Tipos de datos de parámetros
Como se mencionó en la primera parte de esta serie, una de las razones por las que es mejor parametrizar explícitamente es para tener control total sobre los tipos de datos de parámetros. La parametrización simple tiene una serie de peculiaridades en esta área, lo que puede dar como resultado que se almacenen en caché más planes parametrizados de lo esperado, o que se encuentren resultados diferentes en comparación con la versión sin parametrizar.
Cuando SQL Server aplica parametrización simple a una declaración ad-hoc, hace una conjetura sobre el tipo de datos del parámetro de reemplazo. Cubriré las razones de las conjeturas más adelante en la serie.
Por el momento, veamos algunos ejemplos que usan la base de datos Stack Overflow 2010 en SQL Server 2019 CU 14. La compatibilidad de la base de datos se establece en 150 y el umbral de costo para el paralelismo se establece en 50 para evitar el paralelismo por ahora:
ALTER DATABASE SCOPED CONFIGURATION
CLEAR PROCEDURE_CACHE;
GO
SELECT U.DisplayName
FROM dbo.Users AS U
WHERE U.Reputation = 252;
GO
SELECT U.DisplayName
FROM dbo.Users AS U
WHERE U.Reputation = 25221;
GO
SELECT U.DisplayName
FROM dbo.Users AS U
WHERE U.Reputation = 252552; Estas declaraciones dan como resultado seis planes en caché, tres Adhoc y tres Preparados :
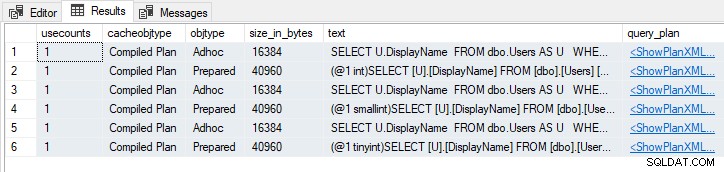 Diferentes tipos adivinados
Diferentes tipos adivinados
Observe los diferentes tipos de datos de parámetros en el Preparado planes.
Inferencia de tipos de datos
Los detalles de cómo se adivina cada tipo de datos son complejos y están documentados de forma incompleta. Como punto de partida, SQL Server deduce un tipo básico de la representación textual del valor y luego usa el subtipo compatible más pequeño.
Para una cadena de números sin comillas ni punto decimal, SQL Server elige entre tinyint , smallint y integer . Para tales números más allá del rango de un integer , SQL Server usa numeric con la menor precisión posible. Por ejemplo, el número 2,147,483,648 se escribe como numeric(10,0) . El bigint type no se usa para la parametrización del lado del servidor. Este párrafo explica los tipos de datos seleccionados en los ejemplos anteriores.
Cadenas de números con un punto decimal se interpretan como numeric , con una precisión y una escala lo suficientemente grande como para contener el valor proporcionado. Las cadenas con el prefijo de un símbolo de moneda se interpretan como money . Las cadenas en notación científica se traducen a float . El smallmoney y real tipos no se emplean.
El datetime y uniqueidentifer los tipos no se pueden deducir de los formatos de cadenas naturales. Para obtener una datetime o uniqueidentifer tipo de parámetro, el valor literal debe proporcionarse en formato de escape ODBC. Por ejemplo {d '1901-01-01'} , {ts '1900-01-01 12:34:56.790'} , o {guid 'F85C72AB-15F7-49E9-A949-273C55A6C393'} . De lo contrario, la fecha prevista o el literal UUID se escribe como una cadena. Tipos de fecha y hora que no sean datetime no se utilizan.
Los literales de cadena y binarios generales se escriben como varchar(8000) , nvarchar(4000) o varbinary(8000) según corresponda, a menos que el literal supere los 8000 bytes, en cuyo caso el max se utiliza la variante. Este esquema ayuda a evitar la contaminación de caché y el bajo nivel de reutilización que resultaría del uso de longitudes específicas.
No es posible usar CAST o CONVERT para establecer el tipo de datos para los parámetros por razones que detallaré más adelante en esta serie. Hay un ejemplo de esto en la siguiente sección.
No cubriré la parametrización forzada en esta serie, pero quiero mencionar las reglas para la inferencia de tipos de datos en ese caso tienen algunas diferencias importantes en comparación con la parametrización simple . La parametrización forzada no se agregó hasta SQL Server 2005, por lo que Microsoft tuvo la oportunidad de incorporar algunas lecciones de la parametrización simple experiencia, y no tuvo que preocuparse mucho por los problemas de compatibilidad con versiones anteriores.
Tipos numéricos
Para números con un punto decimal y números enteros más allá del rango de integer , las reglas de tipos inferidos presentan problemas especiales para la reutilización del plan y la contaminación del caché.
Considere la siguiente consulta usando decimales:
ALTER DATABASE SCOPED CONFIGURATION
CLEAR PROCEDURE_CACHE;
GO
DROP TABLE IF EXISTS dbo.Test;
GO
CREATE TABLE dbo.Test
(
SomeValue decimal(19,8) NOT NULL
);
GO
SELECT
T.SomeValue
FROM dbo.Test AS T
WHERE
T.SomeValue >= 987.65432
AND T.SomeValue < 123456.789;
Esta consulta califica para parametrización simple . SQL Server elige la menor precisión y escala para los parámetros que pueden contener los valores proporcionados. Esto significa que elige numeric(8,5) para 987.65432 y numeric(9,3) para 123456.789 :
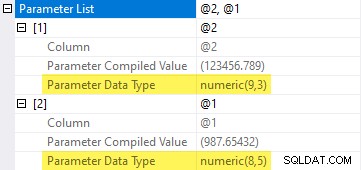 Tipos de datos numéricos inferidos
Tipos de datos numéricos inferidos
Estos tipos inferidos no coinciden con el decimal(19,8) tipo de la columna, por lo que aparece una conversión en torno al parámetro en el plan de ejecución:
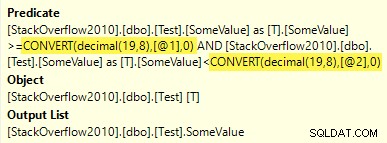 Conversión a tipo de columna
Conversión a tipo de columna
Estas conversiones solo representan una pequeña ineficiencia del tiempo de ejecución en este caso particular. En otras situaciones, una discrepancia entre el tipo de datos de la columna y el tipo inferido de un parámetro podría impedir una búsqueda de índice o requerir que SQL Server haga un trabajo adicional para fabricar una búsqueda dinámica.
Incluso cuando el plan de ejecución resultante parece razonable, una falta de coincidencia de tipos puede afectar fácilmente la calidad del plan debido al efecto de la falta de coincidencia de tipos en la estimación de la cardinalidad. Siempre es mejor usar tipos de datos coincidentes y prestar mucha atención a los tipos derivados que resultan de las expresiones.
Planificación de reutilización
El principal problema con el plan actual son los tipos específicos inferidos que afectan la coincidencia del plan en caché y, por lo tanto, la reutilización. Ejecutemos un par de consultas más de la misma forma general:
SELECT
T.SomeValue
FROM dbo.Test AS T
WHERE
T.SomeValue >= 98.76
AND T.SomeValue < 123.4567;
GO
SELECT
T.SomeValue
FROM dbo.Test AS T
WHERE
T.SomeValue >= 1.2
AND T.SomeValue < 1234.56789;
GO Ahora mire el caché del plan:
SELECT
CP.usecounts,
CP.objtype,
ST.[text]
FROM sys.dm_exec_cached_plans AS CP
CROSS APPLY sys.dm_exec_sql_text (CP.plan_handle) AS ST
WHERE
ST.[text] NOT LIKE '%dm_exec_cached_plans%'
AND ST.[text] LIKE '%SomeValue%Test%'
ORDER BY
CP.objtype ASC; Muestra un AdHoc y Preparado declaración para cada consulta que enviamos:
 Declaraciones preparadas separadas
Declaraciones preparadas separadas
El texto parametrizado es el mismo, pero los tipos de datos de parámetros son diferentes, por lo que los planes se almacenan en caché por separado y no se reutiliza el plan.
Si seguimos enviando consultas con diferentes combinaciones de escala o precisión, un nuevo Preparado el plan se creará y almacenará en caché cada vez. Recuerde que el tipo inferido de cada parámetro no está limitado por el tipo de datos de la columna, por lo que podríamos terminar con una gran cantidad de planes almacenados en caché, según los literales numéricos enviados. El número de combinaciones de numeric(1,0) a numeric(38,38) ya es grande antes de que pensemos en múltiples parámetros.
Parametrización explícita
Este problema no surge cuando usamos parametrización explícita, idealmente eligiendo el mismo tipo de datos que la columna con la que se compara el parámetro:
ALTER DATABASE SCOPED CONFIGURATION
CLEAR PROCEDURE_CACHE;
GO
DECLARE
@stmt nvarchar(4000) =
N'SELECT T.SomeValue FROM dbo.Test AS T WHERE T.SomeValue >= @P1 AND T.SomeValue < @P2;',
@params nvarchar(4000) =
N'@P1 numeric(19,8), @P2 numeric(19,8)';
EXECUTE sys.sp_executesql
@stmt,
@params,
@P1 = 987.65432,
@P2 = 123456.789;
EXECUTE sys.sp_executesql
@stmt,
@params,
@P1 = 98.76,
@P2 = 123.4567;
EXECUTE sys.sp_executesql
@stmt,
@params,
@P1 = 1.2,
@P2 = 1234.56789; Con una parametrización explícita, la consulta de caché del plan muestra solo un plan en caché, usado tres veces y no se necesitan conversiones de tipo:
 Parametrización explícita
Parametrización explícita
Como nota al margen final, he usado decimal y numeric indistintamente en esta sección. Son técnicamente diferentes tipos, aunque documentados como sinónimos y comportándose de manera equivalente. Este suele ser el caso, pero no siempre:
-- Raises error 8120: -- Column 'dbo.Test.SomeValue' is invalid in the select list -- because it is not contained in either an aggregate function -- or the GROUP BY clause. SELECT CONVERT(decimal(19,8), T.SomeValue) FROM dbo.Test AS T GROUP BY CONVERT(numeric(19,8), T.SomeValue);
Probablemente sea un pequeño error del analizador, pero aún así vale la pena ser coherente (a menos que estés escribiendo un artículo y quieras señalar una excepción interesante).
Operadores aritméticos
Hay otro caso límite que quiero abordar, basado en un ejemplo dado en la documentación, pero con un poco más de detalle (y quizás precisión):
-- The dbo.LinkTypes table contains two rows -- Uses simple parameterization SELECT r = CONVERT(float, 1./ 7) FROM dbo.LinkTypes AS LT; -- No simple parameterization due to -- constant-constant comparison SELECT r = CONVERT(float, 1./ 7) FROM dbo.LinkTypes AS LT WHERE 1 = 1;
Los resultados son diferentes, como se documenta:
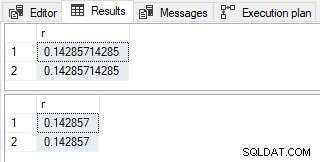 Diferentes resultados
Diferentes resultados
Con Parametrización Simple
Cuando parametrización simple ocurre, SQL Server parametriza ambos valores literales. El 1. el valor se escribe como numeric(1,0) como se esperaba. De manera un tanto inconsistente, el 7 se escribe como integer (no tinyint ). Las reglas de inferencia de tipos han sido construidas a lo largo del tiempo por diferentes equipos. Los comportamientos se mantienen para evitar romper el código heredado.
El siguiente paso implica el / operador aritmético. SQL Server requiere tipos compatibles antes de realizar la división. Dado numeric (decimal ) tiene una precedencia de tipo de datos más alta que integer , el integer se convertirá a numeric .
SQL Server necesita convertir implícitamente el integer a numeric . Pero, ¿qué precisión y escala usar? La respuesta podría basarse en el literal original, como lo hace SQL Server en otras circunstancias, pero siempre usa numeric(10) aquí.
El tipo de datos del resultado de dividir un numeric(1,0) por un numeric(10,0) está determinado por otro conjunto de reglas, dadas en la documentación para precisión, escala y longitud. Introduciendo los números en las fórmulas para la precisión de los resultados y la escala que se dan allí, tenemos:
- Precisión del resultado:
- p1 – s1 + s2 + máx(6, s1 + p2 + 1)
- =1 – 0 + 0 + máx(6, 0 + 10 + 1)
- =1 + máx(6, 11)
- =1 + 11
- =12
- Escala de resultados:
- máx(6, s1 + p2 + 1)
- =máx(6, 0 + 10 + 1)
- =máx(6, 11)
- =11
El tipo de datos de 1. / 7 es, por tanto, numeric(12, 11) . Este valor luego se convierte a float según lo solicitado y mostrado como 0.14285714285 (con 11 dígitos después del punto decimal).
Sin Parametrización Simple
Cuando no se realiza una parametrización simple, el 1. el literal se escribe como numeric(1,0) como antes. El 7 se escribe inicialmente como integer también como se vio anteriormente. La diferencia clave es el integer se convierte a numeric(1,0) , por lo que el operador de división tiene tipos comunes con los que trabajar. Esta es la precisión y escala más pequeña capaz de contener el valor 7 . Recuerde la parametrización simple utilizada numeric(10,0) aquí.
Las fórmulas de precisión y escala para dividir numeric(1,0) por numeric(1,0) dar un tipo de datos de resultado de numeric(7,6) :
- Precisión del resultado:
- p1 – s1 + s2 + máx(6, s1 + p2 + 1)
- =1 – 0 + 0 + máx(6, 0 + 1 + 1)
- =1 + máx(6, 2)
- =1 + 6
- =7
- Escala de resultados:
- máx(6, s1 + p2 + 1)
- =máx(6, 0 + 1 + 1)
- =máx(6, 2)
- =6
Después de la conversión final a float , el resultado mostrado es 0.142857 (con seis dígitos después del punto decimal).
Por lo tanto, la diferencia observada en los resultados se debe a la derivación de tipo provisional (numeric(12,11) vs. numeric(7,6) ) en lugar de la conversión final a float .
Si necesita más evidencia, la conversión a float no es responsable, considere:
-- Simple parameterization SELECT r = CONVERT(decimal(13,12), 1. / 7) FROM dbo.LinkTypes AS LT; -- No simple parameterization SELECT r = CONVERT(decimal(13,12), 1. / 7) FROM dbo.LinkTypes AS LT OPTION (MAXDOP 1);
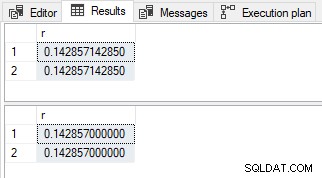 Resultado con decimal
Resultado con decimal
Los resultados difieren en valor y escala como antes.
Esta sección no cubre todas las peculiaridades de la inferencia y conversión de tipos de datos con parametrización simple por cualquier medio. Como se dijo antes, es mejor usar parámetros explícitos con tipos de datos conocidos siempre que sea posible.
Fin de la Parte 2
La siguiente parte de esta serie describe cómo la parametrización simple afecta los planes de ejecución.