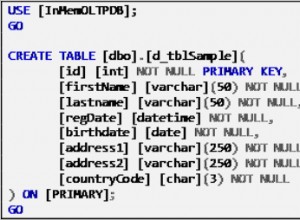
PostgreSQL es una de las bases de datos de código abierto más avanzadas del mundo con muchas funciones excelentes. Uno de ellos es Streaming Replication (Replicación física) que se introdujo en PostgreSQL 9.0. Se basa en registros XLOG que se transfieren al servidor de destino y se aplican allí. Sin embargo, está basado en clústeres y no podemos hacer una replicación de una sola base de datos o de un solo objeto (replicación selectiva). A lo largo de los años, hemos dependido de herramientas externas como Slony, Bucardo, BDR, etc. para la replicación selectiva o parcial, ya que no había ninguna característica a nivel central hasta PostgreSQL 9.6. Sin embargo, a PostgreSQL 10 se le ocurrió una función llamada Logical Replication, a través de la cual podemos realizar una replicación a nivel de base de datos/objeto.
La replicación lógica replica los cambios de los objetos en función de su identidad de replicación, que suele ser una clave principal. Es diferente a la replicación física, en la que la replicación se basa en bloques y la replicación byte a byte. La replicación lógica no necesita una copia binaria exacta en el lado del servidor de destino, y tenemos la capacidad de escribir en el servidor de destino a diferencia de la replicación física. Esta función se origina en el módulo pglogical.
En esta publicación de blog, vamos a discutir:
- Cómo funciona - Arquitectura
- Características
- Casos de uso:cuando es útil
- Limitaciones
- Cómo lograrlo
Cómo funciona:arquitectura de replicación lógica
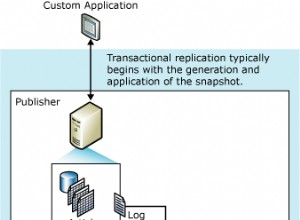
La replicación lógica implementa un concepto de publicación y suscripción (publicación y suscripción). A continuación se muestra un diagrama arquitectónico de nivel superior sobre cómo funciona.
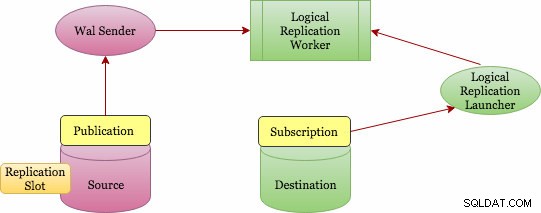
Arquitectura básica de replicación lógica
La publicación se puede definir en el servidor maestro y el nodo en el que se define se denomina "editor". La publicación es un conjunto de cambios de una sola tabla o grupo de tablas. Está a nivel de base de datos y cada publicación existe en una base de datos. Se pueden agregar varias tablas a una sola publicación y una tabla puede estar en varias publicaciones. Debe agregar objetos explícitamente a una publicación, excepto si elige la opción "TODAS LAS TABLAS", que necesita un privilegio de superusuario.
Puede limitar los cambios de objetos (INSERTAR, ACTUALIZAR y ELIMINAR) para que se repliquen. De forma predeterminada, todos los tipos de operaciones se replican. Debe tener una identidad de replicación configurada para el objeto que desea agregar a una publicación. Esto es para replicar las operaciones UPDATE y DELETE. La identidad de replicación puede ser una clave principal o un índice único. Si la tabla no tiene una clave principal o un índice único, entonces se puede configurar para replicar la identidad "completa" en la que toma todas las columnas como clave (toda la fila se convierte en clave).
Puede crear una publicación utilizando CREAR PUBLICACIÓN. Algunos comandos prácticos están cubiertos en la sección "Cómo lograrlo".
La suscripción se puede definir en el servidor de destino y el nodo en el que se define se denomina "suscriptor". La conexión a la base de datos de origen se define en la suscripción. El nodo de suscriptor es el mismo que cualquier otra base de datos de postgres independiente, y también puede usarlo como una publicación para suscripciones adicionales.
La suscripción se agrega usando CREAR SUSCRIPCIÓN y se puede detener/reanudar en cualquier momento usando el comando ALTERAR SUSCRIPCIÓN y eliminar usando DROP SUSCRIPCIÓN.
Una vez que se crea una suscripción, la replicación lógica copia una instantánea de los datos en la base de datos del editor. Una vez hecho esto, espera los cambios delta y los envía al nodo de suscripción tan pronto como ocurren.
Sin embargo, ¿cómo se recopilan los cambios? ¿Quién los envía al objetivo? ¿Y quién las aplica en el blanco? La replicación lógica también se basa en la misma arquitectura que la replicación física. Se implementa mediante los procesos "walsender" y "apply". Como se basa en la decodificación WAL, ¿quién inicia la decodificación? El proceso walsender es responsable de iniciar la decodificación lógica de WAL y carga el complemento de decodificación lógica estándar (pgoutput). El complemento transforma los cambios leídos de WAL al protocolo de replicación lógica y filtra los datos de acuerdo con la especificación de publicación. Luego, los datos se transfieren continuamente mediante el protocolo de replicación de transmisión al trabajador de aplicación, que asigna los datos a las tablas locales y aplica los cambios individuales a medida que se reciben, en el orden transaccional correcto.
Registra todos estos pasos en archivos de registro mientras lo configura. Podemos ver los mensajes en la sección "Cómo lograrlo" más adelante en la publicación.
Características de la replicación lógica
- La replicación lógica replica los objetos de datos en función de su identidad de replicación (generalmente un
- clave primaria o índice único).
- El servidor de destino se puede usar para escrituras. Puede tener diferentes índices y definiciones de seguridad.
- La replicación lógica admite varias versiones. A diferencia de Streaming Replication, Logical Replication se puede configurar entre diferentes versiones de PostgreSQL (aunque> 9.4)
- La replicación lógica hace un filtrado basado en eventos
- En comparación, la replicación lógica tiene menos amplificación de escritura que la replicación de transmisión
- Las publicaciones pueden tener varias suscripciones
- La replicación lógica brinda flexibilidad de almacenamiento a través de la replicación de conjuntos más pequeños (incluso tablas particionadas)
- Carga mínima del servidor en comparación con las soluciones basadas en activadores
- Permite la transmisión paralela entre editores
- La replicación lógica se puede usar para migraciones y actualizaciones
- La transformación de datos se puede realizar durante la configuración.
Casos de uso:¿cuándo es útil la replicación lógica?
Es muy importante saber cuándo utilizar la replicación lógica. De lo contrario, no obtendrá muchos beneficios si su caso de uso no coincide. Entonces, aquí hay algunos casos de uso sobre cuándo usar la replicación lógica:
- Si desea consolidar varias bases de datos en una única base de datos con fines analíticos.
- Si su requisito es replicar datos entre diferentes versiones principales de PostgreSQL.
- Si desea enviar cambios incrementales en una sola base de datos o un subconjunto de una base de datos a otras bases de datos.
- Si da acceso a datos replicados a diferentes grupos de usuarios.
- Si comparte un subconjunto de la base de datos entre varias bases de datos.
Limitaciones de la replicación lógica
La replicación lógica tiene algunas limitaciones en las que la comunidad trabaja continuamente para superarlas:
- Las tablas deben tener el mismo nombre calificado completo entre la publicación y la suscripción.
- Las tablas deben tener una clave principal o una clave única
- La replicación mutua (bidireccional) no es compatible
- No replica el esquema/DDL
- No replica secuencias
- No replica TRUNCATE
- No replica objetos grandes
- Las suscripciones pueden tener más columnas o un orden diferente de las columnas, pero los tipos y los nombres de las columnas deben coincidir entre Publicación y Suscripción.
- Privilegios de superusuario para agregar todas las tablas
- No puede transmitir al mismo host (la suscripción se bloqueará).
Cómo lograr la replicación lógica
Estos son los pasos para lograr la replicación lógica básica. Podemos hablar sobre escenarios más complejos más adelante.
-
Inicialice dos instancias diferentes para publicación y suscripción y comience.
C1MQV0FZDTY3:bin bajishaik$ export PATH=$PWD:$PATH C1MQV0FZDTY3:bin bajishaik$ which psql /Users/bajishaik/pg_software/10.2/bin/psql C1MQV0FZDTY3:bin bajishaik$ ./initdb -D /tmp/publication_db C1MQV0FZDTY3:bin bajishaik$ ./initdb -D /tmp/subscription_db -
Parámetros a cambiar antes de iniciar las instancias (tanto para instancias de publicación como de suscripción).
C1MQV0FZDTY3:bin bajishaik$ tail -3 /tmp/publication_db/postgresql.conf listen_addresses='*' port = 5555 wal_level= logical C1MQV0FZDTY3:bin bajishaik$ pg_ctl -D /tmp/publication_db/ start waiting for server to start....2018-03-21 16:03:30.394 IST [24344] LOG: listening on IPv4 address "0.0.0.0", port 5555 2018-03-21 16:03:30.395 IST [24344] LOG: listening on IPv6 address "::", port 5555 2018-03-21 16:03:30.544 IST [24344] LOG: listening on Unix socket "/tmp/.s.PGSQL.5555" 2018-03-21 16:03:30.662 IST [24345] LOG: database system was shut down at 2018-03-21 16:03:27 IST 2018-03-21 16:03:30.677 IST [24344] LOG: database system is ready to accept connections done server started C1MQV0FZDTY3:bin bajishaik$ tail -3 /tmp/subscription_db/postgresql.conf listen_addresses='*' port=5556 wal_level=logical C1MQV0FZDTY3:bin bajishaik$ pg_ctl -D /tmp/subscription_db/ start waiting for server to start....2018-03-21 16:05:28.408 IST [24387] LOG: listening on IPv4 address "0.0.0.0", port 5556 2018-03-21 16:05:28.408 IST [24387] LOG: listening on IPv6 address "::", port 5556 2018-03-21 16:05:28.410 IST [24387] LOG: listening on Unix socket "/tmp/.s.PGSQL.5556" 2018-03-21 16:05:28.460 IST [24388] LOG: database system was shut down at 2018-03-21 15:59:32 IST 2018-03-21 16:05:28.512 IST [24387] LOG: database system is ready to accept connections done server startedOtros parámetros pueden estar predeterminados para la configuración básica.
-
Cambie el archivo pg_hba.conf para permitir la replicación. Tenga en cuenta que estos valores dependen de su entorno; sin embargo, este es solo un ejemplo básico (tanto para instancias de publicación como de suscripción).
C1MQV0FZDTY3:bin bajishaik$ tail -1 /tmp/publication_db/pg_hba.conf host all repuser 0.0.0.0/0 md5 C1MQV0FZDTY3:bin bajishaik$ tail -1 /tmp/subscription_db/pg_hba.conf host all repuser 0.0.0.0/0 md5 C1MQV0FZDTY3:bin bajishaik$ psql -p 5555 -U bajishaik -c "select pg_reload_conf()" Timing is on. Pager usage is off. 2018-03-21 16:08:19.271 IST [24344] LOG: received SIGHUP, reloading configuration files pg_reload_conf ---------------- t (1 row) Time: 16.103 ms C1MQV0FZDTY3:bin bajishaik$ psql -p 5556 -U bajishaik -c "select pg_reload_conf()" Timing is on. Pager usage is off. 2018-03-21 16:08:29.929 IST [24387] LOG: received SIGHUP, reloading configuration files pg_reload_conf ---------------- t (1 row) Time: 53.542 ms C1MQV0FZDTY3:bin bajishaik$ -
Cree un par de tablas de prueba para replicar e insertar algunos datos en la instancia de Publicación.
postgres=# create database source_rep; CREATE DATABASE Time: 662.342 ms postgres=# \c source_rep You are now connected to database "source_rep" as user "bajishaik". source_rep=# create table test_rep(id int primary key, name varchar); CREATE TABLE Time: 63.706 ms source_rep=# create table test_rep_other(id int primary key, name varchar); CREATE TABLE Time: 65.187 ms source_rep=# insert into test_rep values(generate_series(1,100),'data'||generate_series(1,100)); INSERT 0 100 Time: 2.679 ms source_rep=# insert into test_rep_other values(generate_series(1,100),'data'||generate_series(1,100)); INSERT 0 100 Time: 1.848 ms source_rep=# select count(1) from test_rep; count ------- 100 (1 row) Time: 0.513 ms source_rep=# select count(1) from test_rep_other ; count ------- 100 (1 row) Time: 0.488 ms source_rep=# -
Cree la estructura de las tablas en la instancia de suscripción, ya que la replicación lógica no replica la estructura.
postgres=# create database target_rep; CREATE DATABASE Time: 514.308 ms postgres=# \c target_rep You are now connected to database "target_rep" as user "bajishaik". target_rep=# create table test_rep_other(id int primary key, name varchar); CREATE TABLE Time: 9.684 ms target_rep=# create table test_rep(id int primary key, name varchar); CREATE TABLE Time: 5.374 ms target_rep=# -
Crear publicación en instancia de Publicación (puerto 5555).
source_rep=# CREATE PUBLICATION mypub FOR TABLE test_rep, test_rep_other; CREATE PUBLICATION Time: 3.840 ms source_rep=# -
Cree una suscripción en la instancia de suscripción (puerto 5556) a la publicación creada en el paso 6.
target_rep=# CREATE SUBSCRIPTION mysub CONNECTION 'dbname=source_rep host=localhost user=bajishaik port=5555' PUBLICATION mypub; NOTICE: created replication slot "mysub" on publisher CREATE SUBSCRIPTION Time: 81.729 msDel registro:
2018-03-21 16:16:42.200 IST [24617] LOG: logical decoding found consistent point at 0/1616D80 2018-03-21 16:16:42.200 IST [24617] DETAIL: There are no running transactions. target_rep=# 2018-03-21 16:16:42.207 IST [24618] LOG: logical replication apply worker for subscription "mysub" has started 2018-03-21 16:16:42.217 IST [24619] LOG: starting logical decoding for slot "mysub" 2018-03-21 16:16:42.217 IST [24619] DETAIL: streaming transactions committing after 0/1616DB8, reading WAL from 0/1616D80 2018-03-21 16:16:42.217 IST [24619] LOG: logical decoding found consistent point at 0/1616D80 2018-03-21 16:16:42.217 IST [24619] DETAIL: There are no running transactions. 2018-03-21 16:16:42.219 IST [24620] LOG: logical replication table synchronization worker for subscription "mysub", table "test_rep" has started 2018-03-21 16:16:42.231 IST [24622] LOG: logical replication table synchronization worker for subscription "mysub", table "test_rep_other" has started 2018-03-21 16:16:42.260 IST [24621] LOG: logical decoding found consistent point at 0/1616DB8 2018-03-21 16:16:42.260 IST [24621] DETAIL: There are no running transactions. 2018-03-21 16:16:42.267 IST [24623] LOG: logical decoding found consistent point at 0/1616DF0 2018-03-21 16:16:42.267 IST [24623] DETAIL: There are no running transactions. 2018-03-21 16:16:42.304 IST [24621] LOG: starting logical decoding for slot "mysub_16403_sync_16393" 2018-03-21 16:16:42.304 IST [24621] DETAIL: streaming transactions committing after 0/1616DF0, reading WAL from 0/1616DB8 2018-03-21 16:16:42.304 IST [24621] LOG: logical decoding found consistent point at 0/1616DB8 2018-03-21 16:16:42.304 IST [24621] DETAIL: There are no running transactions. 2018-03-21 16:16:42.306 IST [24620] LOG: logical replication table synchronization worker for subscription "mysub", table "test_rep" has finished 2018-03-21 16:16:42.308 IST [24622] LOG: logical replication table synchronization worker for subscription "mysub", table "test_rep_other" has finishedComo puede ver en el mensaje AVISO, creó una ranura de replicación que garantiza que la limpieza de WAL no se realice hasta que la instantánea inicial o los cambios delta se transfieran a la base de datos de destino. Luego, el remitente de WAL comenzó a decodificar los cambios, y la aplicación de replicación lógica funcionó cuando se iniciaron tanto la publicación como la suscripción. Luego comienza la sincronización de la tabla.
-
Verifique los datos en la instancia de Suscripción.
target_rep=# select count(1) from test_rep; count ------- 100 (1 row) Time: 0.927 ms target_rep=# select count(1) from test_rep_other ; count ------- 100 (1 row) Time: 0.767 ms target_rep=#Como puede ver, los datos se han replicado a través de la instantánea inicial.
-
Verifique los cambios delta.
C1MQV0FZDTY3:bin bajishaik$ psql -d postgres -p 5555 -d source_rep -c "insert into test_rep values(generate_series(101,200), 'data'||generate_series(101,200))" INSERT 0 100 Time: 3.869 ms C1MQV0FZDTY3:bin bajishaik$ psql -d postgres -p 5555 -d source_rep -c "insert into test_rep_other values(generate_series(101,200), 'data'||generate_series(101,200))" INSERT 0 100 Time: 3.211 ms C1MQV0FZDTY3:bin bajishaik$ psql -d postgres -p 5556 -d target_rep -c "select count(1) from test_rep" count ------- 200 (1 row) Time: 1.742 ms C1MQV0FZDTY3:bin bajishaik$ psql -d postgres -p 5556 -d target_rep -c "select count(1) from test_rep_other" count ------- 200 (1 row) Time: 1.480 ms C1MQV0FZDTY3:bin bajishaik$
Estos son los pasos para una configuración básica de Logical Replication.