El ANY agregado no es algo que podamos escribir directamente en Transact SQL. Es una función solo interna utilizada por el optimizador de consultas y el motor de ejecución.
Personalmente, soy bastante aficionado a ANY agregado, por lo que fue un poco decepcionante saber que está roto de una manera bastante fundamental. El sabor particular de "roto" al que me refiero aquí es la variedad de resultados incorrectos.
En esta publicación, echo un vistazo a dos lugares particulares donde ANY agregado comúnmente aparece, demuestra el problema de resultados incorrectos y sugiere soluciones cuando es necesario.
Para obtener información sobre ANY agregado, consulte mi publicación anterior Planes de consulta no documentados:el agregado CUALQUIER.
1. Consultas de una fila por grupo
Este debe ser uno de los requisitos de consulta más comunes del día a día, con una solución muy conocida. Probablemente escriba este tipo de consulta todos los días, siguiendo automáticamente el patrón, sin pensar realmente en ello.
La idea es numerar el conjunto de filas de entrada usando el ROW_NUMBER función de ventana, dividida por la columna o columnas de agrupación. Eso está envuelto en una expresión de tabla común o tabla derivada y se filtra a las filas donde el número de fila calculado es igual a uno. Desde el ROW_NUMBER se reinicia en uno para cada grupo, esto nos da la fila requerida por grupo.
No hay problema con ese patrón general. El tipo de consulta de una fila por grupo que está sujeta a ANY problema agregado es aquel en el que no nos importa qué fila en particular se selecciona de cada grupo.
En ese caso, no está claro qué columna debe usarse en el ORDER BY obligatorio. cláusula del ROW_NUMBER Función de ventana. Después de todo, explícitamente no nos importa qué fila está seleccionada. Un enfoque común es reutilizar la PARTITION BY columna(s) en ORDER BY cláusula. Aquí es donde podría ocurrir el problema.
Ejemplo
Veamos un ejemplo usando un conjunto de datos de juguetes:
CREATE TABLE #Data
(
c1 integer NULL,
c2 integer NULL,
c3 integer NULL
);
INSERT #Data
(c1, c2, c3)
VALUES
-- Group 1
(1, NULL, 1),
(1, 1, NULL),
(1, 111, 111),
-- Group 2
(2, NULL, 2),
(2, 2, NULL),
(2, 222, 222);
El requisito es devolver cualquier fila completa de datos de cada grupo, donde la pertenencia al grupo se define por el valor de la columna c1 .

Siguiendo el ROW_NUMBER patrón, podríamos escribir una consulta como la siguiente (observe el ORDER BY cláusula del ROW_NUMBER la función de ventana coincide con PARTITION BY cláusula):
WITH
Numbered AS
(
SELECT
D.*,
rn = ROW_NUMBER() OVER (
PARTITION BY D.c1
ORDER BY D.c1)
FROM #Data AS D
)
SELECT
N.c1,
N.c2,
N.c3
FROM Numbered AS N
WHERE
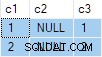
N.rn = 1; Tal como se presenta, esta consulta se ejecuta correctamente, con resultados correctos. Los resultados son técnicamente no deterministas ya que SQL Server podría devolver válidamente cualquiera de las filas de cada grupo. Sin embargo, si ejecuta esta consulta usted mismo, es muy probable que vea el mismo resultado que yo:
El plan de ejecución depende de la versión de SQL Server utilizada y no depende del nivel de compatibilidad de la base de datos.
En SQL Server 2014 y versiones anteriores, el plan es:

Para SQL Server 2016 o posterior, verá:

Ambos planes son seguros, pero por diferentes razones. El Orden Distinto el plan contiene un ANY agregado, pero el Clasificación distinta la implementación del operador no manifiesta el error.
El plan más complejo de SQL Server 2016+ no usa ANY agregado en absoluto. El Ordenar coloca las filas en el orden necesario para la operación de numeración de filas. El segmento El operador establece una bandera al comienzo de cada nuevo grupo. El Proyecto Secuencia calcula el número de fila. Finalmente, el Filtro el operador pasa solo aquellas filas que tienen un número de fila calculado de uno.
El bicho
Para obtener resultados incorrectos con este conjunto de datos, debemos usar SQL Server 2014 o anterior, y ANY los agregados deben implementarse en un Stream Aggregate o Eager Agregado de hash operador (Flow Distinct Hash Match Agregado no produce el error).
Una forma de animar al optimizador a elegir un Stream Aggregate en lugar de Clasificación distinta es agregar un índice agrupado para ordenar por columna c1 :
CREATE CLUSTERED INDEX c ON #Data (c1);
Después de ese cambio, el plan de ejecución se convierte en:

El ANY los agregados son visibles en las Propiedades ventana cuando el Stream Aggregate se selecciona el operador:

El resultado de la consulta es:
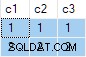
Esto es incorrecto . SQL Server ha devuelto filas que no existen en los datos de origen. No hay filas de origen donde c2 = 1 y c3 = 1 por ejemplo. Como recordatorio, los datos de origen son:
El plan de ejecución calcula erróneamente separar ANY agregados para el c2 y c3 columnas, ignorando nulos. Cada agregado independientemente devuelve el primer no nulo valor que encuentra, dando un resultado donde los valores para c2 y c3 provienen de diferentes filas de origen . Esto no es lo que solicitaba la especificación de consulta SQL original.
Se puede producir el mismo resultado incorrecto con o sin el índice agrupado agregando una OPTION (HASH GROUP) sugerencia para producir un plan con un Eager Hash Aggregate en lugar de un Stream Aggregate .
Condiciones
Este problema solo puede ocurrir cuando múltiples ANY los agregados están presentes y los datos agregados contienen valores nulos. Como se señaló, el problema solo afecta a Stream Aggregate y Eager Agregado de hash operadores; Clasificación distinta y Flujo Distinto no se ven afectados.
SQL Server 2016 en adelante hace un esfuerzo por evitar la introducción de múltiples ANY agregados para el patrón de consulta de numeración de filas de una fila por grupo cuando las columnas de origen son anulables. Cuando esto suceda, el plan de ejecución contendrá Segmento , Proyecto de secuencia y Filtro operadores en lugar de un agregado. Esta forma de plano siempre es segura, ya que no ANY se utilizan agregados.
Reproduciendo el error en SQL Server 2016+
El optimizador de SQL Server no es perfecto para detectar cuándo una columna originalmente restringida para ser NOT NULL aún podría producir un valor intermedio nulo a través de manipulaciones de datos.
Para reproducir esto, comenzaremos con una tabla donde todas las columnas se declaran como NOT NULL :
IF OBJECT_ID(N'tempdb..#Data', N'U') IS NOT NULL
BEGIN
DROP TABLE #Data;
END;
CREATE TABLE #Data
(
c1 integer NOT NULL,
c2 integer NOT NULL,
c3 integer NOT NULL
);
CREATE CLUSTERED INDEX c ON #Data (c1);
INSERT #Data
(c1, c2, c3)
VALUES
-- Group 1
(1, 1, 1),
(1, 2, 2),
(1, 3, 3),
-- Group 2
(2, 1, 1),
(2, 2, 2),
(2, 3, 3);
Podemos producir nulos a partir de este conjunto de datos de muchas maneras, la mayoría de las cuales el optimizador puede detectar con éxito, y así evitar introducir ANY agregados durante la optimización.
A continuación se muestra una forma de agregar valores nulos que pasan desapercibidos:
SELECT
D.c1,
OA1.c2,
OA2.c3
FROM #Data AS D
OUTER APPLY (SELECT D.c2 WHERE D.c2 <> 1) AS OA1
OUTER APPLY (SELECT D.c3 WHERE D.c3 <> 2) AS OA2; Esa consulta produce el siguiente resultado:
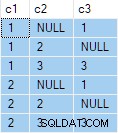
El siguiente paso es usar esa especificación de consulta como datos de origen para la consulta estándar "cualquier fila por grupo":
WITH
SneakyNulls AS
(
-- Introduce nulls the optimizer can't see
SELECT
D.c1,
OA1.c2,
OA2.c3
FROM #Data AS D
OUTER APPLY (SELECT D.c2 WHERE D.c2 <> 1) AS OA1
OUTER APPLY (SELECT D.c3 WHERE D.c3 <> 2) AS OA2
),
Numbered AS
(
SELECT
D.c1,
D.c2,
D.c3,
rn = ROW_NUMBER() OVER (
PARTITION BY D.c1
ORDER BY D.c1)
FROM SneakyNulls AS D
)
SELECT
N.c1,
N.c2,
N.c3
FROM Numbered AS N
WHERE
N.rn = 1; En cualquier versión de SQL Server, que produce el siguiente plan:
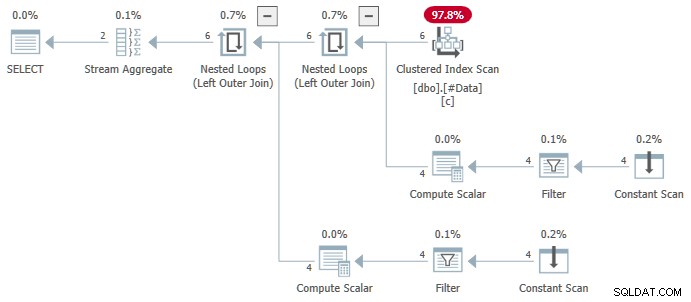
El agregado de flujo contiene múltiples ANY agregados, y el resultado es incorrecto . Ninguna de las filas devueltas aparece en el conjunto de datos de origen:
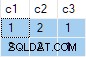
db<>demostración en línea de violín
Solución alternativa
La única solución completamente confiable hasta que se solucione este error es evitar el patrón donde el ROW_NUMBER tiene la misma columna en ORDER BY cláusula tal como está en PARTITION BY cláusula.
Cuando no nos importa cuál se selecciona una fila de cada grupo, es desafortunado que un ORDER BY la cláusula es necesaria en absoluto. Una forma de evitar el problema es usar una constante de tiempo de ejecución como ORDER BY @@SPID en la función de ventana.
2. Actualización no determinista
El problema con múltiples ANY Los agregados en entradas anulables no están restringidos a un patrón de consulta de una sola fila por grupo. El optimizador de consultas puede introducir un ANY interno agregado en una serie de circunstancias. Uno de esos casos es una actualización no determinista.
Un no determinista actualizar es donde la declaración no garantiza que cada fila de destino se actualice como máximo una vez. En otras palabras, hay varias filas de origen para al menos una fila de destino. La documentación advierte explícitamente sobre esto:
Tenga cuidado al especificar la cláusula FROM para proporcionar los criterios para la operación de actualización.Los resultados de una declaración UPDATE no están definidos si la declaración incluye una cláusula FROM que no se especifica de tal manera que solo hay un valor disponible para cada ocurrencia de columna que se actualiza, que es si la sentencia UPDATE no es determinista.
Para manejar una actualización no determinista, el optimizador agrupa las filas por una clave (índice o RID) y aplica ANY agregados a las columnas restantes. La idea básica es elegir una fila de varios candidatos y usar los valores de esa fila para realizar la actualización. Hay paralelismos obvios con el anterior ROW_NUMBER problema, por lo que no sorprende que sea bastante fácil demostrar una actualización incorrecta.
A diferencia del problema anterior, SQL Server actualmente no toma pasos especiales para evitar múltiples ANY agregados en columnas anulables al realizar una actualización no determinista. Por lo tanto, lo siguiente se relaciona con todas las versiones de SQL Server , incluido SQL Server 2019 CTP 3.0.
Ejemplo
DECLARE @Target table
(
c1 integer PRIMARY KEY,
c2 integer NOT NULL,
c3 integer NOT NULL
);
DECLARE @Source table
(
c1 integer NULL,
c2 integer NULL,
c3 integer NULL,
INDEX c CLUSTERED (c1)
);
INSERT @Target
(c1, c2, c3)
VALUES
(1, 0, 0);
INSERT @Source
(c1, c2, c3)
VALUES
(1, 2, NULL),
(1, NULL, 3);
UPDATE T
SET T.c2 = S.c2,
T.c3 = S.c3
FROM @Target AS T
JOIN @Source AS S
ON S.c1 = T.c1;
SELECT * FROM @Target AS T; db<>demostración en línea de violín
Lógicamente, esta actualización siempre debería producir un error:La tabla de destino no permite valores nulos en ninguna columna. Cualquier fila coincidente que se elija de la tabla de origen, un intento de actualizar la columna c2 o c3 para anular debe ocurrir.
Lamentablemente, la actualización se realizó correctamente y el estado final de la tabla de destino no coincide con los datos proporcionados:
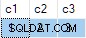
He informado de esto como un error. La solución es evitar escribir UPDATE no determinista declaraciones, entonces ANY no se necesitan agregados para resolver la ambigüedad.
Como se mencionó, SQL Server puede introducir ANY agregados en más circunstancias que los dos ejemplos dados aquí. Si esto sucede cuando la columna agregada contiene valores nulos, existe la posibilidad de obtener resultados incorrectos.