Mucha gente usa las estadísticas de espera como parte de su metodología general de solución de problemas de rendimiento, al igual que yo, por lo que la pregunta que quería explorar en esta publicación es sobre los tipos de espera asociados con la sobrecarga del observador. Por sobrecarga del observador, me refiero al impacto en el rendimiento de la carga de trabajo de SQL Server causado por SQL Profiler, los seguimientos del lado del servidor o las sesiones de eventos extendidos. Para obtener más información sobre el tema de la sobrecarga del observador, consulte las siguientes dos publicaciones de mi colega Jonathan Kehayias :
Entonces, en esta publicación, me gustaría analizar algunas variaciones de la sobrecarga del observador y ver si podemos encontrar tipos de espera consistentes asociados con la degradación medida. Los usuarios de SQL Server implementan el seguimiento en sus entornos de producción de varias maneras, por lo que los resultados pueden variar, pero quería cubrir algunas categorías amplias e informar sobre lo que encontré:
- Uso de sesión de SQL Profiler
- Uso de seguimiento del lado del servidor
- Uso de seguimiento del lado del servidor, escritura en una ruta de E/S lenta
- Uso de eventos extendidos con un destino de búfer circular
- Uso de eventos extendidos con un destino de archivo
- Uso de eventos extendidos con un destino de archivo en una ruta de E/S lenta
- Uso de eventos extendidos con un destino de archivo en una ruta de E/S lenta sin pérdida de eventos
Es probable que pueda pensar en otras variaciones sobre el tema y lo invito a compartir cualquier hallazgo interesante con respecto a la sobrecarga del observador y las estadísticas de espera como un comentario en esta publicación.
Línea de base
Para la prueba, utilicé una máquina virtual VMware con cuatro vCPU y 4 GB de RAM. Mi invitado de máquina virtual estaba en OCZ Vertex SSD. El sistema operativo era Windows Server 2008 R2 Enterprise y la versión de SQL Server es 2012, SP1 CU4.
En cuanto a la "carga de trabajo", estoy usando una consulta de solo lectura en un bucle en la base de datos de muestras de crédito de 2008, configurada en GO 10 000 000 veces.
USE [Credit];
GO
SELECT TOP 1
[member].[member_no],
[member].[lastname],
[payment].[payment_no],
[payment].[payment_dt],
[payment].[payment_amt]
FROM [dbo].[payment]
INNER JOIN [dbo].[member]
ON [member].[member_no] = [payment].[member_no];
GO 10000000 También estoy ejecutando esta consulta a través de 16 sesiones simultáneas. El resultado final en mi sistema de prueba es una utilización de CPU del 100 % en todas las vCPU en el invitado virtual y un promedio de 14 492 solicitudes por lotes por segundo durante un período de 2 minutos.
En cuanto al seguimiento de eventos, en cada prueba utilicé Showplan XML Statistics Profile para las pruebas de seguimiento del SQL Profiler y del lado del servidor, y query_post_execution_showplan para sesiones de eventos extendidos. Los eventos del plan de ejecución son muy costosos, que es precisamente por lo que los elegí para poder ver si, en circunstancias extremas, podía derivar o no temas de tipo espera.
Para probar la acumulación de tipo de espera durante un período de prueba, utilicé la siguiente consulta. Nada especial:simplemente borrar las estadísticas, esperar 2 minutos y luego recopilar las 10 principales acumulaciones de espera para la instancia de SQL Server durante el período de prueba de degradación:
-- Clearing the wait stats
DBCC SQLPERF('waitstats', clear);
WAITFOR DELAY '00:02:00';
GO
SELECT TOP 10
[wait_type],
[waiting_tasks_count],
[wait_time_ms]
FROM sys.[dm_os_wait_stats] AS [ws]
ORDER BY [wait_time_ms] DESC; Fíjate que no filtrar los tipos de espera en segundo plano que normalmente se filtran, y esto se debe a que no quería eliminar algo que normalmente es benigno, pero en esta circunstancia en realidad apunta a un área real para investigar más a fondo.
Sesión del Analizador de SQL
La siguiente tabla muestra las solicitudes por lotes antes y después por segundo cuando se habilita un seguimiento de seguimiento local de SQL Profiler Showplan XML Statistics Profile (ejecutándose en la misma máquina virtual que la instancia de SQL Server):
| Solicitudes de lote de referencia por segundo (promedio de 2 minutos) | Solicitudes por lotes de sesión de SQL Profiler por segundo (promedio de 2 minutos) |
|---|---|
| 14.492 | 1416 |
Puede ver que el seguimiento de SQL Profiler provoca una caída significativa en el rendimiento.
En cuanto al tiempo de espera acumulado durante ese mismo período, los principales tipos de espera fueron los siguientes (al igual que con el resto de las pruebas de este artículo, realicé algunas pruebas y el resultado fue generalmente consistente):
| esperar_tipo | recuento_de_tareas_en_espera | tiempo_de_espera_ms |
|---|---|---|
| TRACEWRITE | 67.142 | 1,149,824 |
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237.003 |
| TAREA_DORMIR | 313 | 180.449 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120,111 |
| HADR_FILESTREAM_IOMGR_IOCOMPLETION | 240 | 120.086 |
| LAZYWRITER_SLEEP | 120 | 120.059 |
| DIRTY_PAGE_POLL | 1198 | 120.038 |
| HADR_WORK_QUEUE | 12 | 120.015 |
| LOGMGR_QUEUE | 937 | 120.011 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120.006 |
El tipo de espera que me llama la atención es TRACEWRITE – que Books Online define como un tipo de espera que "ocurre cuando el proveedor de seguimiento del conjunto de filas SQL Trace espera un búfer libre o un búfer con eventos para procesar". El resto de los tipos de espera se ven como tipos de espera de fondo estándar que normalmente se filtrarían de su conjunto de resultados. Es más, hablé de un problema similar con el rastreo excesivo en un artículo de 2011 llamado Sobrecarga de Observer:los peligros del rastreo excesivo, por lo que estaba familiarizado con este tipo de espera a veces. señalando correctamente los problemas de sobrecarga del observador. Ahora, en ese caso particular sobre el que escribí en el blog, no se trataba de SQL Profiler, sino de otra aplicación que usaba el proveedor de seguimiento del conjunto de filas (de manera ineficiente).
Rastreo del lado del servidor
Eso fue para SQL Profiler, pero ¿qué pasa con la sobrecarga de seguimiento del lado del servidor? La siguiente tabla muestra las solicitudes por lotes anteriores y posteriores por segundo cuando se habilita una escritura de seguimiento del lado del servidor local en un archivo:
| Solicitudes de lote de referencia por segundo (promedio de 2 minutos) | Solicitudes por lotes de SQL Profiler por segundo (promedio de 2 minutos) |
|---|---|
| 14.492 | 4.015 |
Los principales tipos de espera fueron los siguientes (hice algunas pruebas y el resultado fue consistente):
| esperar_tipo | recuento_de_tareas_en_espera | tiempo_de_espera_ms |
|---|---|---|
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237.015 |
| TAREA_DORMIR | 253 | 180.871 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120.046 |
| HADR_WORK_QUEUE | 12 | 120.042 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120.021 |
| XE_DISPATCHER_WAIT | 3 | 120.006 |
| ESPERAR | 1 | 120.000 |
| LOGMGR_QUEUE | 931 | 119.993 |
| DIRTY_PAGE_POLL | 1193 | 119.958 |
| XE_TIMER_EVENT | 55 | 119.954 |
Esta vez no vemos TRACEWRITE (estamos usando un proveedor de archivos ahora) y el otro tipo de espera relacionado con el rastreo, el SQLTRACE_INCREMENTAL_FLUSH_SLEEP no documentado subió, pero en comparación con la primera prueba, tiene un tiempo de espera acumulado muy similar (120 046 frente a 120 006), y mi colega Erin Stellato (@erinstellato) habló sobre este tipo de espera en particular en su publicación Averiguar cuándo se borraron por última vez las estadísticas de espera . Entonces, al observar los otros tipos de espera, ninguno salta como una señal de alerta confiable.
Rastreo del lado del servidor escribiendo en una ruta de E/S lenta
¿Qué sucede si colocamos el archivo de seguimiento del lado del servidor en un disco lento? La siguiente tabla muestra las solicitudes por lotes antes y después por segundo al habilitar un seguimiento del lado del servidor local que escribe en un archivo en una memoria USB:
| Solicitudes de lote de referencia por segundo (promedio de 2 minutos) | Solicitudes por lotes de SQL Profiler por segundo (promedio de 2 minutos) |
|---|---|
| 14.492 | 260 |
Como podemos ver, el rendimiento se degrada significativamente, incluso en comparación con la prueba anterior.
Los principales tipos de espera fueron los siguientes:
| esperar_tipo | recuento_de_tareas_en_espera | tiempo_de_espera_ms |
|---|---|---|
| SQLTRACE_FILE_BUFFER | 357 | 351.174 |
| SP_SERVER_DIAGNOSTICS_SLEEP | 2273 | 299.995 |
| TAREA_DORMIR | 240 | 194.264 |
| FT_IFTS_SCHEDULER_IDLE_WAIT | 2 | 181.458 |
| REQUEST_FOR_DEADLOCK_SEARCH | 25 | 125.007 |
| LAZYWRITER_SLEEP | 63 | 124.437 |
| LOGMGR_QUEUE | 941 | 120.559 |
| HADR_FILESTREAM_IOMGR_IOCOMPLETION | 67 | 120.516 |
| ESPERAR | 1 | 120.515 |
| DIRTY_PAGE_POLL | 1204 | 120.513 |
Un tipo de espera que salta a la vista para esta prueba es el SQLTRACE_FILE_BUFFER no documentado. . No hay mucha documentación sobre este, pero basándonos en el nombre, podemos hacer una conjetura (especialmente dada la configuración de esta prueba en particular).
Eventos extendidos al destino del búfer circular
A continuación, revisemos los resultados de los equivalentes de sesiones de eventos extendidos. Usé la siguiente definición de sesión:
CREATE EVENT SESSION [ApplicationXYZ] ON SERVER ADD EVENT sqlserver.query_post_execution_showplan, ADD TARGET package0.ring_buffer(SET max_events_limit=(1000)) WITH (STARTUP_STATE=ON); GO
La siguiente tabla muestra las solicitudes por lotes antes y después por segundo al habilitar una sesión XE con un destino de búfer circular (capturando el query_post_execution_showplan evento):
| Solicitudes de lote de referencia por segundo (promedio de 2 minutos) | Solicitudes por lotes de SQL Profiler por segundo (promedio de 2 minutos) |
|---|---|
| 14.492 | 4737 |
Los principales tipos de espera fueron los siguientes:
| esperar_tipo | recuento_de_tareas_en_espera | tiempo_de_espera_ms |
|---|---|---|
| SP_SERVER_DIAGNOSTICS_SLEEP | 612 | 299.992 |
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237.006 |
| TAREA_DORMIR | 240 | 181.739 |
| LAZYWRITER_SLEEP | 120 | 120,219 |
| HADR_WORK_QUEUE | 12 | 120.038 |
| DIRTY_PAGE_POLL | 1198 | 120.035 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120.017 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120.011 |
| LOGMGR_QUEUE | 936 | 120.008 |
| ESPERAR | 1 | 120.001 |
Nada saltó como relacionado con XE, solo "ruido" de tareas en segundo plano.
Eventos extendidos a un destino de archivo
¿Qué hay de cambiar la sesión para usar un destino de archivo en lugar de un destino de búfer circular? La siguiente tabla muestra las solicitudes por lotes anteriores y posteriores por segundo al habilitar una sesión XE con un destino de archivo en lugar de un destino de búfer circular:
| Solicitudes de lote de referencia por segundo (promedio de 2 minutos) | Solicitudes por lotes de SQL Profiler por segundo (promedio de 2 minutos) |
|---|---|
| 14.492 | 4299 |
Los principales tipos de espera fueron los siguientes:
| esperar_tipo | recuento_de_tareas_en_espera | tiempo_de_espera_ms |
|---|---|---|
| SP_SERVER_DIAGNOSTICS_SLEEP | 2103 | 299.996 |
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237.003 |
| TAREA_DORMIR | 253 | 180.663 |
| LAZYWRITER_SLEEP | 120 | 120.187 |
| HADR_WORK_QUEUE | 12 | 120.029 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120.019 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120.011 |
| ESPERAR | 1 | 120.001 |
| XE_TIMER_EVENT | 59 | 119.966 |
| LOGMGR_QUEUE | 935 | 119.957 |
Nada, a excepción de XE_TIMER_EVENT , saltó como relacionado con XE. El repositorio de tipo de espera de Bob Ward considera que es seguro ignorarlo a menos que haya algo que pueda estar mal, pero, de manera realista, ¿notaría este tipo de espera generalmente benigno si estuviera en el noveno lugar en su sistema durante una degradación del rendimiento? ¿Y si ya lo está filtrando debido a su naturaleza normalmente benigna?
Eventos extendidos a un destino de archivo de ruta de E/S lento
Ahora, ¿qué sucede si coloco el archivo en una ruta de E/S lenta? La siguiente tabla muestra las solicitudes por lotes antes y después por segundo al habilitar una sesión XE con un destino de archivo en una memoria USB:
| Solicitudes de lote de referencia por segundo (promedio de 2 minutos) | Solicitudes por lotes de SQL Profiler por segundo (promedio de 2 minutos) |
|---|---|
| 14.492 | 4,386 |
Los principales tipos de espera fueron los siguientes:
| esperar_tipo | recuento_de_tareas_en_espera | tiempo_de_espera_ms |
|---|---|---|
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237.046 |
| TAREA_DORMIR | 253 | 180.719 |
| HADR_FILESTREAM_IOMGR_IOCOMPLETION | 240 | 120.427 |
| LAZYWRITER_SLEEP | 120 | 120.190 |
| HADR_WORK_QUEUE | 12 | 120.025 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120.013 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120.011 |
| ESPERAR | 1 | 120.002 |
| DIRTY_PAGE_POLL | 1197 | 119.977 |
| XE_TIMER_EVENT | 59 | 119.949 |
Una vez más, no salta nada relacionado con XE, excepto el XE_TIMER_EVENT .
Eventos extendidos a un objetivo de archivo de ruta de E/S lento, sin pérdida de eventos
La siguiente tabla muestra las solicitudes por lotes antes y después por segundo al habilitar una sesión XE con un destino de archivo en una memoria USB, pero esta vez sin permitir la pérdida de eventos (EVENT_RETENTION_MODE=NO_EVENT_LOSS), lo cual no se recomienda y verá en los resultados por qué podría ser:
| Solicitudes de lote de referencia por segundo (promedio de 2 minutos) | Solicitudes por lotes de SQL Profiler por segundo (promedio de 2 minutos) |
|---|---|
| 14.492 | 539 |
Los principales tipos de espera fueron los siguientes:
| esperar_tipo | recuento_de_tareas_en_espera | tiempo_de_espera_ms |
|---|---|---|
| XE_BUFFERMGR_FREEBUF_EVENT | 8773 | 1,707,845 |
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237.003 |
| TAREA_DORMIR | 337 | 180.446 |
| LAZYWRITER_SLEEP | 120 | 120.032 |
| DIRTY_PAGE_POLL | 1198 | 120.026 |
| HADR_WORK_QUEUE | 12 | 120.009 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120.007 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120.006 |
| ESPERAR | 1 | 120.000 |
| XE_TIMER_EVENT | 59 | 119.944 |
Con la reducción extrema del rendimiento, vemos XE_BUFFERMGR_FREEBUF_EVENT salta a la posición número uno en nuestros resultados de tiempo de espera acumulados. Este es documentado en Books Online, y Microsoft nos dice que este evento está asociado con sesiones XE configuradas para no perder eventos, y donde todos los búferes de la sesión están llenos.
Impacto del observador
Dejando a un lado los tipos de espera, fue interesante notar qué impacto tuvo cada método de observación en la capacidad de nuestra carga de trabajo para procesar solicitudes por lotes:
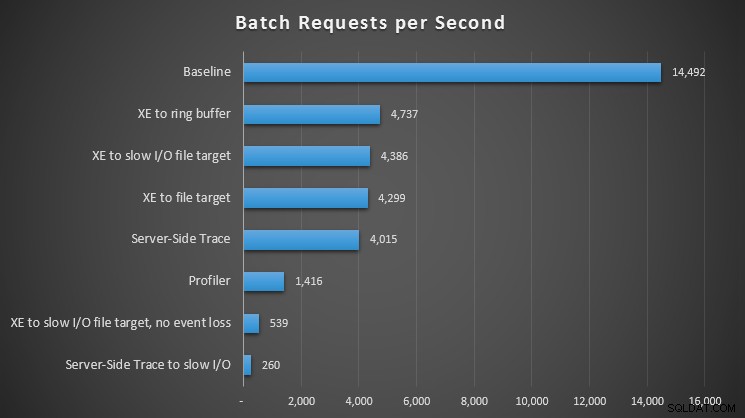
Impacto de los diferentes métodos de observación en las solicitudes de lotes por segundo
Para todos los enfoques, hubo un impacto significativo, pero no impactante, en comparación con nuestra línea de base (sin observación); Sin embargo, el mayor dolor se sintió al usar Profiler, al usar Server-Side Trace en una ruta de E/S lenta o eventos extendidos en un destino de archivo en una ruta de E/S lenta, pero solo cuando se configuró para que no se pierdan eventos. Con la pérdida de eventos, esta configuración realmente funcionó a la par con un destino de archivo a una ruta de E/S rápida, presumiblemente porque pudo eliminar muchos más eventos.
Resumen
No probé todos los escenarios posibles y ciertamente hay otras combinaciones interesantes (sin mencionar los diferentes comportamientos basados en la versión de SQL Server), pero la conclusión clave que saco de esta exploración es que no siempre se puede confiar en una acumulación de tipo de espera obvia. puntero cuando se enfrenta a un escenario de observación por encima de la cabeza. Según las pruebas de esta publicación, solo tres de los siete escenarios manifestaron un tipo de espera específico que podría ayudarlo a orientarse en la dirección correcta. Incluso entonces, estas pruebas se realizaron en un sistema controlado y, a menudo, las personas filtran los tipos de espera antes mencionados como tipos de fondo benignos, por lo que es posible que no los vea en absoluto.
Ante esto, ¿qué puedes hacer? Para la degradación del rendimiento sin síntomas claros u obvios, recomiendo ampliar el alcance para preguntar sobre seguimientos y sesiones XE (aparte, también recomiendo ampliar su alcance si el sistema está virtualizado o puede tener opciones de energía incorrectas). Por ejemplo, como parte de la solución de problemas de un sistema, verifique sys.[traces] y sys.[dm_xe_sessions] para ver si se está ejecutando algo inesperado en el sistema. Es una capa adicional de lo que debe preocuparse, pero hacer algunas validaciones rápidas puede ahorrarle una cantidad significativa de tiempo.