Python es muy popular en estos días. Dado que Python es un lenguaje de programación de propósito general, también se puede utilizar para realizar el proceso de extracción, transformación y carga (ETL). Hay diferentes módulos ETL disponibles, pero hoy nos quedaremos con la combinación de Python y MySQL. Usaremos Python para invocar procedimientos almacenados y preparar y ejecutar sentencias SQL.
Usaremos dos enfoques similares pero diferentes. Primero, invocaremos los procedimientos almacenados que harán todo el trabajo, y luego analizaremos cómo podríamos hacer el mismo proceso sin procedimientos almacenados usando código MySQL en Python.
¿Listo? Antes de profundizar, veamos el modelo de datos, o modelos de datos, ya que hay dos de ellos en este artículo.
Los modelos de datos
Necesitaremos dos modelos de datos, uno para almacenar nuestros datos operativos y el otro para almacenar nuestros datos de informes.
El primer modelo se muestra en la imagen de arriba. Este modelo se utiliza para almacenar datos operativos (en vivo) para un negocio basado en suscripción. Para obtener más información sobre este modelo, consulte nuestro artículo anterior, Creación de un DWH, primera parte:un modelo de datos comerciales de suscripción.
Separar los datos operativos y de informes suele ser una decisión muy acertada. Para lograr esa separación, necesitaremos crear un almacén de datos (DWH). Ya hicimos eso; Puedes ver el modelo en la imagen de arriba. Este modelo también se describe en detalle en la publicación Creación de un DWH, segunda parte:un modelo de datos comerciales de suscripción.
Finalmente, necesitamos extraer datos de la base de datos en vivo, transformarlos y cargarlos en nuestro DWH. Ya hemos hecho esto usando procedimientos almacenados de SQL. Puede encontrar una descripción de lo que queremos lograr junto con algunos ejemplos de código en Creación de un almacén de datos, parte 3:un modelo de datos comerciales de suscripción.
Si necesita información adicional sobre DWH, le recomendamos leer estos artículos:
- El esquema estelar
- El esquema del copo de nieve
- Esquema de estrella frente a esquema de copo de nieve.
Nuestra tarea de hoy es reemplazar los procedimientos almacenados de SQL con código de Python. Estamos listos para hacer algo de magia con Python. Comencemos usando solo procedimientos almacenados en Python.
Método 1:ETL utilizando procedimientos almacenados
Antes de comenzar a describir el proceso, es importante mencionar que tenemos dos bases de datos en nuestro servidor.
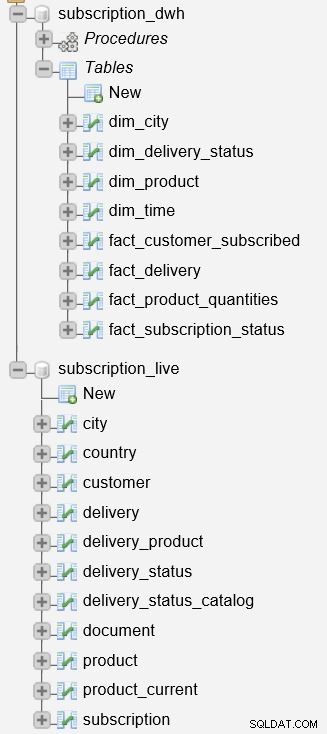
El subscription_live La base de datos se utiliza para almacenar datos transaccionales/en vivo, mientras que subscription_dwh es nuestra base de datos de informes (DWH).
Ya hemos descrito los procedimientos almacenados que se utilizan para actualizar tablas de hechos y dimensiones. Leerán los datos de subscription_live base de datos, combínelo con datos en el subscription_dwh base de datos e inserte nuevos datos en el subscription_dwh base de datos. Estos dos procedimientos son:
p_update_dimensions– Actualiza las tablas de dimensionesdim_timeydim_city.p_update_facts– Actualiza dos tablas de hechos,fact_customer_subscribedyfact_subscription_status.
Si desea ver el código completo de estos procedimientos, lea Creación de un almacén de datos, parte 3:un modelo de datos comerciales de suscripción.
Ahora estamos listos para escribir un script Python simple que se conectará al servidor y realizará el proceso ETL. Primero echemos un vistazo a todo el script (etl_procedures.py ). Luego explicaremos las partes más importantes.
# import MySQL connector import mysql.connector # connect to server connection = mysql.connector.connect(user='', password=' ', host='127.0.0.1') print('Connected to database.') cursor = connection.cursor() # I update dimensions cursor.callproc('subscription_dwh.p_update_dimensions') print('Dimension tables updated.') # II update facts cursor.callproc('subscription_dwh.p_update_facts') print('Fact tables updated.') # commit & close connection cursor.close() connection.commit() connection.close() print('Disconnected from database.')
etl_procedures.py
Importación de módulos y conexión a la base de datos
Python usa módulos para almacenar definiciones y declaraciones. Puede usar un módulo existente o escribir uno propio. El uso de módulos existentes simplificará su vida porque está utilizando un código preescrito, pero escribir su propio módulo también es muy útil. Cuando salga del intérprete de Python y lo vuelva a ejecutar, perderá las funciones y variables que haya definido previamente. Por supuesto, no desea escribir el mismo código una y otra vez. Para evitar eso, puede almacenar sus definiciones en un módulo e importarlo a Python.
Volver a etl_procedures.py . En nuestro programa, comenzamos con la importación de MySQL Connector:
# import MySQL connector import mysql.connector
El Conector MySQL para Python se usa como un controlador estandarizado que se conecta a un servidor/base de datos MySQL. Deberá descargarlo e instalarlo si no lo ha hecho anteriormente. Además de conectarse a la base de datos, ofrece una serie de métodos y propiedades para trabajar con una base de datos. Usaremos algunos de ellos, pero puedes consultar la documentación completa aquí.
A continuación, necesitaremos conectarnos a nuestra base de datos:
# connect to server connection = mysql.connector.connect(user='', password=' ', host='127.0.0.1') print('Connected to database.') cursor = connection.cursor()
La primera línea se conectará a un servidor (en este caso, me estoy conectando a mi máquina local) usando sus credenciales (reemplace
connection = mysql.connector.connect(user='', password=' ', host='127.0.0.1', database=' ')
Me conecté intencionalmente solo a un servidor y no a una base de datos específica porque usaré dos bases de datos ubicadas en el mismo servidor.
El siguiente comando:print – es aquí solo una notificación de que nos conectamos con éxito. Si bien no tiene importancia para la programación, podría usarse para depurar el código si algo salió mal en el script.
La última línea de esta parte es:
cursor =conexión.cursor()
Cursors are the handler structure used to work with the data. We’ll use them for retrieving data from the database (SELECT), but also to modify the data (INSERT, UPDATE, DELETE). Before using a cursor, we need to create it. And that is what this line does.
Procedimientos de llamada
La parte anterior era general y podría usarse para otras tareas relacionadas con la base de datos. La siguiente parte del código es específicamente para ETL:llamar a nuestros procedimientos almacenados con cursor.callproc dominio. Se ve así:
# 1. update dimensions
cursor.callproc('subscription_dwh.p_update_dimensions')
print('Dimension tables updated.')
# 2. update facts
cursor.callproc('subscription_dwh.p_update_facts')
print('Fact tables updated.')
Los procedimientos de llamada se explican por sí mismos. Después de cada llamada, se agregó un comando de impresión. Nuevamente, esto solo nos da una notificación de que todo salió bien.
Confirmar y cerrar
La parte final del script confirma los cambios de la base de datos y cierra todos los objetos usados:
# commit & close connection
cursor.close()
connection.commit()
connection.close()
print('Disconnected from database.')
Los procedimientos de llamada se explican por sí mismos. Después de cada llamada, se agregó un comando de impresión. Nuevamente, esto solo nos da una notificación de que todo salió bien.
El compromiso es esencial aquí; sin él, no habrá cambios en la base de datos, incluso si llamó a un procedimiento o ejecutó una instrucción SQL.
Ejecutar la secuencia de comandos
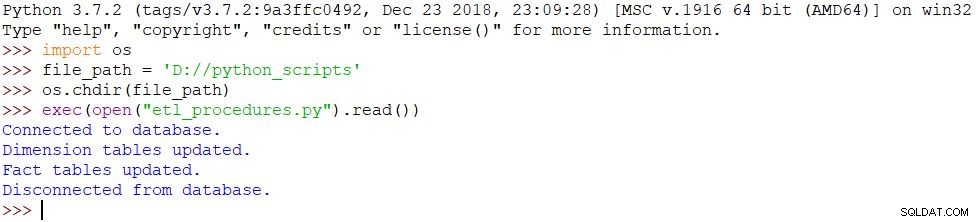
Lo último que tenemos que hacer es ejecutar nuestro script. Usaremos los siguientes comandos en Python Shell para lograrlo:
import osfile_path ='D://python_scripts'os.chdir(file_path)exec(open("etl_procedures.py").read())El script se ejecuta y todos los cambios se realizan en la base de datos en consecuencia. El resultado se puede ver en la imagen de abajo.
Método 2:ETL usando Python y MySQL
El enfoque presentado anteriormente no difiere mucho del enfoque de llamar a procedimientos almacenados directamente en MySQL. La única diferencia es que ahora tenemos un script que hará todo el trabajo por nosotros.
Podríamos usar otro enfoque:poner todo dentro del script de Python. Incluiremos declaraciones de Python, pero también prepararemos consultas SQL y las ejecutaremos en la base de datos. La base de datos de origen (en vivo) y la base de datos de destino (DWH) son las mismas que en el ejemplo con procedimientos almacenados.
Antes de profundizar en esto, echemos un vistazo al script completo (etl_queries.py ):
from datetime import date # import MySQL connector import mysql.connector # connect to server connection = mysql.connector.connect(user='', password=' ', host='127.0.0.1') print('Connected to database.') # 1. update dimensions # 1.1 update dim_time # date - yesterday yesterday = date.fromordinal(date.today().toordinal()-1) yesterday_str = '"' + str(yesterday) + '"' # test if date is already in the table cursor = connection.cursor() query = ( "SELECT COUNT(*) " "FROM subscription_dwh.dim_time " "WHERE time_date = " + yesterday_str) cursor.execute(query) result = cursor.fetchall() yesterday_subscription_count = int(result[0][0]) if yesterday_subscription_count == 0: yesterday_year = 'YEAR("' + str(yesterday) + '")' yesterday_month = 'MONTH("' + str(yesterday) + '")' yesterday_week = 'WEEK("' + str(yesterday) + '")' yesterday_weekday = 'WEEKDAY("' + str(yesterday) + '")' query = ( "INSERT INTO subscription_dwh.`dim_time`(`time_date`, `time_year`, `time_month`, `time_week`, `time_weekday`, `ts`) " " VALUES (" + yesterday_str + ", " + yesterday_year + ", " + yesterday_month + ", " + yesterday_week + ", " + yesterday_weekday + ", Now())") cursor.execute(query) # 1.2 update dim_city query = ( "INSERT INTO subscription_dwh.`dim_city`(`city_name`, `postal_code`, `country_name`, `ts`) " "SELECT city_live.city_name, city_live.postal_code, country_live.country_name, Now() " "FROM subscription_live.city city_live " "INNER JOIN subscription_live.country country_live ON city_live.country_id = country_live.id " "LEFT JOIN subscription_dwh.dim_city city_dwh ON city_live.city_name = city_dwh.city_name AND city_live.postal_code = city_dwh.postal_code AND country_live.country_name = city_dwh.country_name " "WHERE city_dwh.id IS NULL") cursor.execute(query) print('Dimension tables updated.') # 2. update facts # 2.1 update customers subscribed # delete old data for the same date query = ( "DELETE subscription_dwh.`fact_customer_subscribed`.* " "FROM subscription_dwh.`fact_customer_subscribed` " "INNER JOIN subscription_dwh.`dim_time` ON subscription_dwh.`fact_customer_subscribed`.`dim_time_id` = subscription_dwh.`dim_time`.`id` " "WHERE subscription_dwh.`dim_time`.`time_date` = " + yesterday_str) cursor.execute(query) # insert new data query = ( "INSERT INTO subscription_dwh.`fact_customer_subscribed`(`dim_city_id`, `dim_time_id`, `total_active`, `total_inactive`, `daily_new`, `daily_canceled`, `ts`) " " SELECT city_dwh.id AS dim_ctiy_id, time_dwh.id AS dim_time_id, SUM(CASE WHEN customer_live.active = 1 THEN 1 ELSE 0 END) AS total_active, SUM(CASE WHEN customer_live.active = 0 THEN 1 ELSE 0 END) AS total_inactive, SUM(CASE WHEN customer_live.active = 1 AND DATE(customer_live.time_updated) = @time_date THEN 1 ELSE 0 END) AS daily_new, SUM(CASE WHEN customer_live.active = 0 AND DATE(customer_live.time_updated) = @time_date THEN 1 ELSE 0 END) AS daily_canceled, MIN(NOW()) AS ts " "FROM subscription_live.`customer` customer_live " "INNER JOIN subscription_live.`city` city_live ON customer_live.city_id = city_live.id " "INNER JOIN subscription_live.`country` country_live ON city_live.country_id = country_live.id " "INNER JOIN subscription_dwh.dim_city city_dwh ON city_live.city_name = city_dwh.city_name AND city_live.postal_code = city_dwh.postal_code AND country_live.country_name = city_dwh.country_name " "INNER JOIN subscription_dwh.dim_time time_dwh ON time_dwh.time_date = " + yesterday_str + " " "GROUP BY city_dwh.id, time_dwh.id") cursor.execute(query) # 2.2 update subscription statuses # delete old data for the same date query = ( "DELETE subscription_dwh.`fact_subscription_status`.* " "FROM subscription_dwh.`fact_subscription_status` " "INNER JOIN subscription_dwh.`dim_time` ON subscription_dwh.`fact_subscription_status`.`dim_time_id` = subscription_dwh.`dim_time`.`id` " "WHERE subscription_dwh.`dim_time`.`time_date` = " + yesterday_str) cursor.execute(query) # insert new data query = ( "INSERT INTO subscription_dwh.`fact_subscription_status`(`dim_city_id`, `dim_time_id`, `total_active`, `total_inactive`, `daily_new`, `daily_canceled`, `ts`) " "SELECT city_dwh.id AS dim_ctiy_id, time_dwh.id AS dim_time_id, SUM(CASE WHEN subscription_live.active = 1 THEN 1 ELSE 0 END) AS total_active, SUM(CASE WHEN subscription_live.active = 0 THEN 1 ELSE 0 END) AS total_inactive, SUM(CASE WHEN subscription_live.active = 1 AND DATE(subscription_live.time_updated) = @time_date THEN 1 ELSE 0 END) AS daily_new, SUM(CASE WHEN subscription_live.active = 0 AND DATE(subscription_live.time_updated) = @time_date THEN 1 ELSE 0 END) AS daily_canceled, MIN(NOW()) AS ts " "FROM subscription_live.`customer` customer_live " "INNER JOIN subscription_live.`subscription` subscription_live ON subscription_live.customer_id = customer_live.id " "INNER JOIN subscription_live.`city` city_live ON customer_live.city_id = city_live.id " "INNER JOIN subscription_live.`country` country_live ON city_live.country_id = country_live.id " "INNER JOIN subscription_dwh.dim_city city_dwh ON city_live.city_name = city_dwh.city_name AND city_live.postal_code = city_dwh.postal_code AND country_live.country_name = city_dwh.country_name " "INNER JOIN subscription_dwh.dim_time time_dwh ON time_dwh.time_date = " + yesterday_str + " " "GROUP BY city_dwh.id, time_dwh.id") cursor.execute(query) print('Fact tables updated.') # commit & close connection cursor.close() connection.commit() connection.close() print('Disconnected from database.')
etl_queries.py
Importación de módulos y conexión a la base de datos
Una vez más, necesitaremos importar MySQL usando el siguiente código:
import mysql.connector
También importaremos el módulo de fecha y hora, como se muestra a continuación. Necesitamos esto para operaciones relacionadas con fechas en Python:
from datetime import date
El proceso de conexión a la base de datos es el mismo que en el ejemplo anterior.
Actualización de la dimensión dim_time
Para actualizar el dim_time table, tendremos que verificar si el valor (para ayer) ya está en la tabla. Tendremos que usar las funciones de fecha de Python (en lugar de las de SQL) para hacer esto:
# date - yesterday yesterday = date.fromordinal(date.today().toordinal()-1) yesterday_str = '"' + str(yesterday) + '"'
La primera línea de código devolverá la fecha de ayer en la variable de fecha, mientras que la segunda línea almacenará este valor como una cadena. Necesitaremos esto como una cadena porque la concatenaremos con otra cadena cuando construyamos la consulta SQL.
A continuación, tendremos que probar si esta fecha ya está en el dim_time mesa. Después de declarar un cursor, prepararemos la consulta SQL. Para ejecutar la consulta, usaremos el cursor.execute comando:
# test if date is already in the table cursor = connection.cursor() query = ( "SELECT COUNT(*) " "FROM subscription_dwh.dim_time " "WHERE time_date = " + yesterday_str) cursor.execute(query) '"'
Almacenaremos el resultado de la consulta en el resultado variable. El resultado tendrá 0 o 1 filas, por lo que podemos probar la primera columna de la primera fila. Contendrá un 0 o un 1. (Recuerde, podemos tener la misma fecha solo una vez en una tabla de dimensiones).
Si la fecha aún no está en la tabla, prepararemos las cadenas que formarán parte de la consulta SQL:
result = cursor.fetchall()
yesterday_subscription_count = int(result[0][0])
if yesterday_subscription_count == 0:
yesterday_year = 'YEAR("' + str(yesterday) + '")'
yesterday_month = 'MONTH("' + str(yesterday) + '")'
yesterday_week = 'WEEK("' + str(yesterday) + '")'
yesterday_weekday = 'WEEKDAY("' + str(yesterday) + '")'
Finalmente, crearemos una consulta y la ejecutaremos. Esto actualizará el dim_time tabla después de que se confirme. Tenga en cuenta que he usado la ruta completa a la tabla, incluido el nombre de la base de datos (subscription_dwh ).
query = (
"INSERT INTO subscription_dwh.`dim_time`(`time_date`, `time_year`, `time_month`, `time_week`, `time_weekday`, `ts`) "
" VALUES (" + yesterday_str + ", " + yesterday_year + ", " + yesterday_month + ", " + yesterday_week + ", " + yesterday_weekday + ", Now())")
cursor.execute(query)
Actualizar la dimensión dim_city
Actualizando el dim_city table es aún más simple porque no necesitamos probar nada antes de la inserción. De hecho, incluiremos esa prueba en la consulta SQL.
# 1.2 update dim_city query = ( "INSERT INTO subscription_dwh.`dim_city`(`city_name`, `postal_code`, `country_name`, `ts`) " "SELECT city_live.city_name, city_live.postal_code, country_live.country_name, Now() " "FROM subscription_live.city city_live " "INNER JOIN subscription_live.country country_live ON city_live.country_id = country_live.id " "LEFT JOIN subscription_dwh.dim_city city_dwh ON city_live.city_name = city_dwh.city_name AND city_live.postal_code = city_dwh.postal_code AND country_live.country_name = city_dwh.country_name " "WHERE city_dwh.id IS NULL") cursor.execute(query)
Aquí preparamos y ejecutamos la consulta SQL. Observe que nuevamente usé las rutas completas a las tablas, incluidos los nombres de ambas bases de datos (subscription_live y subscription_dwh ).
Actualización de las tablas de hechos
Lo último que debemos hacer es actualizar nuestras tablas de hechos. El proceso es casi el mismo que actualizar tablas de dimensiones:preparamos consultas y las ejecutamos. Estas consultas son mucho más complejas, pero son las mismas que se utilizan en los procedimientos almacenados.
Agregamos una mejora en comparación con los procedimientos almacenados:eliminar los datos existentes para la misma fecha en la tabla de hechos. Esto nos permitirá ejecutar un script varias veces para la misma fecha. Al final, necesitaremos confirmar la transacción y cerrar todos los objetos y la conexión.
Ejecución del guión
Tenemos un cambio menor en esta parte, que llama a un script diferente:
- import os
- file_path = 'D://python_scripts'
- os.chdir(file_path)
- exec(open("etl_queries.py").read())
Debido a que usamos los mismos mensajes y el script se completó correctamente, el resultado es el mismo:
¿Cómo usarías Python en ETL?
Hoy vimos un ejemplo de cómo realizar el proceso ETL con un script de Python. Hay otras formas de hacer esto, p. una serie de soluciones de código abierto que utilizan bibliotecas de Python para trabajar con bases de datos y realizar el proceso ETL. En el próximo artículo, jugaremos con uno de ellos. Mientras tanto, no dude en compartir su experiencia con Python y ETL.