Las bases de datos deben funcionar de manera óptima, pero esa no es una tarea tan fácil. La base de datos INFORMATION SCHEMA puede ser su arma secreta en la guerra de la optimización de bases de datos.
Estamos acostumbrados a crear bases de datos utilizando una interfaz gráfica o una serie de comandos SQL. Eso está completamente bien, pero también es bueno comprender un poco lo que sucede en segundo plano. Esto es importante para la creación, el mantenimiento y la optimización de una base de datos, y también es una buena manera de realizar un seguimiento de los cambios que ocurren "detrás de escena".
En este artículo, veremos un puñado de consultas SQL que pueden ayudarlo a observar el funcionamiento de una base de datos MySQL.
La base de datos INFORMACION_ESQUEMA
Ya discutimos el INFORMATION_SCHEMA base de datos en este artículo. Si aún no lo ha leído, definitivamente le sugiero que lo haga antes de continuar.
Si necesita un repaso en el INFORMATION_SCHEMA base de datos, o si decide no leer el primer artículo, aquí hay algunos datos básicos que necesita saber:
- El
INFORMATION_SCHEMALa base de datos es parte del estándar ANSI. Trabajaremos con MySQL, pero otros RDBMS tienen sus variantes. Puede encontrar versiones para H2 Database, HSQLDB, MariaDB, Microsoft SQL Server y PostgreSQL. - Esta es la base de datos que realiza un seguimiento de todas las demás bases de datos en el servidor; encontraremos descripciones de todos los objetos aquí.
- Como cualquier otra base de datos, el
INFORMATION_SCHEMALa base de datos contiene varias tablas relacionadas e información sobre diferentes objetos. - Puede consultar esta base de datos usando SQL y usar los resultados para:
- Supervisar el estado y el rendimiento de la base de datos, y
- Genera código automáticamente en función de los resultados de la consulta.
Ahora pasemos a consultar la base de datos INFORMACION_ESQUEMA. Empezaremos mirando el modelo de datos que vamos a utilizar.
El modelo de datos
El modelo que usaremos en este artículo se muestra a continuación.
Este es un modelo simplificado que nos permite almacenar información sobre clases, instructores, estudiantes y otros detalles relacionados. Repasemos brevemente las tablas.
Guardaremos la lista de instructores en el lecturer mesa. Para cada profesor, registraremos un first_name y un last_name .
La class tabla enumera todas las clases que tenemos en nuestra escuela. Para cada registro en esta tabla, almacenaremos el class_name , el ID del profesor, una start_date planificada y end_date y cualquier class_details adicional . En aras de la simplicidad, supondré que solo tenemos un profesor por clase.
Las clases generalmente se organizan como una serie de conferencias. Generalmente requieren uno o más exámenes. Almacenaremos listas de clases y exámenes relacionados en la class y exam mesas. Ambos tendrán el ID de la clase relacionada y el start_time esperado y end_time .
Ahora necesitamos estudiantes para nuestras clases. Una lista de todos los estudiantes se almacena en el student mesa. Una vez más, almacenaremos solo el first_name y el last_name de cada alumno.
Lo último que debemos hacer es realizar un seguimiento de las actividades de los estudiantes. Guardaremos una lista de cada clase en la que se registró un estudiante, el registro de asistencia del estudiante y los resultados de sus exámenes. Cada una de las tres tablas restantes:on_class , on_lecture y on_exam – Tendrá una referencia al alumno y una referencia a la tabla correspondiente. Solo el on_exam la tabla tendrá un valor adicional:grado.
Sí, este modelo es muy sencillo. Podríamos añadir muchos otros detalles sobre estudiantes, profesores y clases. Podríamos almacenar valores históricos cuando los registros se actualizan o eliminan. Aún así, este modelo será suficiente para los propósitos de este artículo.
Crear una base de datos
Estamos listos para crear una base de datos en nuestro servidor local y examinar lo que sucede dentro de ella. Exportaremos el modelo (en Vertabelo) usando el “Generate SQL script " botón.
Luego crearemos una base de datos en la instancia del servidor MySQL. Llamé a mi base de datos “classes_and_students ”.
Lo siguiente que debemos hacer es ejecutar un script SQL generado previamente.
Ahora tenemos la base de datos con todos sus objetos (tablas, claves primarias y externas, claves alternativas).
Tamaño de la base de datos
Después de que se ejecuta el script, los datos sobre las "classes and students ” la base de datos se almacena en el INFORMATION_SCHEMA base de datos. Estos datos están en muchas tablas diferentes. No los enumeraré a todos nuevamente aquí; lo hicimos en el artículo anterior.
Veamos cómo podemos usar SQL estándar en esta base de datos. Comenzaré con una consulta muy importante:
SET @table_schema = "classes_and_students";
SELECT
ROUND(SUM( INFORMATION_SCHEMA.TABLES.DATA_LENGTH + INFORMATION_SCHEMA.TABLES.INDEX_LENGTH ) / 1024 / 1024, 2) AS "DB Size (in MB)",
ROUND(SUM( INFORMATION_SCHEMA.TABLES.DATA_FREE )/ 1024 / 1024, 2) AS "Free Space (in MB)"
FROM INFORMATION_SCHEMA.TABLES
WHERE INFORMATION_SCHEMA.TABLES.TABLE_SCHEMA = @table_schema;
Solo estamos consultando INFORMATION_SCHEMA.TABLES mesa aquí. Esta tabla debería darnos detalles más que suficientes sobre todas las tablas en el servidor. Tenga en cuenta que he filtrado solo las tablas de "classes_and_students " base de datos usando el SET variable en la primera línea y luego usando este valor en la consulta. La mayoría de las tablas contienen las columnas TABLE_NAME y TABLE_SCHEMA , que denotan la tabla y el esquema/base de datos al que pertenecen estos datos.
Esta consulta devolverá el tamaño actual de nuestra base de datos y el espacio libre reservado para nuestra base de datos. Aquí está el resultado real:

Como era de esperar, el tamaño de nuestra base de datos vacía es inferior a 1 MB y el espacio libre reservado es mucho mayor.
Tamaños y propiedades de las tablas
La próxima cosa interesante a hacer sería mirar los tamaños de las tablas en nuestra base de datos. Para ello, utilizaremos la siguiente consulta:
SET @table_schema = "classes_and_students";
SELECT
INFORMATION_SCHEMA.TABLES.TABLE_NAME,
ROUND(SUM( INFORMATION_SCHEMA.TABLES.DATA_LENGTH + INFORMATION_SCHEMA.TABLES.INDEX_LENGTH ) / 1024 / 1024, 2) "Table Size (in MB)",
ROUND(SUM( INFORMATION_SCHEMA.TABLES.DATA_FREE )/ 1024 / 1024, 2) AS "Free Space (in MB)",
MAX( INFORMATION_SCHEMA.TABLES.TABLE_ROWS) AS table_rows_number,
MAX( INFORMATION_SCHEMA.TABLES.AUTO_INCREMENT) AS auto_increment_value
FROM INFORMATION_SCHEMA.TABLES
WHERE INFORMATION_SCHEMA.TABLES.TABLE_SCHEMA = @table_schema
GROUP BY INFORMATION_SCHEMA.TABLES.TABLE_NAME
ORDER BY 2 DESC;
La consulta es casi idéntica a la anterior, con una excepción:el resultado se agrupa en el nivel de la tabla.
Aquí hay una imagen del resultado devuelto por esta consulta:
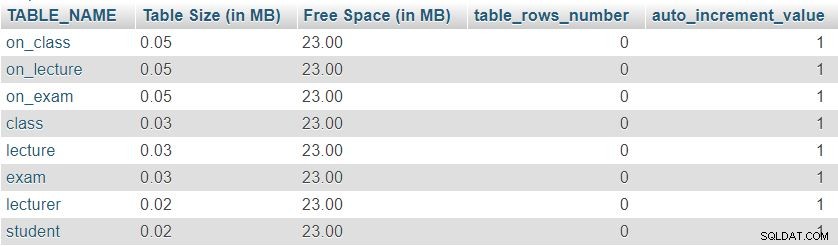
Primero, podemos notar que las ocho mesas tienen un “Tamaño de mesa” mínimo reservado para la definición de tablas, que incluye las columnas, la clave principal y el índice. El “Espacio Libre” se distribuye por igual entre todas las tablas.
También podemos ver el número de filas actualmente en cada tabla y el valor actual del auto_increment propiedad de cada tabla. Dado que todas las tablas están completamente vacías, no tenemos datos y auto_increment se establece en 1 (un valor que se asignará a la siguiente fila insertada).
Claves primarias
Cada tabla debe tener un valor de clave principal definido, por lo que es aconsejable verificar si esto es cierto para nuestra base de datos. Una forma de hacerlo es unir una lista de todas las tablas con una lista de restricciones. Esto debería darnos la información que necesitamos.
SET @table_schema = "classes_and_students";
SELECT
tab.TABLE_NAME,
COUNT(*) AS PRI_number
FROM INFORMATION_SCHEMA.TABLES tab
LEFT JOIN (
SELECT
INFORMATION_SCHEMA.COLUMNS.TABLE_SCHEMA,
INFORMATION_SCHEMA.COLUMNS.TABLE_NAME
FROM INFORMATION_SCHEMA.COLUMNS
WHERE INFORMATION_SCHEMA.COLUMNS.TABLE_SCHEMA = @table_schema
AND INFORMATION_SCHEMA.COLUMNS.COLUMN_KEY = 'PRI'
) col
ON tab.TABLE_SCHEMA = col.TABLE_SCHEMA
AND tab.TABLE_NAME = col.TABLE_NAME
WHERE tab.TABLE_SCHEMA = @table_schema
GROUP BY
tab.TABLE_NAME;
También hemos utilizado INFORMATION_SCHEMA.COLUMNS tabla en esta consulta. Mientras que la primera parte de la consulta simplemente devolverá todas las tablas en la base de datos, la segunda parte (después de LEFT JOIN ) contará el número de PRI en estas tablas. Usamos LEFT JOIN porque queremos ver si una tabla tiene 0 PRI en las COLUMNS mesa.
Como era de esperar, cada tabla en nuestra base de datos contiene exactamente una columna de clave principal (PRI).
¿"Islas"?
Las “islas” son mesas que están completamente separadas del resto del modelo. Suceden cuando una tabla no contiene claves foráneas y no se hace referencia a ninguna otra tabla. Esto realmente no debería ocurrir a menos que haya una muy buena razón, p. cuando las tablas contienen parámetros o almacenan resultados o informes dentro del modelo.
SET @table_schema = "classes_and_students";
SELECT
tab.TABLE_NAME,
(CASE WHEN f1.number_referenced IS NULL THEN 0 ELSE f1.number_referenced END) AS number_referenced,
(CASE WHEN f2.number_referencing IS NULL THEN 0 ELSE f2.number_referencing END) AS number_referencing
FROM INFORMATION_SCHEMA.TABLES tab
LEFT JOIN
-- # table was used as a reference
(
SELECT
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_SCHEMA,
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_NAME,
COUNT(*) AS number_referenced
FROM INFORMATION_SCHEMA.KEY_COLUMN_USAGE
WHERE INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_SCHEMA = @table_schema
GROUP BY
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_SCHEMA,
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_NAME
) f1
ON tab.TABLE_SCHEMA = f1.REFERENCED_TABLE_SCHEMA
AND tab.TABLE_NAME = f1.REFERENCED_TABLE_NAME
LEFT JOIN
-- # of references in the table
(
SELECT
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.TABLE_SCHEMA,
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.TABLE_NAME,
COUNT(*) AS number_referencing
FROM INFORMATION_SCHEMA.KEY_COLUMN_USAGE
WHERE INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_SCHEMA = @table_schema
AND INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_NAME IS NOT NULL
GROUP BY
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.TABLE_SCHEMA,
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.TABLE_NAME
) f2
ON tab.TABLE_SCHEMA = f2.TABLE_SCHEMA
AND tab.TABLE_NAME = f2.TABLE_NAME
WHERE tab.TABLE_SCHEMA = @table_schema;
¿Cuál es la idea detrás de esta consulta? Bueno, estamos usando el INFORMATION_SCHEMA.KEY_COLUMN_USAGE table para comprobar si alguna columna de la tabla es una referencia a otra tabla o si alguna columna se utiliza como referencia en otra tabla. La primera parte de la consulta selecciona todas las tablas. Después del primer LEFT JOIN, contamos el número de veces que se usó cualquier columna de esta tabla como referencia. Después del segundo LEFT JOIN, contamos el número de veces que cualquier columna de esta tabla hace referencia a cualquier otra tabla.
El resultado devuelto es:
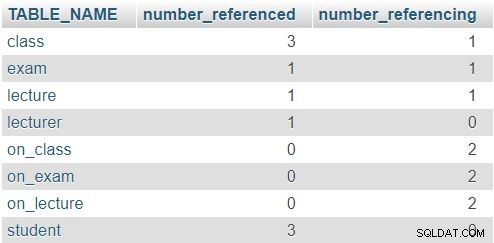
En la fila de la class tabla, los números 3 y 1 indican que esta tabla fue referenciada tres veces (en la lecture , exam y on_class tablas) y que contiene un atributo que hace referencia a otra tabla (lecturer_id ). Las otras tablas siguen un patrón similar, aunque los números reales, por supuesto, serán diferentes. La regla aquí es que ninguna fila debe tener un 0 en ambas columnas.
Agregar filas
Hasta ahora, todo ha ido como se esperaba. Hemos importado con éxito nuestro modelo de datos de Vertabelo al servidor MySQL local. Todas las tablas contienen claves, tal como queremos, y todas las tablas están relacionadas entre sí:no hay "islas" en nuestro modelo.
Ahora, insertaremos algunas filas en nuestras tablas y usaremos las consultas demostradas anteriormente para rastrear los cambios en nuestra base de datos.
Después de agregar 1000 filas en la tabla del profesor, volveremos a ejecutar la consulta desde "Table Sizes and Properties " sección. Devolverá el siguiente resultado:
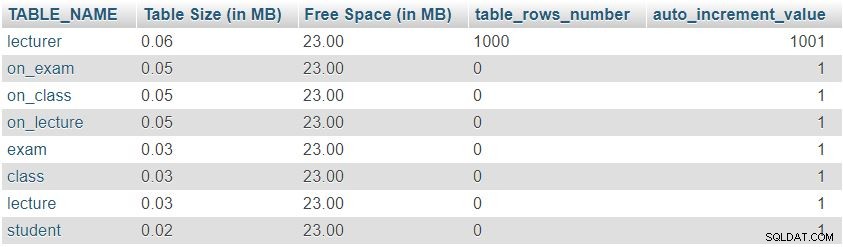
Podemos notar fácilmente que la cantidad de filas y los valores de incremento automático han cambiado como se esperaba, pero no hubo cambios significativos en el tamaño de la tabla.
Este fue solo un ejemplo de prueba; en situaciones de la vida real, notaríamos cambios significativos. El número de filas cambiará drásticamente en tablas rellenadas por usuarios o procesos automatizados (es decir, tablas que no son diccionarios). Verificar el tamaño y los valores en tales tablas es una muy buena manera de encontrar y corregir rápidamente comportamientos no deseados.
¿Te importa compartir?
Trabajar con bases de datos es una búsqueda constante para lograr un rendimiento óptimo. Para tener más éxito en esa búsqueda, debe utilizar cualquier herramienta disponible. Hoy hemos visto algunas consultas que son útiles en nuestra lucha por un mejor rendimiento. ¿Has encontrado algo más útil? ¿Has jugado con el INFORMATION_SCHEMA base de datos antes? Comparte tu experiencia en los comentarios a continuación.