Introducción
Almacenar datos es una cosa; almacenamiento significativo, útil, correcto los datos son otra muy distinta. Si bien el significado y la utilidad son en sí mismos cualidades subjetivas, la corrección al menos puede definirse y aplicarse lógicamente. Los tipos ya aseguran que los números sean números y las fechas sean fechas, pero no pueden garantizar que el peso o la distancia sean números positivos ni evitar que los intervalos de fechas se superpongan. Las restricciones de tupla, tabla y base de datos aplican reglas a los datos que se almacenan y rechazan valores o combinaciones de valores que no pasan la prueba.
Las restricciones no hacen que otras técnicas de validación de entrada sean inútiles de ninguna manera, incluso cuando prueban las mismas afirmaciones. El tiempo dedicado a intentar y fallar en almacenar datos no válidos es una pérdida de tiempo. Mensajes de infracción, como assert en sistemas y lenguajes de programación de aplicaciones, solo revela el primer problema con el registro del primer candidato con mucho más detalle que cualquier persona que no esté directamente involucrada con las necesidades de la base de datos. Pero en lo que se refiere a la exactitud de los datos, las restricciones son la ley, para bien o para mal; cualquier otra cosa es un consejo.
En tuplas:no nulas, predeterminadas y verificadas
Las restricciones no nulas son la categoría más simple. Una tupla debe tener un valor para el atributo restringido, o dicho de otro modo, el conjunto de valores permitidos para la columna ya no incluye el conjunto vacío. Sin valor significa que no hay tupla:se rechaza la inserción o actualización.
Protegerse contra valores nulos es tan fácil como declarar column_name COLUMN_TYPE NOT NULL en CREATE TABLE o ADD COLUMN . Los valores nulos causan categorías completas de problemas entre la base de datos y los usuarios finales, por lo que definir reflexivamente restricciones no nulas en cualquier columna sin una buena razón para permitir valores nulos es un buen hábito.
La provisión de un valor predeterminado si no se especifica nada (por omisión o un NULL explícito ) en una inserción o actualización no siempre se considera una restricción, ya que los registros candidatos se modifican y almacenan en lugar de rechazarse. En muchos DBMS, una función puede generar valores predeterminados, aunque MySQL no permite funciones definidas por el usuario para este propósito.
Cualquier otra regla de validación que dependa solo de los valores dentro de una sola tupla se puede implementar como CHECK restricción. En cierto sentido, NOT NULL en sí mismo es una abreviatura de CHECK (column_name IS NOT NULL); el mensaje de error recibido en violación hace la mayor parte de la diferencia. CHECK , sin embargo, puede aplicar y hacer cumplir la verdad de cualquier predicado booleano sobre una sola tupla. Por ejemplo, una tabla que almacene ubicaciones geográficas debería CHECK (latitude >= -90 AND latitude < 90) , y de manera similar para longitudes entre -180 y 180 -- o, si está disponible, use y valide una GEOGRAPHY tipo de datos.
En tablas:único y exclusión
Las restricciones a nivel de tabla prueban las tuplas entre sí. En una restricción única, solo un registro puede tener un conjunto dado de valores para las columnas restringidas. La nulabilidad puede causar problemas aquí, ya que NULL nunca es igual a nada más, hasta e incluyendo NULL sí mismo. Una restricción única en (batman, robin) por lo tanto, permite infinitas copias de cualquier Robinless Batman.
Las restricciones de exclusión solo se admiten en PostgreSQL y DB2, pero llenan un nicho muy útil:pueden evitar superposiciones. Especifique los campos restringidos y las operaciones mediante las cuales se evaluará cada uno, y solo se aceptará un nuevo registro si ningún registro existente se compara correctamente con cada campo y operación. Por ejemplo, un schedules la tabla se puede configurar para rechazar conflictos:
-- text, int, etc. comparisons in exclusion constraints require this-- Postgres extensionCREATE EXTENSION btree_gist;CREATE TABLE schedules ( schedule_id SERIAL NOT NULL PRIMARY KEY, room_number TEXT NOT NULL, -- a range of TIMESTAMP WITH TIME ZONE provides both start and end duration TSTZRANGE, -- table-level constraints imply an index, since otherwise they'd -- have to search the entire table to validate a candidate record; -- GiST (generalized search tree) indexes are usually used in -- Postgres EXCLUDE USING GIST ( room_number WITH =, duration WITH && ));INSERT INTO schedules (room_number, duration)VALUES ('32A', '[2020-08-20T10:00:00Z,2020-08-20T11:00:00Z)');-- the same time in a different room: acceptedINSERT INTO schedules (room_number, duration)VALUES ('32B', '[2020-08-20T10:00:00Z,2020-08-20T11:00:00Z)');-- a half-hour overlap for an already-scheduled room: rejectedINSERT INTO schedules (room_number, duration)VALUES ('32A', '[2020-08-20T10:30:00Z,2020-08-20T11:30:00Z)');
Upsert operaciones como ON CONFLICT de PostgreSQL cláusula o de MySQL ON DUPLICATE KEY UPDATE use una restricción a nivel de tabla para detectar conflictos. Y al igual que las restricciones no nulas, se pueden expresar como CHECK restricciones, una restricción única se puede expresar como una restricción de exclusión sobre la igualdad.
La clave primaria
Las restricciones únicas tienen un caso especial particularmente útil. Con una restricción no nula adicional en la columna o columnas únicas, cada registro de la tabla se puede identificar individualmente por sus valores para las columnas restringidas, que se denominan colectivamente una clave . Varias claves candidatas pueden coexistir en una tabla, como users todavía a veces tiene un email distinto, único y no nulo s y username s; pero declarar una clave primaria establece un criterio único por el cual los registros son de conocimiento público y exclusivo. Algunos RDBMS incluso organizan las filas en las páginas por la clave principal, denominada para este fin un índice agrupado , para que la búsqueda por valores de clave principal sea lo más rápida posible.
Hay dos tipos de clave principal. Una clave natural se define en una columna o columnas incluidas "naturalmente" en los datos de la tabla, mientras que una clave sustituta o sintética se inventa únicamente con el propósito de convertirse en la clave. Las claves naturales requieren cuidado:pueden cambiar más cosas de las que los diseñadores de bases de datos suelen creer, desde nombres hasta esquemas de numeración. Una tabla de búsqueda que contiene nombres de países y regiones puede usar sus respectivos códigos ISO 3166 como una clave primaria natural segura, pero un users tabla con una clave natural basada en valores mutables como nombres o direcciones de correo electrónico invita a problemas. En caso de duda, cree una clave sustituta.
Si una clave natural abarca varias columnas, al menos siempre se debe considerar una clave sustituta, ya que las claves de varias columnas requieren más esfuerzo para administrar. Sin embargo, si la clave natural se adapta, las columnas deben ordenarse de manera creciente tal como lo están en los índices:código de país luego código de región, en lugar de al revés.
Históricamente, la clave sustituta ha sido una sola columna entera, o BIGINT donde eventualmente se asignarán miles de millones. Las bases de datos relacionales pueden llenar automáticamente las claves sustitutas con el siguiente número entero de una serie, una característica que generalmente se llama SERIAL o IDENTITY .
Un contador numérico de incremento automático no está exento de inconvenientes:agregar registros con claves pregeneradas puede causar conflictos, y si los valores secuenciales están expuestos a los usuarios, es fácil para ellos adivinar qué otras claves válidas podrían ser. Los identificadores únicos universales, o UUID, evitan estas debilidades y se han convertido en una opción común para las claves sustitutas, aunque también son mucho más grandes en la página que un simple número. Los tipos de UUID v1 (basado en direcciones MAC) y v4 (pseudoaleatorio) son los más utilizados.
En la base de datos:Claves externas
Las bases de datos relacionales implementan solo una clase de restricción de tablas múltiples, el
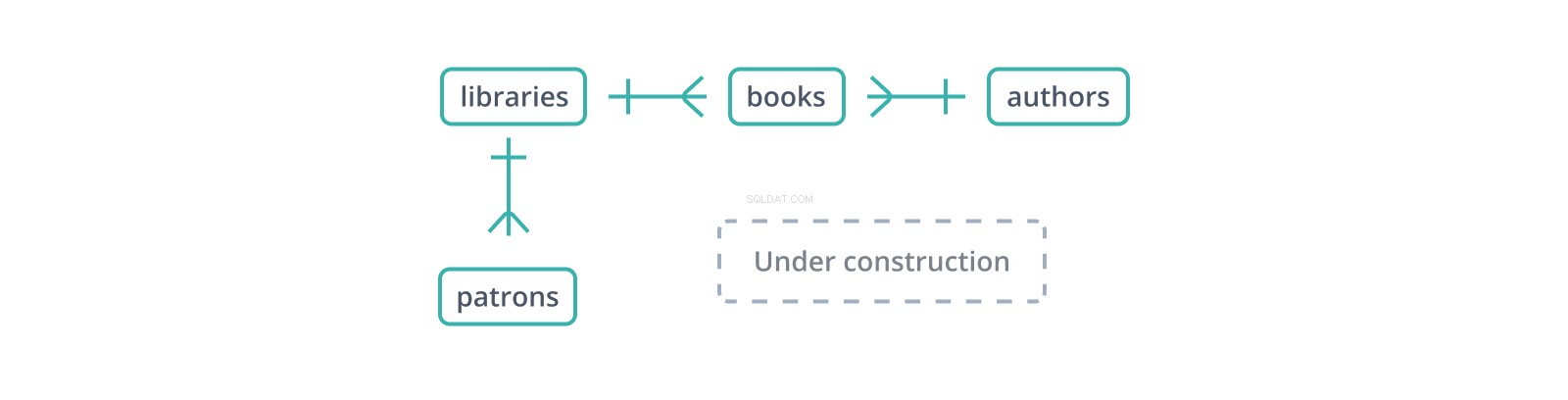
Este "diagrama entidad-relación" informal o ERD muestra los comienzos de un esquema para una base de datos de bibliotecas y sus colecciones y usuarios. Cada borde representa una relación entre las tablas que conecta. el | El glifo indica un solo registro de lado, mientras que el glifo de "pata de gallo" representa varios:una biblioteca tiene muchos libros y muchos usuarios.
Una clave externa es una copia de la clave principal de otra tabla, columna por columna (un punto a favor de las claves sustitutas:solo una columna para copiar y hacer referencia), con valores que vinculan los registros en esta tabla con los registros "principales" en eso. En el esquema anterior, los books la tabla mantiene un library_id clave foránea a libraries , que contienen libros y un author_id a authors , quienes los escriben. Pero, ¿qué sucede si se inserta un libro con un author_id? que no existe en authors ?
Si la clave externa no está restringida, es decir, es solo otra columna o columnas, un libro puede tener un autor que no existe. Esto es un problema:si alguien intenta seguir el enlace entre books y authors , no terminan en ninguna parte. Si authors.author_id es un número entero en serie, también existe la posibilidad de que nadie se dé cuenta hasta que el author_id espurio finalmente se asigna, y terminas con una copia particular de Don Quijote atribuido primero a un desconocido y luego a Pierre Menard, sin que Miguel Cervantes aparezca por ninguna parte.
Restringir la clave externa no puede evitar que un libro se atribuya incorrectamente si el author_id es erróneo. apunta a un registro existente en authors , por lo que otras comprobaciones y pruebas siguen siendo importantes. Sin embargo, el conjunto de valores de clave externa existente es casi siempre un pequeño subconjunto de los posibles valores de clave externa, por lo que las restricciones de clave externa detectarán y evitarán la mayoría de los valores incorrectos. Con una restricción de clave externa, el Quijote con un autor inexistente será rechazado en lugar de grabado.
¿Es aquí de donde proviene el "relacional" en la "base de datos relacional"?
Las claves foráneas crean relaciones entre tablas, pero las tablas, tal como las conocemos, son matemáticamente relaciones. entre los conjuntos de valores posibles para cada atributo. Una sola tupla relaciona un valor de la columna A con un valor de la columna B y en adelante. El artículo original de E.F. Codd usa "relacional" en este sentido.
Esto ha causado un sinfín de confusión y probablemente seguirá haciéndolo a perpetuidad.
Para Ciertos Valores de Correcto
Hay muchas más formas en las que los datos pueden ser incorrectos que las que se abordan aquí. Las restricciones ayudan, pero incluso ellas son tan flexibles; muchas especificaciones comunes dentro de la tabla, como un límite de dos o más en la cantidad de veces que se permite que un valor aparezca en una columna, solo se pueden aplicar con disparadores.
Pero también hay formas en las que la estructura misma de una tabla puede dar lugar a incoherencias. Para evitar esto, necesitaremos ordenar las claves primarias y externas no solo para definir y validar, sino también para normalizar las relaciones entre tablas. Primero, sin embargo, apenas hemos arañado la superficie de cómo las relaciones entre las tablas definen la estructura de la base de datos en sí.



