[ Parte 1 | Parte 2 | Parte 3 ]
En la parte 1 de esta serie, probé algunas formas de comprimir una tabla de 1 TB. Si bien obtuve resultados decentes en mi primer intento, quería ver si podía mejorar el rendimiento en la parte 2. Allí describí algunas de las cosas que pensé que podrían ser problemas de rendimiento y expliqué cómo dividiría mejor la tabla de destino. para una compresión óptima del almacén de columnas. Ya he:
- dividió la tabla en 8 particiones (una por núcleo);
- poner el archivo de datos de cada partición en su propio grupo de archivos; y,
- establezca la compresión de archivo en todas las particiones excepto en la "activa".
Todavía necesito hacer que cada programador escriba exclusivamente en su propia partición.
Primero, necesito hacer cambios en la tabla de lotes que creé. Necesito una columna para almacenar la cantidad de filas agregadas por lote (una especie de verificación de cordura de autoauditoría) y las horas de inicio/finalización para medir el progreso.
ALTER TABLE dbo.BatchQueue ADD RowsAdded int, StartTime datetime2, EndTime datetime2;
A continuación, necesito crear una tabla para proporcionar afinidad; nunca queremos que se ejecute más de un proceso en ningún programador, incluso si eso significa perder algo de tiempo para reintentar la lógica. Por lo tanto, necesitamos una tabla que realice un seguimiento de cualquier sesión en un programador específico y evite el apilamiento:
CREATE TABLE dbo.OpAffinity ( SchedulerID int NOT NULL, SessionID int NULL, CONSTRAINT PK_OpAffinity PRIMARY KEY CLUSTERED (SchedulerID) );
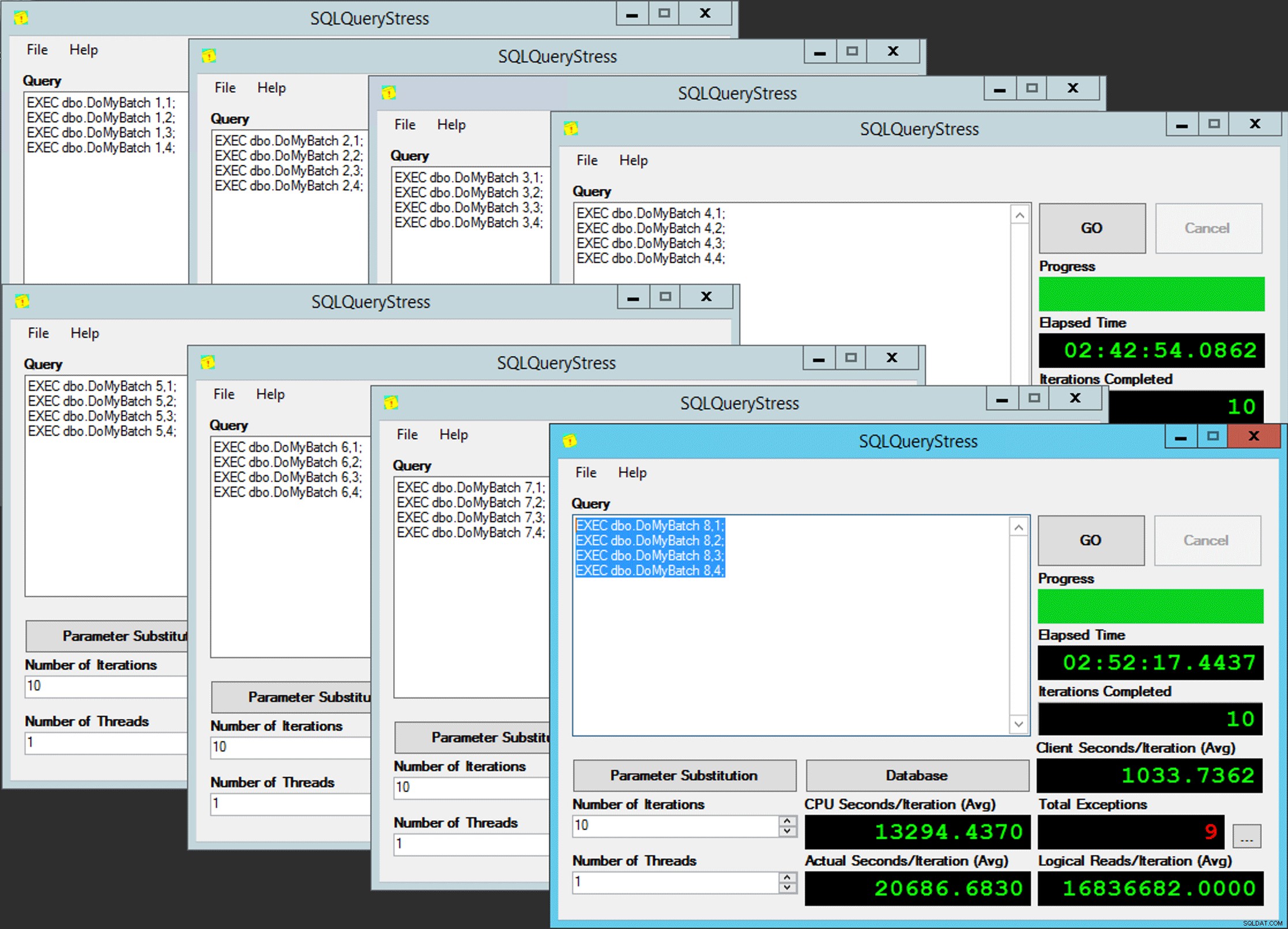
La idea es que tendría ocho instancias de una aplicación (SQLQueryStress) que se ejecutaría cada una en un programador dedicado, manejando solo los datos destinados a una partición/grupo de archivos/archivo de datos específico, ~100 millones de filas a la vez (haga clic para ampliar) :
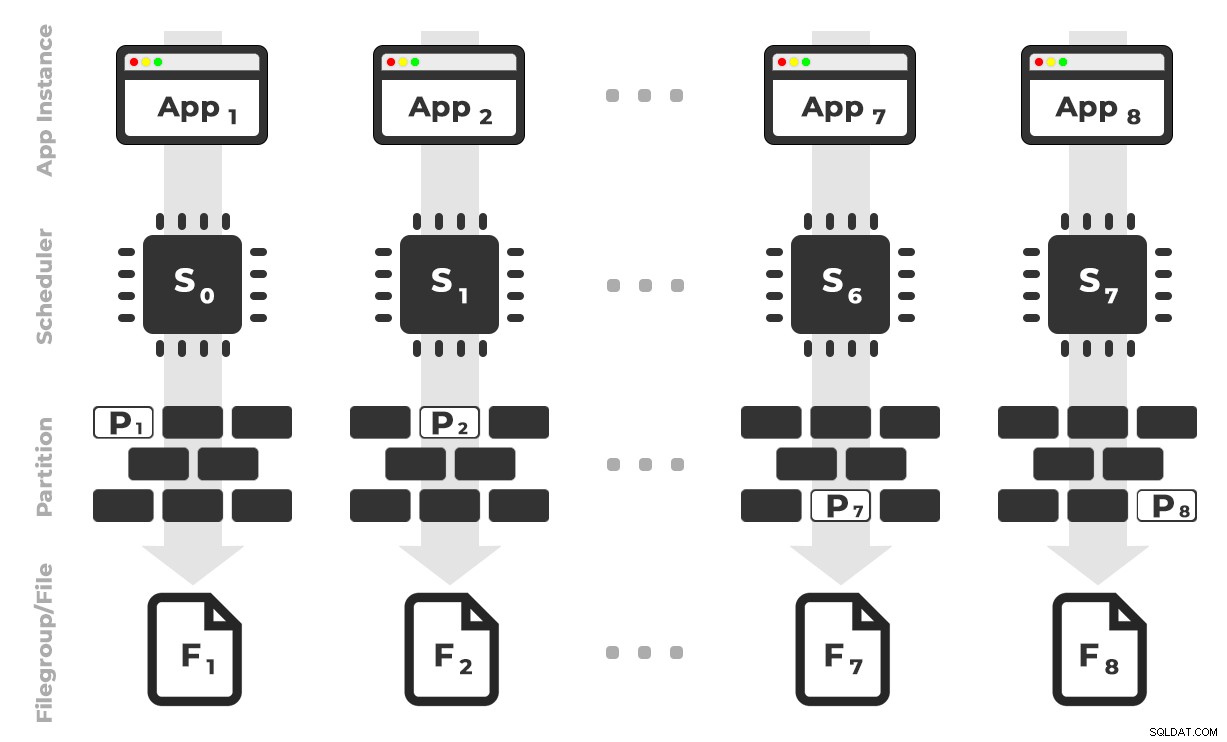 La aplicación 1 obtiene el programador 0 y escribe en la partición 1 en el grupo de archivos 1, y así sucesivamente …
La aplicación 1 obtiene el programador 0 y escribe en la partición 1 en el grupo de archivos 1, y así sucesivamente …
A continuación, necesitamos un procedimiento almacenado que permita que cada instancia de la aplicación reserve tiempo en un solo programador. Como mencioné en una publicación anterior, esta no es mi idea original (y nunca la habría encontrado en esa guía si no fuera por Joe Obbish). Aquí está el procedimiento que creé en Utility :
CREATE PROCEDURE dbo.DoMyBatch
@PartitionID int, -- pass in 1 through 8
@BatchID int -- pass in 1 through 4
AS
BEGIN
DECLARE @BatchSize bigint,
@MinID bigint,
@MaxID bigint,
@rc bigint,
@ThisSchedulerID int =
(
SELECT scheduler_id
FROM sys.dm_exec_requests
WHERE session_id = @@SPID
);
-- try to get the requested scheduler, 0-based
IF @ThisSchedulerID <> @PartitionID - 1
BEGIN
-- surface the scheduler we got to the application, but force a delay
RAISERROR('Got wrong scheduler %d.', 11, 1, @ThisSchedulerID);
WAITFOR DELAY '00:00:05';
RETURN -3;
END
ELSE
BEGIN
-- we are on our scheduler, now serializibly make sure we're exclusive
INSERT Utility.dbo.OpAffinity(SchedulerID, SessionID)
SELECT @ThisSchedulerID, @@SPID
WHERE NOT EXISTS
(
SELECT 1 FROM Utility.dbo.OpAffinity WITH (TABLOCKX)
WHERE SchedulerID = @ThisSchedulerID
);
-- if someone is already using this scheduler, raise roar:
IF @@ROWCOUNT <> 1
BEGIN
RAISERROR('Wrong scheduler %d, try again.',11,1,@ThisSchedulerID) WITH NOWAIT;
RETURN @ThisSchedulerID;
END
-- checkpoint twice to clear log
EXEC OCopy.sys.sp_executesql N'CHECKPOINT; CHECKPOINT;';
-- get our range of rows for the current batch
SELECT @MinID = MinID, @MaxID = MaxID
FROM Utility.dbo.BatchQueue
WHERE PartitionID = @PartitionID
AND BatchID = @BatchID
AND StartTime IS NULL;
-- if we couldn't get a row here, must already be done:
IF @@ROWCOUNT <> 1
BEGIN
RAISERROR('Already done.', 11, 1) WITH NOWAIT;
RETURN -1;
END
-- update the BatchQueue table to indicate we've started:
UPDATE msdb.dbo.BatchQueue
SET StartTime = sysdatetime(), EndTime = NULL
WHERE PartitionID = @PartitionID
AND BatchID = @BatchID;
-- do the work - copy from Original to Partitioned
INSERT OCopy.dbo.tblPartitionedCCI
SELECT * FROM OCopy.dbo.tblOriginal AS o
WHERE o.CostID >= @MinID AND o.CostID <= @MaxID
OPTION (MAXDOP 1); -- don't want parallelism here!
/*
You might think, don't I want a TABLOCK hint on the insert,
to benefit from minimal logging? I thought so too, but while
this leads to a BULK UPDATE lock on rowstore tables, it is a
TABLOCKX with columnstore. This isn't going to work well if
we want to have multiple processes inserting into separate
partitions simultaneously. We need a PARTITIONLOCK hint!
*/
SET @rc = @@ROWCOUNT;
-- update BatchQueue that we've finished and how many rows:
UPDATE Utility.dbo.BatchQueue
SET EndTime = sysdatetime(), RowsAdded = @rc
WHERE PartitionID = @PartitionID
AND BatchID = @BatchID;
-- remove our lock to this scheduler:
DELETE Utility.dbo.OpAffinity
WHERE SchedulerID = @ThisSchedulerID
AND SessionID = @@SPID;
END
END Sencillo, ¿verdad? Inicie 8 instancias de SQLQueryStress y coloque este lote en cada una:
EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 1; EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 2; EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 3; EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 4;
 Paralelismo del pobre
Paralelismo del pobre
Excepto que no es tan simple, ya que la asignación del programador es como una caja de chocolates. Se necesitaron muchos intentos para obtener cada instancia de la aplicación en el programador esperado; Inspeccionaría las excepciones en cualquier instancia dada de la aplicación y cambiaría el PartitionID para emparejar Es por eso que usé más de una iteración (pero todavía solo quería un hilo por instancia). Como ejemplo, esta instancia de la aplicación esperaba estar en el programador 3, pero obtuvo el programador 4:
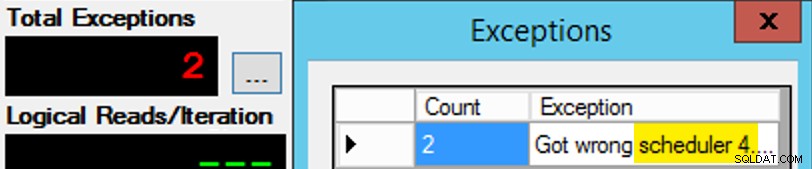 Si al principio no tiene éxito...
Si al principio no tiene éxito...
Cambié los 3 en la ventana de consulta a 4 y lo intenté de nuevo. Si era rápido, la asignación del programador era lo suficientemente "pegajosa" como para que la tomara de inmediato y comenzara a funcionar. Pero no siempre fui lo suficientemente rápido, así que fue como golpear un topo para ponerme en marcha. Probablemente podría haber ideado una mejor rutina de reintento/bucle para hacer el trabajo menos manual aquí, y acortar la demora para saber de inmediato si funcionó o no, pero esto fue lo suficientemente bueno para mis necesidades. También provocó un escalonamiento involuntario de los tiempos de inicio de cada proceso, otro consejo del Sr. Obbish.
Monitoreo
Mientras se ejecuta la copia afín, puedo obtener una pista sobre el estado actual con las siguientes dos consultas:
SELECT r.session_id, r.[status], r.scheduler_id, partition_id = o.SchedulerID + 1,
r.logical_reads, r.total_elapsed_time, r.last_wait_type, longest_wait_type =
(
SELECT TOP (1) wait_type
FROM sys.dm_exec_session_wait_stats
WHERE session_id = r.session_id AND wait_type <> 'WAITFOR'
ORDER BY wait_time_ms - signal_wait_time_ms DESC
)
FROM sys.dm_exec_requests AS r
INNER JOIN Utility.dbo.OpAffinity AS o
ON o.SessionID = r.session_id
WHERE r.command = N'INSERT'
ORDER BY r.scheduler_id;
SELECT SchedulerID = PartitionID - 1, Duration = DATEDIFF(SECOND, StartTime, EndTime), *
FROM Utility.dbo.BatchQueue WITH (NOLOCK)
WHERE StartTime IS NOT NULL -- AND EndTime IS NULL
ORDER BY PartitionID;
Si hiciera todo bien, ambas consultas devolverían 8 filas y mostrarían lecturas lógicas y duración incrementales. Los tipos de espera cambiarán entre PAGEIOLATCH_SH , SOS_SCHEDULER_YIELD y ocasionalmente RESERVED_MEMORY_ALLOCATION_EXT. Cuando se terminó un lote (podría revisarlos quitando el comentario de -- AND EndTime IS NULL , confirmaría que RowsAdded = RowsInRange .
Una vez que se completaron las 8 instancias de SQLQueryStress, pude realizar SELECT INTO <newtable> FROM dbo.BatchQueue para registrar los resultados finales para su posterior análisis.
Otras pruebas
Además de copiar los datos en el índice de almacén de columnas agrupado particionado que ya existía, mediante afinidad, también quería probar un par de cosas más:
- Copiar los datos a la nueva tabla sin intentar controlar la afinidad. Eliminé la lógica de afinidad del procedimiento y simplemente dejé todo el asunto de "espero que obtengas el programador correcto" al azar. Esto tomó más tiempo porque, efectivamente, el apilamiento del programador lo hizo ocurrir. Por ejemplo, en este punto específico, el programador 3 estaba ejecutando dos procesos, mientras que el programador 0 estaba tomando un descanso para almorzar:
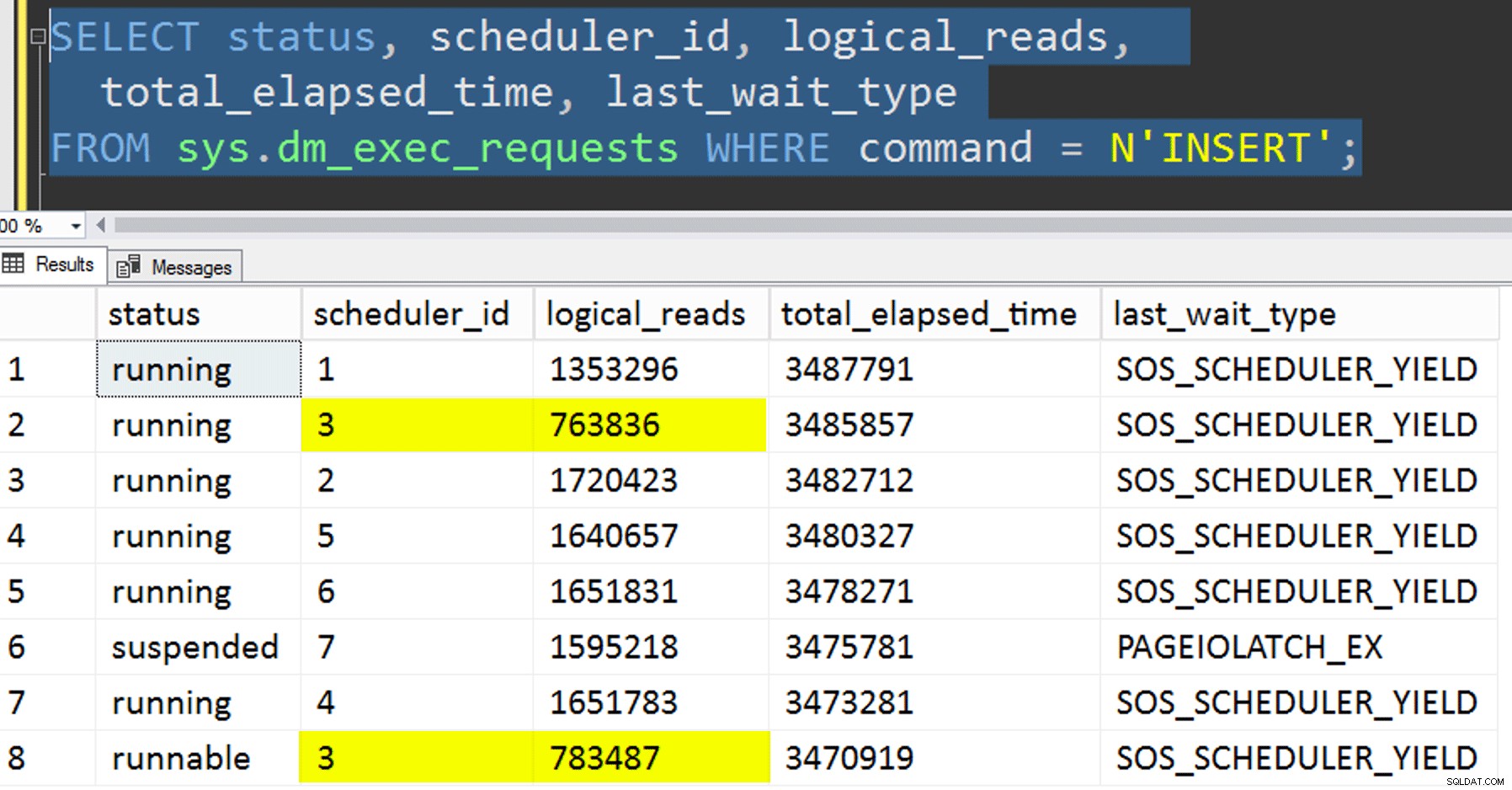 ¿Dónde estás, programador número 0?
¿Dónde estás, programador número 0? - Aplicando página o fila compresión (tanto en línea como fuera de línea) a la fuente antes la copia afín (fuera de línea), para ver si comprimir los datos primero podría acelerar el destino. Tenga en cuenta que la copia también se puede hacer en línea pero, como
intde Andy Mallon abigintconversión, requiere algo de gimnasia. Tenga en cuenta que en este caso no podemos aprovechar la afinidad de la CPU (aunque podríamos hacerlo si la tabla de origen ya estuviera particionada). Fui inteligente e hice una copia de seguridad de la fuente original y creé un procedimiento para revertir la base de datos a su estado inicial. Mucho más rápido y más fácil que intentar volver a un estado específico manualmente.-- refresh source, then do page online: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = PAGE, ONLINE = ON); -- then run SQLQueryStress -- refresh source, then do page offline: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = PAGE, ONLINE = OFF); -- then run SQLQueryStress -- refresh source, then do row online: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = ROW, ONLINE = ON); -- then run SQLQueryStress -- refresh source, then do row offline: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = ROW, ONLINE = OFF); -- then run SQLQueryStress
- Y, por último, reconstruir primero el índice agrupado en el esquema de partición y luego construir el índice de almacén de columnas agrupado encima de eso. La desventaja de esto último es que, en SQL Server 2017, no puede ejecutar esto en línea... pero podrá hacerlo en 2019.
Aquí primero debemos eliminar la restricción PK; no puedes usar
Mensaje 1907, nivel 16, estado 1DROP_EXISTING, ya que el índice de almacén de columnas agrupado no puede aplicar la restricción única original y no puede reemplazar un índice agrupado único con un índice agrupado no único.
No se puede volver a crear el índice 'pk_tblOriginal'. La nueva definición de índice no coincide con la restricción impuesta por el índice existente.Todos estos detalles hacen que este sea un proceso de tres pasos, solo el segundo paso en línea. El primer paso solo probé explícitamente
OFFLINE; que se ejecutó en tres minutos, mientras queONLINEMe detuve después de 15 minutos. Una de esas cosas que tal vez no debería ser una operación de tamaño de datos en cualquier caso, pero lo dejaré para otro día.ALTER TABLE dbo.tblOriginal DROP CONSTRAINT PK_tblOriginal WITH (ONLINE = OFF); GO CREATE CLUSTERED INDEX CCI_tblOriginal -- yes, a bad name, but only temporarily ON dbo.tblOriginal(OID) WITH (ONLINE = ON) ON PS_OID (OID); -- this moves the data CREATE CLUSTERED COLUMNSTORE INDEX CCI_tblOriginal ON dbo.tblOriginal WITH ( DROP_EXISTING = ON, DATA_COMPRESSION = COLUMNSTORE_ARCHIVE ON PARTITIONS (1 TO 7), DATA_COMPRESSION = COLUMNSTORE ON PARTITIONS (8) -- in 2019, CCI can be ONLINE = ON as well ) ON PS_OID (OID); GO
Resultados
Tiempos y tasas de compresión:
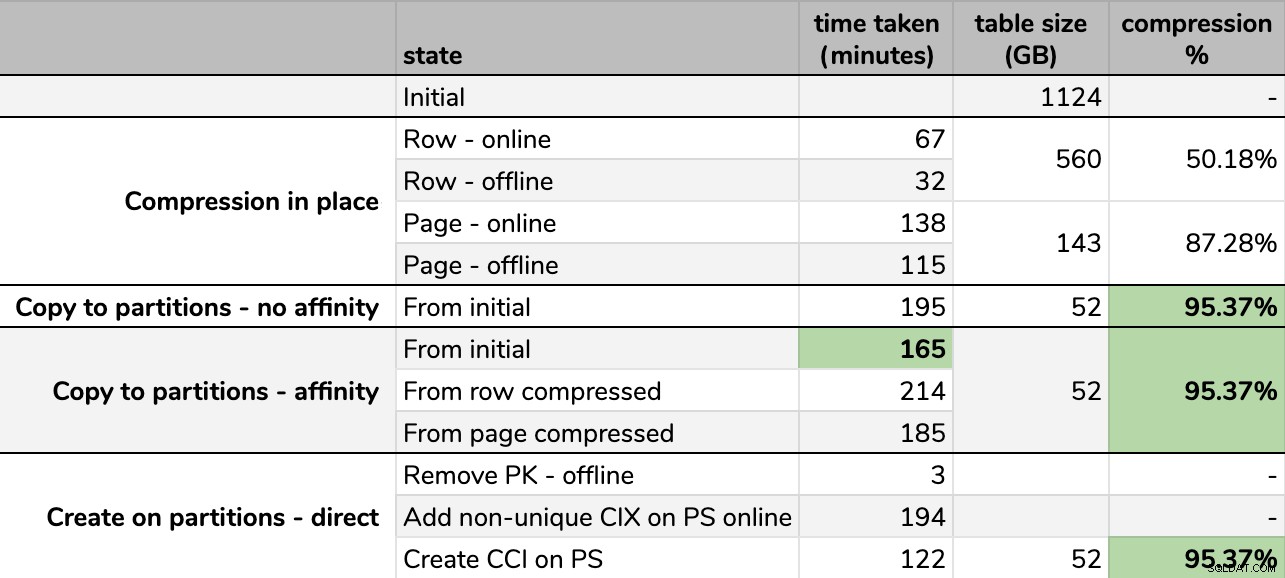 Algunas opciones son mejores que otras
Algunas opciones son mejores que otras
Tenga en cuenta que redondeé a GB porque habría pequeñas diferencias en el tamaño final después de cada ejecución, incluso usando la misma técnica. Además, los tiempos para los métodos de afinidad se basaron en el promedio programador individual/tiempo de ejecución por lotes, ya que algunos programadores terminaron más rápido que otros.
Es difícil imaginar una imagen exacta de la hoja de cálculo como se muestra, porque algunas tareas tienen dependencias, así que intentaré mostrar la información como una línea de tiempo y mostrar cuánta compresión obtienes en comparación con el tiempo invertido:
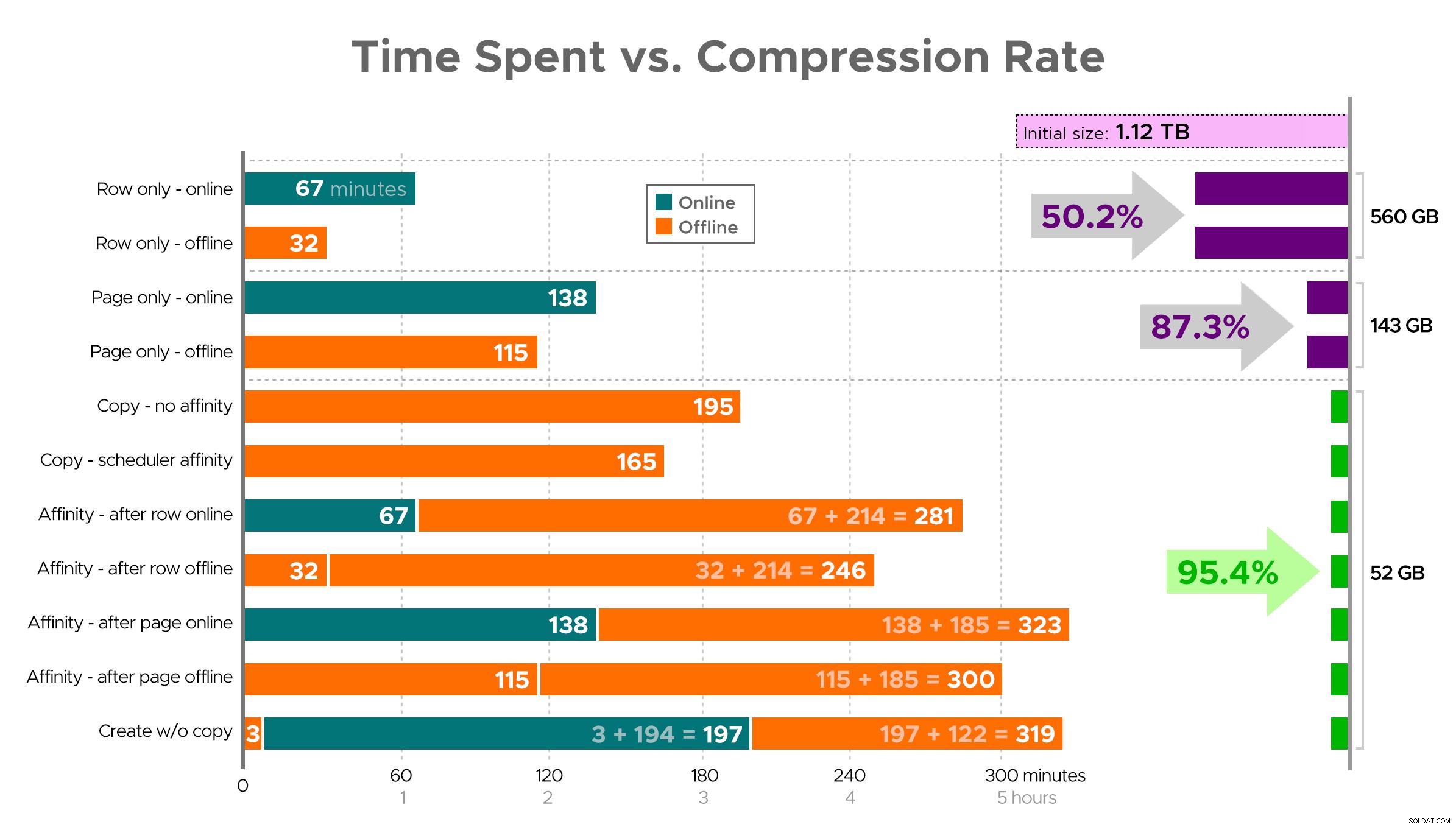 Tiempo empleado (minutos) frente a tasa de compresión
Tiempo empleado (minutos) frente a tasa de compresión
Algunas observaciones de los resultados, con la advertencia de que sus datos pueden comprimirse de manera diferente (y que las operaciones en línea solo se aplican a usted si usa Enterprise Edition):
- Si su prioridad es ahorrar algo de espacio lo más rápido posible , su mejor opción es aplicar la compresión de filas en su lugar. Si desea minimizar las interrupciones, use en línea; si desea optimizar la velocidad, utilícelo sin conexión.
- Si desea maximizar la compresión sin interrupciones , puede acercarse al 90 % de reducción de almacenamiento sin ningún tipo de interrupción, utilizando la compresión de página en línea.
- Si desea maximizar la compresión y la interrupción está bien , copie los datos en una nueva versión particionada de la tabla, con un índice de almacén de columnas agrupado y use el proceso de afinidad descrito anteriormente para migrar los datos. (Y nuevamente, puede eliminar esta interrupción si es mejor planificador que yo).
La opción final funcionó mejor para mi escenario, aunque aún tendremos que esforzarnos en las cargas de trabajo (sí, en plural). También tenga en cuenta que en SQL Server 2019 esta técnica puede no funcionar tan bien, pero puede crear índices de almacén de columnas agrupados en línea allí, por lo que puede que no importe tanto.
Algunos de estos enfoques pueden ser más o menos aceptables para usted, porque puede preferir "permanecer disponible" en lugar de "terminar lo más rápido posible" o "minimizar el uso del disco" en lugar de "permanecer disponible" o simplemente equilibrar el rendimiento de lectura y la sobrecarga de escritura. .
Si desea obtener más detalles sobre cualquier aspecto de esto, solo pregunte. Recorté parte de la grasa para equilibrar los detalles con la digestibilidad, y antes me había equivocado con respecto a ese equilibrio. Un pensamiento de despedida es que tengo curiosidad por lo lineal que es:tenemos otra mesa con una estructura similar que tiene más de 25 TB, y tengo curiosidad por saber si podemos tener un impacto similar allí. Hasta entonces, ¡feliz compresión!
[ Parte 1 | Parte 2 | Parte 3 ]