El resaltado de coincidencias es una función que muchas personas desean que la búsqueda de texto completo de SQL Server admita de forma nativa. Aquí es donde puede devolver el documento completo (o un extracto) y señalar las palabras o frases que ayudaron a hacer coincidir ese documento con la búsqueda. Hacerlo de manera eficiente y precisa no es tarea fácil, como descubrí de primera mano.
Como ejemplo de resaltado de aciertos:cuando realiza una búsqueda en Google o Bing, obtiene las palabras clave en negrita tanto en el título como en el extracto (haga clic en cualquiera de las imágenes para ampliarlas):

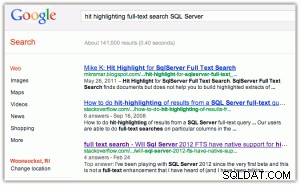
[Aparte, encuentro dos cosas divertidas aquí:(1) que Bing favorece las propiedades de Microsoft mucho más que Google, y (2) que Bing se molesta en devolver 2,2 millones de resultados, muchos de los cuales probablemente sean irrelevantes.]
Estos extractos se denominan comúnmente "fragmentos" o "resúmenes sesgados por consultas". Hemos estado solicitando esta funcionalidad en SQL Server durante algún tiempo, pero aún no hemos recibido buenas noticias de Microsoft:
- Connect #295100:resúmenes de búsqueda de texto completo (resaltado de coincidencias)
- Conexión n.º 722324:Sería bueno que SQL Full Text Search proporcionara soporte para fragmentos/resaltado
La pregunta también aparece en Stack Overflow de vez en cuando:
- Cómo resaltar los resultados de una consulta de texto completo de SQL Server
- ¿Sql Server 2012 FTS tendrá compatibilidad nativa con el resaltado de coincidencias?
Hay algunas soluciones parciales. Este script de Mike Kramar, por ejemplo, producirá un extracto destacado, pero no aplica la misma lógica (como los separadores de palabras específicos del idioma) al documento en sí. También utiliza un conteo absoluto de caracteres, por lo que el extracto puede comenzar y terminar con palabras parciales (como demostraré en breve). Este último es bastante fácil de solucionar, pero otro problema es que carga todo el documento en la memoria, en lugar de realizar ningún tipo de transmisión. Sospecho que en índices de texto completo con documentos de gran tamaño, esto será un impacto de rendimiento notable. Por ahora me centraré en un tamaño de documento promedio relativamente pequeño (35 KB).
Un ejemplo sencillo
Así que digamos que tenemos una tabla muy simple, con un índice de texto completo definido:
CREATE FULLTEXT CATALOG [FTSDemo]; GO CREATE TABLE [dbo].[Document] ( [ID] INT IDENTITY(1001,1) NOT NULL, [Url] NVARCHAR(200) NOT NULL, [Date] DATE NOT NULL, [Title] NVARCHAR(200) NOT NULL, [Content] NVARCHAR(MAX) NOT NULL, CONSTRAINT PK_DOCUMENT PRIMARY KEY(ID) ); GO CREATE FULLTEXT INDEX ON [dbo].[Document] ( [Content] LANGUAGE [English], [Title] LANGUAGE [English] ) KEY INDEX [PK_Document] ON ([FTSDemo]);
Esta tabla se completa con algunos documentos (en concreto, 7), como la Declaración de Independencia y el discurso "Estoy preparado para morir" de Nelson Mandela. Una búsqueda típica de texto completo en esta tabla podría ser:
SELECT d.Title, d.[Content] FROM dbo.[Document] AS d INNER JOIN CONTAINSTABLE(dbo.[Document], *, N'states') AS t ON d.ID = t.[KEY] ORDER BY [RANK] DESC;
El resultado devuelve 4 filas de 7:

Ahora usando una función UDF como la de Mike Kramar:
SELECT d.Title, Excerpt = dbo.HighLightSearch(d.[Content], N'states', 'font-weight:bold', 80) FROM dbo.[Document] AS d INNER JOIN CONTAINSTABLE(dbo.[Document], *, N'states') AS t ON d.ID = t.[KEY] ORDER BY [RANK] DESC;
Los resultados muestran cómo funciona el extracto:a <SPAN> la etiqueta se inyecta en la primera palabra clave y el extracto se extrae en función de un desplazamiento desde esa posición (sin tener en cuenta el uso de palabras completas):

(Nuevamente, esto es algo que se puede arreglar, pero quiero asegurarme de representar adecuadamente lo que está ahí fuera ahora).
Piensa en resaltar
Eran Meyuchas de Interactive Thoughts ha desarrollado un componente que resuelve muchos de estos problemas. ThinkHighlight se implementa como un ensamblado CLR con dos funciones de valor escalar CLR:
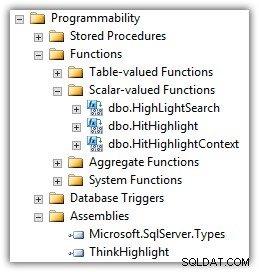
(También verá el UDF de Mike Kramar en la lista de funciones).
Ahora, sin entrar en todos los detalles sobre la instalación y activación del ensamblado en su sistema, así es como se representaría la consulta anterior con ThinkHighlight:
SELECT d.Title,
Excerpt = dbo.HitHighlight(dbo.HitHighlightContext('Document', 'Content', N'states', -1),
'top-fragment', 100, d.ID)
FROM dbo.[Document] AS d
INNER JOIN CONTAINSTABLE(dbo.[Document], *, N'states') AS t
ON d.ID = t.[KEY]
ORDER BY t.[RANK] DESC; Los resultados muestran cómo se resaltan las palabras clave más relevantes y se deriva un extracto basado en palabras completas y una compensación del término resaltado:

Algunas ventajas adicionales que no he demostrado aquí incluyen la capacidad de elegir diferentes estrategias de resumen, controlar la presentación de cada palabra clave (en lugar de todas) usando CSS único, así como soporte para múltiples idiomas e incluso documentos en formato binario (la mayoría de IFilters son compatibles).
Resultados de rendimiento
Inicialmente probé las métricas de tiempo de ejecución para las tres consultas usando SQL Sentry Plan Explorer, contra la tabla de 7 filas. Los resultados fueron:

A continuación, quería ver cómo se compararían en un tamaño de datos mucho mayor. Inserté la tabla en sí misma hasta llegar a las 4000 filas y luego ejecuté la siguiente consulta:
SET STATISTICS TIME ON;
GO
SELECT /* FTS */ d.Title, d.[Content]
FROM dbo.[Document] AS d
INNER JOIN CONTAINSTABLE(dbo.[Document], *, N'states') AS t
ON d.ID = t.[KEY]
ORDER BY [RANK] DESC;
GO
SELECT /* UDF */ d.Title,
Excerpt = dbo.HighLightSearch(d.[Content], N'states', 'font-weight:bold', 100)
FROM dbo.[Document] AS d
INNER JOIN CONTAINSTABLE(dbo.[Document], *, N'states') AS t
ON d.ID = t.[KEY]
ORDER BY [RANK] DESC;
GO
SELECT /* ThinkHighlight */ d.Title,
Excerpt = dbo.HitHighlight(dbo.HitHighlightContext('Document', 'Content', N'states', -1),
'top-fragment', 100, d.ID)
FROM dbo.[Document] AS d
INNER JOIN CONTAINSTABLE(dbo.[Document], *, N'states') AS t
ON d.ID = t.[KEY]
ORDER BY t.[RANK] DESC;
GO
SET STATISTICS TIME OFF;
GO También supervisé sys.dm_exec_memory_grants mientras se ejecutaban las consultas, para detectar cualquier discrepancia en las concesiones de memoria. Resultados con un promedio de más de 10 ejecuciones:
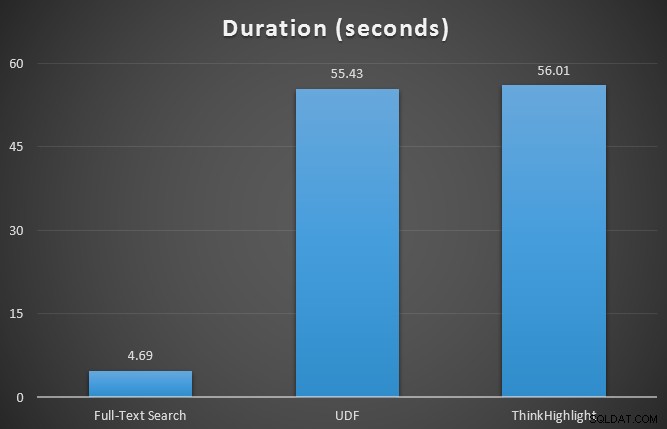
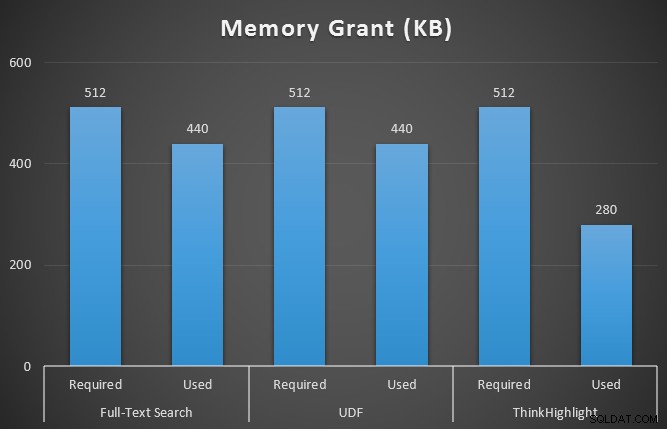
Si bien ambas opciones de resaltado tienen una penalización significativa por no resaltar en absoluto, la solución ThinkHighlight, con opciones más flexibles, representa un costo incremental muy marginal en términos de duración (~1 %), mientras que utiliza una cantidad significativamente menor de memoria (36 %). que la variante UDF.
Conclusión
No debería sorprender que el resaltado de coincidencias sea una operación costosa y, en función de la complejidad de lo que se debe admitir (piense en varios idiomas), que existan muy pocas soluciones. Creo que Mike Kramar ha hecho un excelente trabajo al producir un UDF de referencia que le brinda una buena forma de resolver el problema, pero me sorprendió gratamente encontrar una oferta comercial más sólida, y encontré que era muy estable, incluso en forma beta. Planeo realizar pruebas más exhaustivas utilizando una gama más amplia de tamaños y tipos de documentos. Mientras tanto, si el resaltado de hits es parte de los requisitos de su aplicación, debería probar el UDF de Mike Kramar y considerar la posibilidad de probar ThinkHighlight.