Recientemente lanzamos un nuevo sitio de soporte, donde puede hacer preguntas, enviar comentarios sobre productos o solicitudes de funciones, o abrir tickets de soporte. Parte del objetivo era centralizar todos los lugares donde estábamos ofreciendo asistencia a la comunidad. Esto incluyó el sitio de preguntas y respuestas de SQLPerformance.com, donde Paul White, Hugo Kornelis y muchos otros han estado ayudando a resolver las preguntas más complicadas sobre el ajuste de consultas y el plan de ejecución, desde febrero de 2013. Les digo con sentimientos encontrados que el El sitio de preguntas y respuestas ha sido cerrado.
Sin embargo, hay una ventaja. Ahora puede hacer esas preguntas difíciles en el nuevo foro de soporte. Si está buscando el contenido anterior, bueno, todavía está allí, pero se ve un poco diferente. Por una variedad de razones que no mencionaré hoy, una vez que decidimos cancelar el sitio de preguntas y respuestas original, finalmente decidimos simplemente alojar todo el contenido existente en un sitio de WordPress de solo lectura, en lugar de migrarlo al back-end. del nuevo sitio.
Esta publicación no trata sobre las razones detrás de esa decisión.
Me sentí muy mal por la rapidez con la que el sitio de respuestas tuvo que desconectarse, el DNS cambió y el contenido migró. Dado que se implementó un banner de advertencia en el sitio, pero AnswerHub en realidad no lo hizo visible, esto fue un shock para muchos usuarios. Así que quería asegurarme de mantener adecuadamente la mayor cantidad de contenido posible, y quería que fuera correcto. Esta publicación está aquí porque pensé que sería interesante hablar sobre el proceso real, cuántas piezas diferentes de tecnología estuvieron involucradas para llevarlo a cabo y mostrar el resultado. No espero que ninguno de ustedes se beneficie de este punto a punto, ya que esta es una ruta de migración relativamente oscura, pero más como un ejemplo de vincular un montón de tecnologías para realizar una tarea. También me sirve como un buen recordatorio de que muchas cosas no terminan siendo tan fáciles como parecen antes de comenzar.
El TL;DR es esto:dediqué mucho tiempo y esfuerzo a hacer que el contenido archivado se viera bien, aunque todavía estoy tratando de recuperar las últimas publicaciones que llegaron hacia el final. Usé estas tecnologías:
- Perl
- Servidor SQL
- PowerShell
- Transmitir (FTP)
- HTML
- CSS
- C#
- MarkdownSharp
- phpMyAdmin
- MySQL
De ahí el título. Si quieres una gran parte de los detalles sangrientos, aquí están. Si tiene alguna pregunta o comentario, comuníquese con nosotros o comente a continuación.
AnswerHub proporcionó un archivo de volcado de 665 MB de la base de datos MySQL que alojaba el contenido de preguntas y respuestas. Cada editor que probé se atragantó con él, así que primero tuve que dividirlo en un archivo por tabla usando este práctico script Perl de Jared Cheney. Las tablas que necesitaba se llamaban network11_nodes (preguntas, respuestas y comentarios), network11_authoritables (usuarios) y network11_managed_files (todos los archivos adjuntos, incluidas las cargas de planes):perl extract_sql.pl -t network11_nodes -r dump.sql>> nodes.sql
perl extract_sql.pl -t network11_authoritables -r dump.sql>> users.sql
perl extract_sql.pl -t red11_archivos_administrados -r dump.sql>> archivos.sql
Ahora, esos no fueron extremadamente rápidos de cargar en SSMS, pero al menos allí pude usar Ctrl +H para cambiar (por ejemplo) esto:
CREATE TABLE `network11_managed_files` ( `c_id` bigint(20) NOT NULL, ... ); INSERT INTO `network11_managed_files` (`c_id`, ...) VALUES (1, ...);
A esto:
CREATE TABLE dbo.files ( c_id bigint NOT NULL, ... ); INSERT dbo.files (c_id, ...) VALUES (1, ...);
Entonces podría cargar los datos en SQL Server para poder manipularlos. Y créanme, lo manipulé.
A continuación, tuve que recuperar todos los archivos adjuntos. Mira, el archivo de volcado de MySQL que obtuve del proveedor contenía un montón de INSERT declaraciones, pero ninguno de los archivos de plan reales que los usuarios habían cargado; la base de datos solo tenía las rutas relativas a los archivos. Usé T-SQL para crear una serie de comandos de PowerShell que llamarían a Invoke-WebRequest para recuperar todos los archivos y almacenarlos localmente (muchas formas de despellejar a este gato, pero esto fue muy fácil). De esto:
SELECT 'Invoke-WebRequest -Uri ' + '"$($url)' + RTRIM(c_id) + '-' + c_name + '"' + ' -OutFile "E:\s\temp\' + RTRIM(c_id) + '-' + c_name + '";' FROM dbo.files WHERE LOWER(c_mime_type) LIKE 'application/%';
Eso produjo este conjunto de comandos (junto con un comando previo para resolver este problema de TLS); todo funcionó bastante rápido, pero no recomiendo este enfoque para ninguna combinación de {conjunto masivo de archivos} y/o {bajo ancho de banda}:
$AllProtocols = [System.Net.SecurityProtocolType]'Ssl3,Tls,Tls11,Tls12'; [System.Net.ServicePointManager]::SecurityProtocol = $AllProtocols; $u = "https://answers.sqlperformance.com/s/temp/"; Invoke-WebRequest -Uri "$($u)/1-proc.pesession" -OutFile "E:\s\temp\1-proc.pesession"; Invoke-WebRequest -Uri "$($u)/14-test.pesession" -OutFile "E:\s\temp\14-test.pesession"; Invoke-WebRequest -Uri "$($u)/15-a.QueryAnalysis" -OutFile "E:\s\temp\15-a.QueryAnalysis"; ...
Esto descargó casi todos los archivos adjuntos, pero es cierto que se perdieron algunos debido a errores en el sitio anterior cuando se cargaron inicialmente. Por lo tanto, en el nuevo sitio, es posible que ocasionalmente vea una referencia a un archivo adjunto que no existe.
Luego usé Panic Transmit 5 para subir el temp carpeta al nuevo sitio, y ahora, cuando se carga el contenido, se vincula a /s/temp/1-proc.pesession seguirá funcionando.
A continuación, pasé a SSL. Para solicitar un certificado en el nuevo sitio de WordPress, tuvimos que actualizar el DNS de answers.sqlperformance.com para que apuntara al CNAME en nuestro host de WordPress, WPEngine. Fue una especie de huevo y gallina aquí:tuvimos que sufrir un tiempo de inactividad para las URL https, que fallarían por no tener certificado en el nuevo sitio. Esto estuvo bien porque el certificado en el sitio anterior había caducado, así que en realidad no estábamos peor. También tuve que esperar para hacer esto hasta que hube descargado todos los archivos del sitio anterior, porque una vez que el DNS cambiaba, no habría forma de acceder a ellos excepto a través de alguna puerta trasera.
Mientras esperaba que se propagara el DNS, comencé a trabajar en la lógica para extraer todas las preguntas, respuestas y comentarios en algo consumible en WordPress. Los esquemas de las tablas no solo eran diferentes a los de WordPress, sino que los tipos de entidades también son bastante diferentes. Mi visión era combinar cada pregunta, y cualquier respuesta o comentario, en una sola publicación.
La parte complicada es que la tabla de nodos solo contiene los tres tipos de contenido en la misma tabla, con referencias primarias y originales ("maestras"). Es probable que su código frontal use algún tipo de cursor para recorrer y mostrar el contenido en un orden jerárquico y cronológico. No tendría ese lujo en WordPress, así que tuve que unir el HTML de una sola vez. Solo como ejemplo, así es como se veían los datos:
SELECT c_type, c_id, c_parent, oParent = c_originalParent, c_creation_date, c_title FROM dbo.nodes WHERE c_originalParent = 285; /* c_type c_id c_parent oParent c_creation_date accepted c_title ---------- ------ -------- ------- ---------------- -------- ------------------------- question 285 NULL 285 2013-02-13 16:30 why is the MERGE JOIN ... answer 287 285 285 2013-02-14 01:15 1 NULL comment 289 285 285 2013-02-14 13:35 NULL answer 293 285 285 2013-02-14 18:22 NULL comment 294 287 285 2013-02-14 18:29 NULL comment 298 285 285 2013-02-14 20:40 NULL comment 299 298 285 2013-02-14 18:29 NULL */
No podía ordenar por identificación, tipo o padre, ya que a veces un comentario vendría más tarde en una respuesta anterior, la primera respuesta no siempre sería la respuesta aceptada, y así sucesivamente. Quería esta salida (donde ++ representa un nivel de sangría):
/* c_type c_id c_parent oParent c_creation_date reason ---------- ------ -------- ------- ---------------- ------------------------- question 285 NULL 285 2013-02-13 16:30 question is ALWAYS first ++comment 289 285 285 2013-02-14 13:35 comments on the question before answers answer 287 285 285 2013-02-14 01:15 first answer (accepted = 1) ++comment 294 287 285 2013-02-14 18:29 first comment on first answer ++comment 298 287 285 2013-02-14 20:40 second comment on first answer ++++comment 299 298 285 2013-02-14 18:29 reply to second comment on first answer answer 293 285 285 2013-02-14 18:22 second answer */
Empecé a escribir un CTE recursivo y,
DECLARE @foo TABLE
(
c_type varchar(255),
c_id int,
c_parent int,
oParent int,
accepted bit
);
INSERT @foo(c_type, c_id, c_parent, oParent, accepted) VALUES
('question', 285, NULL, 285, 0),
('answer', 287, 285 , 285, 1),
('comment', 289, 285 , 285, 0),
('comment', 294, 287 , 285, 0),
('comment', 298, 287 , 285, 0),
('comment', 299, 298 , 285, 0),
('answer', 293, 285 , 285, 0);
;WITH cte AS
(
SELECT
lvl = 0,
f.c_type,
f.c_id, f.c_parent, f.oParent,
Sort = CONVERT(varchar(255),RIGHT('00000' + CONVERT(varchar(5),f.c_id),5))
FROM @foo AS f WHERE f.c_parent IS NULL
UNION ALL
SELECT
lvl = c.lvl + 1,
c_type = CONVERT(varchar(255), CASE
WHEN f.accepted = 1 THEN 'accepted answer'
WHEN f.c_type = 'comment' THEN c.c_type + ' ' + f.c_type
ELSE f.c_type
END),
f.c_id, f.c_parent, f.oParent,
Sort = CONVERT(varchar(255),c.Sort + RIGHT('00000' + CONVERT(varchar(5),f.c_id),5))
FROM @foo AS f INNER JOIN cte AS c ON c.c_id = f.c_parent
)
SELECT lvl = CASE lvl WHEN 0 THEN 1 ELSE lvl END, c_type, c_id, c_parent, oParent, Sort
FROM cte
ORDER BY
oParent,
CASE
WHEN c_type LIKE 'question%' THEN 1 -- it's a question *or* a comment on the question
WHEN c_type LIKE 'accepted answer%' THEN 2 -- accepted answer *or* comment on accepted answer
ELSE 3 END,
Sort; Resultados:
/* lvl c_type c_id c_parent oParent Sort ---- --------------------------------- ----------- ----------- ----------- -------------------- 1 question 285 NULL 285 00285 1 question comment 289 285 285 0028500289 1 accepted answer 287 285 285 0028500287 2 accepted answer comment 294 287 285 002850028700294 2 accepted answer comment 298 287 285 002850028700298 3 accepted answer comment comment 299 298 285 00285002870029800299 1 answer 293 285 285 0028500293 */
Genio. Revisé una docena más o menos y me alegré de pasar al siguiente paso. Le he dado las gracias a Andy efusivamente, varias veces, pero déjame hacerlo de nuevo:¡Gracias, Andy!
Ahora que podía devolver todo el conjunto en el orden que me gustaba, tenía que manipular el resultado para aplicar elementos HTML y nombres de clase que me permitieran marcar preguntas, respuestas, comentarios y sangría de manera significativa. El objetivo final era una salida que se veía así (y tenga en cuenta que este es uno de los casos más simples):
<div class="question">
<span class="authorq" title=" Author : author name ">
<i class="fas fa-user"></i>Author name</span>
<span class="createdq" title=" February 13th, 2013 ">
<i class="fas fa-calendar-alt"></i>2013-02-13 16:30:36</span>
<div class=mainbodyq>I don't understand why the merge operator is passing over 4million
rows to the hash match operator when there is only 41K and 19K from other operators.
<div class=attach><i class="fas fa-file"></i>
<a target="_blank" href="/s/temp/254-tmp4DA0.queryanalysis" rel="noopener noreferrer">
/s/temp/254-tmp4DA0.queryanalysis</a>
</div>
</div>
<div class="comment indent1 ">
<div class=linecomment>
<span class="authorc" title=" Author : author name ">
<i class="fas fa-user"></i>author name</span>
<span class="createdc" title=" February 14th, 2013 ">
<i class="fas fa-calendar-alt"></i>2013-02-14 13:35:39</span>
</div>
<div class=mainbodyc>
I am still trying to understand the significant amount of rows from the MERGE operator.
Unless it's a result of a Cartesian product from the two inputs then finally the WHERE
predicate is applied to filter out the unmatched rows leaving the 4 million row count.
</div>
</div>
<div class="answer indent1 [accepted]">
<div class=lineanswer>
<span class="authora" title=" Author : author name ">
<i class="fas fa-user"></i>author name</span>
<span class="createda" title=" February 14th, 2013 ">
<i class="fas fa-calendar-alt"></i>2013-02-14 01:15:42</span>
</div>
<div class=mainbodya>
The reason for the large number of rows can be seen in the Plan Explorer tool tip for
the Merge Join operator:
<img src="/s/temp/259-sp.png" alt="Merge Join tool tip" />
...
</div>
</div>
</div>
No pasaré por la ridícula cantidad de iteraciones por las que tuve que pasar para llegar a una forma confiable de ese resultado para los más de 5000 elementos (lo que se tradujo en casi 1000 publicaciones una vez que todo estuvo pegado). Además de eso, necesitaba generarlos en forma de INSERT declaraciones que luego podía pegar en phpMyAdmin en el sitio de WordPress, lo que significaba adherirse a su extraño diagrama de sintaxis. Esas declaraciones debían incluir otra información adicional requerida por WordPress, pero no presente o precisa en los datos de origen (como post_type ). Y esa consola de administración se agotaba con demasiados datos, por lo que tuve que dividirla en ~750 inserciones a la vez. Aquí está el procedimiento con el que terminé (esto no es realmente para aprender nada específico, solo una demostración de cuánta manipulación de los datos importados fue necesaria):
CREATE /* OR ALTER */ PROCEDURE dbo.BuildMySQLInserts
@LowerBound int = 1,
@UpperBound int = 750
AS
BEGIN
SET NOCOUNT ON;
;WITH CTE AS
(
SELECT lvl = 0,
[type] = CONVERT(varchar(100),f.[type]),
f.id,
f.parent,
f.master_parent,
created = CONVERT(char(10), f.created, 120) + ' '
+ CONVERT(char(8), f.created, 108),
f.state,
Sort = CONVERT(varchar(100),RIGHT('0000000000'
+ CONVERT(varchar(10),f.id),10))
FROM dbo.foo AS f
WHERE f.type = 'question'
AND master_parent BETWEEN @LowerBound AND @UpperBound
UNION ALL
SELECT lvl = c.lvl + 1,
CONVERT(varchar(100),CASE
WHEN f.[state] = '[accepted]' THEN 'accepted answer'
WHEN f.type = 'comment' THEN c.type + ' ' + f.type
ELSE f.type
END),
f.id,
f.parent,
f.master_parent,
created = CONVERT(char(10), f.created, 120) + ' '
+ CONVERT(char(8), f.created, 108),
f.state,
Sort = CONVERT(varchar(100),c.sort + RIGHT('0000000000'
+ CONVERT(varchar(10),f.id),10))
FROM dbo.foo AS f
JOIN CTE AS c ON c.id = f.parent
)
SELECT
master_parent,
prefix = CASE WHEN lvl = 0 THEN
CONVERT(varchar(11), master_parent) + ', 3, ''' + created + ''', '''
+ created + ''',''' END,
bodypre = '<div class="' + COALESCE(c_type, RTRIM(LEFT([type],8)))
+ CASE WHEN c_type <> 'question' THEN ' indent' + RTRIM(lvl)
+ COALESCE(' ' + [state], '') ELSE '' END + '">'
+ CASE WHEN c_type <> 'question' THEN
'<div class=line' + c_type + '>' ELSE '' END
+ '<span class="author' + LEFT(c_type, 1) + '" title=" Author : '
+ REPLACE(REPLACE(Fullname,'''','\'''),'"','')
+ ' "><i class="fas fa-user"></i>' + REPLACE(Fullname,'''','\''') --"
+ '</span> <span class="created' + LEFT(c_type,1) + '" title=" '
+ DATENAME(MONTH, c_creation_date) + ' ' + RTRIM(DAY(c_creation_date))
+ CASE
WHEN DAY(c_creation_date) IN (1,21,31) THEN 'st'
WHEN DAY(c_creation_date) IN (2,22) THEN 'nd'
WHEN DAY(c_creation_date) IN (3,23) THEN 'rd' ELSE 'th' END
+ ', ' + RTRIM(YEAR(c_creation_date))
+ ' "><i class="fas fa-calendar-alt"></i>' + created + '</span>'
+ CASE WHEN c_type <> 'question' THEN '</div>' ELSE '' END,
body = '<div class=mainbody' + left(c_type,1) + '>'
+ REPLACE(REPLACE(c_body, char(39), '\' + char(39)), '’', '\' + char(39)),
bodypost = COALESCE(urls, '') + '</div></div>',--'
+ CASE WHEN c_type = 'question' THEN '</div>' ELSE '' END,
suffix = ''',''' + REPLACE(n.c_title, '''', '\''') + ''','''',''publish'',
''closed'',''closed'','''',''' + REPLACE(n.c_plug, '''', '\''')
+ ''','''','''',''' + created + ''',''' + created + ''','''',0,
''https://answers.sqlperformance.com/?p=' + CONVERT(varchar(11), master_parent)
+ ''', 0, ''post'','''',0);',
rn = RTRIM(ROW_NUMBER() OVER (PARTITION BY master_parent
ORDER BY master_parent,
CASE
WHEN [type] LIKE 'question%' THEN 1
WHEN [type] LIKE 'accepted answer%' THEN 2
ELSE 3
END,
Sort)),
c = RTRIM(COUNT(*) OVER (PARTITION BY master_parent))
FROM CTE
LEFT OUTER JOIN dbo.network11_nodes AS n
ON cte.id = n.c_id
LEFT OUTER JOIN dbo.Users AS u
ON n.c_author = u.UserID
LEFT OUTER JOIN
(
SELECT NodeID, urls = STRING_AGG('<div class=attach>
<i class="fas fa-file'
+ CASE WHEN c_mime_type IN ('image/jpeg','image/png')
THEN '-image' ELSE '' END
+ '"></i><a target="_blank" href=' + url + ' rel="noopener noreferrer">' + url + '</a></div>', '\n')
FROM dbo.Attachments
GROUP BY NodeID
) AS a
ON n.c_id = a.NodeID
ORDER BY master_parent,
CASE
WHEN [type] LIKE 'question%' THEN 1
WHEN [type] LIKE 'accepted answer%' THEN 2
ELSE 3
END,
Sort;
END
GO El resultado de eso no está completo y aún no está listo para incluirse en WordPress:
 Salida de muestra (haga clic para ampliar)
Salida de muestra (haga clic para ampliar)
Necesitaría ayuda adicional de C# para convertir el contenido real (incluida la reducción) en HTML y CSS que podría controlar mejor, y escribir el resultado (un montón de INSERT declaraciones que incluían un montón de código HTML) a archivos en el disco que podía abrir y pegar en phpMyAdmin. Para el HTML, texto sin formato + descuento que comenzaba así:
SELECCIONA algo de dbo.sometable;
[1]:https://otro lugar
Tendría que convertirse en esto:
Hay una publicación de blog aquí que habla de ello, y también esta publicación .
SELECCIONE algo de dbo.sometable; Para lograr esto, recluté la ayuda de MarkdownSharp, una biblioteca de código abierto que se originó en Stack Overflow y que maneja gran parte de la conversión de rebajas a HTML. Se ajustaba bien a mis necesidades, pero no perfecto; Todavía tendría que realizar más manipulaciones:
- MarkdownSharp no permite cosas como
target=_blank, por lo que tendría que inyectarlos yo mismo después del procesamiento; - code (cualquier cosa prefijada con cuatro espacios) hereda
using System.Text; using System.Data; using System.Data.SqlClient; using MarkdownSharp; using System.IO; namespace AnswerHubMigrator { class Program { static void Main(string[] args) { StringBuilder output; string suffix = ""; string thisfile = ""; // pass two arguments on the command line, e.g. 1, 750 int LowerBound = int.Parse(args[0]); int UpperBound = int.Parse(args[1]); // auto-expand URLs, and only accept bold/italic markdown // when it completely surrounds an entire word var options = new MarkdownOptions { AutoHyperlink = true, StrictBoldItalic = true }; MarkdownSharp.Markdown mark = new MarkdownSharp.Markdown(options); using (var conn = new SqlConnection("Server=.\\SQL2017;Integrated Security=true")) using (var cmd = new SqlCommand("MigrateDB.dbo.BuildMySQLInserts", conn)) { cmd.CommandType = CommandType.StoredProcedure; cmd.Parameters.Add("@LowerBound", SqlDbType.Int).Value = LowerBound; cmd.Parameters.Add("@UpperBound", SqlDbType.Int).Value = UpperBound; conn.Open(); using (var reader = cmd.ExecuteReader()) { // use a StringBuilder to dump output to a file output = new StringBuilder(); while (reader.Read()) { // on first pass, make a new delete/insert // delete is to make the commands idempotent if (reader["rn"].Equals("1")) { // for each master parent, I would create a // new WordPress post, inheriting the parent ID output.Append("DELETE FROM `wp_posts` WHERE ID = "); output.Append(reader["master_parent"].ToString()); output.Append("; INSERT INTO `wp_posts` (`ID`, `post_author`, "); output.Append("`post_date`, `post_date_gmt`, `post_content`, "); output.Append("`post_title`, `post_excerpt`, `post_status`, "); output.Append("`comment_status`, `ping_status`, `post_password`,"); output.Append(" `post_name`, `to_ping`, `pinged`, `post_modified`,"); output.Append(" `post_modified_gmt`, `post_content_filtered`, "); output.Append("`post_parent`, `guid`, `menu_order`, `post_type`, "); output.Append("`post_mime_type`, `comment_count`) VALUES ("); // I'm sure some of the above columns are optional, but identifying // those would not be a valuable use of time IMHO output.Append(reader["prefix"]); // hold on to the additional values until last row suffix = reader["suffix"].ToString(); } // manipulate the body content to be WordPress and INSERT statement-friendly string body = reader["body"].ToString().Replace(@"\n", "\n"); body = mark.Transform(body).Replace("href=", "target=_blank href="); body = body.Replace("<p>", "").Replace("</p>", ""); body = body.Replace("<pre><code>", "<pre lang=\"tsql\">"); body = body.Replace("</code></"+"pre>", "</"+"pre>"); body = body.Replace(@"'", "\'").Replace(@"’", "\'"); body = reader["bodypre"].ToString() + body.Replace("\n", @"\n"); body += reader["bodypost"].ToString(); body = body.Replace("<", "<").Replace(">", ">"); output.Append(body); // if we are on the last row, add additional values from the first row if (reader["c"].Equals(reader["rn"])) { output.Append(suffix); } } thisfile = UpperBound.ToString(); using (StreamWriter w = new StreamWriter(@"C:\wp\" + thisfile + ".sql")) { w.WriteLine(output); w.Flush(); } } } } } }Sí, ese es un montón de código feo, pero finalmente me llevó al conjunto de resultados que no harían vomitar a phpMyAdmin, y que WordPress se presentaría bien (suficiente). Simplemente llamé al programa C# varias veces con los diferentes rangos de parámetros:
AnswerHubMigrator 1 750 AnswerHubMigrator 751 1500 AnswerHubMigrator 1501 2250 ...
Luego abrí cada uno de los archivos, los pegué en phpMyAdmin y presioné IR:
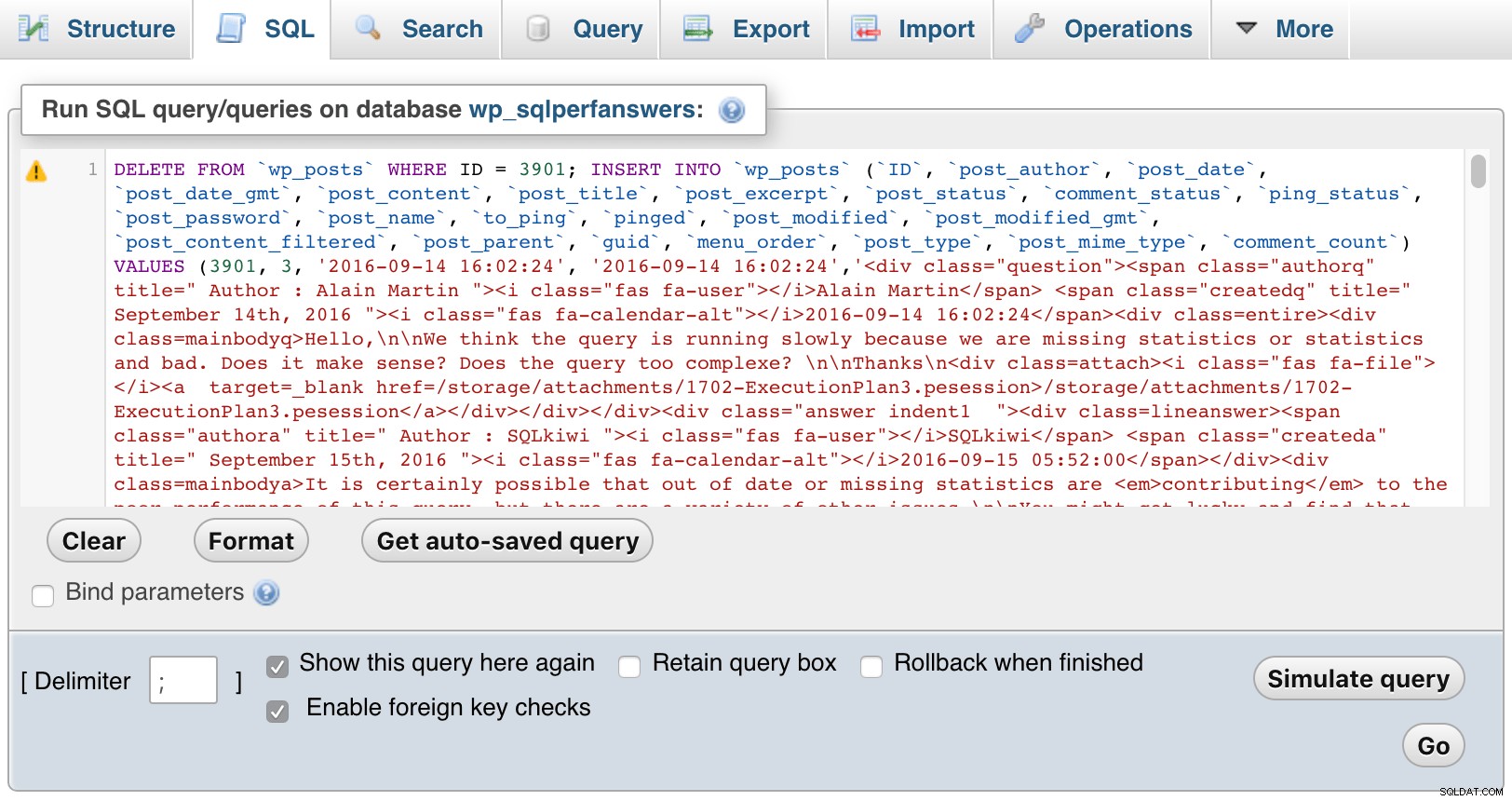 phpMyAdmin (haga clic para agrandar)
phpMyAdmin (haga clic para agrandar) Por supuesto, tuve que agregar algo de CSS dentro de WordPress para ayudar a diferenciar entre preguntas, comentarios y respuestas, y también sangrar los comentarios para mostrar las respuestas tanto a las preguntas como a las respuestas, anidar los comentarios que respondían a los comentarios, etc. Así es como se ve un extracto cuando profundiza en las preguntas de un mes:
 Cuadro de preguntas (haga clic para agrandar)
Cuadro de preguntas (haga clic para agrandar) Y luego una publicación de ejemplo, que muestra imágenes incrustadas, varios archivos adjuntos, comentarios anidados y una respuesta:
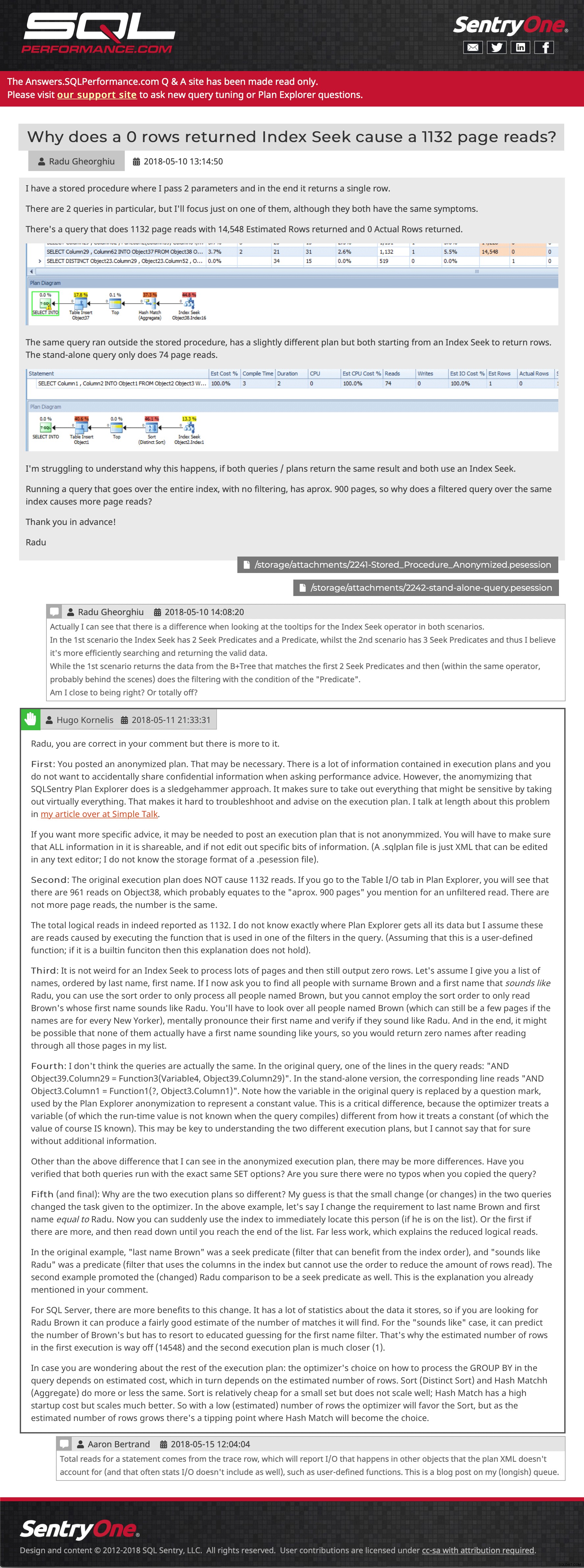 Pregunta y respuesta de muestra (haga clic para ir allí)
Pregunta y respuesta de muestra (haga clic para ir allí) Todavía estoy tratando de recuperar algunas publicaciones que se enviaron al sitio después de que se realizó la última copia de seguridad, pero lo invito a navegar. Háganos saber si encuentra algo que falta o está fuera de lugar, o simplemente díganos que el contenido aún le es útil. Esperamos reintroducir la funcionalidad de carga de planes desde Plan Explorer, pero requerirá un poco de trabajo de API en el nuevo sitio de soporte, por lo que no tengo una ETA para usted hoy.
- Respuestas.SQLPerformance.com