¿Te gusta analizar cadenas? Si es así, una de las funciones de cadena indispensables para usar es SUBSTRING SQL. Es una de esas habilidades que un desarrollador debe tener para cualquier idioma.
Entonces, ¿cómo lo haces?
Puntos importantes en el análisis de cadenas
Suponga que es nuevo en el análisis. ¿Qué puntos importantes necesitas recordar?
- Sepa qué información está incrustada dentro de la cadena.
- Obtenga las posiciones exactas de cada pieza de información en una cadena. Puede que tenga que contar todos los caracteres dentro de la cadena.
- Sepa el tamaño o la longitud de cada pieza de información en una cadena.
- Utilice la función de cadena correcta que puede extraer fácilmente cada pieza de información en la cadena.
Conocer todos estos factores lo preparará para usar SQL SUBSTRING() y pasarle argumentos.
Sintaxis de SUBCADENA SQL

La sintaxis de SQL SUBSTRING es la siguiente:
SUBSTRING(expresión de cadena, inicio, longitud)
- expresión de cadena – un cadena literal o una expresión SQL que devuelve una cadena.
- empezar – un número donde comenzará la extracción. También se basa en 1:el primer carácter en el argumento de expresión de cadena debe comenzar con 1, no con 0. En SQL Server, siempre es un número positivo. En MySQL u Oracle, sin embargo, puede ser positivo o negativo. Si es negativo, el escaneo comienza desde el final de la cadena.
- longitud – la longitud de los caracteres a extraer. SQL Server lo requiere. En MySQL u Oracle, es opcional.
4 ejemplos de SUBCADENA SQL
1. Uso de SQL SUBSTRING para extraer de una cadena literal
Comencemos con un ejemplo simple usando una cadena literal. Usamos el nombre de un famoso grupo femenino coreano, BlackPink, y la Figura 1 ilustra cómo funcionará SUBSTRING:

El siguiente código muestra cómo lo extraeremos:
-- extract 'black' from BlackPink (English)
SELECT SUBSTRING('BlackPink',1,5) AS result
Ahora, también inspeccionemos el conjunto de resultados en la Figura 2:
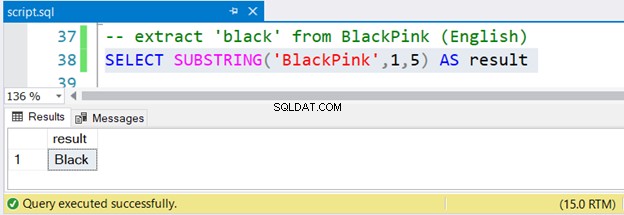
¿No es fácil?
Para extraer Negro de BlackPink , comienzas desde la posición 1 y terminas en la posición 5. Desde BlackPink es coreano, averigüemos si SUBSTRING funciona con caracteres coreanos Unicode.
(DESCARGO DE RESPONSABILIDAD :No puedo hablar, leer o escribir coreano, así que obtuve la traducción al coreano de Wikipedia. También usé Google Translate para ver qué caracteres corresponden a Black y rosa . Por favor, perdóname si está mal. Aún así, espero que llegue el punto que estoy tratando de aclarar de ancho)
Tengamos la cadena en coreano (ver Figura 3). Los caracteres coreanos utilizados se traducen a BlackPink:

Ahora, vea el código a continuación. Extraeremos dos caracteres correspondientes a Negro .
-- extract 'black' from BlackPink (Korean)
SELECT SUBSTRING(N'블랙핑크',1,2) AS result
¿Notaste la cadena coreana precedida por N? ? Utiliza caracteres Unicode, y SQL Server asume NVARCHAR y debe estar precedido por N . Esa es la única diferencia en la versión en inglés. ¿Pero funcionará bien? Ver figura 4:
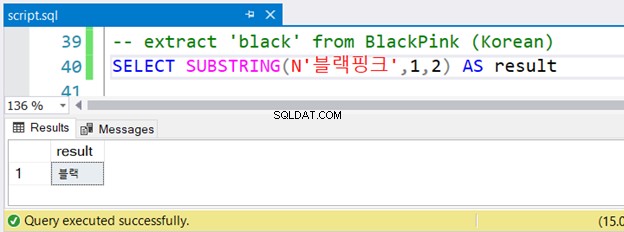
Se ejecutó sin errores.
2. Uso de SQL SUBSTRING en MySQL con un argumento de inicio negativo
Tener un argumento de inicio negativo no funcionará en SQL Server. Pero podemos tener un ejemplo de esto usando MySQL. Esta vez, extraigamos Rosa de BlackPink . Aquí está el código:
-- Extract 'Pink' from BlackPink using MySQL Substring (English)
select substring('BlackPink',-4,4) as result;
Ahora, veamos el resultado en la Figura 5:
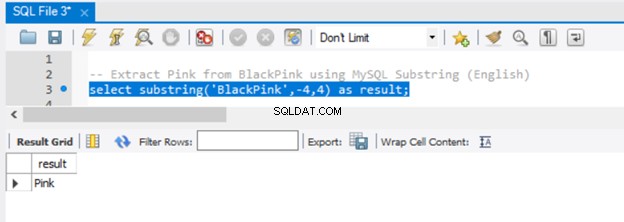
Dado que pasamos -4 al parámetro de inicio, la extracción comenzó desde el final de la cadena, retrocediendo 4 caracteres. Para lograr el mismo resultado en SQL Server, use la función RIGHT().
Los caracteres Unicode también funcionan con SUBSTRING de MySQL, como puede ver en la Figura 6:
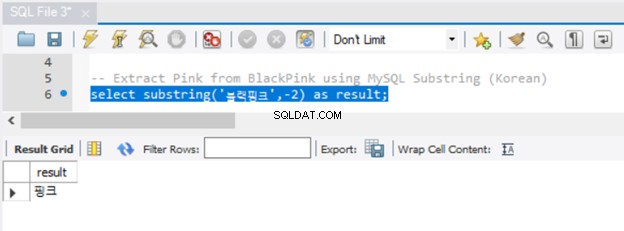
Funcionó muy bien. Pero, ¿se dio cuenta de que no necesitábamos preceder la cadena con N? Además, tenga en cuenta que hay varias formas de obtener una subcadena en MySQL. Ya has visto SUBSTRING. Las funciones equivalentes en MySQL son SUBSTR() y MID().
3. Análisis de subcadenas con argumentos de inicio y longitud variables
Lamentablemente, no todas las extracciones de cadenas utilizan argumentos fijos de inicio y longitud. En tal caso, necesita CHARINDEX para obtener la posición de una cadena a la que se dirige. Pongamos un ejemplo:
DECLARE @lineString NVARCHAR(30) = N'김제니 01/16/example@sqldat.com'
DECLARE @name NVARCHAR(5)
DECLARE @bday DATE
DECLARE @instagram VARCHAR(20)
SET @name = SUBSTRING(@lineString,1,CHARINDEX('@',@lineString)-11)
SET @bday = SUBSTRING(@lineString,CHARINDEX('@',@lineString)-10,10)
SET @instagram = SUBSTRING(@lineString,CHARINDEX('@',@lineString),30)
SELECT @name AS [Name], @bday AS [BirthDate], @instagram AS [InstagramAccount]
En el código anterior, debe extraer un nombre en coreano, la fecha de nacimiento y la cuenta de Instagram.
Comenzamos con la definición de tres variables para contener esas piezas de información. Después de eso, podemos analizar la cadena y asignar los resultados a cada variable.
Puede pensar que tener inicios y longitudes fijos es más simple. Además, podemos localizarlo contando los caracteres manualmente. Pero, ¿y si tienes muchos de estos en una mesa?
Aquí está nuestro análisis:
- El único elemento fijo en la cadena es @ personaje en la cuenta de Instagram. Podemos obtener su posición en la cadena usando CHARINDEX. Luego, usamos esa posición para obtener el inicio y la duración del resto.
- La fecha de nacimiento tiene un formato fijo usando MM/dd/yyyy con 10 caracteres.
- Para extraer el nombre, comenzamos en 1. Ya que la fecha de nacimiento tiene 10 caracteres más la @ carácter, puede llegar al carácter final del nombre en la cadena. Desde la posición del @ carácter, retrocedemos 11 caracteres. La SUBCADENA(@lineString,1,CHARINDEX(‘@’,@lineString)-11) es el camino a seguir.
- Para obtener la fecha de nacimiento, aplicamos la misma lógica. Obtener la posición del @ carácter y retroceda 10 caracteres para obtener el valor inicial de la fecha de nacimiento. 10 es una longitud fija. SUBCADENA(@lineString,CHARINDEX(‘@’,@lineString)-10,10) es cómo obtener la fecha de nacimiento.
- Por último, obtener una cuenta de Instagram es sencillo. Comience desde la posición de @ personaje usando CHARINDEX. Nota:30 es el límite de nombre de usuario de Instagram.
Mira los resultados en la Figura 7:
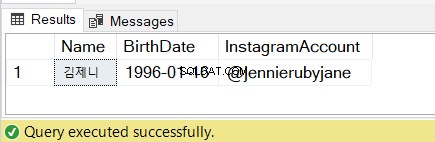
4. Uso de SQL SUBSTRING en una instrucción SELECT
También puede usar SUBSTRING en la declaración SELECT, pero primero, necesitamos tener datos de trabajo. Aquí está el código:
SELECT
CAST(P.LastName AS CHAR(50))
+ CAST(P.FirstName AS CHAR(50))
+ CAST(ISNULL(P.MiddleName,'') AS CHAR(50))
+ CAST(ea.EmailAddress AS CHAR(50))
+ CAST(a.City AS CHAR(30))
+ CAST(a.PostalCode AS CHAR(15)) AS line
INTO PersonContacts
FROM Person.Person p
INNER JOIN Person.EmailAddress ea
ON P.BusinessEntityID = ea.BusinessEntityID
INNER JOIN Person.BusinessEntityAddress bea
ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Person.Address a
ON bea.AddressID = a.AddressID
El código anterior forma una cadena larga que contiene el nombre, la dirección de correo electrónico, la ciudad y el código postal. También queremos almacenarlo en PersonContacts mesa.
Ahora, tengamos el código para aplicar ingeniería inversa usando SUBSTRING:
SELECT
TRIM(SUBSTRING(line,1,50)) AS [LastName]
,TRIM(SUBSTRING(line,51,50)) AS [FirstName]
,TRIM(SUBSTRING(line,101,50)) AS [MiddleName]
,TRIM(SUBSTRING(line,151,50)) AS [EmailAddress]
,TRIM(SUBSTRING(line,201,30)) AS [City]
,TRIM(SUBSTRING(line,231,15)) AS [PostalCode]
FROM PersonContacts pc
ORDER BY LastName, FirstName
Como usamos columnas de tamaño fijo, no es necesario usar CHARINDEX.
Uso de SQL SUBSTRING en una cláusula WHERE:¿una trampa de rendimiento?
Es cierto. Nadie puede impedirle usar SUBSTRING en una cláusula WHERE. Es una sintaxis válida. Pero, ¿y si causa problemas de rendimiento?
Es por eso que lo demostramos con un ejemplo y luego discutimos cómo solucionar este problema. Pero primero, preparemos nuestros datos:
USE AdventureWorks
GO
SELECT * INTO SalesOrders FROM Sales.SalesOrderHeader soh
No puedo estropear el SalesOrderHeader mesa, así que lo tiré a otra mesa. Luego, hice el SalesOrderID en los nuevos Pedidos de Venta tabla una clave principal.
Ahora, estamos listos para la consulta. Estoy usando dbForge Studio para SQL Server con Modo de generación de perfiles de consultas activado para analizar las consultas.
SELECT
so.SalesOrderID
,so.OrderDate
,so.CustomerID
,so.AccountNumber
FROM SalesOrders so
WHERE SUBSTRING(so.AccountNumber,4,4) = '4030'
Como puede ver, la consulta anterior funciona bien. Ahora, mire el diagrama del plan de perfil de consulta en la figura 8:
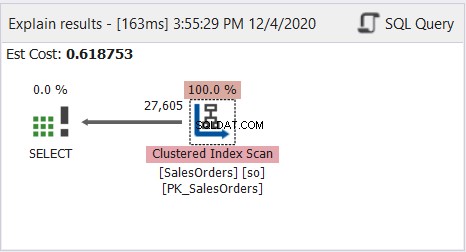
El diagrama del plan parece simple, pero inspeccionemos las propiedades del nodo Análisis de índice agrupado. En particular, necesitamos la información de tiempo de ejecución:
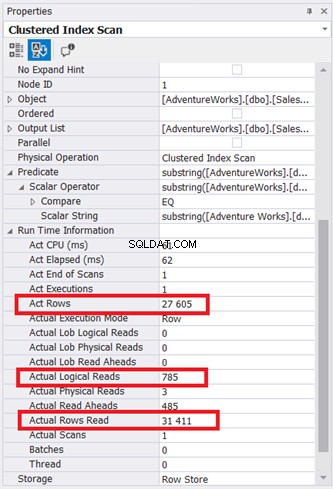
La Ilustración 9 muestra páginas de 785 * 8 KB leídas por el motor de la base de datos. Observe también que la lectura de filas reales es 31.411. Es el número total de filas en la tabla. Sin embargo, la consulta devolvió solo 27 605 filas reales.
Se leyó toda la tabla utilizando el índice agrupado como referencia.
¿Por qué?
La cuestión es que SQL Server necesita saber si 4030 es una subcadena de un número de cuenta. Debe leer y evaluar cada registro. Descartar las filas que no son iguales y devolver las filas que necesitamos. Hace el trabajo pero no lo suficientemente rápido.
¿Qué podemos hacer para que funcione más rápido?
Evite SUBSTRING en la cláusula WHERE y obtenga el mismo resultado más rápido
Lo que queremos ahora es obtener el mismo resultado sin usar SUBSTRING en la cláusula WHERE. Siga los pasos a continuación:
- Modifique la tabla agregando una columna calculada con una SUBCADENA(Número de Cuenta, 4,4) fórmula. Llamémoslo AccountCategory a falta de un término mejor.
- Cree un índice no agrupado para la nueva AccountCategory columna. Incluya la Fecha del pedido , Número de cuenta y ID de cliente columnas.
Eso es todo.
Cambiamos la cláusula WHERE de la consulta para adaptar la nueva AccountCategory columna:
SET STATISTICS IO ON
SELECT
so.SalesOrderID
,so.OrderDate
,so.CustomerID
,so.AccountNumber
FROM SalesOrders so
WHERE so.AccountCategory = '4030'
SET STATISTICS IO OFF
No hay SUBSTRING en la cláusula WHERE. Ahora, revisemos el diagrama del plan:
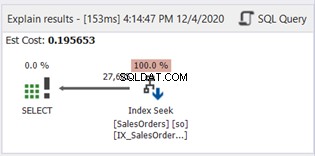
Index Scan ha sido reemplazado por Index Seek. Observe también que SQL Server utilizó el nuevo índice en la columna calculada. ¿Hay también cambios en las lecturas lógicas y las filas reales leídas? Ver Figura 11:
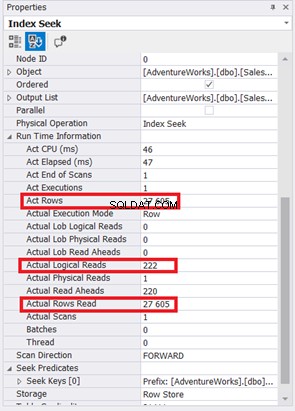
Reducir de 785 a 222 lecturas lógicas es una gran mejora, más de tres veces menos que las lecturas lógicas originales. También minimizó la lectura de filas reales a solo aquellas filas que necesitamos.
Por lo tanto, el uso de SUBSTRING en la cláusula WHERE no es bueno para el rendimiento y sirve para cualquier otra función con valores escalares utilizada en la cláusula WHERE.
Conclusión
- Los desarrolladores no pueden evitar analizar cadenas. De una forma u otra surgirá la necesidad.
- Al analizar cadenas, es esencial conocer la información dentro de la cadena, las posiciones de cada pieza de información y sus tamaños o longitudes.
- Una de las funciones de análisis es SUBSTRING SQL. Solo necesita la cadena para analizar, la posición para iniciar la extracción y la longitud de la cadena para extraer.
- SUBSTRING puede tener diferentes comportamientos entre tipos de SQL como SQL Server, MySQL y Oracle.
- Puede usar SUBSTRING con cadenas literales y cadenas en las columnas de la tabla.
- También usamos SUBSTRING con caracteres Unicode.
- Usar SUBSTRING o cualquier función con valores escalares en la cláusula WHERE puede reducir el rendimiento de las consultas. Solucione esto con una columna calculada indexada.
Si encuentra útil esta publicación, compártala en sus plataformas de redes sociales preferidas o comparta su comentario a continuación.