Introducción
Recientemente nos encontramos con un problema de rendimiento interesante en una de nuestras bases de datos de SQL Server que procesa transacciones a un ritmo considerable. La tabla de transacciones utilizada para capturar estas transacciones se convirtió en una tabla activa. Como resultado, el problema apareció en la capa de aplicación. Fue un tiempo de espera intermitente de la sesión que buscaba publicar transacciones.
Esto sucedió porque una sesión generalmente "retenía" la tabla y provocaba una serie de bloqueos falsos en la base de datos.
La primera reacción de un administrador de base de datos típico sería identificar la sesión de bloqueo principal y finalizarla de forma segura. Esto era seguro porque normalmente era una instrucción SELECT o una sesión inactiva.
También hubo otros intentos de solucionar el problema:
- Purgar la mesa. Se esperaba que esto otorgara un buen rendimiento incluso si la consulta tenía que escanear una tabla completa.
- Habilitar el nivel de aislamiento READ COMMITTED SNAPSHOT para reducir el impacto del bloqueo de sesiones.
En este artículo, intentaremos recrear una versión simplista del escenario y la usaremos para mostrar cómo la indexación simple puede abordar situaciones como esta cuando se hace correctamente.
Dos tablas relacionadas
Eche un vistazo al Listado 1 y al Listado 2. Muestran las versiones simplificadas de las tablas involucradas en el escenario bajo consideración.
-- Listing 1: Create TranLog Table
use DB2
go
create table TranLog (
TranID INT IDENTITY(1,1)
,CustomerID char(4)
,ProductCount INT
,TotalPrice Money
,TranTime Timestamp
)
-- Listing 2: Create TranDetails Table
use DB2
go
create table TranDetails (
TranDetailsID INT IDENTITY(1,1)
,TranID INT
,ProductCode uniqueidentifier
,UnitCost Money
,ProductCount INT
,TotalPrice Money
)
El Listado 3 muestra un activador que inserta cuatro filas en TranDetails tabla para cada fila insertada en el TranLog mesa.
-- Listing 3: Create Trigger
CREATE TRIGGER dbo.GenerateDetails
ON dbo.TranLog
AFTER INSERT
AS
BEGIN
-- SET NOCOUNT ON added to prevent extra result sets from
-- interfering with SELECT statements.
SET NOCOUNT ON;
insert into dbo.TranDetails (TranID, ProductCode,UnitCost, ProductCount, TotalPrice)
select top 1 dbo.TranLog.TranID, NEWID(), dbo.TranLog.TotalPrice/dbo.TranLog.ProductCount, dbo.TranLog.ProductCount, dbo.TranLog.TotalPrice
from dbo.TranLog order by TranID desc;
insert into dbo.TranDetails (TranID, ProductCode,UnitCost, ProductCount, TotalPrice)
select top 1 dbo.TranLog.TranID, NEWID(), dbo.TranLog.TotalPrice/dbo.TranLog.ProductCount, dbo.TranLog.ProductCount, dbo.TranLog.TotalPrice
from dbo.TranLog order by TranID desc;
insert into dbo.TranDetails (TranID, ProductCode,UnitCost, ProductCount, TotalPrice)
select top 1 dbo.TranLog.TranID, NEWID(), dbo.TranLog.TotalPrice/dbo.TranLog.ProductCount, dbo.TranLog.ProductCount, dbo.TranLog.TotalPrice
from dbo.TranLog order by TranID desc;
insert into dbo.TranDetails (TranID, ProductCode,UnitCost, ProductCount, TotalPrice)
select top 1 dbo.TranLog.TranID, NEWID(), dbo.TranLog.TotalPrice/dbo.TranLog.ProductCount, dbo.TranLog.ProductCount, dbo.TranLog.TotalPrice
from dbo.TranLog order by TranID desc;
END
GO
Unirse a consulta
Es típico encontrar tablas de transacciones soportadas por tablas grandes. El propósito es mantener transacciones mucho más antiguas o almacenar los detalles de los registros resumidos en la primera tabla. Piense en esto como órdenes y detalles del pedido tablas que son típicas en las bases de datos de muestra de SQL Server. En nuestro caso, estamos considerando el TranLog y TranDetails mesas.
En circunstancias normales, las transacciones completan estas dos tablas a lo largo del tiempo. En términos de informes o consultas simples, la consulta realizará una unión en estas dos tablas. Esta unión capitalizará una columna común entre las tablas.
Primero, llenamos la tabla usando la consulta en el Listado 4.
-- Listing 4: Insert Rows in TranLog
use DB2
go
insert into TranLog values ('CU01', 5, '50.45', DEFAULT);
insert into TranLog values ('CU02', 7, '42.35', DEFAULT);
insert into TranLog values ('CU03', 15, '39.55', DEFAULT);
insert into TranLog values ('CU04', 9, '33.50', DEFAULT);
insert into TranLog values ('CU05', 2, '105.45', DEFAULT);
go 1000
use DB2
go
select * from TranLog;
select * from TranDetails;
En nuestra muestra, la columna común utilizada por la combinación es TranID columna:
-- Listing 5 Join Query
-- 5a
select * from TranLog a join TranDetails b
on a.TranID=b.TranID where a.CustomerID='CU03';
-- 5b
select * from TranLog a join TranDetails b
on a.TranID=b.TranID where a.TranID=30;
Puede ver las dos consultas de muestra simples que usan una unión para recuperar registros de TranLog y TranDetails .
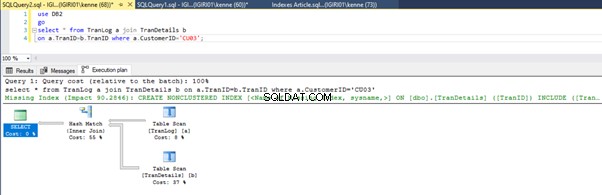
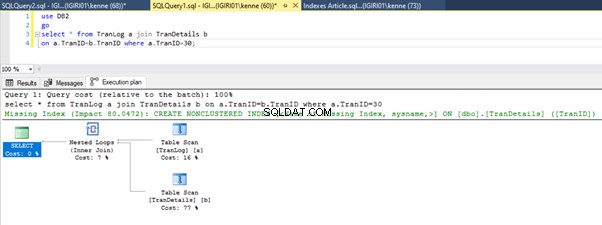
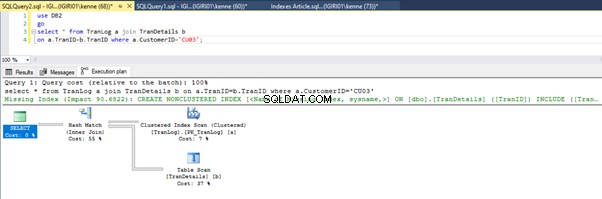
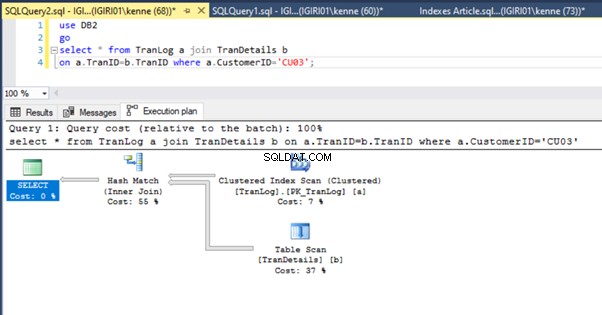
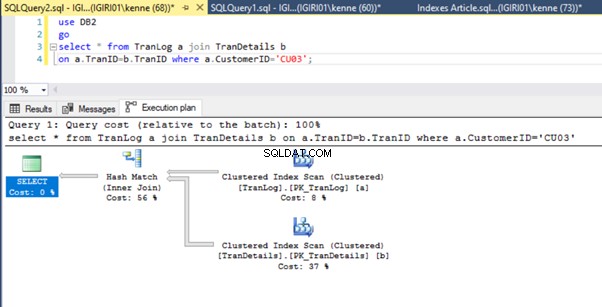
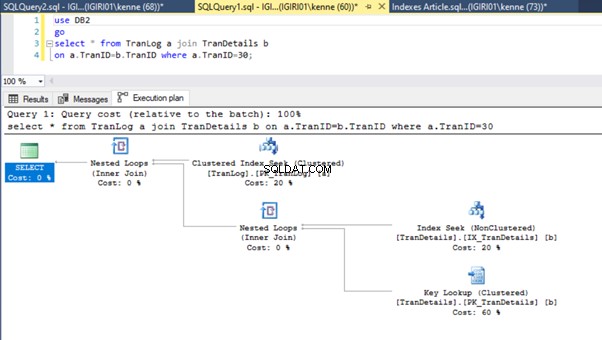
Cuando ejecutamos las consultas en el Listado 5, en ambos casos, tenemos que hacer un escaneo de tabla completo en ambas tablas (vea las Figuras 1 y 2). La parte dominante de cada consulta son las operaciones físicas. Ambos son uniones internas. Sin embargo, el Listado 5a usa una coincidencia hash unirse, mientras que el Listado 5b usa un Bucle anidado entrar. Nota:el Listado 5a devuelve 4000 filas mientras que el Listado 4b devuelve 4 filas.
Tres pasos de ajuste de rendimiento
La primera optimización que hacemos es introducir un índice (una clave principal, para ser exactos) en el TranID columna del TranLog tabla:
-- Listing 6: Create Primary Key
alter table TranLog add constraint PK_TranLog primary key clustered (TranID);
Las figuras 3 y 4 muestran que SQL Server utiliza este índice en ambas consultas, realizando un escaneo en el Listado 5a y una búsqueda en el Listado 5b.
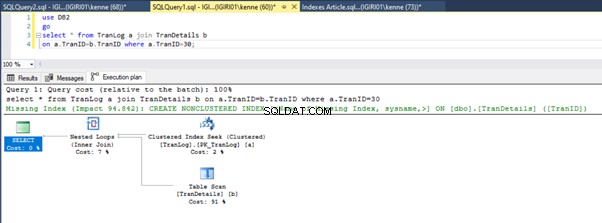
Tenemos una búsqueda de índice en el Listado 5b. Ocurre debido a la columna involucrada en el predicado de la cláusula WHERE:TranID. Es esa columna a la que hemos aplicado un índice.
A continuación, introducimos una clave foránea en el TranID columna de TranDetails tabla (Listado 7).
-- Listing 7: Create Foreign Key
alter table TranDetails add constraint FK_TranDetails foreign key (TranID) references TranLog (TranID);
Esto no cambia mucho en el plan de ejecución. La situación es prácticamente la misma que se muestra anteriormente en las Figuras 3 y 4.
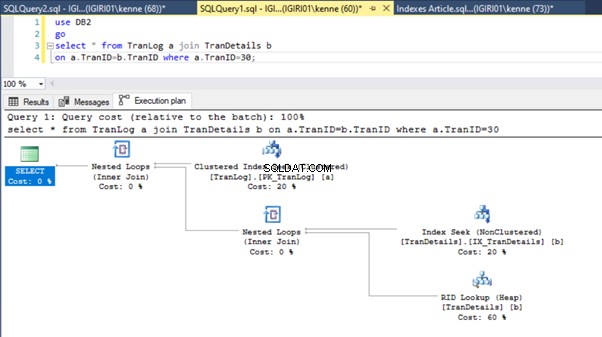
Luego introducimos un índice en la columna de clave externa:
-- Listing 8: Create Index on Foreign Key
create index IX_TranDetails on TranDetails (TranID);
Esta acción cambia drásticamente el plan de ejecución del Listado 5b (consulte la Figura 6). Vemos que más índice busca suceder. Además, observe la búsqueda de RID en la Figura 6.
Las búsquedas de RID en montones suelen ocurrir en ausencia de una clave principal. Un montón es una tabla sin clave principal.
Finalmente, agregamos una clave principal a los TranDetails mesa. Esto elimina el escaneo de la tabla y la búsqueda del montón RID en los Listados 5a y 5b respectivamente (consulte las Figuras 7 y 8).
-- Listing 9: Create Primary Key on TranDetailsID
alter table TranDetails add constraint PK_TranDetails primary key clustered (TranDetailsID);
Conclusión
La mejora del rendimiento introducida por los índices es bien conocida incluso por los administradores de bases de datos novatos. Sin embargo, queremos señalar que debe observar detenidamente cómo las consultas usan índices.
Además, la idea es establecer la solución en el caso particular donde tenemos las consultas de combinación entre Registro de transacciones tablas y Detalles de transacciones mesas.
Por lo general, tiene sentido reforzar la relación entre dichas tablas usando una clave e introducir índices en las columnas de clave primaria y externa.
Al desarrollar aplicaciones que utilizan un diseño de este tipo, los desarrolladores deben tener en cuenta los índices y las relaciones necesarios en la etapa de diseño. Las herramientas modernas para los especialistas de SQL Server hacen que estos requisitos sean mucho más fáciles de cumplir. Puede perfilar sus consultas utilizando la herramienta especializada Query Profiler. Es parte de la solución profesional de funciones múltiples dbForge Studio para SQL Server desarrollada por Devart para simplificar la vida de los administradores de bases de datos.