Aunque vienen con muchas restricciones y algunas advertencias de implementación importantes, las vistas indexadas siguen siendo una característica muy poderosa de SQL Server cuando se emplean correctamente en las circunstancias adecuadas. Un uso común es proporcionar una vista agregada previamente de los datos subyacentes, lo que brinda a los usuarios la capacidad de consultar los resultados directamente sin incurrir en los costos de procesar las uniones, los filtros y los agregados subyacentes cada vez que se ejecuta una consulta.
Aunque las nuevas funciones de Enterprise Edition, como el almacenamiento en columnas y el procesamiento en modo por lotes, han transformado las características de rendimiento de muchas consultas grandes de este tipo, aún no existe una forma más rápida de obtener un resultado que evitar por completo todo el procesamiento subyacente, sin importar qué tan eficiente sea ese procesamiento. podría haberse convertido.
Antes de que se añadieran al producto las vistas indexadas (y sus primos más limitados, las columnas calculadas), los profesionales de las bases de datos a veces escribían código complejo de activación múltiple para presentar los resultados de una consulta importante en una tabla real. Este tipo de arreglo es notoriamente difícil de hacer bien en todas las circunstancias, particularmente cuando los cambios simultáneos en los datos subyacentes son frecuentes.
La función de vistas indexadas hace que todo esto sea mucho más fácil, donde se aplica de manera sensata y correcta. El motor de la base de datos se ocupa de todo lo necesario para garantizar que los datos leídos desde una vista indexada coincidan con la consulta subyacente y los datos de la tabla en todo momento.
Mantenimiento Incremental
SQL Server mantiene los datos de vista indexados sincronizados con la consulta subyacente al actualizar automáticamente los índices de vista de manera adecuada cada vez que los datos cambian en las tablas base. El costo de esta actividad de mantenimiento corre a cargo del proceso de cambio de los datos base. Las operaciones adicionales necesarias para mantener los índices de vista se agregan silenciosamente al plan de ejecución para la operación original de inserción, actualización, eliminación o combinación. En segundo plano, SQL Server también se ocupa de problemas más sutiles relacionados con el aislamiento de transacciones, por ejemplo, asegurando el manejo correcto de las transacciones que se ejecutan bajo el aislamiento de instantáneas o instantáneas confirmadas de lectura.
Construir las operaciones adicionales del plan de ejecución necesarias para mantener los índices de vista correctamente no es un asunto trivial, como sabrá cualquiera que haya intentado una implementación de "tabla de resumen mantenida por código de activación". La complejidad de la tarea es una de las razones por las que las vistas indexadas tienen tantas restricciones. Limitar el área de superficie admitida a uniones internas, proyecciones, selecciones (filtros) y los agregados SUM y COUNT_BIG reduce considerablemente la complejidad de la implementación.
Las vistas indexadas se mantienen incrementalmente . Esto significa que el procesador de consultas determina el efecto neto de los cambios de la tabla base en la vista y aplica solo los cambios necesarios para actualizar la vista. En casos simples, puede calcular los deltas necesarios solo a partir de los cambios de la tabla base y los datos actualmente almacenados en la vista. Cuando la definición de la vista contiene uniones, la parte de mantenimiento de la vista indexada del plan de ejecución también necesitará acceder a las tablas unidas, pero esto generalmente se puede realizar de manera eficiente, dados los índices de tabla base apropiados.
Para simplificar aún más la implementación, SQL Server siempre usa la misma forma de plan básico (como punto de partida) para implementar operaciones de mantenimiento de vistas indexadas. Las instalaciones normales proporcionadas por el optimizador de consultas se emplean para simplificar y optimizar la forma de mantenimiento estándar según corresponda. Ahora pasaremos a un ejemplo para ayudar a unir estos conceptos.
Ejemplo 1:inserción de una sola fila
Supongamos que tenemos la siguiente tabla simple y vista indexada:
CREATE TABLE dbo.T1
(
GroupID integer NOT NULL,
Value integer NOT NULL
);
GO
INSERT dbo.T1
(GroupID, Value)
VALUES
(1, 1),
(1, 2),
(2, 3),
(2, 4),
(2, 5);
GO
CREATE VIEW dbo.IV
WITH SCHEMABINDING
AS
SELECT
T1.GroupID,
SumValue = SUM(T1.Value),
NumRows = COUNT_BIG(*)
FROM dbo.T1 AS T1
WHERE
T1.GroupID BETWEEN 1 AND 5
GROUP BY
T1.GroupID;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.IV (GroupID); Después de ejecutar ese script, los datos en la tabla de muestra se ven así:

Y la vista indexada contiene:

El ejemplo más simple de un plan de mantenimiento de vista indexada para esta configuración ocurre cuando agregamos una sola fila a la tabla base:
INSERT dbo.T1
(GroupID, Value)
VALUES
(3, 6); El plan de ejecución para este inserto se muestra a continuación:
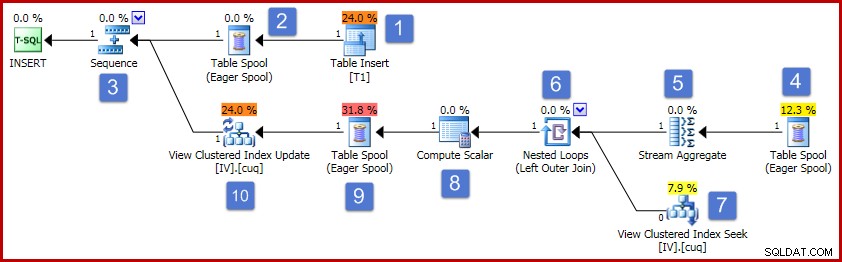
Siguiendo los números del diagrama, la operación de este plan de ejecución procede de la siguiente manera:
- El operador Insertar tabla agrega la nueva fila a la tabla base. Este es el único operador de plan asociado con la inserción de la tabla base; todos los operadores restantes están preocupados por el mantenimiento de la vista indexada.
- Eager Table Spool guarda los datos de la fila insertada en un almacenamiento temporal.
- El operador de Secuencia garantiza que la rama superior del plan se ejecute hasta el final antes de que se active la siguiente rama de la Secuencia. En este caso especial (insertando una sola fila), sería válido quitar la Secuencia (y los spools en las posiciones 2 y 4), conectando directamente la entrada de Stream Aggregate a la salida de Table Insert. Esta posible optimización no está implementada, por lo que la Secuencia y los Spools permanecen.
- Este Eager Table Spool está asociado con el spool en la posición 2 (tiene una propiedad de ID de nodo principal que proporciona este enlace explícitamente). El spool reproduce filas (una fila en el presente caso) desde el mismo almacenamiento temporal escrito por el spool primario. Como se mencionó anteriormente, los carretes y las posiciones 2 y 4 son innecesarios y se presentan simplemente porque existen en la plantilla genérica para el mantenimiento de la vista indexada.
- Stream Aggregate calcula la suma de los datos de la columna Valor en el conjunto insertado y cuenta el número de filas presentes por grupo de claves de vista. La salida son los datos incrementales necesarios para mantener la vista sincronizada con los datos base. Tenga en cuenta que Stream Aggregate no tiene un elemento Group By porque el optimizador de consultas sabe que solo se está procesando un único valor. Sin embargo, el optimizador no aplica una lógica similar para reemplazar los agregados con proyecciones (la suma de un solo valor es solo el valor en sí mismo, y el recuento siempre será uno para una sola inserción de fila). Calcular los agregados de suma y conteo para una sola fila de datos no es una operación costosa, por lo que esta optimización perdida no es motivo de preocupación.
- La combinación relaciona cada cambio incremental calculado con una clave existente en la vista indexada. La combinación es una combinación externa porque es posible que los datos recién insertados no se correspondan con ningún dato existente en la vista.
- Este operador ubica la fila que se modificará en la vista.
- El Compute Scalar tiene dos responsabilidades importantes. En primer lugar, determina si cada cambio incremental afectará a una fila existente en la vista o si será necesario crear una nueva fila. Para ello, comprueba si la combinación externa produjo un valor nulo desde el lado de la vista de la combinación. Nuestro inserto de muestra es para el grupo 3, que actualmente no existe en la vista, por lo que se creará una nueva fila. La segunda función de Compute Scalar es calcular nuevos valores para las columnas de la vista. Si se va a agregar una nueva fila a la vista, esto es simplemente el resultado de la suma incremental de Stream Aggregate. Si se va a actualizar una fila existente en la vista, el nuevo valor es el valor existente en la fila de la vista más la suma incremental de Stream Aggregate.
- Este carrete de mesa Eager es para protección de Halloween. Es necesario para la corrección cuando una operación de inserción afecta a una tabla a la que también se hace referencia en el lado de acceso a datos de la consulta. Técnicamente no es necesario si la operación de mantenimiento de una sola fila da como resultado una actualización de una fila de vista existente, pero permanece en el plan de todos modos.
- El operador final en el plan está etiquetado como un operador de actualización, pero realizará una inserción o una actualización para cada fila que reciba según el valor de la columna "código de acción" agregada por Compute Scalar en el nodo 8 En términos más generales, este operador de actualización es capaz de insertar, actualizar y eliminar.
Hay bastantes detalles allí, así que para resumir:
- El agregado agrupa los cambios de datos por la clave agrupada única de la vista. Calcula el efecto neto de los cambios de la tabla base en cada columna por clave.
- La combinación externa conecta los cambios incrementales por clave a las filas existentes en la vista.
- El escalar de cómputo calcula si se debe agregar una nueva fila a la vista o actualizar una fila existente. Calcula los valores finales de la columna para la operación de inserción o actualización de la vista.
- El operador de actualización de vista inserta una nueva fila o actualiza una existente según lo indique el código de acción.
Ejemplo 2:Inserción de varias filas
Lo crea o no, el plan de ejecución de inserción de tabla base de una sola fila discutido anteriormente estaba sujeto a una serie de simplificaciones. Aunque se omitieron algunas posibles optimizaciones adicionales (como se indicó), el optimizador de consultas aún logró eliminar algunas operaciones de la plantilla de mantenimiento de vista indexada general y reducir la complejidad de otras.
Se permitieron varias de estas optimizaciones porque estábamos insertando solo una fila, pero otras se habilitaron porque el optimizador pudo ver los valores literales que se agregaron a la tabla base. Por ejemplo, el optimizador podría ver que el valor de grupo insertado pasaría el predicado en la cláusula WHERE de la vista.
Si ahora insertamos dos filas, con los valores "ocultos" en las variables locales, obtenemos un plan un poco más complejo:
DECLARE
@Group1 integer = 4,
@Value1 integer = 7,
@Group2 integer = 5,
@Value2 integer = 8;
INSERT dbo.T1
(GroupID, Value)
VALUES
(@Group1, @Value1),
(@Group2, @Value2);
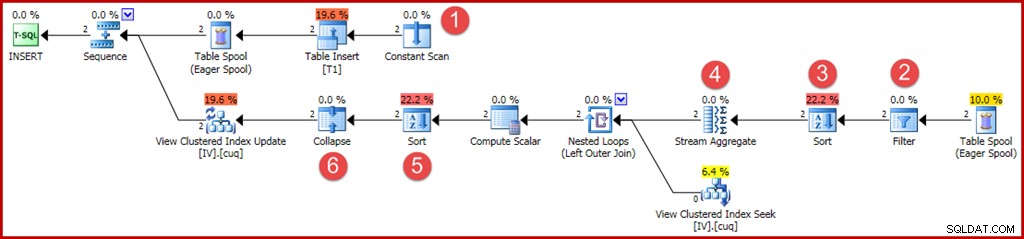
Los operadores nuevos o modificados se anotan como antes:
- La exploración constante proporciona los valores para insertar. Anteriormente, una optimización para inserciones de una sola fila permitía omitir este operador.
- Ahora se requiere un operador de filtro explícito para verificar que los grupos insertados en la tabla base coincidan con la cláusula WHERE en la vista. Da la casualidad de que las dos nuevas filas pasarán la prueba, pero el optimizador no puede ver los valores en las variables para saber esto de antemano. Además, no sería seguro almacenar en caché un plan que omitió este filtro porque una futura reutilización del plan podría tener diferentes valores en las variables.
- Ahora se requiere Ordenar para garantizar que las filas lleguen al agregado de flujo en orden de grupo. La ordenación se eliminó anteriormente porque no tiene sentido ordenar una fila.
- El Stream Aggregate ahora tiene una propiedad de "agrupar por", que coincide con la clave agrupada única de la vista.
- Se requiere esta ordenación para presentar las filas en el orden de código de acción de clave de vista, que es necesario para el funcionamiento correcto del operador Contraer. Sort es un operador de bloqueo completo, por lo que ya no es necesario un Eager Table Spool para la protección de Halloween.
- El nuevo operador Collapse combina una inserción y una eliminación adyacentes en el mismo valor clave en una sola operación de actualización. Este operador no es realmente requerido en este caso, porque no se pueden generar códigos de acción de borrado (solo inserciones y actualizaciones). Esto parece ser un descuido, o tal vez algo dejado por razones de seguridad. Las partes generadas automáticamente de un plan de consulta de actualización pueden volverse extremadamente complejas, por lo que es difícil saberlo con certeza.
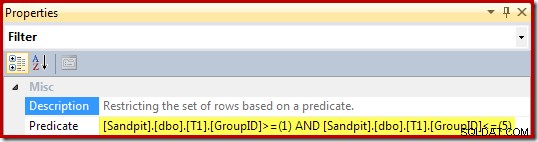
Las propiedades del Filtro (derivadas de la cláusula WHERE de la vista) son:
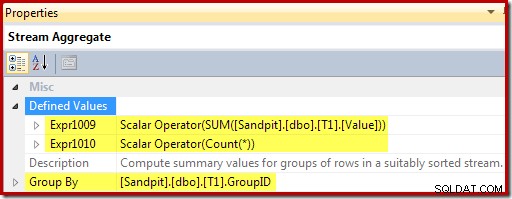
Stream Aggregate agrupa por la clave de vista y calcula la suma y cuenta los agregados por grupo:
Compute Scalar identifica la acción a realizar por fila (insertar o actualizar en este caso) y calcula el valor para insertar o actualizar en la vista:
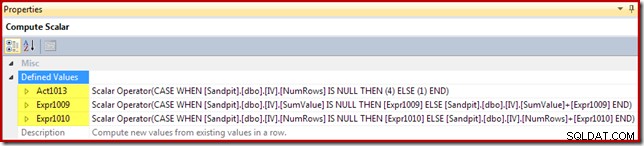
El código de acción recibe una etiqueta de expresión de [Act1xxx]. Los valores válidos son 1 para una actualización, 3 para una eliminación y 4 para una inserción. Esta expresión de acción da como resultado una inserción (código 4) si no se encontró ninguna fila coincidente en la vista (es decir, la combinación externa devolvió un valor nulo para la columna NumRows). Si se encontró una fila coincidente, el código de acción es 1 (actualizar).
Tenga en cuenta que NumRows es el nombre que se le da a la columna COUNT_BIG(*) requerida en la vista. En un plan que podría resultar en eliminaciones de la vista, Compute Scalar detectaría cuándo este valor se convertiría en cero (sin filas para el grupo actual) y generaría un código de acción de eliminación (3).
Las expresiones restantes mantienen los agregados sum y count en la vista. Sin embargo, tenga en cuenta que las etiquetas de expresión [Expr1009] y [Expr1010] no son nuevas; se refieren a las etiquetas creadas por Stream Aggregate. La lógica es sencilla:si no se encontró una fila coincidente, el nuevo valor para insertar es solo el valor calculado en el agregado. Si se encontró una fila coincidente en la vista, el valor actualizado es el valor actual en la fila más el incremento calculado por el agregado.
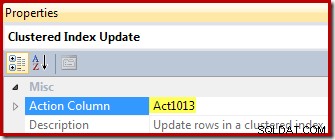
Finalmente, el operador de actualización de vista (que se muestra como una Actualización de índice agrupado en SSMS) muestra la referencia de la columna de acción ([Act1013] definida por Compute Scalar):
Ejemplo 3:actualización de varias filas
Hasta ahora solo hemos analizado las inserciones en la tabla base. Los planes de ejecución para una eliminación son muy similares, con solo algunas diferencias menores en los cálculos detallados. Por lo tanto, el siguiente ejemplo pasa a ver el plan de mantenimiento para una actualización de la tabla base:
DECLARE
@Group1 integer = 1,
@Group2 integer = 2,
@Value integer = 1;
UPDATE dbo.T1
SET Value = Value + @Value
WHERE GroupID IN (@Group1, @Group2); Como antes, esta consulta usa variables para ocultar los valores literales del optimizador, evitando que se apliquen algunas simplificaciones. También es cuidadoso actualizar dos grupos separados, evitando las optimizaciones que se pueden aplicar cuando el optimizador sabe que solo se verá afectado un solo grupo (una sola fila de la vista indexada). El plan de ejecución anotado para la consulta de actualización se encuentra a continuación:
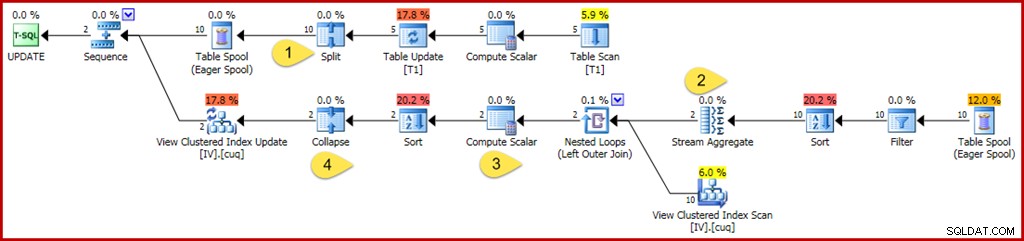
Los cambios y punto de interés son:
- El nuevo operador Dividir convierte cada actualización de fila de la tabla base en una operación de eliminación e inserción separada. Cada fila de actualización se divide en dos filas separadas, duplicando el número de filas después de este punto en el plan. Split es parte del patrón split-sort-collapse necesario para proteger contra errores transitorios incorrectos de violación de clave única.
- El agregado de transmisión se modifica para tener en cuenta las filas entrantes que pueden especificar una eliminación o una inserción (debido a la división y determinado por una columna de código de acción en la fila). Una fila de inserción aporta el valor original en sumas agregadas; el signo se invierte para eliminar filas de acción. De manera similar, el agregado de conteo de filas aquí cuenta las filas de inserción como +1 y las filas de eliminación como -1.
- La lógica Compute Scalar también se modifica para reflejar que el efecto neto de los cambios por grupo podría requerir una eventual acción de inserción, actualización o eliminación en la vista materializada. En realidad, no es posible que esta consulta de actualización en particular resulte en la inserción o eliminación de una fila en esta vista, pero la lógica requerida para deducir eso está más allá de las capacidades de razonamiento actuales del optimizador. Una consulta de actualización o una definición de vista ligeramente diferentes podrían dar como resultado una combinación de acciones de vista de inserción, eliminación y actualización.
- El operador Colapso se resalta únicamente por su función en el patrón de colapsado de clasificación dividida mencionado anteriormente. Tenga en cuenta que solo colapsa eliminaciones e inserciones en la misma clave; las eliminaciones e inserciones sin igual después del Colapso son perfectamente posibles (y bastante habituales).
Como antes, las propiedades del operador clave que se deben observar para comprender el trabajo de mantenimiento de la vista indexada son Filter, Stream Aggregate, Outer Join y Compute Scalar.
Ejemplo 4:actualización de filas múltiples con uniones
Para completar la descripción general de los planes de ejecución de mantenimiento de vista indexada, necesitaremos una nueva vista de ejemplo que una varias tablas e incluya una proyección en la lista de selección:
CREATE TABLE dbo.E1 (g integer NULL, a integer NULL);
CREATE TABLE dbo.E2 (g integer NULL, a integer NULL);
CREATE TABLE dbo.E3 (g integer NULL, a integer NULL);
GO
INSERT dbo.E1 (g, a) VALUES (1, 1);
INSERT dbo.E2 (g, a) VALUES (1, 1);
INSERT dbo.E3 (g, a) VALUES (1, 1);
GO
CREATE VIEW dbo.V1
WITH SCHEMABINDING
AS
SELECT
g = E1.g,
sa1 = SUM(ISNULL(E1.a, 0)),
sa2 = SUM(ISNULL(E2.a, 0)),
sa3 = SUM(ISNULL(E3.a, 0)),
cbs = COUNT_BIG(*)
FROM dbo.E1 AS E1
JOIN dbo.E2 AS E2
ON E2.g = E1.g
JOIN dbo.E3 AS E3
ON E3.g = E2.g
WHERE
E1.g BETWEEN 1 AND 5
GROUP BY
E1.g;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.V1 (g); Para garantizar la corrección, uno de los requisitos de la vista indexada es que un agregado de suma no puede operar en una expresión que podría evaluarse como nula. La definición de vista anterior usa ISNULL para cumplir con ese requisito. A continuación, se muestra una consulta de actualización de muestra que produce un componente de plan de mantenimiento de índice bastante completo, junto con el plan de ejecución que produce:
UPDATE dbo.E1
SET g = g + 1,
a = a + 1;
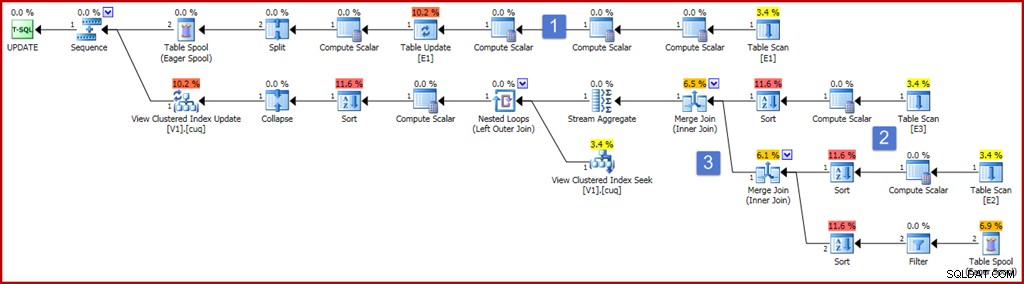
El plan parece bastante grande y complicado ahora, pero la mayoría de los elementos son exactamente como ya hemos visto. Las diferencias clave son:
- La rama superior del plan incluye una serie de operadores adicionales de Compute Scalar. Estos podrían organizarse de manera más compacta, pero esencialmente están presentes para capturar los valores previos a la actualización de las columnas que no se agrupan. Compute Scalar a la izquierda de Table Update captura el valor posterior a la actualización de la columna "a", con la proyección ISNULL aplicada.
- Los nuevos escalares de cálculo en esta área del plan calculan el valor producido por la expresión ISNULL en cada tabla de origen. En general, las proyecciones en las tablas unidas en la vista estarán representadas por Compute Scalars aquí. Las ordenaciones en esta área del plan están presentes simplemente porque el optimizador eligió una estrategia de combinación de combinación por razones de costo (recuerde, la combinación requiere una entrada ordenada de clave de combinación).
- Los dos operadores de combinación son nuevos y simplemente implementan las combinaciones en la definición de la vista. Estas uniones siempre aparecen antes de Stream Aggregate que calcula el efecto incremental de los cambios en la vista. Tenga en cuenta que un cambio en una tabla base puede dar como resultado que una fila que solía cumplir con los criterios de unión ya no se una, y viceversa. Todas estas posibles complejidades se manejan correctamente (dadas las restricciones de vista indexadas) por Stream Aggregate que produce un resumen de los cambios por clave de vista después de que se han realizado las uniones.
Reflexiones finales
Ese último plan representa prácticamente la plantilla completa para mantener una vista indexada, aunque la adición de índices no agrupados a la vista también agregaría operadores adicionales en la salida del operador de actualización de vista. Aparte de una división adicional (y una combinación de ordenación y contracción si el índice no agrupado de la vista es único), esta posibilidad no tiene nada de especial. Agregar una cláusula de salida a la consulta de la tabla base también puede producir algunos operadores adicionales interesantes, pero nuevamente, estos no son específicos del mantenimiento de vistas indexadas per se.
Para resumir la estrategia general completa:
- Los cambios en la tabla base se aplican normalmente; Es posible que se capturen los valores previos a la actualización.
- Se puede usar un operador de división para transformar las actualizaciones en pares de eliminación/inserción.
- Un spool ansioso guarda la información de cambio de la tabla base en un almacenamiento temporal.
- Se accede a todas las tablas de la vista, excepto a la tabla base actualizada (que se lee desde el spool).
- Las proyecciones en la vista están representadas por Compute Scalars.
- Se aplican filtros en la vista. Los filtros pueden insertarse en exploraciones o búsquedas como residuos.
- Se realizan las uniones especificadas en la vista.
- Un agregado calcula los cambios incrementales netos agrupados por clave de vista agrupada.
- El conjunto de cambios incrementales se une externamente a la vista.
- Un Compute Scalar calcula un código de acción (insertar/actualizar/eliminar en la vista) para cada cambio y calcula los valores reales que se insertarán o actualizarán. La lógica computacional se basa en la salida del agregado y el resultado de la unión externa a la vista.
- Los cambios se ordenan según la clave de vista y el código de acción, y se colapsan en las actualizaciones según corresponda.
- Finalmente, los cambios incrementales se aplican a la vista misma.
Como hemos visto, el conjunto normal de herramientas disponibles para el optimizador de consultas todavía se aplica a las partes del plan generadas automáticamente, lo que significa que uno o más de los pasos anteriores pueden simplificarse, transformarse o eliminarse por completo. Sin embargo, la forma básica y el funcionamiento del plan permanecen intactos.
Si ha estado siguiendo los ejemplos de código, puede usar el siguiente script para limpiar:
DROP VIEW dbo.V1; DROP TABLE dbo.E3, dbo.E2, dbo.E1; DROP VIEW dbo.IV; DROP TABLE dbo.T1;



