Implementar una búsqueda fácil de usar puede ser complicado, pero también se puede hacer de manera muy eficiente. ¿Cómo sé esto? No hace mucho, necesitaba implementar un motor de búsqueda en una aplicación móvil. La aplicación se creó en el marco Ionic y se conectaría a un backend CakePHP 2. La idea era mostrar los resultados a medida que el usuario escribía. Había varias opciones para esto, pero no todas cumplían con los requisitos de mi proyecto.
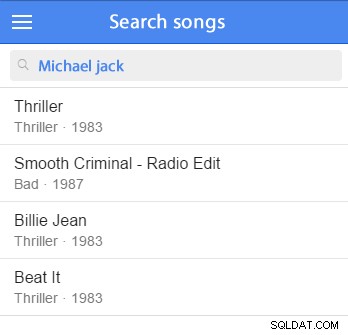
Para ilustrar lo que implica este tipo de tarea, imaginemos la búsqueda de canciones y sus posibles relaciones (como artistas, álbumes, etc.).
Los registros tendrían que ordenarse por relevancia, lo que dependería de si la palabra de búsqueda coincidía con campos del propio registro o de otras columnas en tablas relacionadas. Además, la búsqueda debe implementar al menos alguna derivación básica de palabras. (La derivación se usa para obtener la raíz de una palabra. "Raíces", "derivación", "derivación" y "derivación" tienen la misma raíz:"raíz".)
El enfoque que se presenta aquí se probó con varios cientos de miles de registros y pudo recuperar resultados útiles mientras el usuario escribía.
Productos de búsqueda de texto completo a tener en cuenta
Hay varias formas de implementar este tipo de búsqueda. Nuestro proyecto tenía algunas limitaciones en relación con el tiempo y los recursos del servidor, por lo que teníamos que mantener la solución lo más simple posible. Eventualmente surgieron un par de contendientes:
Búsqueda elástica
Elasticsearch proporciona búsquedas de texto completo en un servicio orientado a documentos. Está diseñado para gestionar grandes cantidades de carga de forma distribuida:puede clasificar los resultados por relevancia, realizar agregaciones y trabajar con la derivación de palabras y sinónimos Esta herramienta está pensada para búsquedas en tiempo real. Desde su sitio web:
Elasticsearch crea capacidades distribuidas sobre Apache Lucene para proporcionar las capacidades de búsqueda de texto completo más potentes disponibles. La API de consulta potente y fácil de usar para desarrolladores admite búsquedas multilingües, geolocalización, sugerencias contextuales de tipo quisiste decir, autocompletado y fragmentos de resultados.
Elasticsearch puede funcionar como un servicio REST, respondiendo a solicitudes http y se puede configurar muy rápidamente. Sin embargo, iniciar el motor como un servicio requiere que tenga algunos privilegios de acceso al servidor. Y si su proveedor de alojamiento no es compatible con Elasticsearch desde el primer momento, deberá instalar algunos paquetes.
La conclusión es que este producto es una excelente opción si desea una solución de búsqueda sólida como una roca. (Nota:es posible que necesite un VPS o un servidor dedicado, ya que los requisitos de hardware son bastante exigentes).
Esfinge
Al igual que Elasticsearch, Sphinx también proporciona un producto de búsqueda de texto completo muy sólido:Craigslist atiende más de 300 000 000 consultas por día con él. Sphinx no proporciona una interfaz RESTful nativa. Se implementa en C, con una huella de hardware más pequeña que Elasticsearch (que se implementa en Java y puede ejecutarse en cualquier sistema operativo con jvm). También necesitará acceso de root al servidor con alguna RAM/CPU dedicada para ejecutar Sphinx correctamente.
Búsqueda de texto completo de MySQL
Históricamente, las búsquedas de texto completo eran compatibles con los motores MyISAM. Después de la versión 5.6, MySQL también admitía búsquedas de texto completo en motores de almacenamiento InnoDB. Esta ha sido una gran noticia, ya que permite a los desarrolladores beneficiarse de la integridad referencial, la capacidad para realizar transacciones y los bloqueos de nivel de fila de InnoDB.
Básicamente, existen dos enfoques para las búsquedas de texto completo en MySQL:lenguaje natural y modo booleano. (Una tercera opción aumenta la búsqueda en lenguaje natural con una segunda consulta de expansión).
La principal diferencia entre los modos natural y booleano es que el booleano permite ciertos operadores como parte de la búsqueda. Por ejemplo, se pueden usar operadores booleanos si una palabra tiene mayor relevancia que otras en la consulta o si una palabra específica debe estar presente en los resultados, etc. Vale la pena notar que en ambos casos, los resultados se pueden ordenar por la relevancia calculada por MySQL durante la búsqueda.
Tomar las decisiones
La mejor opción para nuestro problema fue usar búsquedas de texto completo de InnoDb en modo booleano. ¿Por qué?
- Tuvimos poco tiempo para implementar la función de búsqueda.
- En este punto, no teníamos grandes datos para procesar ni una carga masiva para requerir algo como Elasticsearch o Sphinx.
- Utilizamos alojamiento compartido que no es compatible con Elasticsearch o Sphinx y el hardware era bastante limitado en esta etapa.
- Aunque queríamos la derivación de palabras en nuestra función de búsqueda, no era un factor decisivo:podíamos implementarla (dentro de las limitaciones) a través de una simple codificación PHP y desnormalización de datos
- Las búsquedas de texto completo en modo booleano pueden buscar palabras con comodines (para la raíz de la palabra) y ordenar los resultados según su relevancia.
Búsquedas de texto completo en modo booleano
Como se mencionó anteriormente, la búsqueda en lenguaje natural es el enfoque más simple:simplemente busque una frase o una palabra en las columnas donde ha establecido un índice de texto completo y obtendrá resultados ordenados por relevancia.
En el Modelo Vertabelo Normalizado
Veamos cómo funcionaría una búsqueda simple. Primero crearemos una tabla de muestra:
-- Created by Vertabelo (https://vertabelo.com) -- Last modification date: 2016-04-25 15:01:22.153 -- tables -- Table: artists CREATE TABLE artists ( id int(11) NOT NULL AUTO_INCREMENT, name varchar(255) NOT NULL, bio text NOT NULL, CONSTRAINT artists_pk PRIMARY KEY (id) ) ENGINE InnoDB; CREATE FULLTEXT INDEX artists_idx_1 ON artists (name); -- End of file.
En modo de lenguaje natural
Puede insertar algunos datos de muestra y comenzar a probar. (Sería bueno agregarlo a su conjunto de datos de muestra). Por ejemplo, intentaremos buscar a Michael Jackson:
SELECT
*
FROM
artists
WHERE
MATCH (artists.name) AGAINST ('Michael Jackson' IN NATURAL LANGUAGE MODE)
Esta consulta encontrará registros que coincidan con los términos de búsqueda y ordenará los registros coincidentes por relevancia; cuanto mejor sea la coincidencia, más relevante será y más alto aparecerá el resultado en la lista.
En modo booleano
Podemos realizar la misma búsqueda en modo booleano. Si no aplicamos ningún operador a nuestra consulta, la única diferencia será que los resultados no ordenados por relevancia:
SELECT
*
FROM
artists
WHERE
MATCH (artists.name) AGAINST ('Michael Jackson' IN BOOLEAN MODE)
El operador comodín en modo booleano
Como queremos buscar palabras derivadas y parciales, necesitaremos el operador comodín (*). Este operador se puede utilizar en búsquedas en modo booleano, por lo que elegimos ese modo.
Entonces, liberemos el poder de la búsqueda booleana e intentemos buscar parte del nombre del artista. Usaremos el operador comodín para hacer coincidir cualquier artista cuyo nombre comience con "Mich":
SELECT
*
FROM
artists
WHERE
MATCH (name) AGAINST ('Mich*' IN BOOLEAN MODE)
Ordenar por relevancia en modo booleano
Ahora veamos la relevancia calculada para la búsqueda. Esto nos ayudará a comprender la clasificación que haremos más adelante con Cake:
SELECT
*, MATCH (name) AGAINST ('mich*' IN BOOLEAN MODE) AS rank
FROM
artists
WHERE
MATCH (name) AGAINST ('mich*' IN BOOLEAN MODE)
ORDER BY rank DESC
Esta consulta recupera coincidencias de búsqueda y el valor de relevancia que MySQL calcula para cada registro. El optimizador del motor detectará que estamos seleccionando la relevancia, por lo que no se molestará en volver a calcular la clasificación.
Lematización de palabras en la búsqueda de texto completo
Cuando incorporamos la derivación de palabras en una búsqueda, la búsqueda se vuelve más fácil de usar. Incluso si el resultado no es una palabra en sí misma, los algoritmos intentan generar la misma raíz para las palabras derivadas. Por ejemplo, la raíz "argu" no es una palabra en inglés, pero se puede usar como raíz para "argue", "argud", "argues", "arguing","Argus" y otras palabras.
Stemming mejora los resultados, ya que el usuario puede ingresar una palabra que no tiene una coincidencia exacta pero su "raíz" sí. Aunque el lematizador de PHP o el lematizador de Python de Snowball podrían ser una opción (si tiene acceso SSH raíz a su servidor), utilizaremos la clase PorterStemmer.php.
Esta clase implementa el algoritmo propuesto por Martin Porter para derivar palabras en inglés. Como afirma el autor en su sitio web, es de uso gratuito para cualquier propósito. Simplemente suelte el archivo dentro de su directorio de proveedores dentro de CakePHP, incluya la biblioteca en su modelo y llame al método estático para derivar una palabra:
//include the library (should be called PorterStemmer.php) within CakePHP’s Vendors folder
App::import('Vendor', 'PorterStemmer');
//stem a word (words must be stemmed one by one)
echo PorterStemmer::Stem(‘stemming’);
//output will be ‘stem’
Nuestro objetivo es hacer que la búsqueda sea rápida y eficiente y poder ordenar los resultados por su relevancia de texto completo. Para hacer esto, necesitaremos emplear la derivación de palabras de dos maneras:
- Las palabras ingresadas por el usuario
- Datos relacionados con la canción (que almacenaremos en columnas y ordenaremos los resultados según su relevancia)
El primer tipo de derivación de palabras se puede lograr así:
App::import('Vendor', 'PorterStemmer');
$search = trim(preg_replace('/[^A-Za-z0-9_\s]/', '', $search));//remove undesired characters
$words = explode(" ", trim($search));
$stemmedSearch = "";
$unstemmedSearch = "";
foreach ($words as $word) {
$stemmedSearch .= PorterStemmer::Stem($word) . "* ";//we add the wildcard after each word
$unstemmedSearch = $word . "* " ;//to search the artist column which is not stemmed
}
$stemmedSearch = trim($stemmedSearch);
$unstemmedSearch = trim($unstemmedSearch);
if ($stemmedSearch == "*" || $unstemmedSearch=="*") {
//otherwise mySql will complain, as you cannot use the wildcard alone
$stemmedSearch = "";
$unstemmedSearch = "";
}
Hemos creado dos cadenas:una para buscar el nombre del artista (sin derivación) y otra para buscar en las otras columnas derivadas. Esto nos ayudará a construir más tarde nuestro ‘contra’ parte de la consulta de texto completo. Ahora veamos cómo podemos derivar y ordenar los datos de la canción.
Desnormalización de datos de canciones
Nuestros criterios de clasificación se basarán en hacer coincidir el artista de la canción (sin derivación) primero. Luego vendrá el nombre de la canción, el álbum y las categorías relacionadas. La lematización se utilizará en todos los criterios de búsqueda secundarios.
Para ilustrar esto, supongamos que busco 'nirvana' y hay una canción llamada 'Nirvana Games' de 'XYZ', y otra canción llamada 'Polly' del artista 'Nirvana'. Los resultados deben mostrar 'Polly' primero, ya que la coincidencia con el nombre del artista es más importante que la coincidencia con el nombre de la canción (según mis criterios).
Para hacer esto, agregué 4 campos en las songs tabla, una para cada uno de los criterios de búsqueda/ordenación que queramos:
ALTER TABLE `songs` ADD `denorm_artist` VARCHAR(255) NOT NULL AFTER`trackname`, ADD `denorm_trackname` VARCHAR(500) NOT NULL AFTER`denorm_artist`, ADD `denorm_album` VARCHAR(255) NOT NULL AFTER`denorm_trackname`, ADD `denorm_categories` VARCHAR(500) NOT NULL AFTER`denorm_album`, ADD FULLTEXT (`denorm_artist`), ADD FULLTEXT(`denorm_trackname`), ADD FULLTEXT (`denorm_album`), ADD FULLTEXT(`denorm_categories`);
Nuestro modelo completo de base de datos se vería así:
Siempre que guarde una canción usando agregar/editar en CakePHP, solo necesita almacenar el nombre del artista en la columna denorm_artist sin detenerlo. A continuación, agregue el nombre de la pista derivada en denorm_trackname (similar a lo que hicimos en el texto buscado) y guarde el nombre del álbum derivado en el denorm_album columna. Finalmente, almacene el conjunto de categorías derivadas para la canción en denorm_categories campo, concatenando las palabras y agregando un espacio entre cada nombre de categoría derivada.
Búsqueda de texto completo y clasificación por relevancia en CakePHP
Continuando con el ejemplo de buscar 'Nirvana', veamos qué se puede lograr con una consulta similar a esta:
SELECT
trackname,
MATCH(denorm_artist) AGAINST ('Nirvana*' IN BOOLEAN MODE) as rank1,
MATCH(denorm_trackname) AGAINST ('Nirvana*' IN BOOLEAN MODE) as rank2,
MATCH(denorm_album) AGAINST ('Nirvana*' IN BOOLEAN MODE) as rank3,
MATCH(denorm_categories) AGAINST ('Nirvana*' IN BOOLEAN MODE) as rank4
FROM songs
WHERE
MATCH(denorm_artist) AGAINST ('Nirvana*' IN BOOLEAN MODE) OR
MATCH(denorm_trackname) AGAINST ('Nirvana*' IN BOOLEAN MODE) OR
MATCH(denorm_album) AGAINST ('Nirvana*' IN BOOLEAN MODE) OR
MATCH(denorm_categories) AGAINST ('Nirvana*' IN BOOLEAN MODE)
ORDER BY rank1 DESC, rank2 DESC, rank3 DESC, rank4 DESC
Obtendríamos el siguiente resultado:
| nombre de pista | rango1 | rango2 | rango 3 | rango 4 |
| Polly | 0,0906190574169159 | 0 | 0 | 0 |
| juegos de nirvana | 0 | 0,0906190574169159 | 0 | 0 |
Para hacer esto en CakePHP, el find El método debe llamarse usando una combinación de parámetros de 'campos', 'condiciones' y 'pedido'. Continuando con el código de ejemplo de PHP anterior:
//within Song.php model file
$fields = array(
"Song.trackname",
"MATCH(Song.denorm_artist) AGAINST ({$unstemmedSearch} IN BOOLEAN MODE) as `rank1`",
"MATCH(Song.denorm_trackname) AGAINST ({$stemmedSearch} IN BOOLEAN MODE) as `rank2`",
"MATCH(Song.denorm_album) AGAINST ({$stemmedSearch} IN BOOLEAN MODE) as `rank3`",
"MATCH(Song.denorm_categories) AGAINST ({$stemmedSearch} IN BOOLEAN MODE) as `rank4`"
);
$order = "`rank1` DESC,`rank2` DESC,`rank3` DESC,`rank4` DESC,Song.trackname ASC";
$conditions = array(
"OR" => array(
"MATCH(Song.denorm_artist) AGAINST ({$unstemmedSearch} IN BOOLEAN MODE)",
"MATCH(Song.denorm_trackname) AGAINST ({$stemmedSearch} IN BOOLEAN MODE)",
"MATCH(Song.denorm_album) AGAINST ({$stemmedSearch} IN BOOLEAN MODE)",
"MATCH(Song.denorm_categories) AGAINST ({$stemmedSearch} IN BOOLEAN MODE)"
)
);
$results = $this->find(‘all’,array(‘conditions’=>$conditions,’fields’=>$fields,’order’=>$order);
$resultados será la matriz de canciones ordenadas con los criterios que definimos anteriormente.
Esta solución se puede utilizar para generar búsquedas significativas para el usuario, sin requerir demasiado tiempo de los desarrolladores ni agregar una mayor complejidad al código.
Mejorando aún más las búsquedas de CakePHP
Vale la pena mencionar que "condimentar" las columnas desnormalizadas con más datos puede generar mejores resultados.
Por "condimentar" me refiero a que podría incluir, en las columnas desnormalizadas, más datos de columnas adicionales que considere útiles con el objetivo de hacer que los resultados sean más relevantes, por ejemplo, si supiera que el país de un artista podría figurar en los términos de búsqueda, podría agregar el país junto con el nombre del artista en el denorm_artist columna. Esto mejoraría la calidad de los resultados de búsqueda.
Desde mi experiencia (dependiendo de los datos reales que use y las columnas que desnormalice), los resultados superiores tienden a ser realmente precisos. Esto es excelente para las aplicaciones móviles, ya que desplazarse por una lista larga puede resultar frustrante para el usuario.
Finalmente, si necesita obtener más datos de las tablas con las que se relaciona la canción, siempre puede hacer una combinación y obtener el artista, las categorías, los álbumes, los comentarios de la canción, etc. Si está utilizando el filtro de comportamiento contenedor de CakePHP, me gustaría sugiera agregar el complemento EagerLoader para lograr las uniones de manera eficiente.
Si tiene su propio enfoque para implementar la búsqueda de texto completo, compártalo en los comentarios a continuación. Todos podemos aprender de la experiencia de los demás.