased by one
@Start bigint = CONVERT(bigint, -4611686018427387906);
INSERT #T (c1)
SELECT
c1 = @Start + N.n
FROM #Numbers AS N;
GO
CREATE CLUSTERED COLUMNSTORE INDEX c ON #T
WITH (MAXDOP = 1); Ejecute exactamente las mismas consultas de prueba pushdown agregadas que antes:
SELECT
c = COUNT_BIG(*)
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SELECT
m = MAX(T.c1)
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SELECT
s = SUM(T.c1 + CONVERT(bigint, 4611686018427387904))
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
Esta vez, solo el COUNT_BIG el agregado logra la inserción agregada (solo SQL Server 2017). El MAX y SUM los agregados no. Aquí está el nuevo SUM plan de comparación con el de la primera prueba:

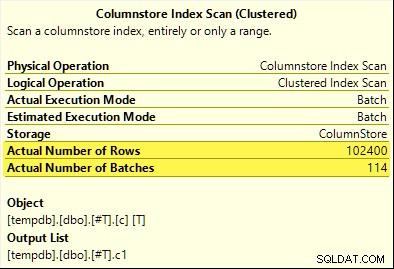
Las 102 400 filas (en 114 lotes) son emitidas por el Escaneo de índice de almacén de columnas , procesado por Compute Scalar y enviado al Agregado de Hash .
¿Por qué la diferencia? ¡Todo lo que hicimos fue compensar el rango de números almacenados en la tabla de almacén de columnas en uno!
Explicación
Mencioné en la introducción que no todos los tipos de datos de ocho bytes caben en 64 bits. Este hecho es importante porque muchas optimizaciones de rendimiento del modo por lotes y del almacén de columnas solo funcionan con datos de 64 bits de tamaño. La reducción agregada es una de esas cosas. Hay muchas más funciones de rendimiento (no todas documentadas) que funcionan mejor (o funcionan) solo cuando los datos caben en 64 bits.
En nuestro ejemplo específico, el pushdown agregado está deshabilitado para un segmento de almacén de columnas cuando contiene incluso uno valor de datos que no cabe en 64 bits. SQL Server puede determinar esto a partir de los metadatos de valor mínimo y máximo asociados con cada segmento sin verificar todos los datos. Cada segmento se evalúa por separado.
El pushdown agregado aún funciona para el COUNT_BIG agregado sólo en la segunda prueba. Esta es una optimización agregada en algún momento en SQL Server 2017 (mis pruebas se ejecutaron en CU16). Es lógico no deshabilitar la inserción agregada cuando solo contamos filas y no hacemos nada con los valores de datos específicos. No pude encontrar ninguna documentación para esta mejora, pero eso no es tan inusual en estos días.
Como nota al margen, noté que SQL Server 2017 CU16 habilita la inserción agregada para los tipos de datos real que anteriormente no eran compatibles , float , datetimeoffset y numeric con una precisión superior a 18, cuando los datos caben en 64 bits. Esto tampoco está documentado en el momento de escribir este artículo.
Bien, pero ¿por qué?
Es posible que se esté haciendo una pregunta muy razonable:¿Por qué un conjunto de bigint los valores de prueba aparentemente caben en 64 bits pero el otro no?
Si adivinó que el motivo estaba relacionado con NULL , date un tic. Aunque la columna de la tabla de prueba se define como NOT NULL , SQL Server usa el mismo diseño de datos normalizados para bigint si los datos permiten nulos o no. Hay razones para esto, que desglosaré poco a poco.
Permítanme comenzar con algunas observaciones:
- Cada valor de columna en un lote se almacena exactamente en ocho bytes (64 bits), independientemente del tipo de datos subyacente. Este diseño de tamaño fijo hace que todo sea más fácil y rápido. La ejecución en modo por lotes tiene que ver con la velocidad.
- Un lote tiene un tamaño de 64 KB y contiene entre 64 y 900 filas, según la cantidad de columnas que se proyectan. Esto tiene sentido dado que los tamaños de datos de las columnas se fijan en 64 bits. Más columnas significa que caben menos filas en cada lote de 64 KB.
- No todos los tipos de datos de SQL Server caben en 64 bits, incluso en principio. Una cadena larga (para tomar un ejemplo) podría no caber en un lote completo de 64 KB (si eso estuviera permitido), y mucho menos en una sola entrada de 64 bits.
SQL Server resuelve este último problema almacenando una referencia de 8 bytes a datos de más de 64 bits. El valor de datos "grande" se almacena en otra parte de la memoria. Puede llamar a este arreglo almacenamiento "fuera de fila" o "fuera de lote". Internamente se conoce como datos profundos .
Ahora, los tipos de datos de ocho bytes no pueden caber en 64 bits cuando se pueden anular. Tome bigint NULL por ejemplo . El rango de datos no nulos puede requerir los 64 bits completos, y todavía necesitamos otro bit para indicar nulo o no.
Resolviendo los problemas
La solución creativa y eficiente a estos desafíos es reservar el bit significativo más bajo (LSB) del valor de 64 bits como bandera. La bandera indica en lote almacenamiento de datos cuando el LSB está claro (puesto a cero). Cuando el LSB está establecido (a uno), puede significar una de dos cosas:
- El valor es nulo; o
- El valor se almacena fuera del lote (son datos profundos).
Estos dos casos se distinguen por el estado de los 63 bits restantes. Cuando son todo cero , el valor es NULL . De lo contrario, el "valor" es un indicador de datos profundos almacenados en otro lugar.
Cuando se ve como un número entero, establecer el LSB significa que los punteros a datos profundos siempre serán impares números. Los valores nulos están representados por el número (impar) 1 (todos los demás bits son cero). Los datos en lote están representados por incluso números porque el LSB es cero.
Esto no significa que SQL Server solo puede almacenar números pares dentro de un lote. Simplemente significa que la representación normalizada de los valores de la columna subyacente siempre tendrán un LSB cero cuando se almacenen "en lote". Esto tendrá más sentido en un momento.
Normalización de datos por lotes
La normalización se realiza de diferentes maneras, según el tipo de datos subyacente. Para bigint el proceso es:
- Si los datos son nulos , almacene el valor 1 (solo LSB establecido).
- Si el valor se puede representar en 63 bits , mueva todos los bits un lugar a la izquierda y ponga a cero el LSB. Al mirar el valor como un número entero, esto significa doblar el valor. Por ejemplo, el
bigintel valor 1 se normaliza al valor 2. En binario, son siete bytes todos cero seguidos de00000010. El LSB siendo cero indica que estos son datos almacenados en línea. Cuando SQL Server necesita el valor original, desplaza a la derecha el valor de 64 bits una posición (eliminando el indicador LSB). - Si el valor no puede representarse en 63 bits, el valor se almacena fuera del lote como datos profundos . El puntero en lote tiene el LSB establecido (lo que lo convierte en un número impar).
El proceso de probar si un bigint el valor que puede caber en 63 bits es:
- Almacenar el crudo*
bigintvalor en el registro del procesador de 64 bitsr8. - Almacenar el doble del valor de
r8en el registrorax. - Cambia los bits de
raxun lugar a la derecha. - Prueba si los valores en
raxyr8son iguales.
* Tenga en cuenta que el valor bruto no se puede determinar de forma fiable para todos los tipos de datos mediante una conversión de T-SQL a un tipo binario. El resultado de T-SQL puede tener un orden de bytes diferente y también puede contener metadatos, p. time precisión de fracciones de segundo.
Si pasa la prueba en el paso 4, sabemos que el valor se puede duplicar y luego reducir a la mitad dentro de los 64 bits, conservando el valor original.
Un rango reducido
El resultado de todo esto es que el rango de bigint los valores que se pueden almacenar en lote se reduce por un bit (porque el LSB no está disponible). Los siguientes rangos inclusivos de bigint los valores se almacenarán fuera del lote como datos profundos :
- -4,611,686,018,427,387,905 a -9,223,372,036,854,775,808
- +4,611,686,018,427,387,904 a +9,223,372,036,854,775,807
A cambio de aceptar que estos bigint limitaciones de rango, la normalización permite que SQL Server almacene (la mayoría) bigint valores, nulos y referencias de datos profundos en lote . Esto es mucho más simple y ahorra más espacio que tener estructuras separadas para referencias de datos profundos y anulabilidad. También facilita mucho el procesamiento de datos por lotes con las instrucciones del procesador SIMD.
Normalización de otros tipos de datos
SQL Server contiene normalización código para cada uno de los tipos de datos compatibles con la ejecución en modo por lotes. Cada rutina está optimizada para manejar el diseño binario entrante de manera eficiente y solo para crear datos profundos cuando sea necesario. La normalización siempre da como resultado que el LSB se reserve para indicar datos nulos o profundos, pero el diseño de los 63 bits restantes varía según el tipo de datos.
Siempre en lote
Los datos normalizados para los siguientes tipos de datos siempre se almacenan en lote ya que nunca necesitan más de 63 bits:
datetime(n)– reescalado internamente atime(7)datetime2(n)– reescalado internamente adatetime2(7)integersmallinttinyintbit– usa eltinyintimplementación.smalldatetimedatetimerealfloatsmallmoney
Depende
Los siguientes tipos de datos se pueden almacenar en lote o datos profundos dependiendo del valor de los datos:
bigint– como se describió anteriormente.money– mismo rango en lote quebigintpero dividido por 10.000.numeric/decimal– 18 dígitos decimales o menos en el lote independientemente de precisión declarada. Por ejemplo eldecimal(38,9)valor -999999999.999999999 se puede representar como el entero de 8 bytes -999999999999999999 (f21f494c589c0001hexadecimal), que se puede duplicar a -1999999999999999998 (e43e9298b1380002hex) de forma reversible dentro de los 64 bits. SQL Server sabe dónde va el punto decimal de la escala de tipos de datos.datetimeoffset(n)– en lote si el valor de tiempo de ejecución encajará endatetimeoffset(2)independientemente de precisión de segundos fraccionarios declarados.timestamp– el formato interno es diferente al de la pantalla. Por ejemplo, unatimestampmostrado desde T-SQL como0x000000000099449Ase representa internamente como9a449900 00000000(en hexadecimal). Este valor se almacena como datos profundos porque no cabe en 64 bits cuando se duplica (un bit desplazado a la izquierda).
Siempre datos profundos
Los siguientes siempre se almacenan como datos profundos (excepto nulos) :
uniqueidentifiervarbinary(n)– incluido(max)binarychar/varchar(n)/nchar/nvarchar(n)/sysnameincluyendo(max)– estos tipos también pueden usar un diccionario (cuando esté disponible).text/ntext/image/xml– usa elvarbinary(n)implementación.
Para ser claros, nulos para todos los tipos de datos compatibles con el modo por lotes se almacenan en el lote como el valor especial 'uno'.
Pensamientos finales
Es posible que espere aprovechar al máximo las optimizaciones disponibles del modo por lotes y del almacén de columnas cuando utilice tipos de datos y valores que se ajusten a 64 bits. También tendrá la mejor oportunidad de beneficiarse de las mejoras incrementales del producto a lo largo del tiempo, por ejemplo, las últimas mejoras en la reducción agregada que se indican en el texto principal. No todas las ventajas de rendimiento serán tan visibles en los planes de ejecución, o incluso documentadas. Sin embargo, las diferencias pueden ser extremadamente significativas.
También debo mencionar que los datos se normalizan cuando un operador del plan de ejecución en modo de fila proporciona datos a un padre en modo de lote, o cuando un escaneo que no es de almacén de columnas produce lotes (modo de lote en el almacén de filas). Hay un adaptador invisible de fila a lote que llama a la rutina de normalización adecuada en cada valor de columna antes de agregarlo al lote. Evitar los tipos de datos con una normalización complicada y un almacenamiento profundo de datos también puede producir beneficios de rendimiento aquí.