Un índice de soporte puede potencialmente ayudar a evitar la necesidad de una ordenación explícita en el plan de consulta cuando se optimizan las consultas T-SQL que involucran funciones de ventana. Por un índice de apoyo, Me refiero a uno con los elementos de partición y ordenación de ventanas como clave de índice, y el resto de las columnas que aparecen en la consulta como columnas incluidas en el índice. A menudo me refiero a este patrón de indexación como un POC index como acrónimo de partitioning , pedir, y cubrir . Naturalmente, si un elemento de partición o de orden no aparece en la función de ventana, omite esa parte de la definición del índice.
Pero, ¿qué pasa con las consultas que involucran múltiples funciones de ventana con diferentes necesidades de pedido? De manera similar, ¿qué pasa si otros elementos en la consulta además de las funciones de ventana también requieren organizar los datos de entrada según lo ordenado en el plan, como una cláusula ORDER BY de presentación? Esto puede resultar en que diferentes partes del plan necesiten procesar los datos de entrada en diferentes órdenes.
En tales circunstancias, normalmente aceptará que la clasificación explícita es inevitable en el plan. Es posible que la disposición sintáctica de las expresiones en la consulta afecte a cuántos operadores de clasificación explícitos que obtiene en el plan. Si sigue algunos consejos básicos, a veces puede reducir la cantidad de operadores de clasificación explícitos, lo que, por supuesto, puede tener un gran impacto en el rendimiento de la consulta.
Entorno para demostraciones
En mis ejemplos, usaré la base de datos de muestra PerformanceV5. Puede descargar el código fuente para crear y completar esta base de datos aquí.
Ejecuté todos los ejemplos en SQL Server 2019 Developer, donde está disponible el modo por lotes en el almacén de filas.
En este artículo, quiero centrarme en los consejos que tienen que ver con el potencial del cálculo de la función de ventana en el plan para confiar en los datos de entrada ordenados sin requerir una actividad de ordenación explícita adicional en el plan. Esto es relevante cuando el optimizador usa un tratamiento de modo de fila en serie o paralelo de las funciones de ventana, y cuando usa un operador agregado de ventana en modo de lote en serie.
Actualmente, SQL Server no admite una combinación eficiente de una entrada de conservación de orden paralela antes de un operador agregado de ventana en modo de lote paralelo. Por lo tanto, para usar un operador agregado de ventana en modo por lotes paralelo, el optimizador tiene que inyectar un operador de clasificación en modo por lotes paralelo intermediario, incluso cuando la entrada ya está preordenada.
En aras de la simplicidad, puede evitar el paralelismo en todos los ejemplos que se muestran en este artículo. Para lograr esto sin necesidad de agregar una sugerencia a todas las consultas y sin establecer una opción de configuración para todo el servidor, puede establecer la opción de configuración de ámbito de base de datos MAXDOP a 1 , así:
USE PerformanceV5; ALTER DATABASE SCOPED CONFIGURATION SET MAXDOP = 1;
Recuerde volver a establecerlo en 0 después de que haya terminado de probar los ejemplos de este artículo. Te lo recordaré al final.
Alternativamente, puede evitar el paralelismo a nivel de sesión con el DBCC OPTIMIZER_WHATIF no documentado comando, así:
DBCC OPTIMIZER_WHATIF(CPUs, 1);
Para restablecer la opción cuando haya terminado, invóquela nuevamente con el valor 0 como el número de CPU.
Cuando haya terminado de probar todos los ejemplos de este artículo con el paralelismo deshabilitado, le recomiendo habilitar el paralelismo y volver a probar todos los ejemplos para ver qué cambios.
Consejos 1 y 2
Antes de comenzar con los consejos, primero veamos un ejemplo simple con una función de ventana diseñada para beneficiarse de un índice de clasificación supp class="border indent shadow.
Considere la siguiente consulta, a la que me referiré como Consulta 1:
SELECT orderid, orderdate, custid, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1 FROM dbo.Orders;
No se preocupe por el hecho de que el ejemplo es artificial. No hay una buena razón comercial para calcular un total acumulado de ID de pedido:esta tabla tiene un tamaño decente con filas de 1 MM y quería mostrar un ejemplo simple con una función de ventana común, como la que aplica un cálculo total acumulado.
Siguiendo el esquema de indexación de POC, crea el siguiente índice para admitir la consulta:
CREATE UNIQUE NONCLUSTERED INDEX idx_nc_cid_od_oid ON dbo.Orders(custid, orderdate, orderid);
El plan para esta consulta se muestra en la Figura 1.
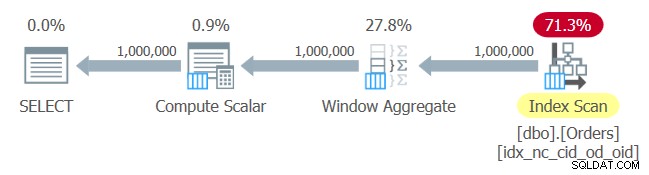 Figura 1:Plan para Consulta 1
Figura 1:Plan para Consulta 1
No hay sorpresas aquí. El plan aplica un escaneo de orden de índice del índice que acaba de crear, proporcionando los datos ordenados al operador de ventana agregada, sin necesidad de una clasificación explícita.
A continuación, considere la siguiente consulta, que implica varias funciones de ventana con diferentes necesidades de ordenación, así como una cláusula ORDER BY de presentación:
SELECT orderid, orderdate, custid, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1, SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3 FROM dbo.Orders ORDER BY custid, orderid;
Me referiré a esta consulta como Consulta 2. El plan para esta consulta se muestra en la Figura 2.
 Figura 2:Plan para Consulta 2
Figura 2:Plan para Consulta 2
Observe que hay cuatro operadores Ordenar en el plan.
Si analiza las diversas funciones de ventana y las necesidades de ordenación de presentaciones, encontrará que hay tres necesidades distintas de ordenación:
- ID del cliente, fecha del pedido, ID del pedido
- ID de pedido
- custid, orderid
Dado que uno de ellos (el primero en la lista anterior) puede ser compatible con el índice que creó anteriormente, esperaría ver solo dos tipos en el plan. Entonces, ¿por qué el plan tiene cuatro tipos? Parece que SQL Server no intenta ser demasiado sofisticado al reorganizar el orden de procesamiento de las funciones en el plan para minimizar las clasificaciones. Procesa las funciones del plan en el orden en que aparecen en la consulta. Ese es al menos el caso de la primera aparición de cada necesidad de pedido distinta, pero explicaré esto en breve.
Puede eliminar la necesidad de algunos de los tipos en el plan aplicando las siguientes dos prácticas simples:
Sugerencia 1:si tiene un índice que admita algunas de las funciones de la ventana en la consulta, especifíquelas primero.
Consejo 2:si la consulta involucra funciones de ventana con la misma necesidad de ordenación que la ordenación de presentación en la consulta, especifique esas funciones al final.
Siguiendo estos consejos, puede reorganizar el orden de aparición de las funciones de la ventana en la consulta de la siguiente manera:
SELECT orderid, orderdate, custid, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1, SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2 FROM dbo.Orders ORDER BY custid, orderid;
Me referiré a esta consulta como Consulta 3. El plan para esta consulta se muestra en la Figura 3.
 Figura 3:Plan para la Consulta 3
Figura 3:Plan para la Consulta 3
Como puede ver, el plan ahora tiene solo dos tipos.
Consejo 3
SQL Server no intenta ser demasiado sofisticado al reorganizar el orden de procesamiento de las funciones de ventana en un intento de minimizar las clasificaciones en el plan. Sin embargo, es capaz de una cierta reorganización simple. Escanea las funciones de la ventana en función del orden de aparición en la consulta y cada vez que detecta una nueva necesidad de pedido distinta, busca funciones de ventana adicionales con la misma necesidad de pedido y, si las encuentra, las agrupa junto con la primera aparición. En algunos casos, incluso puede usar el mismo operador para calcular múltiples funciones de ventana.
Considere la siguiente consulta como ejemplo:
SELECT orderid, orderdate, custid, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1, SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2, MAX(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS max1, MAX(orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max3, MAX(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max2, AVG(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS avg1, AVG(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg3, AVG(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg2 FROM dbo.Orders ORDER BY custid, orderid;
Me referiré a esta consulta como Consulta 4. El plan para esta consulta se muestra en la Figura 4.
 Figura 4:Plan para Consulta 4
Figura 4:Plan para Consulta 4
Las funciones de ventana con las mismas necesidades de ordenación no se agrupan en la consulta. Sin embargo, todavía hay solo dos tipos en el plan. Esto se debe a que lo que cuenta en términos de orden de procesamiento en el plan es la primera aparición de cada necesidad de orden distinta. Esto me lleva al tercer consejo.
Consejo 3:asegúrese de seguir los consejos 1 y 2 para la primera aparición de cada necesidad de pedido distinta. Las instancias posteriores de la misma necesidad de pedido, incluso si no son adyacentes, se identifican y agrupan junto con la primera.
Consejos 4 y 5
Suponga que desea devolver las columnas resultantes de los cálculos en ventana en un cierto orden de izquierda a derecha en la salida. Pero, ¿y si el orden no es el mismo que minimizará las clasificaciones en el plan?
Por ejemplo, suponga que desea el mismo resultado que el producido por la Consulta 2 en términos de orden de columna de izquierda a derecha en la salida (orden de columna:otras columnas, sum2, sum1, sum3), pero prefiere tener el mismo plan como el que obtuvo para la Consulta 3 (orden de las columnas:otras columnas, sum1, sum3, sum2), que obtuvo dos tipos en lugar de cuatro.
Eso es perfectamente factible si está familiarizado con el cuarto consejo.
Sugerencia 4:las recomendaciones mencionadas anteriormente se aplican al orden de aparición de las funciones de ventana en el código, incluso si se encuentran dentro de una expresión de tabla con nombre, como una CTE o una vista, e incluso si la consulta externa devuelve las columnas en un orden diferente al de la expresión de tabla nombrada. Por lo tanto, si necesita devolver columnas en un cierto orden en la salida, y es diferente del orden óptimo en términos de minimizar las ordenaciones en el plan, siga los consejos en términos de orden de aparición dentro de una expresión de tabla con nombre y devuelva las columnas en la consulta externa en el orden de salida deseado.
La siguiente consulta, a la que me referiré como Consulta 5, ilustra esta técnica:
WITH C AS
(
SELECT orderid, orderdate, custid,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1,
SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2
FROM dbo.Orders
)
SELECT orderid, orderdate, custid,
sum2, sum1, sum3
FROM C
ORDER BY custid, orderid; El plan para esta consulta se muestra en la Figura 5.
 Figura 5:Plan para Consulta 5
Figura 5:Plan para Consulta 5
Todavía obtiene solo dos tipos en el plan a pesar de que el orden de las columnas en la salida es:otras columnas, suma2, suma1, suma3, como en la Consulta 2.
Una advertencia para este truco con la expresión de tabla con nombre es que si la consulta externa no hace referencia a las columnas de la expresión de tabla, se excluyen del plan y, por lo tanto, no cuentan.
Considere la siguiente consulta, a la que me referiré como Consulta 6:
WITH C AS
(
SELECT orderid, orderdate, custid,
MAX(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS max1,
MAX(orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max3,
MAX(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max2,
AVG(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS avg1,
AVG(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg3,
AVG(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg2,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1,
SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3
FROM dbo.Orders
)
SELECT orderid, orderdate, custid,
sum2, sum1, sum3,
max2, max1, max3,
avg2, avg1, avg3
FROM C
ORDER BY custid, orderid; Aquí, la consulta externa hace referencia a todas las columnas de expresión de la tabla, por lo que la optimización se produce en función de la primera aparición distinta de cada necesidad de pedido dentro de la expresión de la tabla:
- max1:ID del cliente, fecha del pedido, ID del pedido
- max3:ID de pedido
- max2:ID del cliente, ID del pedido
Esto da como resultado un plan con solo dos tipos, como se muestra en la Figura 6.
 Figura 6:Plan para Consulta 6
Figura 6:Plan para Consulta 6
Ahora cambie solo la consulta externa eliminando las referencias a max2, max1, max3, avg2, avg1 y avg3, así:
WITH C AS
(
SELECT orderid, orderdate, custid,
MAX(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS max1,
MAX(orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max3,
MAX(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max2,
AVG(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS avg1,
AVG(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg3,
AVG(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg2,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1,
SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3
FROM dbo.Orders
)
SELECT orderid, orderdate, custid,
sum2, sum1, sum3
FROM C
ORDER BY custid, orderid; Me referiré a esta consulta como Consulta 7. Los cálculos de max1, max3, max2, avg1, avg3 y avg2 en la expresión de la tabla son irrelevantes para la consulta externa, por lo que se excluyen. Los cálculos restantes que involucran funciones de ventana en la expresión de la tabla, que son relevantes para la consulta externa, son los de suma2, suma1 y suma3. Desafortunadamente, no aparecen en la expresión de la tabla en el orden óptimo en términos de minimización de clases. Como puede ver en el plan para esta consulta, como se muestra en la Figura 7, hay cuatro tipos.
 Figura 7:Plan para Consulta 7
Figura 7:Plan para Consulta 7
Si cree que es poco probable que tenga columnas en la consulta interna a las que no hará referencia en la consulta externa, piense en vistas. Cada vez que consulta una vista, es posible que le interese un subconjunto diferente de las columnas. Con esto en mente, el quinto consejo podría ayudar a reducir las clases en el plan.
Sugerencia 5:en la consulta interna de una expresión de tabla con nombre como una CTE o una vista, agrupe todas las funciones de ventana con las mismas necesidades de orden y siga las sugerencias 1 y 2 en el orden de los grupos de funciones.
El siguiente código implementa una vista basada en esta recomendación:
CREATE OR ALTER VIEW dbo.MyView AS SELECT orderid, orderdate, custid, MAX(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS max1, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1, AVG(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS avg1, MAX(orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max3, SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3, AVG(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg3, MAX(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max2, AVG(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg2, SUM(orderid) OVER(PARTITION BY custid ORDER BY ordered ROWS UNBOUNDED PRECEDING) AS sum2 FROM dbo.Orders; GO
Ahora consulta la vista solicitando solo las columnas de resultados en ventana sum2, sum1 y sum3, en este orden:
SELECT orderid, orderdate, custid, sum2, sum1, sum3 FROM dbo.MyView ORDER BY custid, orderid;
Me referiré a esta consulta como Consulta 8. Obtiene el plan que se muestra en la Figura 8 con solo dos clases.
 Figura 8:Plan para Consulta 8
Figura 8:Plan para Consulta 8
Consejo 6
Cuando tiene una consulta con múltiples funciones de ventana con múltiples necesidades de orden distintas, la sabiduría común es que puede admitir solo una de ellas con datos preordenados a través de un índice. Este es el caso incluso cuando todas las funciones de ventana tienen índices de soporte respectivos.
Permítanme demostrar esto. Recuerde anteriormente cuando creó el índice idx_nc_cid_od_oid, que puede admitir funciones de ventana que necesitan los datos ordenados por custid, orderdate, orderid, como la siguiente expresión:
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING)
Suponga que, además de esta función de ventana, también necesita la siguiente función de ventana en la misma consulta:
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING)
Esta función de ventana se beneficiaría del siguiente índice:
CREATE UNIQUE NONCLUSTERED INDEX idx_nc_cid_oid ON dbo.Orders(custid, orderid);
La siguiente consulta, a la que me referiré como Consulta 9, invoca ambas funciones de ventana:
SELECT orderid, orderdate, custid, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2 FROM dbo.Orders;
El plan para esta consulta se muestra en la Figura 9.
 Figura 9:Plan para Consulta 9
Figura 9:Plan para Consulta 9
Obtengo las siguientes estadísticas de tiempo para esta consulta en mi máquina, con resultados descartados en SSMS:
CPU time = 3234 ms, elapsed time = 3354 ms.
Como se explicó anteriormente, SQL Server analiza las expresiones en ventana en orden de aparición en la consulta y calcula que puede admitir la primera con un análisis ordenado del índice idx_nc_cid_od_oid. Pero luego agrega un operador Ordenar al plan para ordenar los datos como lo necesita la función de la segunda ventana. Esto significa que el plan tiene una escala N log N. No considera usar el índice idx_nc_cid_oid para admitir la función de la segunda ventana. Probablemente esté pensando que no puede, pero trate de pensar un poco fuera de la caja. ¿No podría calcular cada una de las funciones de la ventana en función de su orden de índice respectivo y luego unir los resultados? Teóricamente, puede, y según el tamaño de los datos, la disponibilidad de indexación y otros recursos disponibles, la versión conjunta a veces podría funcionar mejor. SQL Server no considera este enfoque, pero ciertamente puede implementarlo escribiendo la unión usted mismo, así:
WITH C1 AS
(
SELECT orderid, orderdate, custid,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1
FROM dbo.Orders
),
C2 AS
(
SELECT orderid, custid,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2
FROM dbo.Orders
)
SELECT C1.orderid, C1.orderdate, C1.custid, C1.sum1, C2.sum2
FROM C1
INNER JOIN C2
ON C1.orderid = C2.orderid; Me referiré a esta consulta como Consulta 10. El plan para esta consulta se muestra en la Figura 10.
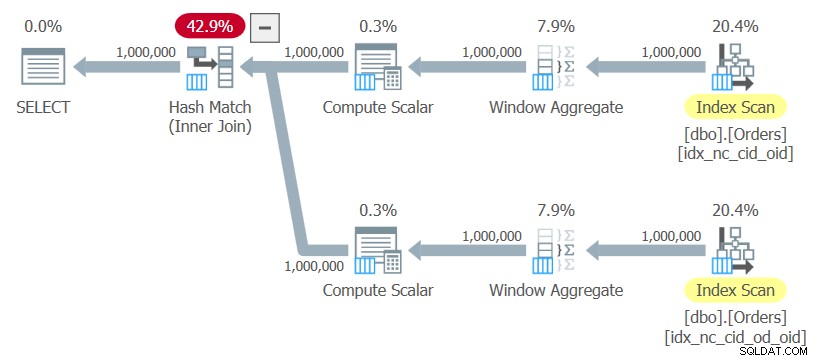 Figura 10:Plan para Consulta 10
Figura 10:Plan para Consulta 10
El plan utiliza exploraciones ordenadas de los dos índices sin clasificación explícita alguna, calcula las funciones de la ventana y utiliza una combinación hash para unir los resultados. Este plan se escala linealmente en comparación con el anterior, que tiene una escala de N log N.
Obtengo las siguientes estadísticas de tiempo para esta consulta en mi máquina (nuevamente con resultados descartados en SSMS):
CPU time = 1000 ms, elapsed time = 1100 ms.
En resumen, este es nuestro sexto consejo.
Sugerencia 6:cuando tenga varias funciones de ventana con varias necesidades de orden distintas y pueda admitirlas todas con índices, pruebe una versión de unión y compare su rendimiento con la consulta sin la unión.
Limpieza
Si deshabilitó el paralelismo estableciendo la opción de configuración de ámbito de base de datos MAXDOP en 1, vuelva a habilitar el paralelismo estableciéndolo en 0:
ALTER DATABASE SCOPED CONFIGURATION SET MAXDOP = 0;
Si usó la opción de sesión no documentada DBCC OPTIMIZER_WHATIF con la opción de CPU configurada en 1, vuelva a habilitar el paralelismo configurándolo en 0:
DBCC OPTIMIZER_WHATIF(CPUs, 0);
Si lo desea, puede volver a intentar todos los ejemplos con el paralelismo habilitado.
Use el siguiente código para limpiar los nuevos índices que creó:
DROP INDEX IF EXISTS idx_nc_cid_od_oid ON dbo.Orders; DROP INDEX IF EXISTS idx_nc_cid_oid ON dbo.Orders;
Y el siguiente código para quitar la vista:
DROP VIEW IF EXISTS dbo.MyView;
Siga los consejos para minimizar el número de clasificaciones
Las funciones de ventana necesitan procesar los datos de entrada solicitados. La indexación puede ayudar a eliminar la clasificación en el plan, pero normalmente solo para una necesidad de pedido distinta. Las consultas con múltiples necesidades de pedidos generalmente involucran algunos tipos en sus planes. Sin embargo, siguiendo ciertos consejos, puede minimizar la cantidad de clasificaciones necesarias. Aquí hay un resumen de los consejos que mencioné en este artículo:
- Consejo 1: Si tiene un índice para admitir algunas de las funciones de la ventana en la consulta, especifíquelas primero.
- Consejo 2: Si la consulta implica funciones de ventana con la misma necesidad de ordenación que la ordenación de presentación en la consulta, especifique esas funciones en último lugar.
- Consejo 3: Asegúrese de seguir los consejos 1 y 2 para la primera aparición de cada necesidad de pedido distinta. Las ocurrencias posteriores de la misma necesidad de pedido, incluso si no son adyacentes, se identifican y agrupan junto con la primera.
- Consejo 4: Las recomendaciones antes mencionadas se aplican al orden de aparición de las funciones de ventana en el código, incluso si se encuentran dentro de una expresión de tabla con nombre, como una CTE o una vista, e incluso si la consulta externa devuelve las columnas en un orden diferente al de la expresión de tabla con nombre. Por lo tanto, si necesita devolver columnas en un cierto orden en la salida, y es diferente del orden óptimo en términos de minimizar las ordenaciones en el plan, siga los consejos en términos de orden de aparición dentro de una expresión de tabla con nombre y devuelva las columnas en la consulta externa en el orden de salida deseado.
- Consejo 5: En la consulta interna de una expresión de tabla con nombre como un CTE o una vista, agrupe todas las funciones de ventana con las mismas necesidades de orden y siga los consejos 1 y 2 en el orden de los grupos de funciones.
- Consejo 6: Cuando tenga varias funciones de ventana con varias necesidades de orden distintas y pueda admitirlas todas con índices, pruebe una versión de combinación y compare su rendimiento con la consulta sin la combinación.