Publicado originalmente en Serverless el 2 de julio de 2019

Exponer una base de datos simple a través de una API GraphQL requiere mucho código personalizado e infraestructura:¿verdadero o falso?
Para aquellos que respondieron "verdadero", estamos aquí para mostrarles que crear API de GraphQL es bastante fácil, con algunos ejemplos concretos para ilustrar por qué y cómo.
(Si ya sabe lo fácil que es crear API de GraphQL con Serverless, también hay mucho para usted en este artículo).
GraphQL es un lenguaje de consulta para las API web. Hay una diferencia clave entre una API REST convencional y las API basadas en GraphQL:con GraphQL, puede usar una sola solicitud para obtener varias entidades a la vez. Esto da como resultado cargas de página más rápidas y permite una estructura más simple para sus aplicaciones frontend, lo que resulta en una mejor experiencia web para todos. Si nunca antes ha usado GraphQL, le sugerimos que consulte este tutorial de GraphQL para obtener una introducción rápida.
El marco Serverless es ideal para las API de GraphQL:con Serverless, no necesita preocuparse por ejecutar, administrar y escalar sus propios servidores de API en la nube, y no necesitará escribir ningún script de automatización de infraestructura. Obtenga más información sobre Serverless aquí. Además, Serverless brinda una excelente experiencia de desarrollador independiente del proveedor y una comunidad sólida para ayudarlo a crear sus aplicaciones GraphQL.
Muchas aplicaciones en nuestra experiencia diaria contienen funciones de redes sociales, y ese tipo de funcionalidad realmente puede beneficiarse de la implementación de GraphQL en lugar del modelo REST, donde es difícil exponer estructuras con entidades anidadas, como usuarios y sus publicaciones de Twitter. Con GraphQL, puede crear un punto final de API unificado que le permita consultar, escribir y editar todas las entidades que necesita mediante una sola solicitud de API.
En este artículo, analizamos cómo crear una API de GraphQL simple con la ayuda del marco Serverless, Node.js y cualquiera de las varias soluciones de bases de datos alojadas disponibles a través de Amazon RDS:MySQL, PostgreSQL y MySQL Workalike Amazon Aurora.
¡Siga este repositorio de ejemplo en GitHub y profundicemos!
Creación de una API de GraphQL con un backend de base de datos relacional
En nuestro proyecto de ejemplo, decidimos usar las tres bases de datos (MySQL, PostgreSQL y Aurora) en el mismo código base. Lo sabemos, eso es excesivo incluso para una aplicación de producción, pero queríamos sorprenderte con la forma en que construimos a escala web. 😉
Pero en serio, sobrecargamos el proyecto solo para asegurarnos de que encuentre un ejemplo relevante que se aplique a su base de datos favorita. Si desea ver ejemplos con otras bases de datos, infórmenos en los comentarios.
Definiendo el esquema de GraphQL
Comencemos definiendo el esquema de la API de GraphQL que queremos crear, lo cual hacemos en el archivo schema.gql en la raíz de nuestro proyecto usando la sintaxis de GraphQL. Si no está familiarizado con esta sintaxis, eche un vistazo a los ejemplos en esta página de documentación de GraphQL.
Para empezar, agregamos los dos primeros elementos al esquema:una entidad de usuario y una entidad de publicación, definiéndolas de la siguiente manera para que cada usuario pueda tener varias entidades de publicación asociadas:
escriba Usuario {
UUID:cadena
Nombre:Cadena
Publicaciones:[Publicación]
escriba Publicación {
UUID:cadena
Texto:Cadena
Ahora podemos ver cómo se ven las entidades Usuario y Publicación. Más tarde, nos aseguraremos de que estos campos se puedan almacenar directamente en nuestras bases de datos.
A continuación, definamos cómo los usuarios de la API consultarán estas entidades. Si bien podríamos usar los dos tipos de GraphQL User y Post directamente en nuestras consultas de GraphQL, es una buena práctica crear tipos de entrada en su lugar para mantener el esquema simple. Así que continuamos y agregamos dos de estos tipos de entrada, uno para las publicaciones y otro para los usuarios:
entrada Entrada de usuario {
Nombre:Cadena
Publicaciones:[PostInput]
entrada Entrada posterior {
Texto:Cadena
Ahora definamos las mutaciones, las operaciones que modifican los datos almacenados en nuestras bases de datos a través de nuestra API GraphQL. Para ello creamos un tipo de Mutación. La única mutación que usaremos por ahora es createUser. Como estamos usando tres bases de datos diferentes, agregamos una mutación para cada tipo de base de datos. Cada una de las mutaciones acepta la entrada UserInput y devuelve una entidad de usuario:
También queremos proporcionar una forma de consultar a los usuarios, por lo que creamos un tipo de consulta con una consulta por tipo de base de datos. Cada consulta acepta una cadena que es el UUID del usuario, devolviendo la entidad de usuario que contiene su nombre, UUID y una colección de cada Pos``t asociado:
Finalmente, definimos el esquema y apuntamos a los tipos Consulta y Mutación:
schema { query: Query mutation: Mutation }
¡Ahora tenemos una descripción completa de nuestra nueva API GraphQL! Puede ver el archivo completo aquí.
Definición de controladores para la API de GraphQL
Ahora que tenemos una descripción de nuestra API GraphQL, podemos escribir el código que necesitamos para cada consulta y mutación. Comenzamos creando un archivo handler.js en la raíz del proyecto, justo al lado del archivo schema.gql que creamos anteriormente.
El primer trabajo de handler.js es leer el esquema:
La constante typeDefs ahora contiene las definiciones de nuestras entidades GraphQL. A continuación, especificamos dónde vivirá el código de nuestras funciones. Para mantener las cosas claras, crearemos un archivo separado para cada consulta y mutación:
La constante de resolución ahora contiene las definiciones de todas las funciones de nuestra API. Nuestro siguiente paso es crear el servidor GraphQL. ¿Recuerdas la biblioteca graphql-yoga que requerimos arriba? Usaremos esa biblioteca aquí para crear un servidor GraphQL que funcione fácil y rápidamente:
Finalmente, exportamos el controlador GraphQL junto con el controlador GraphQL Playground (que nos permitirá probar nuestra API GraphQL en un navegador web):
Bien, hemos terminado con el archivo handler.js por ahora. A continuación:escribir código para todas las funciones que acceden a las bases de datos.
Escribir código para las consultas y las mutaciones
Ahora necesitamos código para acceder a las bases de datos y para potenciar nuestra API GraphQL. En la raíz de nuestro proyecto, creamos la siguiente estructura para nuestras funciones de resolución de MySQL, con las otras bases de datos a continuación:
Consultas comunes
En la carpeta Común, completamos el archivo mysql.js con lo que necesitaremos para la mutación createUser y la consulta getUser:una consulta init, para crear tablas para Usuarios y Publicaciones si aún no existen; y una consulta de usuario, para devolver los datos de un usuario al crear y consultar un usuario. Usaremos esto tanto en la mutación como en la consulta.
La consulta init crea las tablas Usuarios y Publicaciones de la siguiente manera:
La consulta getUser devuelve el usuario y sus publicaciones:
Ambas funciones se exportan; luego podemos acceder a ellos en el archivo handler.js.
Escribiendo la mutación
Es hora de escribir el código para la mutación createUser, que debe aceptar el nombre del nuevo usuario, así como una lista de todas las publicaciones que le pertenecen. Para hacer esto, creamos el archivo resolver/Mutation/mysql_createUser.js con una única función de exportación para la mutación:
La función de mutación necesita hacer lo siguiente, en orden:
-
Conéctese a la base de datos utilizando las credenciales en las variables de entorno de la aplicación.
-
Inserte el usuario en la base de datos utilizando el nombre de usuario, proporcionado como entrada para la mutación.
-
También inserte cualquier publicación asociada con el usuario, proporcionada como entrada para la mutación.
-
Devuelve los datos de usuario creados.
Así es como logramos eso en el código:
Puede ver el archivo completo que define la mutación aquí.
Escribiendo la consulta
La consulta getUser tiene una estructura similar a la mutación que acabamos de escribir, pero esta es aún más simple. Ahora que la función getUser está en el espacio de nombres común, ya no necesitamos ningún SQL personalizado en la consulta. Entonces, creamos el archivo resolver/Query/mysql_getUser.js de la siguiente manera:
Puede ver la consulta completa en este archivo.
Reuniendo todo en el archivo serverless.yml
Demos un paso atrás. Actualmente tenemos lo siguiente:
-
Un esquema de la API de GraphQL.
-
Un archivo handler.js.
-
Un archivo para consultas comunes de bases de datos.
-
Un archivo por cada mutación y consulta.
El último paso es conectar todo esto a través del archivo serverless.yml. Creamos un serverless.yml vacío en la raíz del proyecto y comenzamos definiendo el proveedor, la región y el tiempo de ejecución. También aplicamos el rol LambdaRole IAM (que definimos más adelante aquí) a nuestro proyecto:
Luego definimos las variables de entorno para las credenciales de la base de datos:
Observe que todas las variables hacen referencia a la sección personalizada, que viene a continuación y contiene los valores reales de las variables. Tenga en cuenta que la contraseña es una contraseña terrible para su base de datos y debe cambiarse por algo más seguro (quizás p@ssw0rd 😃):
¿Cuáles son esas referencias después de Fn::GettAtt, preguntas? Esos se refieren a los recursos de la base de datos:
El archivo resource/MySqlRDSInstance.yml define todos los atributos de la instancia de MySQL. Puedes encontrar su contenido completo aquí.
Finalmente, en el archivo serverless.yml definimos dos funciones, graphql y playground. La función graphql se encargará de todas las solicitudes de la API, y el punto final del patio de recreo creará una instancia de GraphQL Playground para nosotros, que es una excelente manera de probar nuestra API de GraphQL en un navegador web:
¡Ahora el soporte de MySQL para nuestra aplicación está completo!
Puede encontrar el contenido completo del archivo serverless.yml aquí.
Adición de compatibilidad con Aurora y PostgreSQL
Ya hemos creado toda la estructura que necesitamos para admitir otras bases de datos en este proyecto. Para agregar soporte para Aurora y Postgres, solo necesitamos definir el código para sus mutaciones y consultas, lo que hacemos de la siguiente manera:
-
Agregue un archivo de consultas comunes para Aurora y para Postgres.
-
Agregue la mutación createUser para ambas bases de datos.
-
Agregue la consulta getUser para ambas bases de datos.
-
Agregue la configuración en el archivo serverless.yml para todas las variables de entorno y los recursos necesarios para ambas bases de datos.
En este punto, tenemos todo lo que necesitamos para implementar nuestra API GraphQL, con tecnología de MySQL, Aurora y PostgreSQL.
Implementación y prueba de la API de GraphQL
La implementación de nuestra API GraphQL es simple.
-
Primero ejecutamos npm install para establecer nuestras dependencias.
-
Luego ejecutamos npm run deployment, que configura todas nuestras variables de entorno y realiza la implementación.
-
Bajo el capó, este comando ejecuta la implementación sin servidor utilizando el entorno adecuado.
¡Eso es todo! En el resultado del paso de implementación, veremos el extremo de la URL para nuestra aplicación implementada. Podemos emitir solicitudes POST a nuestra API de GraphQL usando esta URL, y nuestro Playground (con el que jugaremos en un segundo) está disponible usando GET contra la misma URL.
Probar la API en GraphQL Playground
GraphQL Playground, que es lo que ve cuando visita esa URL en el navegador, es una excelente manera de probar nuestra API.
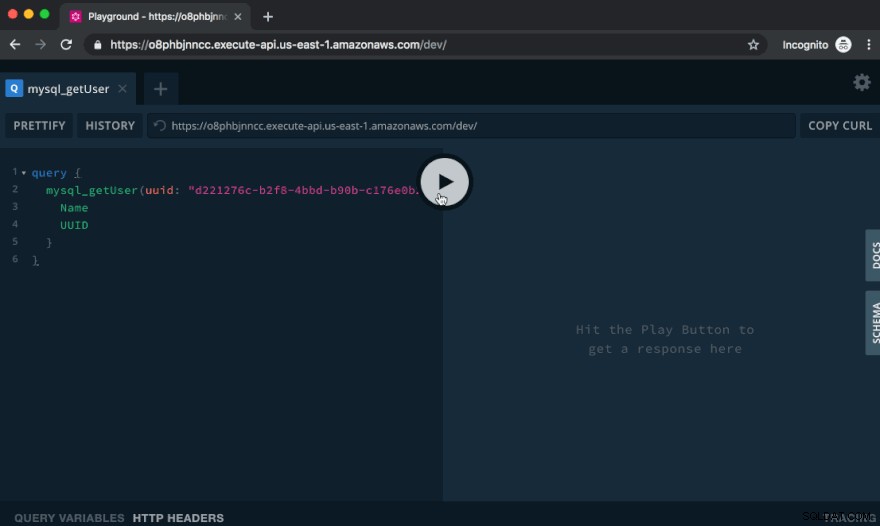
Vamos a crear un usuario ejecutando la siguiente mutación:
mutation { mysql_createUser( input: { Name: "Cicero" Posts: [ { Text: "Lorem ipsum dolor sit amet, consectetur adipiscing elit." } { Text: "Proin consequat mauris orci, ut consequat purus efficitur vel." } ] } ) { Name UUID } }
En esta mutación, llamamos a la API mysql_createUser, proporcionamos el texto de las publicaciones del nuevo usuario e indicamos que queremos recuperar el nombre del usuario y el UUID como respuesta.
Pegue el texto anterior en el lado izquierdo del Playground y haga clic en el botón Reproducir. A la derecha, verá el resultado de la consulta:
Ahora vamos a consultar por este usuario:
query { mysql_getUser(uuid: "f5593682-6bf1-466a-967d-98c7e9da844b") { Name UUID } }
Esto nos devuelve el nombre y el UUID del usuario que acabamos de crear. ¡Pulcro!
Podemos hacer lo mismo con los otros backends, PostgreSQL y Aurora. Para eso, solo necesitamos reemplazar los nombres de la mutación con postgres_createUser o aurora_createUser, y las consultas con postgres_getUser o aurora_getUser. ¡Pruébelo usted mismo! (Tenga en cuenta que los usuarios no están sincronizados entre las bases de datos, por lo que solo podrá consultar los usuarios que haya creado en cada base de datos específica).
Comparación de las implementaciones de MySQL, PostgreSQL y Aurora
Para empezar, las mutaciones y las consultas se ven exactamente iguales en Aurora y MySQL, ya que Aurora es compatible con MySQL. Y solo hay diferencias de código mínimas entre esos dos y la implementación de Postgres.
De hecho, para casos de uso simples, la mayor diferencia entre nuestras tres bases de datos es que Aurora solo está disponible como clúster. La configuración de Aurora más pequeña disponible todavía incluye una réplica de solo lectura y una de escritura, por lo que necesitamos una configuración en clúster incluso para esta implementación básica de Aurora.
Aurora ofrece un rendimiento más rápido que MySQL y PostgreSQL, debido principalmente a las optimizaciones SSD que Amazon realizó en el motor de la base de datos. A medida que crezca su proyecto, es probable que descubra que Aurora ofrece una mejor escalabilidad de la base de datos, un mantenimiento más sencillo y una mejor confiabilidad en comparación con las configuraciones predeterminadas de MySQL y PostgreSQL. Pero también puede realizar algunas de estas mejoras en MySQL y PostgreSQL si ajusta sus bases de datos y agrega replicación.
Para proyectos de prueba y áreas de juego, recomendamos MySQL o PostgreSQL. Estos pueden ejecutarse en instancias db.t2.micro RDS, que forman parte del nivel gratuito de AWS. Aurora actualmente no ofrece instancias db.t2.micro, por lo que pagará un poco más para usar Aurora para este proyecto de prueba.
Una última nota importante
Recuerde eliminar su implementación sin servidor una vez que haya terminado de probar la API de GraphQL para no seguir pagando por los recursos de la base de datos que ya no usa.
Puede eliminar la pila creada en este ejemplo ejecutando npm run remove en la raíz del proyecto.
¡Feliz experimentación!
Resumen
En este artículo, lo guiamos a través de la creación de una API GraphQL simple, utilizando tres bases de datos diferentes a la vez; aunque esto no es algo que haría en la realidad, nos permitió comparar implementaciones simples de las bases de datos Aurora, MySQL y PostgreSQL. Vimos que la implementación para las tres bases de datos es aproximadamente la misma en nuestro caso simple, salvo pequeñas diferencias en la sintaxis y las configuraciones de implementación.
Puede encontrar el proyecto de ejemplo completo que hemos estado usando en este repositorio de GitHub. La forma más fácil de experimentar con el proyecto es clonar el repositorio e implementarlo desde su máquina usando npm run deployment.
Para obtener más ejemplos de API de GraphQL que usan Serverless, consulte el repositorio serverless-graphql.
Si desea obtener más información sobre cómo ejecutar las API de GraphQL sin servidor a escala, puede disfrutar de nuestra serie de artículos "Ejecución de un punto final de GraphQL escalable y confiable con sin servidor"
¿Quizás GraphQL no es lo tuyo y prefieres implementar una API REST? Lo tenemos cubierto:consulte esta publicación de blog para ver algunos ejemplos.
¿Preguntas? Comente esta publicación o cree una discusión en nuestro foro.
Publicado originalmente en https://www.serverless.com.