Alejándome de mi serie de "ajustes de rendimiento instintivos", me gustaría hablar sobre cómo la fragmentación del índice puede aparecer sigilosamente en algunas circunstancias.
¿Qué es la fragmentación de índices?
La mayoría de la gente piensa que la 'fragmentación del índice' significa el problema en el que las páginas de la hoja del índice están desordenadas:la página de la hoja del índice con el siguiente valor clave no es la que está físicamente contigua en el archivo de datos a la página de la hoja del índice que se está examinando actualmente. . Esto se denomina fragmentación lógica (y algunas personas se refieren a ella como fragmentación externa, un término confuso que no me gusta).
La fragmentación lógica ocurre cuando una hoja de índice está llena y se requiere espacio en ella, ya sea para una inserción o para alargar un registro existente (por actualizar una columna de longitud variable). En ese caso, el motor de almacenamiento crea una nueva página vacía y mueve el 50 % de las filas (por lo general, pero no siempre) de la página completa a la página nueva. Esta operación crea espacio en ambas páginas, lo que permite continuar con la inserción o la actualización, y se denomina división de página. Hay casos patológicos interesantes que involucran divisiones de página repetidas a partir de una sola operación y divisiones de página que aumentan en cascada los niveles del índice, pero están más allá del alcance de esta publicación.
Cuando se produce una división de página, generalmente provoca una fragmentación lógica porque es muy poco probable que la nueva página asignada sea físicamente contigua a la que se está dividiendo. Cuando un índice tiene mucha fragmentación lógica, las exploraciones de índice se ralentizan porque las lecturas físicas de las páginas necesarias no se pueden realizar de manera tan eficiente (utilizando lecturas de "lectura anticipada" de varias páginas) cuando las páginas hoja no se almacenan en orden en el archivo de datos. .
Esa es la definición básica de fragmentación de índice, pero hay un segundo tipo de fragmentación de índice que la mayoría de la gente no considera:baja densidad de página (a veces se llama fragmentación interna, nuevamente, un término confuso que no me gusta).
La densidad de página es una medida de la cantidad de datos almacenados en una página hoja de índice. Cuando se produce una división de página con el caso habitual de 50/50, cada página hoja (la que se divide y la nueva) quedan con una densidad de página de solo el 50%. Cuanto menor sea la densidad de la página, más espacio vacío hay en el índice y, por lo tanto, más espacio en disco y memoria de grupo de búfer se puede pensar que se desperdicia. Escribí en un blog sobre este problema hace unos años y puedes leer sobre él aquí.
Ahora que he dado una definición básica de los dos tipos de fragmentación de índices, me referiré a ellos colectivamente como simplemente "fragmentación".
En el resto de esta publicación, me gustaría discutir tres casos en los que los índices agrupados pueden fragmentarse incluso si está evitando operaciones que obviamente causarían fragmentación (es decir, inserciones aleatorias y actualizaciones de registros para que sean más largas).
Fragmentación de Eliminaciones
"¿Cómo puede una eliminación de una página de hoja de índice agrupado causar una división de página?" te estarás preguntando No lo hará, en circunstancias normales (¡y me senté a pensar en ello durante unos minutos para asegurarme de que no se trataba de un caso patológico extraño! Pero consulte la sección a continuación...) Sin embargo, las eliminaciones pueden hacer que la densidad de la página disminuya progresivamente.
Imagine el caso en el que el índice agrupado tiene un valor de clave de identidad bigint, por lo que las inserciones siempre irán al lado derecho del índice y nunca, nunca, se insertarán en una parte anterior del índice (salvo que alguien reinicie el valor de identidad:potencialmente muy problemático!). Ahora imagine que la carga de trabajo elimina registros de la tabla que ya no son necesarios, después de lo cual la tarea de limpieza de fantasmas en segundo plano recuperará el espacio en la página y se convertirá en espacio libre.
En ausencia de inserciones aleatorias (imposible en nuestro escenario a menos que alguien reinicie la identidad o especifique un valor clave para usar después de habilitar SET IDENTITY INSERT para la tabla), ningún registro nuevo usará el espacio que se liberó de los registros eliminados. Esto significa que la densidad de página promedio de las partes anteriores del índice agrupado disminuirá constantemente, lo que generará una mayor cantidad de espacio en disco desperdiciado y memoria de grupo de búfer, como describí anteriormente.
Las eliminaciones pueden causar fragmentación, siempre que considere la densidad de la página como parte de la "fragmentación".
Fragmentación del aislamiento de instantáneas
SQL Server 2005 introdujo dos nuevos niveles de aislamiento:aislamiento de instantáneas y aislamiento de instantáneas de lectura confirmada. Estos dos tienen una semántica ligeramente diferente, pero básicamente permiten consultas para ver una vista de un punto en el tiempo de una base de datos y selecciones sin colisión de bloqueo. Esa es una gran simplificación, pero es suficiente para mis propósitos.
Para facilitar estos niveles de aislamiento, el equipo de desarrollo de Microsoft que dirigí implementó un mecanismo llamado control de versiones. La forma en que funciona el control de versiones es que cada vez que cambia un registro, la versión previa al cambio del registro se copia en el almacén de versiones en tempdb, y el registro modificado recibe una etiqueta de control de versiones de 14 bytes que se agrega al final. La etiqueta contiene un puntero a la versión anterior del registro, además de una marca de tiempo que se puede usar para determinar cuál es la versión correcta de un registro para que lea una consulta en particular. De nuevo, enormemente simplificado, pero lo único que nos interesa es la adición de los 14 bytes.
Por lo tanto, cada vez que un registro cambia cuando cualquiera de estos niveles de aislamiento está en vigor, puede expandirse en 14 bytes si aún no hay una etiqueta de versión para el registro. ¿Qué sucede si no hay suficiente espacio para los 14 bytes adicionales en la página de hoja de índice? Así es, se producirá una división de la página, lo que provocará la fragmentación.
Gran cosa, podría pensar, ya que el registro está cambiando de todos modos, por lo que si estuviera cambiando de tamaño de todos modos, probablemente se habría producido una división de página. No, esa lógica solo es válida si el cambio de registro fue para aumentar el tamaño de una columna de longitud variable. ¡Se agregará una etiqueta de control de versiones incluso si se actualiza una columna de longitud fija!
Así es:cuando el control de versiones está en juego, las actualizaciones de las columnas de longitud fija pueden hacer que un registro se expanda, lo que podría causar una división y fragmentación de la página. Lo que es aún más interesante es que una eliminación también agregará la etiqueta de 14 bytes, por lo que una eliminación en un índice agrupado podría causar una división de página cuando se usa el control de versiones.
La conclusión aquí es que habilitar cualquiera de las formas de aislamiento de instantáneas puede provocar que la fragmentación comience a ocurrir repentinamente en índices agrupados donde anteriormente no había posibilidad de fragmentación.
Fragmentación de secundarios legibles
El último caso que quiero discutir es el uso de secundarios legibles, parte de la función de grupo de disponibilidad que se agregó en SQL Server 2012.
Cuando habilita una secundaria legible, todas las consultas que realiza en la réplica secundaria se convierten para usar el aislamiento de instantáneas bajo las cubiertas. Esto evita que las consultas bloqueen la reproducción constante de los registros de la réplica principal, ya que el código de recuperación adquiere bloqueos a medida que avanza.
Para hacer esto, debe haber etiquetas de control de versiones de 14 bytes en los registros de la réplica secundaria. Hay un problema, porque todas las réplicas deben ser idénticas para que la reproducción del registro funcione. Bueno, no del todo. Los contenidos de la etiqueta de control de versiones no son relevantes, ya que solo se usan en la instancia que los creó. Pero la réplica secundaria no puede agregar etiquetas de control de versiones, lo que hace que los registros sean más largos, ya que eso cambiaría el diseño físico de los registros en una página y rompería la reproducción del registro. Sin embargo, si las etiquetas de control de versiones ya estuvieran allí, podría usar el espacio sin romper nada.
Así que eso es exactamente lo que sucede. El motor de almacenamiento se asegura de que las etiquetas de control de versiones necesarias para la réplica secundaria ya estén allí, al agregarlas en la réplica principal.
Tan pronto como se crea una réplica secundaria legible de una base de datos, cualquier actualización de un registro en la réplica principal hace que se agregue una etiqueta vacía de 14 bytes al registro, de modo que los 14 bytes se contabilicen correctamente en todos los registros. . La etiqueta no se usa para nada (a menos que el aislamiento de instantáneas esté habilitado en la réplica principal), pero el hecho de que se cree hace que el registro se expanda y, si la página ya está llena, entonces...
Sí, habilitar una réplica secundaria legible provoca el mismo efecto en la réplica principal que si hubiera habilitado el aislamiento de instantáneas:fragmentación.
Resumen
No piense que debido a que está evitando el uso de GUID como claves de clúster y evitando la actualización de columnas de longitud variable en sus tablas, sus índices agrupados serán inmunes a la fragmentación. Como describí anteriormente, hay otros factores ambientales y de carga de trabajo que pueden causar problemas de fragmentación en sus índices agrupados que debe tener en cuenta.
Ahora no se deje llevar y piense que no debe eliminar registros, no debe usar el aislamiento de instantáneas y no debe usar archivos secundarios legibles. Solo debe ser consciente de que todos pueden causar fragmentación y saber cómo detectarla, eliminarla y mitigarla.
SQL Sentry tiene una herramienta genial, Fragmentation Manager, que puede usar como complemento de Performance Advisor para ayudar a determinar dónde están los problemas de fragmentación y luego abordarlos. ¡Puede que te sorprenda la fragmentación que encuentras cuando revisas! Como ejemplo rápido, aquí puedo ver visualmente, hasta el nivel de partición individual, cuánta fragmentación existe, qué tan rápido se volvió así, cualquier patrón que exista y el impacto real que tiene en la memoria desperdiciada en el sistema:
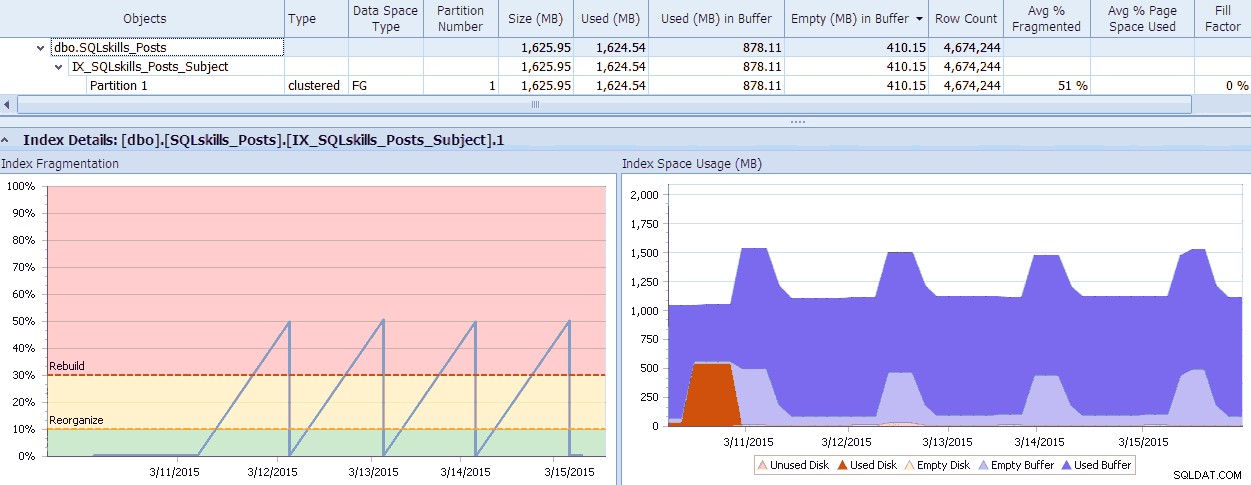 Datos de SQL Sentry Fragmentation Manager (haga clic para agrandar)
Datos de SQL Sentry Fragmentation Manager (haga clic para agrandar)
En mi próxima publicación, hablaré más sobre la fragmentación y cómo mitigarla para que sea menos problemática.