Para el martes de T-SQL de este mes, Steve Jones (@way0utwest) nos pidió que hablemos sobre nuestras mejores o peores experiencias con disparadores. Si bien es cierto que los disparadores a menudo están mal vistos e incluso son temidos, tienen varios casos de uso válidos, que incluyen:
- Auditoría (antes de 2016 SP1, cuando esta función pasó a ser gratuita en todas las ediciones)
- Aplicación de las reglas comerciales y la integridad de los datos, cuando no se pueden implementar fácilmente en las restricciones y no desea que dependan del código de la aplicación o de las propias consultas DML.
- Mantenimiento de versiones históricas de los datos (antes de Change Data Capture, Change Tracking y Temporal Tables)
- Alertas en cola o procesamiento asíncrono en respuesta a un cambio específico
- Permitir modificaciones a las vistas (a través de activadores INSTEAD OF)
No es una lista exhaustiva, solo un resumen rápido de algunos escenarios que he experimentado en los que los factores desencadenantes fueron la respuesta correcta en ese momento.
Cuando los disparadores son necesarios, siempre me gusta explorar el uso de disparadores EN LUGAR DE en lugar de disparadores DESPUÉS. Sí, son un poco más de trabajo inicial*, pero tienen algunos beneficios bastante importantes. En teoría, al menos, la perspectiva de evitar que suceda una acción (y sus consecuencias de registro) parece mucho más eficiente que dejar que todo suceda y luego deshacerlo.
*Digo esto porque tiene que codificar la declaración DML nuevamente dentro del disparador; es por eso que no se les llama ANTES de desencadenantes. La distinción es importante aquí, ya que algunos sistemas implementan disparadores verdaderos ANTES, que simplemente se ejecutan primero. En SQL Server, un disparador INSTEAD OF cancela efectivamente la declaración que provocó que se disparara.
Supongamos que tenemos una tabla simple para almacenar nombres de cuentas. En este ejemplo, crearemos dos tablas para poder comparar dos activadores diferentes y su impacto en la duración de la consulta y el uso del registro. El concepto es que tenemos una regla comercial:el nombre de la cuenta no está presente en otra tabla, lo que representa nombres "malos", y el disparador se usa para hacer cumplir esta regla. Aquí está la base de datos:
USE [master];
GO
CREATE DATABASE [tr] ON (name = N'tr_dat', filename = N'C:\temp\tr.mdf', size = 4096MB)
LOG ON (name = N'tr_log', filename = N'C:\temp\tr.ldf', size = 2048MB);
GO
ALTER DATABASE [tr] SET RECOVERY FULL;
GO Y las tablas:
USE [tr]; GO CREATE TABLE dbo.Accounts_After ( AccountID int PRIMARY KEY, name sysname UNIQUE, filler char(255) NOT NULL DEFAULT '' ); CREATE TABLE dbo.Accounts_Instead ( AccountID int PRIMARY KEY, name sysname UNIQUE, filler char(255) NOT NULL DEFAULT '' ); CREATE TABLE dbo.InvalidNames ( name sysname PRIMARY KEY ); INSERT dbo.InvalidNames(name) VALUES (N'poop'),(N'hitler'),(N'boobies'),(N'cocaine');
Y, por último, los disparadores. Para simplificar, solo estamos tratando con inserciones, y tanto en el caso posterior como en el lugar, solo vamos a abortar todo el lote si algún nombre viola nuestra regla:
CREATE TRIGGER dbo.tr_Accounts_After
ON dbo.Accounts_After
AFTER INSERT
AS
BEGIN
IF EXISTS
(
SELECT 1 FROM inserted AS i
INNER JOIN dbo.InvalidNames AS n
ON i.name = n.name
)
BEGIN
RAISERROR(N'Tsk tsk.', 11, 1);
ROLLBACK TRANSACTION;
RETURN;
END
END
GO
CREATE TRIGGER dbo.tr_Accounts_Instead
ON dbo.Accounts_After
INSTEAD OF INSERT
AS
BEGIN
IF EXISTS
(
SELECT 1 FROM inserted AS i
INNER JOIN dbo.InvalidNames AS n
ON i.name = n.name
)
BEGIN
RAISERROR(N'Tsk tsk.', 11, 1);
RETURN;
END
ELSE
BEGIN
INSERT dbo.Accounts_Instead(AccountID, name, filler)
SELECT AccountID, name, filler FROM inserted;
END
END
GO Ahora, para probar el rendimiento, solo intentaremos insertar 100 000 nombres en cada tabla, con una tasa de error predecible del 10 %. En otras palabras, 90 000 son nombres correctos, los otros 10 000 fallan la prueba y hacen que el disparador retroceda o no se inserte según el lote.
Primero, necesitamos hacer algo de limpieza antes de cada lote:
TRUNCATE TABLE dbo.Accounts_Instead; TRUNCATE TABLE dbo.Accounts_After; GO CHECKPOINT; CHECKPOINT; BACKUP LOG triggers TO DISK = N'C:\temp\tr.trn' WITH INIT, COMPRESSION; GO
Antes de comenzar con la carne de cada lote, contaremos las filas en el registro de transacciones y mediremos el tamaño y el espacio libre. Luego pasaremos por un cursor para procesar las 100.000 filas en orden aleatorio, intentando insertar cada nombre en la tabla correspondiente. Cuando hayamos terminado, volveremos a medir el número de filas y el tamaño del registro y comprobaremos la duración.
SET NOCOUNT ON;
DECLARE @batch varchar(10) = 'After', -- or After
@d datetime2(7) = SYSUTCDATETIME(),
@n nvarchar(129),
@i int,
@err nvarchar(512);
-- measure before and again when we're done:
SELECT COUNT(*) FROM sys.fn_dblog(NULL, NULL);
SELECT CurrentSizeMB = size/128.0,
FreeSpaceMB = (size-CONVERT(int, FILEPROPERTY(name,N'SpaceUsed')))/128.0
FROM sys.database_files
WHERE name = N'tr_log';
DECLARE c CURSOR LOCAL FAST_FORWARD
FOR
SELECT name, i = ROW_NUMBER() OVER (ORDER BY NEWID())
FROM
(
SELECT DISTINCT TOP (90000) LEFT(o.name,64) + '/' + LEFT(c.name,63)
FROM sys.all_objects AS o
CROSS JOIN sys.all_columns AS c
UNION ALL
SELECT TOP (10000) N'boobies' FROM sys.all_columns
) AS x (name)
ORDER BY i;
OPEN c;
FETCH NEXT FROM c INTO @n, @i;
WHILE @@FETCH_STATUS = 0
BEGIN
BEGIN TRY
IF @batch = 'After'
INSERT dbo.Accounts_After(AccountID,name) VALUES(@i,@n);
IF @batch = 'Instead'
INSERT dbo.Accounts_Instead(AccountID,name) VALUES(@i,@n);
END TRY
BEGIN CATCH
SET @err = ERROR_MESSAGE();
END CATCH
FETCH NEXT FROM c INTO @n, @i;
END
-- measure again when we're done:
SELECT COUNT(*) FROM sys.fn_dblog(NULL, NULL);
SELECT duration = DATEDIFF(MILLISECOND, @d, SYSUTCDATETIME()),
CurrentSizeMB = size/128.0,
FreeSpaceMB = (size-CAST(FILEPROPERTY(name,N'SpaceUsed') AS int))/128.0
FROM sys.database_files
WHERE name = N'tr_log';
CLOSE c; DEALLOCATE c; Resultados (promedio de 5 ejecuciones de cada lote):
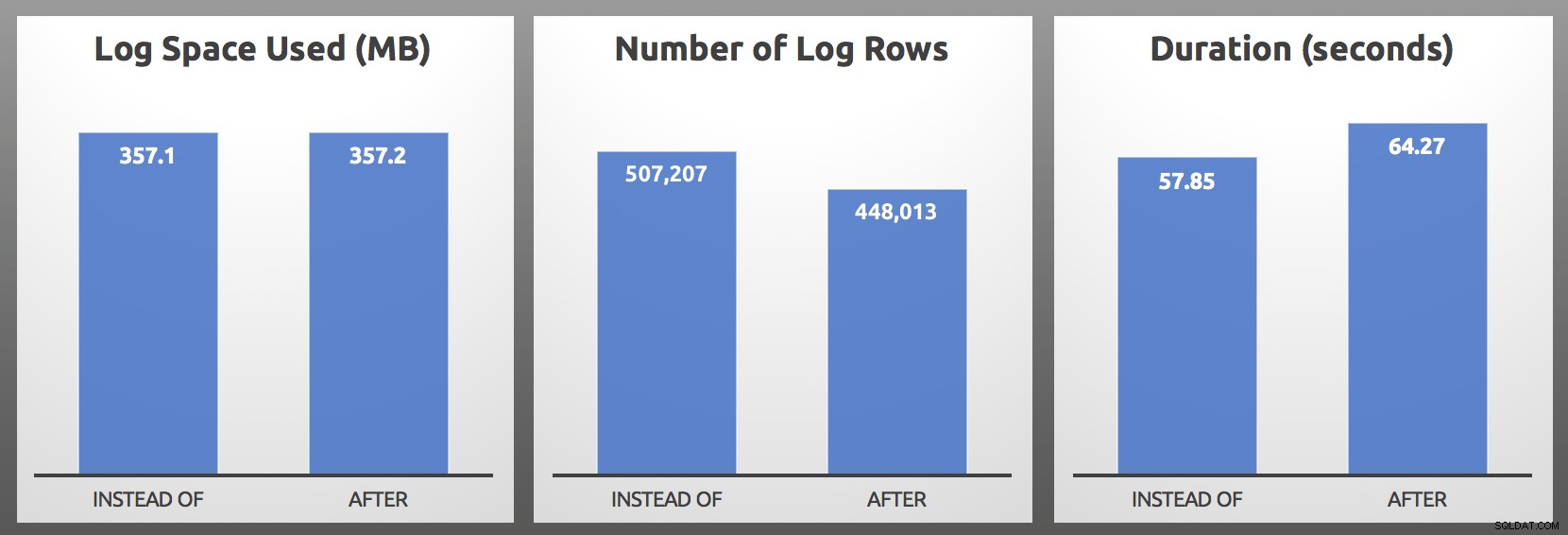 DESPUÉS vs. EN LUGAR DE:Resultados
DESPUÉS vs. EN LUGAR DE:Resultados
En mis pruebas, el uso del registro fue casi idéntico en tamaño, con más de un 10 % más de filas de registro generadas por el activador INSTEAD OF. Investigué un poco al final de cada lote:
SELECT [Operation], COUNT(*) FROM sys.fn_dblog(NULL, NULL) GROUP BY [Operation] ORDER BY [Operation];
Y aquí estaba un resultado típico (resalté los deltas principales):
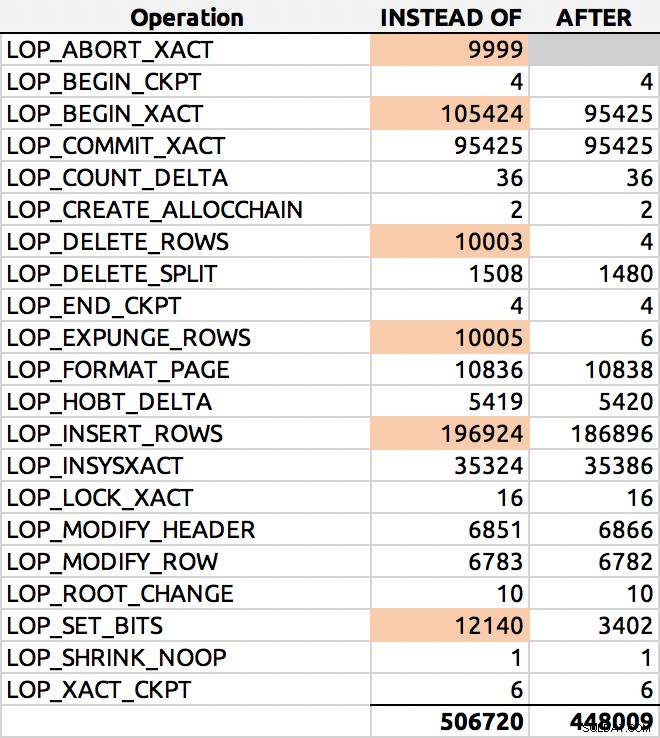 Distribución de filas de registro
Distribución de filas de registro
Profundizaré en eso más profundamente en otro momento.
Pero cuando llegas al grano...
…la métrica más importante casi siempre será duración , y en mi caso, el gatillo INSTEAD OF funcionó al menos 5 segundos más rápido en cada prueba cara a cara. En caso de que todo esto suene familiar, sí, he hablado de ello antes, pero en ese entonces no observé estos mismos síntomas con las filas de registro.
Tenga en cuenta que es posible que este no sea su esquema o carga de trabajo exactos, es posible que tenga un hardware muy diferente, su simultaneidad puede ser mayor y su tasa de fallas puede ser mucho mayor (o menor). Mis pruebas se realizaron en una máquina aislada con mucha memoria y SSD PCIe muy rápidos. Si su registro está en una unidad más lenta, entonces las diferencias en el uso del registro pueden superar las otras métricas y cambiar las duraciones significativamente. Todos estos factores (¡y más!) pueden afectar sus resultados, por lo que debe realizar la prueba en su entorno.
Sin embargo, el punto es que los disparadores INSTEAD OF podrían encajar mejor. Ahora bien, si tan solo pudiéramos obtener activadores EN LUGAR DE DDL...