Este artículo es la tercera entrega de una serie sobre las complejidades de NULL. En la Parte 1, cubrí el significado del marcador NULL y cómo se comporta en las comparaciones. En la Parte 2, describí las inconsistencias del tratamiento NULL en diferentes elementos del lenguaje. Este mes describo las potentes funciones estándar de manejo de valores NULL que aún no han llegado a T-SQL y las soluciones alternativas que la gente usa actualmente.
Continuaré usando la base de datos de muestra TSQLV5 como el mes pasado en algunos de mis ejemplos. Puede encontrar el script que crea y completa esta base de datos aquí, y su diagrama ER aquí.
Predicado DISTINTO
En la Parte 1 de la serie, expliqué cómo se comportan los NULL en las comparaciones y las complejidades en torno a la lógica de predicado de tres valores que emplean SQL y T-SQL. Considere el siguiente predicado:
X =YSi algún predicado es NULL, incluso cuando ambos son NULL, el resultado de este predicado es el valor lógico DESCONOCIDO. Con la excepción de los operadores IS NULL y IS NOT NULL, lo mismo se aplica a todos los demás operadores, incluido diferente a (<>):
X <> YA menudo, en la práctica, desea que los NULL se comporten como valores no NULL para fines de comparación. Ese es especialmente el caso cuando los usa para representar faltante pero inaplicable valores. El estándar tiene una solución para esta necesidad en forma de una característica denominada predicado DISTINCT, que utiliza la siguiente forma:
En lugar de usar la semántica de igualdad o desigualdad, este predicado usa la semántica basada en la distinción al comparar predicados. Como alternativa a un operador de igualdad (=), usaría la siguiente forma para obtener un VERDADERO cuando los dos predicados son iguales, incluso cuando ambos son NULL, y un FALSO cuando no lo son, incluso cuando uno es NULL y el otro. otro no es:
X NO ES DISTINTO DE YComo alternativa a un diferente a operador (<>), usaría la siguiente forma para obtener un VERDADERO cuando los dos predicados son diferentes, incluso cuando uno es NULL y el otro no, y un FALSO cuando son iguales, incluso cuando ambos son NULL:
X ES DISTINTO DE YApliquemos el predicado DISTINCT a los ejemplos que usamos en la Parte 1 de la serie. Recuerde que necesitaba escribir una consulta que, dado un parámetro de entrada, @dt devolviera los pedidos que se enviaron en la fecha de entrada si no es NULL, o que no se enviaron en absoluto si la entrada es NULL. De acuerdo con el estándar, usaría el siguiente código con el predicado DISTINCT para manejar esta necesidad:
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate IS NOT DISTINCT FROM @dt;
Por ahora, recuerde de la Parte 1 que puede usar una combinación del predicado EXISTS y el operador INTERSECT como una solución SARGable en T-SQL, así:
SELECT orderid, shippeddate FROM Sales.Orders WHERE EXISTS(SELECT shippeddate INTERSECT SELECT @dt);
Para devolver pedidos que se enviaron en una fecha diferente a (distinta de) la fecha de entrada @dt, usaría la siguiente consulta:
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate IS DISTINCT FROM @dt;
La solución alternativa que funciona en T-SQL usa una combinación del predicado EXISTS y el operador EXCEPT, así:
SELECT orderid, shippeddate FROM Sales.Orders WHERE EXISTS(SELECT shippeddate EXCEPT SELECT @dt);
En la Parte 1 también analicé escenarios en los que necesita unir tablas y aplicar semántica basada en distinciones en el predicado de unión. En mis ejemplos, utilicé tablas llamadas T1 y T2, con columnas de unión NULLable llamadas k1, k2 y k3 en ambos lados. De acuerdo con el estándar, usaría el siguiente código para manejar dicha unión:
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2 FROM dbo.T1 INNER JOIN dbo.T2 ON T1.k1 IS NOT DISTINCT FROM T2.k1 AND T1.k2 IS NOT DISTINCT FROM T2.k2 AND T1.k3 IS NOT DISTINCT FROM T2.k3;
Por ahora, similar a las tareas de filtrado anteriores, puede usar una combinación del predicado EXISTS y el operador INTERSECT en la cláusula ON de la unión para emular el predicado distinto en T-SQL, así:
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2 FROM dbo.T1 INNER JOIN dbo.T2 ON EXISTS(SELECT T1.k1, T1.k2, T1.k3 INTERSECT SELECT T2.k1, T2.k2, T2.k3);
Cuando se usa en un filtro, este formulario es SARGable, y cuando se usa en uniones, este formulario puede depender potencialmente del orden del índice.
Si desea ver el predicado DISTINCT agregado a T-SQL, puede votarlo aquí.
Si después de leer esta sección todavía te sientes un poco incómodo con el predicado DISTINCT, no estás solo. Quizás este predicado sea mucho mejor que cualquier solución existente que tengamos actualmente en T-SQL, pero es un poco detallado y un poco confuso. Utiliza una forma negativa para aplicar lo que en nuestra mente es una comparación positiva, y viceversa. Bueno, nadie dijo que todas las sugerencias estándar son perfectas. Como señaló Charlie en uno de sus comentarios de la Parte 1, la siguiente forma simplificada funcionaría mejor:
Es conciso y mucho más intuitivo. En lugar de X NO ES DISTINTO DE Y, usaría:
X ES YY en lugar de X ES DISTINTO DE Y, usaría:
X NO ES YEste operador propuesto en realidad está alineado con los operadores IS NULL y IS NOT NULL ya existentes.
Aplicado a nuestra tarea de consulta, para devolver pedidos que se enviaron en la fecha de entrada (o que no se enviaron si la entrada es NULL), usaría el siguiente código:
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate IS @dt;
Para devolver pedidos que se enviaron en una fecha diferente a la fecha de entrada, debe usar el siguiente código:
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate IS NOT @dt;
Si Microsoft alguna vez decide agregar el predicado distintivo, sería bueno si admitieran tanto la forma detallada estándar como esta forma no estándar pero más concisa e intuitiva. Curiosamente, el procesador de consultas de SQL Server ya admite un operador de comparación interno IS, que utiliza la misma semántica que el operador IS deseado que describí aquí. Puede encontrar detalles sobre este operador en el artículo de Paul White Planes de consulta no documentados:comparaciones de igualdad (busque "IS en lugar de EQ"). Lo que falta es exponerlo externamente como parte de T-SQL.
Cláusula de tratamiento NULL (IGNORAR NULLS | RESPETAR NULLS)
Al utilizar las funciones de ventana de desplazamiento LAG, LEAD, FIRST_VALUE y LAST_VALUE, a veces es necesario controlar el comportamiento del tratamiento NULL. De forma predeterminada, estas funciones devuelven el resultado de la expresión solicitada en la posición solicitada, independientemente de si el resultado de la expresión es un valor real o NULL. Sin embargo, a veces desea continuar moviéndose en la dirección relevante (hacia atrás para LAG y LAST_VALUE, hacia adelante para LEAD y FIRST_VALUE) y devolver el primer valor no NULL si está presente, y NULL de lo contrario. El estándar le da control sobre este comportamiento mediante una cláusula de tratamiento NULL con la siguiente sintaxis:
offset_function(El valor predeterminado en caso de que no se especifique la cláusula de tratamiento NULL es la opción RESPECT NULLS, lo que significa devolver lo que esté presente en la posición solicitada, incluso si es NULL. Desafortunadamente, esta cláusula aún no está disponible en T-SQL. Proporcionaré ejemplos para la sintaxis estándar usando las funciones LAG y FIRST_VALUE, así como soluciones alternativas que funcionan en T-SQL. Puede usar técnicas similares si necesita dicha funcionalidad con LEAD y LAST_VALUE.
Como datos de muestra, usaré una tabla llamada T4 que usted crea y completa con el siguiente código:
DROP TABLE IF EXISTS dbo.T4; GO CREATE TABLE dbo.T4 ( id INT NOT NULL CONSTRAINT PK_T4 PRIMARY KEY, col1 INT NULL ); INSERT INTO dbo.T4(id, col1) VALUES ( 2, NULL), ( 3, 10), ( 5, -1), ( 7, NULL), (11, NULL), (13, -12), (17, NULL), (19, NULL), (23, 1759);
Hay una tarea común que consiste en devolver el último relevante valor. Un NULL en col1 indica que no hay cambios en el valor, mientras que un valor que no es NULL indica un nuevo valor relevante. Debe devolver el último valor de col1 que no sea NULL según el pedido de identificación. Usando la cláusula de tratamiento NULL estándar, manejaría la tarea de la siguiente manera:
SELECT id, col1, COALESCE(col1, LAG(col1) IGNORE NULLS OVER(ORDER BY id)) AS lastval FROM dbo.T4;
Este es el resultado esperado de esta consulta:
id col1 lastval ----------- ----------- ----------- 2 NULL NULL 3 10 10 5 -1 -1 7 NULL -1 11 NULL -1 13 -12 -12 17 NULL -12 19 NULL -12 23 1759 1759
Hay una solución en T-SQL, pero implica dos capas de funciones de ventana y una expresión de tabla.
En el primer paso, utiliza la función de ventana MAX para calcular una columna llamada grp que contiene el valor de identificación máximo hasta el momento cuando col1 no es NULL, así:
SELECT id, col1,
MAX(CASE WHEN col1 IS NOT NULL THEN id END)
OVER(ORDER BY id
ROWS UNBOUNDED PRECEDING) AS grp
FROM dbo.T4; Este código genera el siguiente resultado:
id col1 grp ----------- ----------- ----------- 2 NULL NULL 3 10 3 5 -1 5 7 NULL 5 11 NULL 5 13 -12 13 17 NULL 13 19 NULL 13 23 1759 23
Como puede ver, se crea un valor de grp único cada vez que hay un cambio en el valor de col1.
En el segundo paso, define un CTE basado en la consulta del primer paso. Luego, en la consulta externa, devuelve el valor col1 máximo hasta el momento, dentro de cada partición definida por grp. Ese es el último valor col1 no NULL. Aquí está el código completo de la solución:
WITH C AS
(
SELECT id, col1,
MAX(CASE WHEN col1 IS NOT NULL THEN id END)
OVER(ORDER BY id
ROWS UNBOUNDED PRECEDING) AS grp
FROM dbo.T4
)
SELECT id, col1,
MAX(col1) OVER(PARTITION BY grp
ORDER BY id
ROWS UNBOUNDED PRECEDING) AS lastval
FROM C; Claramente, eso es mucho más código y trabajo en comparación con simplemente decir IGNORE_NULLS.
Otra necesidad común es devolver el primer valor relevante. En nuestro caso, suponga que necesita devolver el primer valor de col1 que no sea NULL hasta el momento según el orden de identificación. Usando la cláusula estándar de tratamiento NULL, manejaría la tarea con la función FIRST_VALUE y la opción IGNORE NULLS, así:
SELECT id, col1,
FIRST_VALUE(col1) IGNORE NULLS
OVER(ORDER BY id
ROWS UNBOUNDED PRECEDING) AS firstval
FROM dbo.T4; Este es el resultado esperado de esta consulta:
id col1 firstval ----------- ----------- ----------- 2 NULL NULL 3 10 10 5 -1 10 7 NULL 10 11 NULL 10 13 -12 10 17 NULL 10 19 NULL 10 23 1759 10
La solución en T-SQL utiliza una técnica similar a la utilizada para el último valor no NULL, solo que en lugar de un enfoque de doble MAX, utiliza la función FIRST_VALUE sobre una función MIN.
En el primer paso, utiliza la función de ventana MIN para calcular una columna llamada grp que contiene el valor de identificación mínimo hasta el momento cuando col1 no es NULL, así:
SELECT id, col1,
MIN(CASE WHEN col1 IS NOT NULL THEN id END)
OVER(ORDER BY id
ROWS UNBOUNDED PRECEDING) AS grp
FROM dbo.T4; Este código genera el siguiente resultado:
id col1 grp ----------- ----------- ----------- 2 NULL NULL 3 10 3 5 -1 3 7 NULL 3 11 NULL 3 13 -12 3 17 NULL 3 19 NULL 3 23 1759 3
Si hay NULL presentes antes del primer valor relevante, termina con dos grupos:el primero con NULL como valor grp y el segundo con la primera identificación no NULL como valor grp.
En el segundo paso, coloca el código del primer paso en una expresión de tabla. Luego, en la consulta externa, usa la función FIRST_VALUE, dividida por grp, para recopilar el primer valor relevante (no NULL) si está presente, y NULL de lo contrario, así:
WITH C AS
(
SELECT id, col1,
MIN(CASE WHEN col1 IS NOT NULL THEN id END)
OVER(ORDER BY id
ROWS UNBOUNDED PRECEDING) AS grp
FROM dbo.T4
)
SELECT id, col1,
FIRST_VALUE(col1)
OVER(PARTITION BY grp
ORDER BY id
ROWS UNBOUNDED PRECEDING) AS firstval
FROM C; Nuevamente, eso es mucho código y trabajo en comparación con simplemente usar la opción IGNORE_NULLS.
Si cree que esta función puede resultarle útil, puede votar aquí para incluirla en T-SQL.
ORDEN POR NULOS PRIMERO | NULOS ÚLTIMO
Cuando solicita datos, ya sea para fines de presentación, ventanas, filtrado TOP/OFFSET-FETCH o cualquier otro propósito, existe la pregunta de cómo deben comportarse los valores NULL en este contexto. El estándar SQL dice que los NULL deben clasificarse juntos antes o después de los que no son NULL, y dejan que la implementación determine una forma u otra. Sin embargo, independientemente de lo que elija el proveedor, debe ser coherente. En T-SQL, los NULL se ordenan primero (antes de los que no son NULL) cuando se usa el orden ascendente. Considere la siguiente consulta como ejemplo:
SELECT orderid, shippeddate FROM Sales.Orders ORDER BY shippeddate, orderid;
Esta consulta genera el siguiente resultado:
orderid shippeddate ----------- ----------- 11008 NULL 11019 NULL 11039 NULL ... 10249 2017-07-10 10252 2017-07-11 10250 2017-07-12 ... 11063 2019-05-06 11067 2019-05-06 11069 2019-05-06
El resultado muestra que los pedidos no enviados, que tienen una fecha de envío NULO, se ordenan antes de los pedidos enviados, que tienen una fecha de envío aplicable existente.
Pero, ¿qué sucede si necesita NULL para ordenar en último lugar cuando usa el orden ascendente? El estándar ISO/IEC SQL admite una cláusula que se aplica a una expresión de pedido que controla si los NULL se ordenan primero o último. La sintaxis de esta cláusula es:
Para manejar nuestra necesidad, devolviendo los pedidos ordenados por sus fechas de envío, de forma ascendente, pero con los pedidos no enviados devueltos en último lugar, y luego por sus ID de pedido como desempate, usaría el siguiente código:
SELECT orderid, shippeddate FROM Sales.Orders ORDER BY shippeddate NULLS LAST, orderid;
Desafortunadamente, esta cláusula de pedido NULLS no está disponible en T-SQL.
Una solución común que la gente usa en T-SQL es preceder la expresión de orden con una expresión CASE que devuelve una constante con un valor de orden más bajo para valores que no son NULL que para valores NULL, así (llamaremos a esta solución Consulta 1):
SELECT orderid, shippeddate FROM Sales.Orders ORDER BY CASE WHEN shippeddate IS NOT NULL THEN 0 ELSE 1 END, shippeddate, orderid;
Esta consulta genera el resultado deseado con NULL apareciendo al final:
orderid shippeddate ----------- ----------- 10249 2017-07-10 10252 2017-07-11 10250 2017-07-12 ... 11063 2019-05-06 11067 2019-05-06 11069 2019-05-06 11008 NULL 11019 NULL 11039 NULL ...
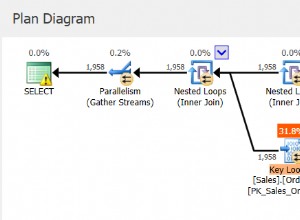
Hay un índice de cobertura definido en la tabla Sales.Orders, con la columna de fecha de envío como clave. Sin embargo, de forma similar a como una columna de filtrado manipulada impide la capacidad SARG del filtro y la capacidad de aplicar una búsqueda de un índice, una columna de ordenación manipulada impide la capacidad de confiar en la ordenación de índices para admitir la cláusula ORDER BY de la consulta. Por lo tanto, SQL Server genera un plan para la Consulta 1 con un operador Ordenar explícito, como se muestra en la Figura 1.
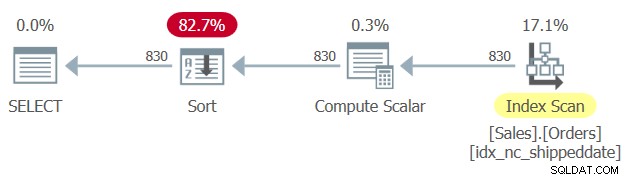 Figura 1:Plan para Consulta 1
Figura 1:Plan para Consulta 1
A veces, el tamaño de los datos no es tan grande como para que la clasificación explícita sea un problema. Pero a veces lo es. Con la clasificación explícita, la escalabilidad de la consulta se vuelve extralineal (pagas más por fila cuantas más filas tengas) y el tiempo de respuesta (el tiempo que tarda en devolverse la primera fila) se retrasa.
Hay un truco que puede usar para evitar la clasificación explícita en tal caso con una solución que se optimiza usando un operador Merge Join Concatenation que conserva el orden. Puede encontrar una cobertura detallada de esta técnica empleada en diferentes escenarios en SQL Server:Cómo evitar una ordenación con concatenación de combinación de combinación. El primer paso de la solución unifica los resultados de dos consultas:una consulta que devuelve las filas donde la columna de orden no es NULL con una columna de resultado (la llamaremos sortcol) basada en una constante con algún valor de orden, digamos 0, y otra consulta que devuelve las filas con NULL, con sortcol establecido en una constante con un valor de ordenación más alto que en la primera consulta, digamos 1. En el segundo paso, luego define una expresión de tabla basada en el código del primer paso, y luego en la consulta externa, ordena las filas de la expresión de la tabla primero por sortcol y luego por los elementos de orden restantes. Aquí está el código de la solución completa que implementa esta técnica (llamaremos a esta solución Consulta 2):
WITH C AS ( SELECT orderid, shippeddate, 0 AS sortcol FROM Sales.Orders WHERE shippeddate IS NOT NULL UNION ALL SELECT orderid, shippeddate, 1 AS sortcol FROM Sales.Orders WHERE shippeddate IS NULL ) SELECT orderid, shippeddate FROM C ORDER BY sortcol, shippeddate, orderid;
El plan para esta consulta se muestra en la Figura 2.
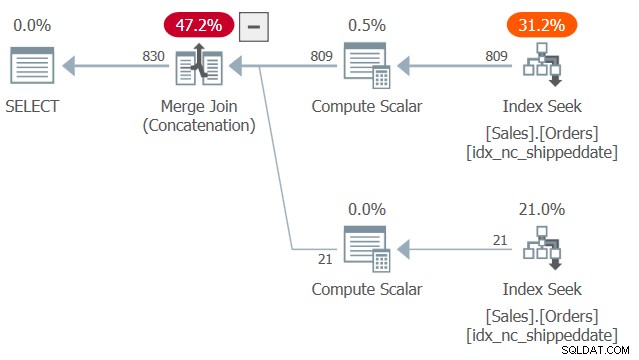 Figura 2:Plan para la Consulta 2
Figura 2:Plan para la Consulta 2
Observe dos búsquedas y escaneos de rango ordenados en el índice de cobertura idx_nc_shippeddate:uno extrae las filas donde la fecha de envío no es NULL y otra extrae las filas donde la fecha de envío es NULL. Luego, de manera similar a la forma en que funciona el algoritmo Merge Join en una unión, el algoritmo Merge Join (Concatenación) unifica las filas de los dos lados ordenados de manera similar a una cremallera y conserva el orden ingerido para admitir las necesidades de ordenación de la presentación de la consulta. No digo que esta técnica sea siempre más rápida que la solución más típica con la expresión CASE, que emplea una clasificación explícita. Sin embargo, el primero tiene una escala lineal y el segundo tiene una escala n log n. Por lo tanto, el primero tenderá a funcionar mejor con un gran número de filas y el segundo con un número pequeño.
Obviamente, es bueno tener una solución para esta necesidad común, pero será mucho mejor si T-SQL agregara soporte para la cláusula de pedido NULL estándar en el futuro.
Conclusión
El estándar ISO/IEC SQL tiene bastantes características de manejo NULL que aún no han llegado a T-SQL. En este artículo cubrí algunos de ellos:el predicado DISTINCT, la cláusula de tratamiento NULL y controlar si los NULL se ordenan primero o último. También proporcioné soluciones para estas características que son compatibles con T-SQL, pero obviamente son engorrosas. El próximo mes continuaré la discusión cubriendo la restricción única estándar, en qué se diferencia de la implementación de T-SQL y las soluciones alternativas que se pueden implementar en T-SQL.