A veces es difícil administrar una gran cantidad de datos en una empresa, especialmente con el incremento exponencial del análisis de datos y el uso de IoT. Dependiendo del tamaño, esta cantidad de datos podría afectar el rendimiento de sus sistemas y probablemente necesite escalar sus bases de datos o encontrar una forma de solucionarlo. Existen diferentes formas de escalar sus bases de datos PostgreSQL y una de ellas es Sharding. En este blog veremos qué es Sharding y cómo configurarlo en PostgreSQL usando ClusterControl para simplificar la tarea.
¿Qué es fragmentación?
La fragmentación es la acción de optimizar una base de datos al separar los datos de una tabla grande en varias tablas pequeñas. Las tablas más pequeñas son Shards (o particiones). La partición y la fragmentación son conceptos similares. La principal diferencia es que la fragmentación implica que los datos se distribuyen entre varias computadoras, mientras que la partición consiste en agrupar subconjuntos de datos dentro de una sola instancia de base de datos.
Hay dos tipos de Sharding:
-
Fragmentación horizontal:cada tabla nueva tiene el mismo esquema que la tabla grande pero filas únicas. Es útil cuando las consultas tienden a devolver un subconjunto de filas que a menudo se agrupan.
-
Fragmentación vertical:cada nueva tabla tiene un esquema que es un subconjunto del esquema de la tabla original. Es útil cuando las consultas tienden a devolver solo un subconjunto de columnas de los datos.
Veamos un ejemplo:
Tabla Original
| ID | Nombre | Edad | País |
|---|---|---|---|
| 1 | James Smith | 26 | EE.UU. |
| 2 | Mary Johnson | 31 | Alemania |
| 3 | Roberto Williams | 54 | Canadá |
| 4 | Jennifer Brown | 47 | Francia |
fragmentación vertical
| Fragmento1 | Fragmento2 | |||
|---|---|---|---|---|
| ID | Nombre | Edad | ID | País |
| 1 | James Smith | 26 | 1 | EE.UU. |
| 2 | Mary Johnson | 31 | 2 | Alemania |
| 3 | Roberto Williams | 54 | 3 | Canadá |
| 4 | Jennifer Brown | 47 | 4 | Francia |
fragmentación horizontal
| Fragmento1 | Fragmento2 | ||||||
|---|---|---|---|---|---|---|---|
| ID | Nombre | Edad | País | ID | Nombre | Edad | País |
| 1 | James Smith | 26 | EE.UU. | 3 | Roberto Williams | 54 | Canadá |
| 2 | Mary Johnson | 31 | Alemania | 4 | Jennifer Brown | 47 | Francia |
Ahora que revisamos algunos conceptos de fragmentación, avancemos al siguiente paso.
¿Cómo implementar un clúster de PostgreSQL?
Usaremos ClusterControl para esta tarea. Si aún no usa ClusterControl, puede instalarlo e implementar o importar su base de datos PostgreSQL actual seleccionando la opción "Importar" y siga los pasos para aprovechar todas las funciones de ClusterControl, como copias de seguridad, conmutación por error automática, alertas, monitoreo y más. .
Para realizar una implementación desde ClusterControl, simplemente seleccione la opción "Implementar" y siga las instrucciones que aparecen.
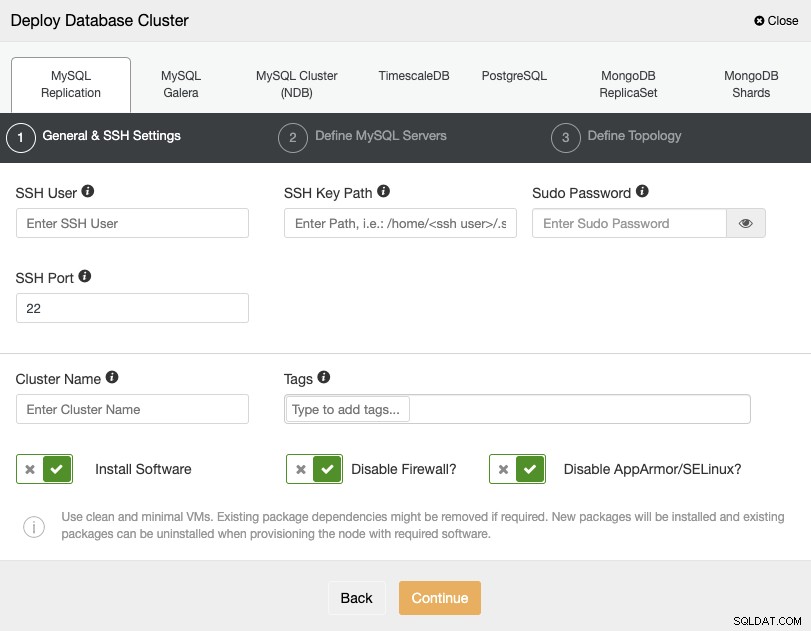
Al seleccionar PostgreSQL, debe especificar su Usuario, Clave o Contraseña, y Puerto para conectarse por SSH a sus servidores. También puede agregar un nombre para su nuevo clúster y, si lo desea, también puede usar ClusterControl para instalar el software y las configuraciones correspondientes.
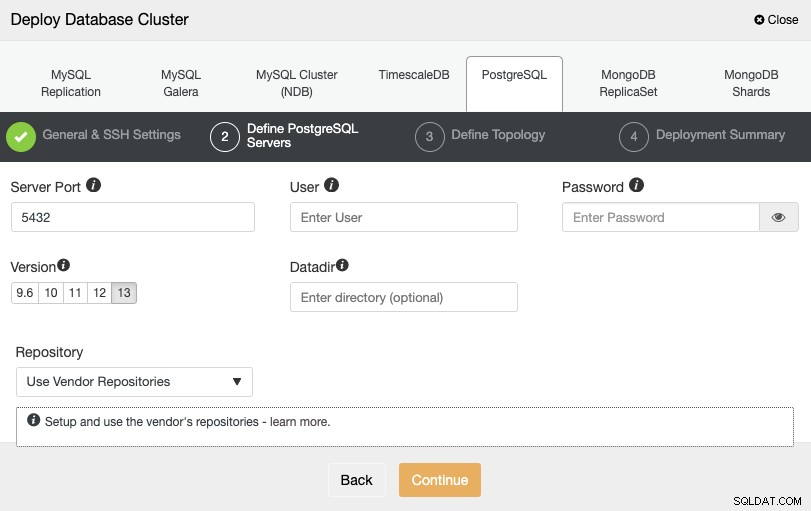
Después de configurar la información de acceso SSH, debe definir las credenciales de la base de datos , versión y datadir (opcional). También puede especificar qué repositorio usar.
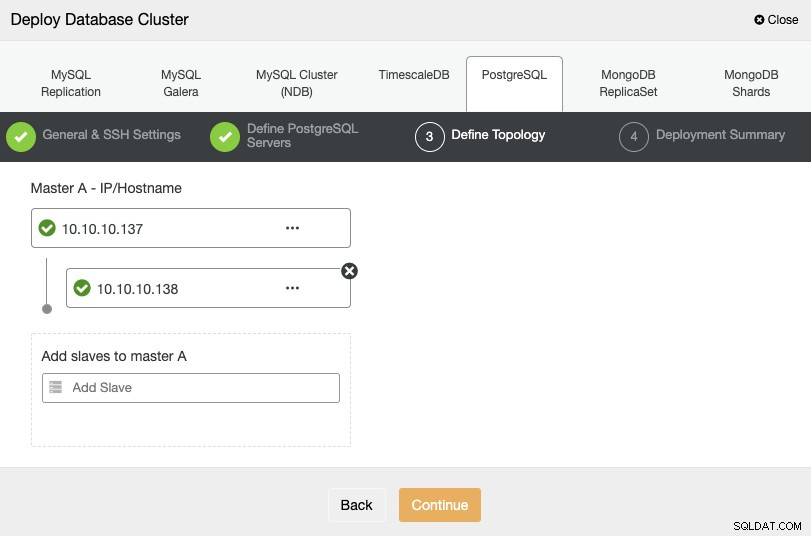
Para el siguiente paso, debe agregar sus servidores al clúster que va a crear utilizando la dirección IP o el nombre de host.
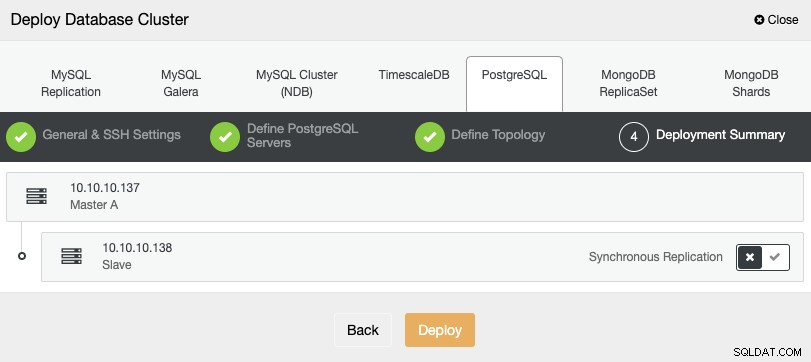
En el último paso, puede elegir si su replicación será Síncrona o Asíncrono, y luego simplemente presione "Implementar".
Una vez finalizada la tarea, verá su nuevo clúster de PostgreSQL en la pantalla principal de ClusterControl.

Ahora que ha creado su clúster, puede realizar varias tareas en él como agregar un equilibrador de carga (HAProxy), un agrupador de conexiones (pgBouncer) o una nueva réplica.
Repita el proceso para tener al menos dos clústeres de PostgreSQL separados para configurar Sharding, que es el siguiente paso.
¿Cómo configurar la fragmentación de PostgreSQL?
Ahora configuraremos Sharding usando PostgreSQL Partitions y Foreign Data Wrapper (FDW). Esta funcionalidad permite que PostgreSQL acceda a datos almacenados en otros servidores. Es una extensión disponible por defecto en la instalación común de PostgreSQL.
Usaremos el siguiente entorno:
Servers: Shard1 - 10.10.10.137, Shard2 - 10.10.10.138
Database User: admindb
Table: customersPara habilitar la extensión FDW, solo necesita ejecutar el siguiente comando en su servidor principal, en este caso, Shard1:
postgres=# CREATE EXTENSION postgres_fdw;
CREATE EXTENSIONAhora vamos a crear la tabla de clientes particionados por fecha de registro:
postgres=# CREATE TABLE customers (
id INT NOT NULL,
name VARCHAR(30) NOT NULL,
registered DATE NOT NULL
)
PARTITION BY RANGE (registered);Y las siguientes particiones:
postgres=# CREATE TABLE customers_2021
PARTITION OF customers
FOR VALUES FROM ('2021-01-01') TO ('2022-01-01');
postgres=# CREATE TABLE customers_2020
PARTITION OF customers
FOR VALUES FROM ('2020-01-01') TO ('2021-01-01');Estas particiones son locales. Ahora insertemos algunos valores de prueba y comprobémoslos:
postgres=# INSERT INTO customers (id, name, registered) VALUES (1, 'James', '2020-05-01');
postgres=# INSERT INTO customers (id, name, registered) VALUES (2, 'Mary', '2021-03-01');Aquí puede consultar la partición principal para ver todos los datos:
postgres=# SELECT * FROM customers;
id | name | registered
----+-------+------------
1 | James | 2020-05-01
2 | Mary | 2021-03-01
(2 rows)O incluso consultar la partición correspondiente:
postgres=# SELECT * FROM customers_2021;
id | name | registered
----+------+------------
2 | Mary | 2021-03-01
(1 row)
postgres=# SELECT * FROM customers_2020;
id | name | registered
----+-------+------------
1 | James | 2020-05-01
(1 row)Como puede ver, los datos se insertaron en diferentes particiones, según la fecha de registro. Ahora, en el nodo remoto, en este caso Shard2, creemos otra tabla:
postgres=# CREATE TABLE customers_2019 (
id INT NOT NULL,
name VARCHAR(30) NOT NULL,
registered DATE NOT NULL);Debe crear este servidor Shard2 en Shard1 de esta manera:
postgres=# CREATE SERVER shard2 FOREIGN DATA WRAPPER postgres_fdw OPTIONS (host '10.10.10.138', dbname 'postgres');Y el usuario para acceder:
postgres=# CREATE USER MAPPING FOR admindb SERVER shard2 OPTIONS (user 'admindb', password 'Passw0rd');Ahora, cree la TABLA EXTRANJERA en Shard1:
postgres=# CREATE FOREIGN TABLE customers_2019
PARTITION OF customers
FOR VALUES FROM ('2019-01-01') TO ('2020-01-01')
SERVER shard2;E insertemos datos en esta nueva tabla remota desde Shard1:
postgres=# INSERT INTO customers (id, name, registered) VALUES (3, 'Robert', '2019-07-01');
INSERT 0 1
postgres=# INSERT INTO customers (id, name, registered) VALUES (4, 'Jennifer', '2019-11-01');
INSERT 0 1Si todo salió bien, debería poder acceder a los datos de Shard1 y Shard2:
Shard1:
postgres=# SELECT * FROM customers;
id | name | registered
----+----------+------------
3 | Robert | 2019-07-01
4 | Jennifer | 2019-11-01
1 | James | 2020-05-01
2 | Mary | 2021-03-01
(4 rows)
postgres=# SELECT * FROM customers_2019;
id | name | registered
----+----------+------------
3 | Robert | 2019-07-01
4 | Jennifer | 2019-11-01
(2 rows)Fragmento2:
postgres=# SELECT * FROM customers_2019;
id | name | registered
----+----------+------------
3 | Robert | 2019-07-01
4 | Jennifer | 2019-11-01
(2 rows)Eso es todo. Ahora está utilizando Sharding en su clúster de PostgreSQL.
Conclusión
El particionamiento y fragmentación en PostgreSQL son buenas características. Te ayuda en caso de que necesites separar datos en una gran tabla para mejorar el rendimiento, o incluso para depurar datos de forma sencilla, entre otras situaciones. Un punto importante cuando usa Sharding es elegir una buena clave de fragmento que distribuya los datos entre los nodos de la mejor manera. Además, puede usar ClusterControl para simplificar la implementación de PostgreSQL y aprovechar algunas características como monitoreo, alertas, conmutación por error automática, copia de seguridad, recuperación de un punto en el tiempo y más.