Hay dos habilidades complementarias que son muy útiles en el ajuste de consultas. Una es la capacidad de leer e interpretar los planes de ejecución. El segundo es saber un poco sobre cómo funciona el optimizador de consultas para traducir texto SQL en un plan de ejecución. Poner las dos cosas juntas puede ayudarnos a detectar momentos en los que no se aplicó una optimización esperada, lo que da como resultado un plan de ejecución que no es tan eficiente como podría ser. Sin embargo, la falta de documentación sobre exactamente qué optimizaciones puede aplicar SQL Server (y en qué circunstancias) significa que gran parte de esto se reduce a la experiencia.
Un ejemplo
La consulta de muestra para este artículo se basa en la pregunta realizada por Fabiano Amorim, MVP de SQL Server, hace unos meses, en función de un problema del mundo real que encontró. El esquema y la consulta de prueba a continuación es una simplificación de la situación real, pero conserva todas las características importantes.
CREATE TABLE dbo.T1 (pk integer PRIMARY KEY, c1 integer NOT NULL);
CREATE TABLE dbo.T2 (pk integer PRIMARY KEY, c1 integer NOT NULL);
CREATE TABLE dbo.T3 (pk integer PRIMARY KEY, c1 integer NOT NULL);
GO
CREATE INDEX nc1 ON dbo.T1 (c1);
CREATE INDEX nc1 ON dbo.T2 (c1);
CREATE INDEX nc1 ON dbo.T3 (c1);
GO
CREATE VIEW dbo.V1
AS
SELECT c1 FROM dbo.T1
UNION ALL
SELECT c1 FROM dbo.T2
UNION ALL
SELECT c1 FROM dbo.T3;
GO
-- The test query
SELECT MAX(c1)
FROM dbo.V1; Prueba 1:10 000 filas, SQL Server 2005+
Los datos específicos de la tabla realmente no importan para estas pruebas. Las siguientes consultas simplemente cargan 10 000 filas de una tabla de números a cada una de las tres tablas de prueba:
INSERT dbo.T1 (pk, c1) SELECT n, n FROM dbo.Numbers AS N WHERE n BETWEEN 1 AND 10000; INSERT dbo.T2 (pk, c1) SELECT pk, c1 FROM dbo.T1; INSERT dbo.T3 (pk, c1) SELECT pk, c1 FROM dbo.T1;
Con los datos cargados, el plan de ejecución producido para la consulta de prueba es:
SELECT MAX(c1) FROM dbo.V1;
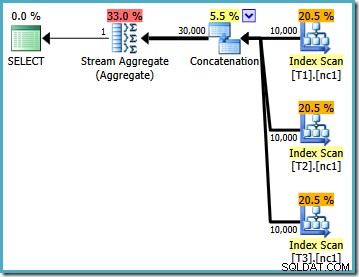
Este plan de ejecución es una implementación bastante directa de la consulta SQL lógica (después de expandir la referencia de vista V1). El optimizador ve la consulta después de la expansión de la vista, casi como si la consulta se hubiera escrito en su totalidad:
SELECT MAX(c1)
FROM
(
SELECT c1 FROM dbo.T1
UNION ALL
SELECT c1 FROM dbo.T2
UNION ALL
SELECT c1 FROM dbo.T3
) AS V1;
Al comparar el texto expandido con el plan de ejecución, la franqueza de la implementación del optimizador de consultas es clara. Hay un escaneo de índice para cada lectura de las tablas base, un operador de concatenación para implementar UNION ALL y un Stream Aggregate para el MAX final agregado.
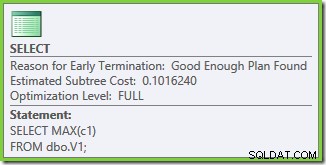
Las propiedades del plan de ejecución muestran que se inició la optimización basada en costos (el nivel de optimización es FULL ), pero que terminó antes de tiempo porque se encontró un plan "suficientemente bueno". El costo estimado del plan seleccionado es 0.1016240 unidades optimizadoras mágicas.
Prueba 2:50 000 filas, SQL Server 2008 y 2008 R2
Ejecute el siguiente script para restablecer el entorno de prueba para que se ejecute con 50 000 filas:
TRUNCATE TABLE dbo.T1; TRUNCATE TABLE dbo.T2; TRUNCATE TABLE dbo.T3; INSERT dbo.T1 (pk, c1) SELECT n, n FROM dbo.Numbers AS N WHERE n BETWEEN 1 AND 50000; INSERT dbo.T2 (pk, c1) SELECT pk, c1 FROM dbo.T1; INSERT dbo.T3 (pk, c1) SELECT pk, c1 FROM dbo.T1; SELECT MAX(c1) FROM dbo.V1;
El plan de ejecución de esta prueba depende de la versión de SQL Server que esté ejecutando. En SQL Server 2008 y 2008 R2, obtenemos el siguiente plan:
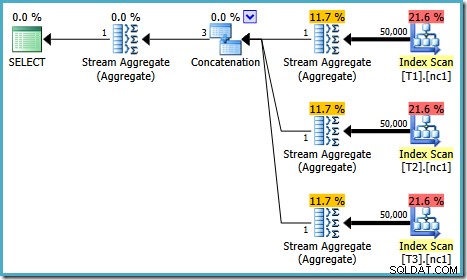
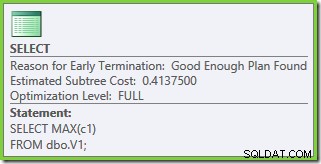
Las propiedades del plan muestran que la optimización basada en costos aún terminó antes de tiempo por la misma razón que antes. El costo estimado es más alto que antes en 0.41375 unidades, pero eso es de esperar debido a la mayor cardinalidad de las tablas base.
Prueba 3:50 000 filas, SQL Server 2005 y 2012
La misma consulta ejecutada en 2005 o 2012 produce un plan de ejecución diferente:
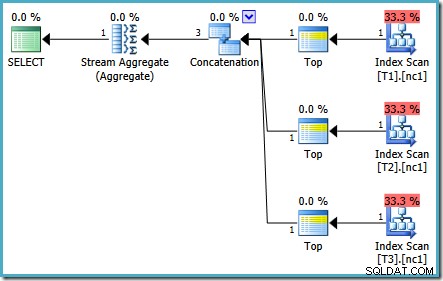
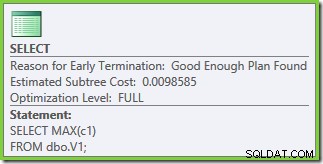
La optimización finalizó antes de tiempo nuevamente, pero el costo estimado del plan para 50 000 filas por tabla base se redujo a 0.0098585 (desde 0.41375 en SQL Server 2008 y 2008 R2).
Explicación
Como sabrá, el optimizador de consultas de SQL Server separa el esfuerzo de optimización en varias etapas, y las etapas posteriores agregan más técnicas de optimización y permiten más tiempo. Las etapas de optimización son:
- Plan trivial
- Optimización basada en costos
- Procesamiento de transacciones (búsqueda 0)
- Plan rápido (búsqueda 1)
- Plan rápido con paralelismo habilitado
- Optimización completa (búsqueda 2)
Ninguna de las pruebas realizadas aquí califica para un plan trivial porque el agregado y las uniones tienen múltiples posibilidades de implementación, lo que requiere una decisión basada en costos.
Procesamiento de transacciones
La etapa de procesamiento de transacciones (TP) requiere que una consulta contenga al menos tres referencias de tabla; de lo contrario, la optimización basada en costos omite esta etapa y pasa directamente al plan rápido. La etapa TP está dirigida a las consultas de navegación de bajo costo típicas de las cargas de trabajo de OLTP. Prueba un número limitado de técnicas de optimización y se limita a encontrar planes con combinaciones de bucle anidado (a menos que se necesite una combinación hash para generar un plan válido).
En algunos aspectos, sorprende que la consulta de prueba califique para una etapa destinada a encontrar planes OLTP. Aunque la consulta contiene las tres referencias de tabla requeridas, no contiene combinaciones. El requisito de las tres tablas es solo una heurística, por lo que no profundizaré en el punto.
¿Qué etapas del optimizador se ejecutaron?
Hay varios métodos, el documentado es comparar el contenido de sys.dm_exec_query_optimizer_info antes y después de la compilación. Esto está bien, pero registra información de toda la instancia, por lo que debe tener cuidado de que la suya sea la única compilación de consultas que ocurre entre las instantáneas.
Una alternativa no documentada (pero bastante conocida) que funciona en todas las versiones compatibles actualmente de SQL Server es habilitar los indicadores de seguimiento 8675 y 3604 mientras se compila la consulta.
Prueba 1
Esta prueba produce una salida de indicador de seguimiento 8675 similar a la siguiente:

El costo estimado de 0.101624 después de la etapa TP es lo suficientemente bajo como para que el optimizador no busque planes más baratos. El plan simple con el que terminamos es bastante razonable dada la cardinalidad relativamente baja de las tablas base, incluso si no es realmente óptimo.
Prueba 2
Con 50 000 filas en cada tabla base, el indicador de seguimiento revela información diferente:

Esta vez, el costo estimado después de la etapa TP es 0.428735 (más filas =mayor costo). Esto es suficiente para animar al optimizador a entrar en la etapa de Plan rápido. Con más técnicas de optimización disponibles, esta etapa encuentra un plan con un costo de 0.41375 . Esto no representa una gran mejora con respecto al plan de prueba 1, pero es más bajo que el umbral de costo predeterminado para el paralelismo y no es suficiente para ingresar a la Optimización completa, por lo que nuevamente la optimización finaliza antes de tiempo.
Prueba 3
Para la ejecución de SQL Server 2005 y 2012, el resultado del indicador de seguimiento es:

Hay pequeñas diferencias en la cantidad de tareas que se ejecutan entre las versiones, pero la diferencia importante es que en SQL Server 2005 y 2012, la etapa Plan rápido encuentra un plan que cuesta solo 0,0098543. unidades. Este es el plan que contiene operadores principales en lugar de los tres agregados de flujo debajo del operador de concatenación que se ve en los planes de SQL Server 2008 y 2008 R2.
Errores y correcciones no documentadas
SQL Server 2008 y 2008 R2 contienen un error de regresión (en comparación con 2005) que se corrigió bajo el indicador de seguimiento 4199, pero no está documentado hasta donde puedo decir. Hay documentación para TF 4199 que enumera las correcciones disponibles bajo marcas de rastreo separadas antes de ser cubiertas por 4199, pero como dice ese artículo de Knowledge Base:
Esta marca de seguimiento se puede usar para habilitar todas las correcciones que se realizaron previamente para el procesador de consultas bajo muchas marcas de seguimiento. Además, todas las correcciones futuras del procesador de consultas se controlarán mediante esta marca de rastreo.
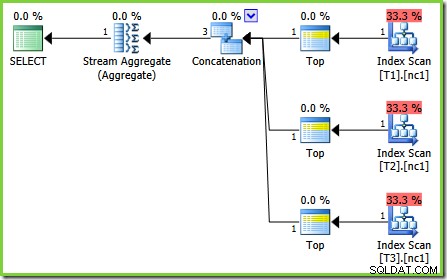
El error en este caso es una de esas "futuras correcciones del procesador de consultas". Una regla de optimización particular, ScalarGbAggToTop , no se aplica a los nuevos agregados vistos en el plan de prueba 2. Con la marca de rastreo 4199 habilitada en compilaciones adecuadas de SQL Server 2008 y 2008 R2, el error se corrige y se obtiene el plan óptimo de la prueba 3:
-- Trace flag 4199 required for 2008 and 2008 R2 SELECT MAX(c1) FROM dbo.V1 OPTION (QUERYTRACEON 4199);
Conclusión
Una vez que sepa que el optimizador puede transformar un escalar MIN o MAX agregado a un TOP (1) en un flujo ordenado, el plan que se muestra en la prueba 2 parece extraño. Los agregados escalares sobre un escaneo de índice (que puede proporcionar orden si se le solicita) se destacan como una optimización perdida que normalmente se aplicaría.
Este es el punto que estaba señalando en la introducción:una vez que tenga una idea del tipo de cosas que puede hacer el optimizador, puede ayudarlo a reconocer los casos en los que algo salió mal.
La respuesta no siempre será habilitar el indicador de seguimiento 4199, ya que es posible que encuentre problemas que aún no se han solucionado. También es posible que no desee que las otras correcciones de QP cubiertas por el indicador de seguimiento se apliquen en un caso particular:las correcciones del optimizador no siempre mejoran las cosas. Si lo hicieran, no habría necesidad de protegerse contra regresiones desafortunadas del plan usando esta bandera.
La solución en otros casos podría ser formular la consulta SQL usando una sintaxis diferente, para dividir la consulta en fragmentos más amigables con el optimizador, o algo completamente distinto. Cualquiera que sea la respuesta, aún vale la pena saber un poco sobre las funciones internas del optimizador para que pueda reconocer que hubo un problema en primer lugar :)



