Ha habido muchas discusiones sobre In-Memory OLTP (la característica anteriormente conocida como "Hekaton") y cómo puede ayudar a cargas de trabajo muy específicas y de alto volumen. En medio de una conversación diferente, noté algo en CREATE TYPE documentación para SQL Server 2014 que me hizo pensar que podría haber un caso de uso más general:

Adiciones relativamente silenciosas y no anunciadas a la documentación CREATE TYPE
Según el diagrama de sintaxis, parece que los parámetros con valores de tabla (TVP) se pueden optimizar para memoria, al igual que las tablas permanentes. Y con eso, las ruedas inmediatamente comenzaron a girar.
Una cosa para la que he usado TVP es para ayudar a los clientes a eliminar costosos métodos de división de cadenas en T-SQL o CLR (consulte los antecedentes en publicaciones anteriores aquí, aquí y aquí). En mis pruebas, el uso de un TVP normal superó a los patrones equivalentes con funciones de división CLR o T-SQL por un margen significativo (25-50%). Lógicamente me pregunté:¿habría alguna ganancia de rendimiento con un TVP optimizado para memoria?
Ha habido cierta aprensión sobre In-Memory OLTP en general, porque hay muchas limitaciones y brechas en las funciones, necesita un grupo de archivos separado para datos optimizados para memoria, necesita mover tablas completas a optimizadas para memoria y el mejor beneficio es típicamente logrado al crear también procedimientos almacenados compilados de forma nativa (que tienen su propio conjunto de limitaciones). Como demostraré, asumiendo que su tipo de tabla contiene estructuras de datos simples (por ejemplo, que representan un conjunto de números enteros o cadenas), el uso de esta tecnología solo para TVP elimina algunos de estos problemas.
La prueba
Aún necesitará un grupo de archivos optimizado para memoria incluso si no va a crear tablas permanentes optimizadas para memoria. Así que vamos a crear una nueva base de datos con la estructura adecuada:
CREATE DATABASE xtp; GO ALTER DATABASE xtp ADD FILEGROUP xtp CONTAINS MEMORY_OPTIMIZED_DATA; GO ALTER DATABASE xtp ADD FILE (name='xtpmod', filename='c:\...\xtp.mod') TO FILEGROUP xtp; GO ALTER DATABASE xtp SET MEMORY_OPTIMIZED_ELEVATE_TO_SNAPSHOT = ON; GO
Ahora, podemos crear un tipo de tabla regular, como lo haríamos hoy, y un tipo de tabla optimizada para memoria con un índice hash no agrupado y un recuento de cubos que saqué del aire (más información sobre cómo calcular los requisitos de memoria y el recuento de cubos en el mundo real aquí):
USE xtp; GO CREATE TYPE dbo.ClassicTVP AS TABLE ( Item INT PRIMARY KEY ); CREATE TYPE dbo.InMemoryTVP AS TABLE ( Item INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 256) ) WITH (MEMORY_OPTIMIZED = ON);
Si intenta esto en una base de datos que no tiene un grupo de archivos optimizado para memoria, obtendrá este mensaje de error, tal como lo haría si intentara crear una tabla normal optimizada para memoria:
Mensaje 41337, nivel 16, estado 0, línea 9El grupo de archivos MEMORY_OPTIMIZED_DATA no existe o está vacío. Las tablas optimizadas para memoria no se pueden crear para una base de datos hasta que tenga un grupo de archivos MEMORY_OPTIMIZED_DATA que no esté vacío.
Para probar una consulta en una tabla regular sin optimización de memoria, simplemente introduje algunos datos en una nueva tabla de la base de datos de muestra AdventureWorks2012, usando SELECT INTO para ignorar todas esas molestas restricciones, índices y propiedades extendidas, luego creé un índice agrupado en la columna que sabía que estaría buscando (ProductID ):
SELECT * INTO dbo.Products FROM AdventureWorks2012.Production.Product; -- 504 rows CREATE UNIQUE CLUSTERED INDEX p ON dbo.Products(ProductID);
A continuación, creé cuatro procedimientos almacenados:dos para cada tipo de tabla; cada uno usando EXISTS y JOIN enfoques (normalmente me gusta examinar ambos, aunque prefiero EXISTS; más adelante verá por qué no quería restringir mis pruebas a solo EXISTS ). En este caso, simplemente asigno una fila arbitraria a una variable, de modo que pueda observar un alto número de ejecuciones sin tener que lidiar con conjuntos de resultados y otros resultados y gastos generales:
-- Old-school TVP using EXISTS:
CREATE PROCEDURE dbo.ClassicTVP_Exists
@Classic dbo.ClassicTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @name NVARCHAR(50);
SELECT @name = p.Name
FROM dbo.Products AS p
WHERE EXISTS
(
SELECT 1 FROM @Classic AS t
WHERE t.Item = p.ProductID
);
END
GO
-- In-Memory TVP using EXISTS:
CREATE PROCEDURE dbo.InMemoryTVP_Exists
@InMemory dbo.InMemoryTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @name NVARCHAR(50);
SELECT @name = p.Name
FROM dbo.Products AS p
WHERE EXISTS
(
SELECT 1 FROM @InMemory AS t
WHERE t.Item = p.ProductID
);
END
GO
-- Old-school TVP using a JOIN:
CREATE PROCEDURE dbo.ClassicTVP_Join
@Classic dbo.ClassicTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @name NVARCHAR(50);
SELECT @name = p.Name
FROM dbo.Products AS p
INNER JOIN @Classic AS t
ON t.Item = p.ProductID;
END
GO
-- In-Memory TVP using a JOIN:
CREATE PROCEDURE dbo.InMemoryTVP_Join
@InMemory dbo.InMemoryTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @name NVARCHAR(50);
SELECT @name = p.Name
FROM dbo.Products AS p
INNER JOIN @InMemory AS t
ON t.Item = p.ProductID;
END
GO
A continuación, necesitaba simular el tipo de consulta que suele presentarse en este tipo de tabla y requiere un TVP o un patrón similar en primer lugar. Imagine un formulario con un menú desplegable o un conjunto de casillas de verificación que contiene una lista de productos, y el usuario puede seleccionar los 20 o 50 o 200 que quiere comparar, enumerar, lo que tiene. Los valores no estarán en un buen conjunto contiguo; por lo general, estarán dispersos por todas partes (si fuera un rango predeciblemente contiguo, la consulta sería mucho más simple:valores de inicio y final). Así que simplemente elegí 20 valores arbitrarios de la tabla (tratando de mantenerme por debajo, digamos, del 5% del tamaño de la tabla), ordenados al azar. Una manera fácil de crear un VALUES reutilizable cláusula como esta es la siguiente:
DECLARE @x VARCHAR(4000) = '';
SELECT TOP (20) @x += '(' + RTRIM(ProductID) + '),'
FROM dbo.Products ORDER BY NEWID();
SELECT @x; Los resultados (los suyos seguramente variarán):
(725), (524), (357), (405), (477), (821), (323), (526), (952), (473), (442), (450), (735) ),(441),(409),(454),(780),(966),(988),(512),
A diferencia de un INSERT...SELECT directo , esto hace que sea bastante fácil manipular esa salida en una declaración reutilizable para completar nuestros TVP repetidamente con los mismos valores y a lo largo de múltiples iteraciones de prueba:
SET NOCOUNT ON; DECLARE @ClassicTVP dbo.ClassicTVP; DECLARE @InMemoryTVP dbo.InMemoryTVP; INSERT @ClassicTVP(Item) VALUES (725),(524),(357),(405),(477),(821),(323),(526),(952),(473), (442),(450),(735),(441),(409),(454),(780),(966),(988),(512); INSERT @InMemoryTVP(Item) VALUES (725),(524),(357),(405),(477),(821),(323),(526),(952),(473), (442),(450),(735),(441),(409),(454),(780),(966),(988),(512); EXEC dbo.ClassicTVP_Exists @Classic = @ClassicTVP; EXEC dbo.InMemoryTVP_Exists @InMemory = @InMemoryTVP; EXEC dbo.ClassicTVP_Join @Classic = @ClassicTVP; EXEC dbo.InMemoryTVP_Join @InMemory = @InMemoryTVP;
Si ejecutamos este lote con SQL Sentry Plan Explorer, los planes resultantes muestran una gran diferencia:el TVP en memoria puede usar una unión de bucles anidados y 20 búsquedas de índice agrupado de una sola fila, frente a una unión de fusión alimentada con 502 filas por un escaneo de índice agrupado para el TVP clásico. Y en este caso, EXISTS y JOIN produjeron planes idénticos. Esto podría dar como resultado una cantidad mucho mayor de valores, pero sigamos suponiendo que la cantidad de valores será inferior al 5 % del tamaño de la tabla:
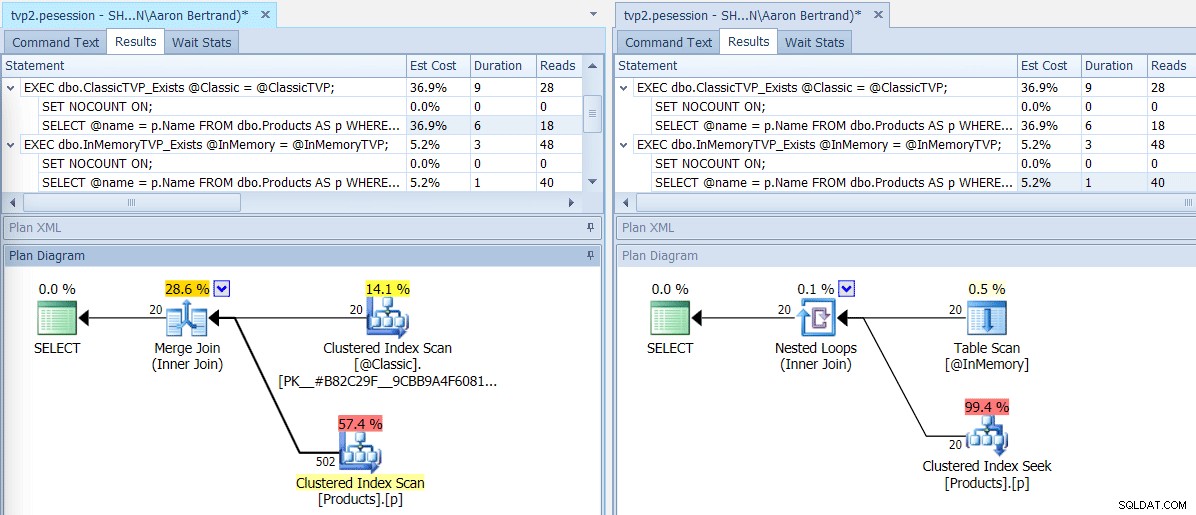 Planes para TVP clásicos y en memoria
Planes para TVP clásicos y en memoria
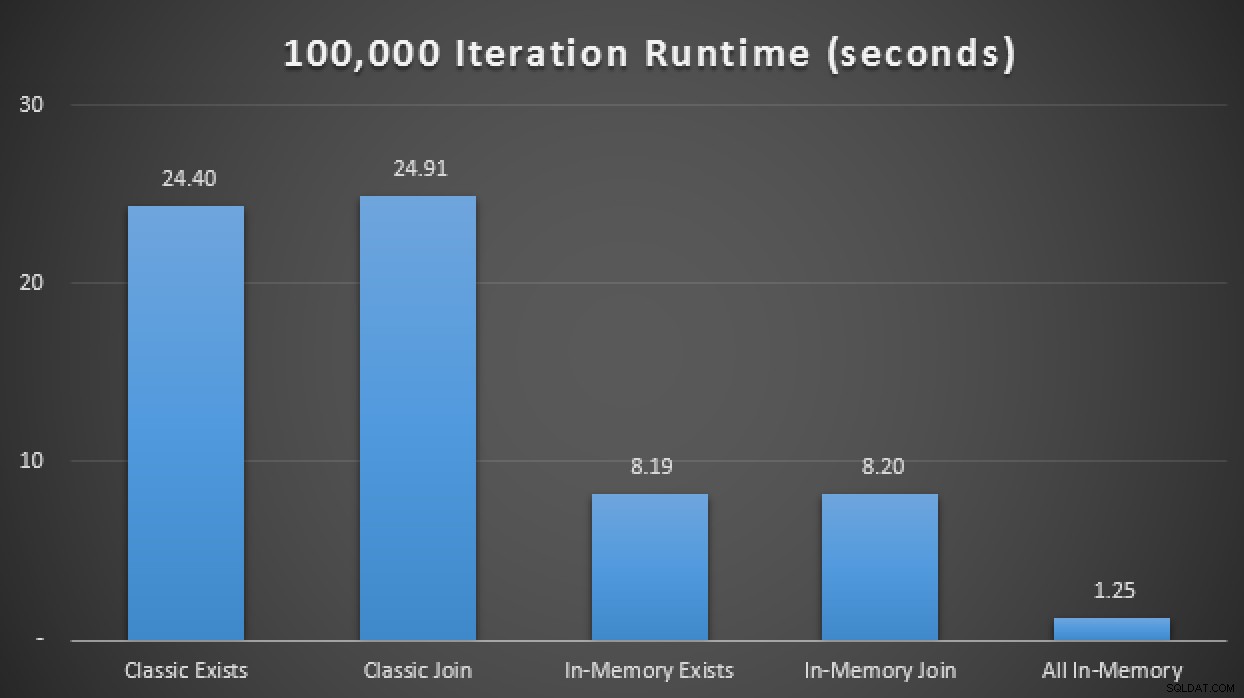 Información sobre herramientas para operadores de exploración/búsqueda, destacando las principales diferencias:Clásico a la izquierda, In- Memoria a la derecha
Información sobre herramientas para operadores de exploración/búsqueda, destacando las principales diferencias:Clásico a la izquierda, In- Memoria a la derecha
Ahora, ¿qué significa esto a escala? Desactivemos cualquier colección de planes de presentación y cambiemos ligeramente el script de prueba para ejecutar cada procedimiento 100 000 veces, capturando el tiempo de ejecución acumulativo manualmente:
DECLARE @i TINYINT = 1, @j INT = 1;
WHILE @i <= 4
BEGIN
SELECT SYSDATETIME();
WHILE @j <= 100000
BEGIN
IF @i = 1
BEGIN
EXEC dbo.ClassicTVP_Exists @Classic = @ClassicTVP;
END
IF @i = 2
BEGIN
EXEC dbo.InMemoryTVP_Exists @InMemory = @InMemoryTVP;
END
IF @i = 3
BEGIN
EXEC dbo.ClassicTVP_Join @Classic = @ClassicTVP;
END
IF @i = 4
BEGIN
EXEC dbo.InMemoryTVP_Join @InMemory = @InMemoryTVP;
END
SET @j += 1;
END
SELECT @i += 1, @j = 1;
END
SELECT SYSDATETIME(); En los resultados, promediados en 10 ejecuciones, vemos que, al menos en este caso de prueba limitado, el uso de un tipo de tabla optimizada para memoria produjo una mejora de aproximadamente 3X en posiblemente la métrica de rendimiento más crítica en OLTP (duración del tiempo de ejecución):
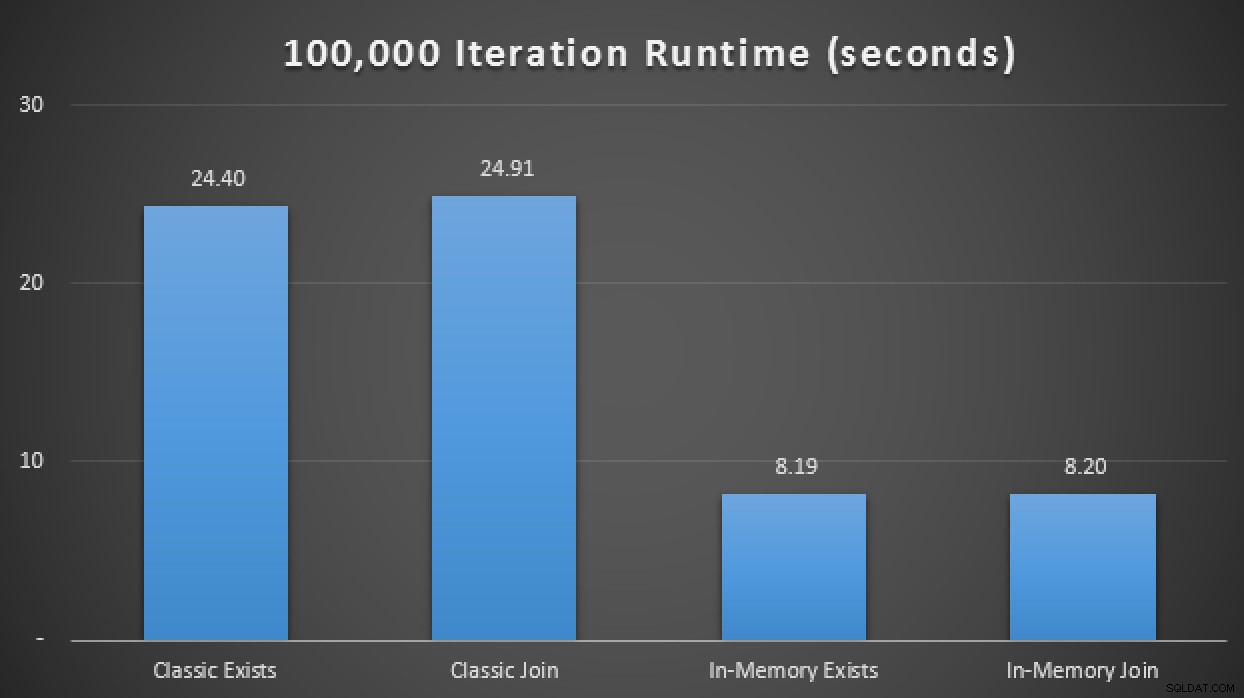
Resultados del tiempo de ejecución que muestran una mejora del triple con TVP en memoria
En memoria + En memoria + En memoria:Inicio en memoria
Ahora que hemos visto lo que podemos hacer simplemente cambiando nuestro tipo de tabla regular a un tipo de tabla optimizada para memoria, veamos si podemos obtener más rendimiento de este mismo patrón de consulta cuando aplicamos la trifecta:una tabla en memoria table, utilizando un procedimiento almacenado optimizado para memoria compilado de forma nativa, que acepta una tabla table en memoria como un parámetro con valores de tabla.
Primero, necesitamos crear una nueva copia de la tabla y completarla desde la tabla local que ya creamos:
CREATE TABLE dbo.Products_InMemory ( ProductID INT NOT NULL, Name NVARCHAR(50) NOT NULL, ProductNumber NVARCHAR(25) NOT NULL, MakeFlag BIT NOT NULL, FinishedGoodsFlag BIT NULL, Color NVARCHAR(15) NULL, SafetyStockLevel SMALLINT NOT NULL, ReorderPoint SMALLINT NOT NULL, StandardCost MONEY NOT NULL, ListPrice MONEY NOT NULL, [Size] NVARCHAR(5) NULL, SizeUnitMeasureCode NCHAR(3) NULL, WeightUnitMeasureCode NCHAR(3) NULL, [Weight] DECIMAL(8, 2) NULL, DaysToManufacture INT NOT NULL, ProductLine NCHAR(2) NULL, [Class] NCHAR(2) NULL, Style NCHAR(2) NULL, ProductSubcategoryID INT NULL, ProductModelID INT NULL, SellStartDate DATETIME NOT NULL, SellEndDate DATETIME NULL, DiscontinuedDate DATETIME NULL, rowguid UNIQUEIDENTIFIER NULL, ModifiedDate DATETIME NULL, PRIMARY KEY NONCLUSTERED HASH (ProductID) WITH (BUCKET_COUNT = 256) ) WITH ( MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA ); INSERT dbo.Products_InMemory SELECT * FROM dbo.Products;
A continuación, creamos un procedimiento almacenado compilado de forma nativa que toma nuestro tipo de tabla optimizada para memoria existente como un TVP:
CREATE PROCEDURE dbo.InMemoryProcedure
@InMemory dbo.InMemoryTVP READONLY
WITH NATIVE_COMPILATION, SCHEMABINDING, EXECUTE AS OWNER
AS
BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english');
DECLARE @Name NVARCHAR(50);
SELECT @Name = Name
FROM dbo.Products_InMemory AS p
INNER JOIN @InMemory AS t
ON t.Item = p.ProductID;
END
GO Un par de advertencias. No podemos usar un tipo de tabla regular, no optimizada para memoria, como parámetro para un procedimiento almacenado compilado de forma nativa. Si lo intentamos, obtenemos:
Mensaje 41323, Nivel 16, Estado 1, Procedimiento InMemoryProcedureEl tipo de tabla 'dbo.ClassicTVP' no es un tipo de tabla optimizado para memoria y no se puede usar en un procedimiento almacenado compilado de forma nativa.
Además, no podemos usar EXISTS patrón aquí tampoco; cuando lo intentamos, obtenemos:
Las subconsultas (consultas anidadas dentro de otra consulta) no son compatibles con los procedimientos almacenados compilados de forma nativa.
Hay muchas otras advertencias y limitaciones con In-Memory OLTP y los procedimientos almacenados compilados de forma nativa, solo quería compartir un par de cosas que pueden parecer obviamente faltantes en las pruebas.
Entonces, al agregar este nuevo procedimiento almacenado compilado de forma nativa a la matriz de prueba anterior, descubrí que, nuevamente, promedió más de 10 ejecuciones, ejecutó las 100,000 iteraciones en solo 1.25 segundos. Esto representa una mejora de aproximadamente 20X con respecto a los TVP regulares y una mejora de 6-7X con respecto a los TVP en memoria que usan tablas y procedimientos tradicionales:
Los resultados del tiempo de ejecución muestran una mejora de hasta 20 veces con In-Memory en general
Conclusión
Si está usando TVP ahora, o está usando patrones que podrían reemplazarse por TVP, debe considerar absolutamente agregar TVP optimizados para memoria a sus planes de prueba, pero tenga en cuenta que es posible que no vea las mismas mejoras en su escenario. (Y, por supuesto, teniendo en cuenta que los TVP en general tienen muchas advertencias y limitaciones, y tampoco son apropiados para todos los escenarios. Erland Sommarskog tiene un excelente artículo sobre los TVP de hoy aquí).
De hecho, puede ver que en el extremo inferior del volumen y la concurrencia, no hay diferencia, pero pruebe a una escala realista. Esta fue una prueba muy simple y artificial en una computadora portátil moderna con un solo SSD, pero cuando se habla de volumen real y/o discos mecánicos giratorios, estas características de rendimiento pueden tener mucho más peso. Viene un seguimiento con algunas demostraciones en tamaños de datos más grandes.