“Waitstats nos ayuda a identificar contadores relacionados con el rendimiento. Pero la información de espera por sí sola no es suficiente para diagnosticar con precisión los problemas de rendimiento. El componente de colas de nuestra metodología proviene de los contadores de Performance Monitor, que brindan una vista del rendimiento del sistema desde el punto de vista de los recursos”.Tom Davidson, Apertura de la caja de herramientas de ajuste de rendimiento de Microsoft
Revista SQL Server Pro, diciembre de 2003
Waits and Queues se ha utilizado como una metodología de ajuste del rendimiento de SQL Server desde que Tom Davidson publicó el artículo anterior, así como el conocido documento técnico de SQL Server 2005 Waits and Queues en 2006. Cuando se aplica en combinación con métricas de recursos, las esperas pueden ser valiosas para evaluar ciertas características de rendimiento de la carga de trabajo y ayudar a dirigir los esfuerzos de ajuste. Los datos de Waits aparecen en muchas soluciones de monitoreo de rendimiento de SQL Server, y desde el principio he sido un defensor de la optimización usando esta metodología. El enfoque influyó en el diseño del panel de rendimiento de SQL Sentry, que presenta esperas flanqueadas por colas (métricas de recursos clave) para ofrecer una visión completa del rendimiento del servidor.
Sin embargo, algunos parecen haber perdido el punto de vista de Davidson con respecto a la importancia de los recursos y confían casi por completo en las esperas para presentar una imagen del rendimiento de las consultas y el estado del sistema. Las estadísticas de espera provienen directamente del motor de SQL Server y son fáciles de consumir y categorizar. Las consultas en espera significan aplicaciones y usuarios en espera, ¡y a nadie le gusta esperar! Es más fácil evangelizar el tuning con esperas como la única solución para hacer consultas y aplicaciones más rápidas que contar la historia completa, que es más complicada.
Desafortunadamente, un enfoque centrado en las esperas para la exclusión del análisis de recursos puede inducir a error y, en el peor de los casos, dejarlo a ciegas. Los miembros del equipo de SentryOne, Kevin Kline y Steve Wright, ya mencionaron esto aquí y aquí. En esta publicación, profundizaré en algunas investigaciones recientes que fueron posibles gracias a Query Store y que arrojaron nueva luz sobre cuán deficiente puede ser realmente el ajuste exclusivo de las esperas.
Las principales consultas que no lo fueron
Recientemente, un cliente de SentryOne se puso en contacto conmigo por problemas de rendimiento con su base de datos de SentryOne. Hay una sola base de datos de SQL Server en el corazón de cada entorno de monitoreo de SentryOne, y este cliente estaba monitoreando alrededor de 600 servidores con nuestro software. A esa escala, no es inusual ver problemas de rendimiento de consultas ocasionales y hacer algunos ajustes, y algunas consultas supuestamente nuevas en la carga de trabajo fueron la fuente de su preocupación.
Me uní a una sesión de pantalla compartida para echar un vistazo, y el cliente primero me presentó datos de un sistema diferente que también estaba monitoreando la base de datos de SentryOne. El sistema utilizó un enfoque de esperas a nivel de consulta y mostró dos procedimientos almacenados como responsables de aproximadamente la mitad de las esperas en el servidor de base de datos SQL Sentry. Esto era inusual porque estos dos procedimientos siempre se ejecutan muy rápido y nunca han sido indicativos de un problema de rendimiento real en nuestra base de datos. Desconcertado, cambié a SQL Sentry para ver qué nos mostraba y me sorprendió ver que, durante el mismo intervalo, el procedimiento n.° 1 en el otro sistema era el n.° 6, el n.° 7 y el n.° 8 en términos de duración total, CPU y lecturas lógicas respectivamente:
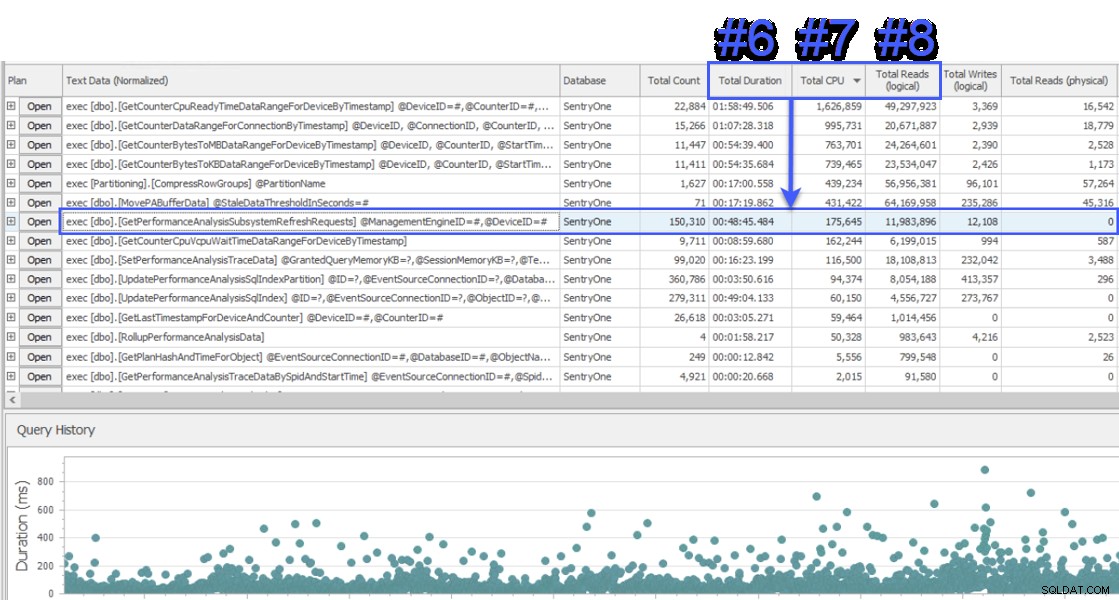 Vista "Top SQL" de SQL Sentry
Vista "Top SQL" de SQL Sentry
Desde el punto de vista del consumo de recursos, esto significaba que las consultas anteriores representaban el 75 % de la duración total, el 87 % de la CPU total y el 88 % de las lecturas lógicas. Además, el procedimiento n.º 2 en el otro sistema ni siquiera estaba entre los primeros 30 en SQL Sentry, ¡de ninguna manera! Estas dos consultas estaban lejos de ser las 2 principales, y las consultas que representaron la mayor parte de los reales el consumo en el sistema estaba gravemente subrepresentado.
Siempre supuse que había una correlación más fuerte entre los mejores camareros y los principales consumidores de recursos, pero nunca había realizado una comparación directa a nivel de consulta como esta, por lo que estos resultados fueron sorprendentes, por decir lo menos. Mi interés despertó, decidí investigar para determinar si esta situación era típica o anómala.
Tienda de consultas 2017 al rescate
En SQL Server 2017 y versiones posteriores, Query Store captura las esperas de nivel de consulta además del consumo de recursos de consulta. Erin Stellato hizo una gran publicación en Query Store espera aquí. Tiene menos gastos generales y es más preciso que las esperas de consulta de los DMV cada segundo con la esperanza de detectar consultas en tránsito, el enfoque estándar utilizado por otras herramientas, incluida la mencionada anteriormente.
SQL Sentry siempre ha capturado las esperas, pero a nivel de instancia de SQL Server, debido a estas preocupaciones sobre la sobrecarga y la precisión. Las esperas de consulta detalladas están disponibles bajo demanda a través del Explorador de planes integrado, y estamos evaluando aumentar las esperas a nivel de instancia con datos a nivel de consulta de Query Store, cuando esté disponible.
Para este esfuerzo, recluté la ayuda del Consejo asesor de productos de SentryOne, un grupo de clientes, socios y amigos de SentryOne en la industria que participan en un canal privado de Slack. Compartí este script para volcar los datos de las 8 horas anteriores de Query Store y recibí los resultados de 11 servidores de producción en múltiples verticales, incluidos los servicios financieros, la publicación de juegos, el seguimiento del estado físico y los seguros.
Las categorías de espera del Almacén de consultas se documentan aquí. Todas las categorías se incluyeron en el análisis excepto estas, que se eliminaron por las razones citadas:
- Paralelismo – Puede inflar enormemente el tiempo de espera de una consulta mucho más allá de su duración real, ya que varios subprocesos pueden eliminar las esperas asociadas, confundiendo la correlación con la duración y otras métricas. Además, aunque la división CXPACKET/CXCONSUMER es útil, CXPACKET solo significa que tiene paralelismo y no es necesariamente problemático o accionable.
- CPU – El tiempo de espera de la señal puede ser útil para determinar los cuellos de botella de la CPU a través de la correlación con las esperas de recursos, pero Query Store actualmente solo incluye SOS_SCHEDULER_YIELD en esta categoría, que no es una espera en el sentido tradicional como se trata aquí. No se presta a una fácil comparación o correlación, especialmente cuando SQL Server está en una VM que vive en un host con exceso de suscripciones. Por ejemplo, en un servidor, las esperas de CPU del Almacén de consultas fueron el 227 % del tiempo total de CPU en todas las consultas sin ningún paralelismo, lo que no debería ser posible.
- Espera de usuario y inactivo – Estas categorías se componen exclusivamente de esperas de temporizador y cola y se excluyeron por la misma razón por la que siempre se deben excluir estos tipos:son inocuos y solo crean ruido.
Aparte, recientemente hablé con el padre de Query Store, Conor Cunningham, sobre la probabilidad de cambios futuros en los tipos de espera y categorías de Query Store y me indicó que ciertamente era posible... por lo que tendremos que vigilar eso.
Resultados del análisis TL;DR
Después de un extenso análisis, confirmé que los resultados observados en el sistema del cliente no son anómalos, sino más bien comunes. Esto significa que si depende de una herramienta centrada en las esperas para supervisar y ajustar sus cargas de trabajo, es muy probable que se esté centrando en las consultas incorrectas y que se pierda a los responsables de la mayoría. de la duración de la consulta y el consumo de recursos en un sistema. Dado que el consumo de CPU y E/S se traduce directamente en hardware de servidor y gasto en la nube, esto es significativo.
La mayoría de las consultas no esperan
Un hallazgo interesante e importante que cubriré primero es que la mayoría de las consultas no generan esperas en absoluto. De un total de 56 438 consultas en todos los servidores, solo 9781 (17 %) tuvieron tiempo de espera y solo 8092 (14 %) tuvieron tiempo de espera de tipos significativos. Si está utilizando solo esperas para determinar qué consultas optimizar, perderá la mayoría de las consultas en la carga de trabajo.
Correlación de esperas y recursos
Analicé cómo se relacionan las esperas con el consumo de recursos clasificando todas las consultas en cada sistema por esperas y recursos y usando las clasificaciones para calcular la correlación de Spearman. Lo que en última instancia estamos tratando de determinar es si los mejores meseros tienden a ser los mejores consumidores. Resulta que no lo hacen.
Tabla 1 muestra los coeficientes de correlación en escala de colores para espera de consulta promedio tiempo a otras medidas:un valor de 1,00 (azul oscuro) representa datos que están perfectamente correlacionados. Como puede ver, la correlación con las esperas y otras medidas en la mayoría de los servidores no es fuerte y para un servidor hay una correlación negativa con la mayoría de las medidas.
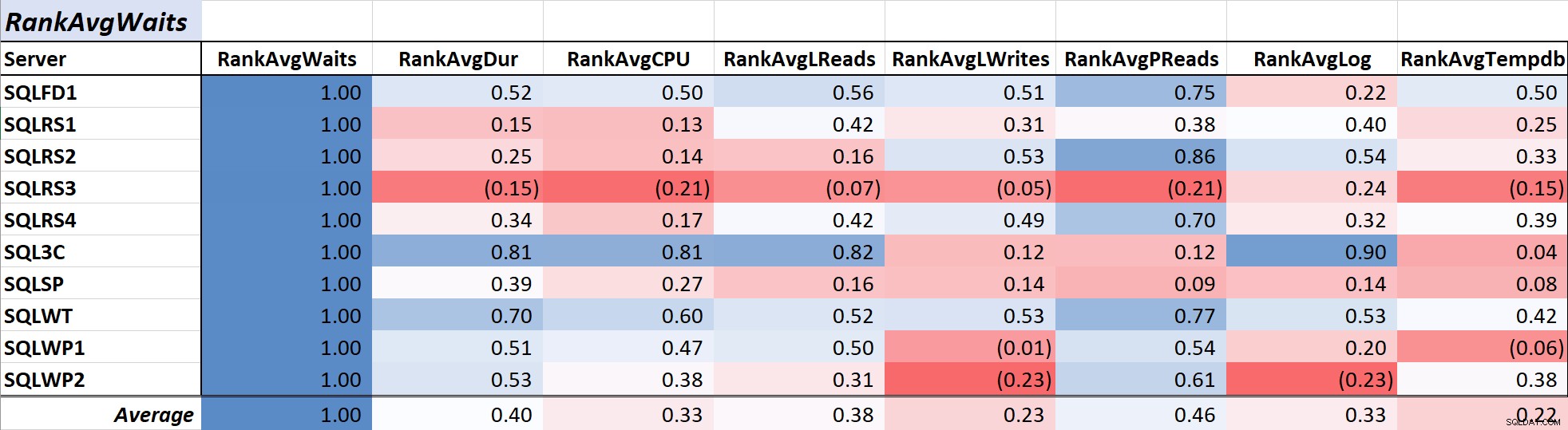 Tabla 1:Correlación con el tiempo medio de espera de consulta (ms)
Tabla 1:Correlación con el tiempo medio de espera de consulta (ms)
La duración de la consulta suele ser una preocupación principal para los administradores de bases de datos y los desarrolladores, ya que se traduce directamente en la experiencia del usuario y en la Tabla 2 muestra la correlación entre duración promedio de consulta y las demás medidas. La correlación con la duración y las dos medidas de recursos principales, CPU y lecturas lógicas, es bastante fuerte con 0,97 y 0,75 respectivamente.
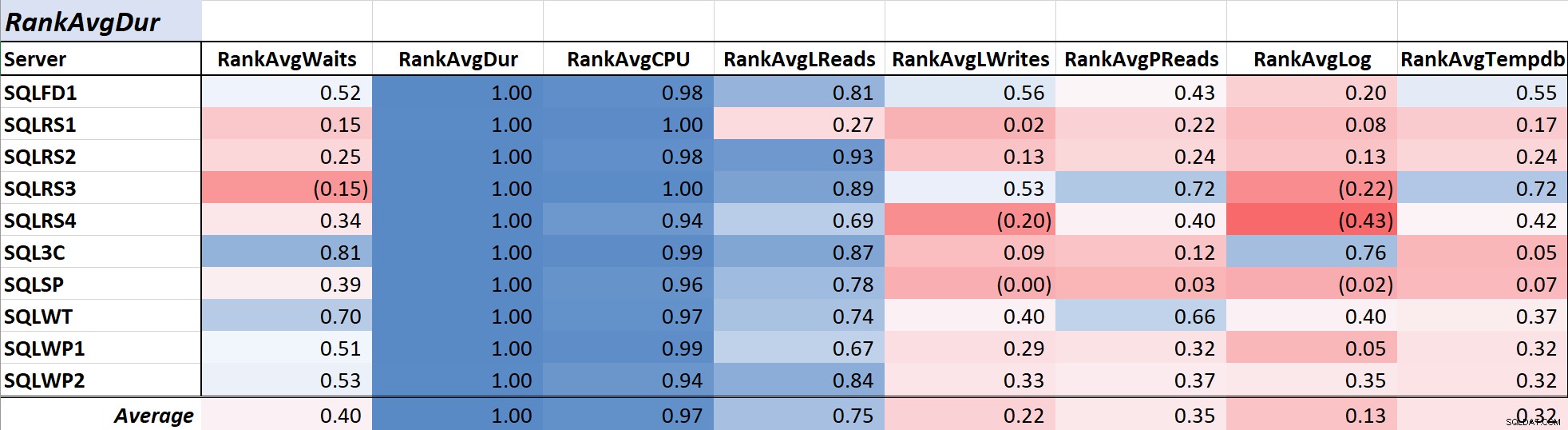 Tabla 2:correlación con la duración media de consultas (ms)
Tabla 2:correlación con la duración media de consultas (ms)
Dado que las lecturas lógicas siempre usan CPU y, al igual que la duración, la CPU se mide en milisegundos, esta relación no es sorprendente. Los resultados son consistentes con la idea de que si desea que sus aplicaciones de base de datos se ejecuten lo más rápido posible, centrarse en reducir la CPU de consulta y las lecturas lógicas será más efectivo para reducir la duración que usar solo las esperas. Afortunadamente, hacerlo a través de un mejor diseño de consultas, indexación, etc. suele ser una propuesta más sencilla que reducir directamente el tiempo de espera de las consultas. El colega Aaron Bertrand presenta efectivamente algunas de las advertencias al sintonizar con las esperas aquí.
% del tiempo total de espera
A continuación, analicé si las consultas con el mayor tiempo de espera tienden a representar el mayor consumo de recursos. Queremos determinar si lo que vimos en el sistema del cliente es atípico, donde las dos principales consultas en espera representaron un porcentaje relativamente pequeño del consumo total de recursos.
Gráfico 1 a continuación se muestra el % de CPU total y lecturas lógicas para cada servidor contabilizado por las consultas que representan el 75 % del tiempo de espera total. Solo un servidor tenía un recurso superior al 75%:lecturas en SQLRS3. Por lo demás, las consultas responsables del 75 % del tiempo de espera consumieron menos del 75 % de los recursos, a menudo mucho menos. Esto refleja lo que vimos en el sistema del cliente y es coherente con el análisis de correlación.
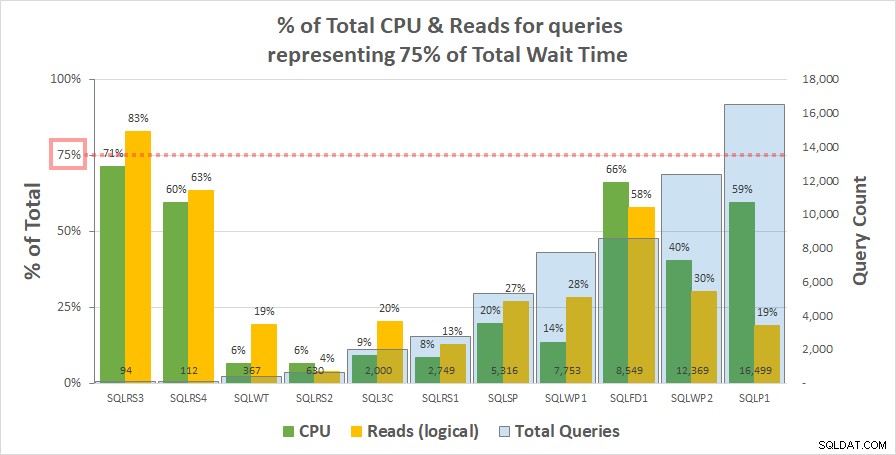 Gráfico 1
Gráfico 1
Tenga en cuenta que parece haber una relación con el número total de consultas en la carga de trabajo. Esto está representado por la serie de columnas de color azul claro en el eje y secundario y el gráfico está ordenado de forma ascendente por esta serie. Los dos servidores con las medidas de recursos más altas con un 75 % de esperas también tuvieron la menor cantidad de consultas (SQLRS3 y SQLRS4). Cuanto menor sea el conjunto de cargas de trabajo, mayor será la influencia potencial de una pequeña cantidad de consultas y, por supuesto, en ambos servidores, solo dos consultas representaron la mayoría de las esperas y los recursos. Una forma de ver esto es que las esperas ayudan más a identificar sus consultas más pesadas cuando menos las necesita.
Tiempo de espera y duración de la consulta
Finalmente, evalué el % del tiempo total de espera a la duración total de la consulta en cada sistema. Tabla 3 tiene columnas para:
- Duración total de la consulta en ms
- Tiempo de espera total en ms:sin procesar
- Tiempo de espera total en ms:sin paralelismo, inactividad ni esperas de usuario (Rev1)
- Tiempo de espera total en ms:sin paralelismo, inactividad, esperas de usuario y CPU (Rev2)
- El % de duración de las 3 columnas de tiempo de espera, con barras de datos
- Recuento total de consultas únicas, con barras de datos
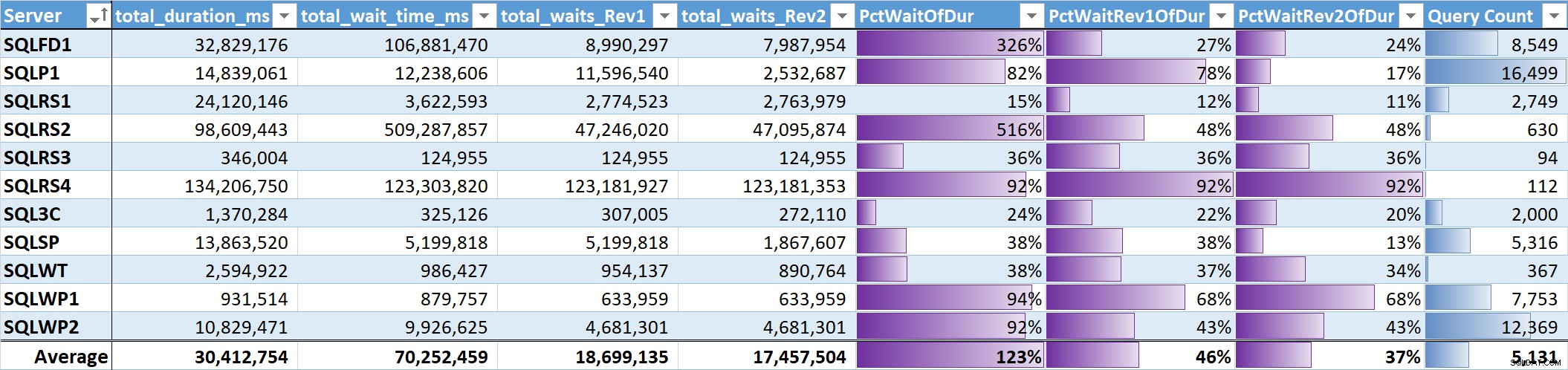 Tabla 3
Tabla 3
El promedio no ponderado de las esperas significativas (Rev2) en todos los sistemas es el 37 % de la duración total de la consulta. En cinco de los sistemas fue inferior al 25 %, y solo en dos sistemas superó el 50 %. En el sistema con un tiempo de espera del 92 % (SQLRS4), uno con la menor cantidad de consultas, dos consultas representaron el 99 % de las esperas, el 97 % de la duración, el 84 % de la CPU y el 86 % de las lecturas.
Aunque el tiempo de espera puede representar una parte significativa del tiempo de ejecución de la consulta en ciertos sistemas, y parece intuitivo que si reduce el tiempo de espera, la duración de la consulta también disminuirá, hemos visto que el tiempo de espera y la duración están poco correlacionados. Es poco probable que sea tan simple, y mi propia experiencia lo corrobora. Se necesita más investigación aquí.
Ajuste integral con Plan Explorer y SQL Sentry
Como sugiere con frecuencia este excelente documento técnico de SQLskills, la raíz de las largas esperas suele ser consultas e índices no optimizados. El SentryOne Plan Explorer gratuito está diseñado específicamente para reducir el consumo de recursos a través de un ajuste de consultas eficiente utilizando su módulo de análisis de índice y muchas otras características innovadoras. SQL Sentry integra Plan Explorer directamente en los módulos Top SQL, Blocking y Deadlocks, para que pueda capturar y ajustar automáticamente las consultas problemáticas en un solo lugar. Puede seleccionar fácilmente un rango de interés en los gráficos históricos de espera, CPU o IO del tablero de SQL Sentry y saltar a la vista Top SQL para encontrar las principales consultas que consumen recursos durante ese tiempo. Luego, con un solo clic, puede abrir una consulta en Plan Explorer y obtener esperas detalladas a nivel de consulta y recursos a pedido cuando sea necesario. No creo que haya una mejor encarnación de la metodología de ajuste completa de esperas y colas que esta.
 Gráfico de "Esperas" de SQL Sentry Dashboard
Gráfico de "Esperas" de SQL Sentry Dashboard
 El explorador de planes SentryOne gratuito que muestra las esperas a lo largo del tiempo, junto con el nivel de operación costes y recursos
El explorador de planes SentryOne gratuito que muestra las esperas a lo largo del tiempo, junto con el nivel de operación costes y recursos
Conclusión
Ajustar las esperas y las colas es tan aplicable al rendimiento de SQL Server hoy como lo era en 2006. Sin embargo, centrarse en las esperas con exclusión de los recursos es un negocio peligroso, ya que está claro a partir de los datos que hacerlo conducirá a resultados generalmente no optimizados y sistemas rentables. Cuando se trata de recursos de hardware y gasto en la nube, en última instancia, está pagando por los recursos informáticos y de E/S, no por el tiempo de espera, por lo que es conveniente optimizar directamente para el consumo. En mi experiencia, a medida que se reduce el consumo de recursos y la contención relacionada, el tiempo de espera se reducirá naturalmente.
Reconocimiento
Quería agradecer a Fred Frost, científico principal de datos de SentryOne, por su valioso aporte y revisión crítica de este análisis.