SQLAlchemy te ayuda a trabajar con bases de datos en Python. En este post te contamos todo lo que necesitas saber para empezar con este módulo.
En el artículo anterior, hablamos sobre cómo usar Python en el proceso ETL. Nos enfocamos en hacer el trabajo mediante la ejecución de procedimientos almacenados y consultas SQL. En este artículo y el siguiente, utilizaremos un enfoque diferente. En lugar de escribir código SQL, usaremos el kit de herramientas SQLAlchemy. También puede usar este artículo por separado, como una introducción rápida sobre la instalación y el uso de SQLAlchemy.
¿Listo? Comencemos.
¿Qué es SQLAlchemy?
Python es bien conocido por su cantidad y variedad de módulos. Estos módulos reducen significativamente nuestro tiempo de codificación porque implementan las rutinas necesarias para lograr una tarea específica. Hay disponibles varios módulos que funcionan con datos, incluido SQLAlchemy.
Para describir SQLAlchemy, usaré una cita de SQLAlchemy.org:
SQLAlchemy es el kit de herramientas SQL de Python y el mapeador relacional de objetos que brinda a los desarrolladores de aplicaciones todo el poder y la flexibilidad de SQL.
Proporciona un conjunto completo de persistencia de nivel empresarial bien conocido patrones, diseñados para un acceso a bases de datos eficiente y de alto rendimiento, adaptados a un lenguaje de dominio simple y Pythonic.
La parte más importante aquí es la parte sobre el ORM (mapeador relacional de objetos), que nos ayuda a tratar los objetos de la base de datos como objetos de Python en lugar de listas.
Antes de continuar con SQLAlchemy, hagamos una pausa y hablemos de los ORM.
Pros y contras de usar ORM
En comparación con SQL sin formato, los ORM tienen sus pros y sus contras, y la mayoría de estos también se aplican a SQLAlchemy.
Lo bueno:
- Portabilidad de código. El ORM se ocupa de las diferencias sintácticas entre las bases de datos.
- Solo un idioma es necesario para manejar su base de datos. Aunque, para ser honesto, esta no debería ser la principal motivación para usar un ORM.
- Los ORM simplifican su código , p.ej. cuidan las relaciones y las tratan como objetos, lo cual es genial si estás acostumbrado a la programación orientada a objetos.
- Puede manipular sus datos dentro del programa .
Desafortunadamente, todo tiene un precio. Lo no tan bueno de los ORM:
- En algunos casos, un ORM podría ser lento .
- Escribir consultas complejas podría volverse aún más complicado o podría resultar en consultas lentas. Pero este no es el caso cuando se usa SQLAlchemy.
- Si conoce bien su DBMS, entonces es una pérdida de tiempo aprender a escribir las mismas cosas en un ORM.
Ahora que hemos manejado ese tema, volvamos a SQLAlchemy.
Antes de empezar...
… recordemos el objetivo de este artículo. Si solo está interesado en instalar SQLAlchemy y necesita un tutorial rápido sobre cómo ejecutar comandos simples, este artículo lo hará. Sin embargo, los comandos presentados en este artículo se usarán en el próximo artículo para realizar el proceso ETL y reemplazar el código SQL (procedimientos almacenados) y Python que presentamos en artículos anteriores.
Bien, ahora comencemos desde el principio:con la instalación de SQLAlchemy.
Instalando SQLAlchemy
1. Compruebe si el módulo ya está instalado
Para usar un módulo de Python, debe instalarlo (es decir, si no se instaló previamente). Una forma de verificar qué módulos se han instalado es usar este comando en Python Shell:
help('modules')
Para verificar si un módulo específico está instalado, simplemente intente importarlo. Usa estos comandos:
import sqlalchemy sqlalchemy.__version__
Si SQLAlchemy ya está instalado, la primera línea se ejecutará correctamente. import es un comando estándar de Python utilizado para importar módulos. Si el módulo no está instalado, Python arrojará un error, en realidad una lista de errores, en texto rojo, que no se puede perder :)
El segundo comando devuelve la versión actual de SQLAlchemy. El resultado devuelto se muestra a continuación:

También necesitaremos otro módulo, y ese es PyMySQL . Esta es una biblioteca de cliente MySQL ligera de Python puro. Este módulo es compatible con todo lo que necesitamos para trabajar con una base de datos MySQL, desde ejecutar consultas simples hasta acciones de base de datos más complejas. Podemos verificar si existe usando help('modules') , como se describió anteriormente, o usando las siguientes dos declaraciones:
import pymysql pymysql.__version__
Por supuesto, estos son los mismos comandos que usamos para probar si se instaló SQLAlchemy.
¿Qué sucede si SQLAlchemy o PyMySQL aún no están instalados?
Importar módulos previamente instalados no es difícil. Pero, ¿y si los módulos que necesita aún no están instalados?
Algunos módulos tienen un paquete de instalación, pero en su mayoría usará el comando pip para instalarlos. PIP es una herramienta de Python utilizada para instalar y desinstalar módulos. La forma más fácil de instalar un módulo (en el sistema operativo Windows) es:
- Usar Símbolo del sistema -> Ejecutar -> cmd .
- Posicionar en el directorio de Python cd C:\...\Python\Python37\Scripts .
- Ejecute el comando pip
install(en nuestro caso, ejecutaremospip install pyMySQLypip install sqlAlchemy.
PIP también se puede utilizar para desinstalar el módulo existente. Para hacer eso, debe usar pip uninstall .
2. Conexión a la base de datos
Si bien instalar todo lo necesario para usar SQLAlchemy es esencial, no es muy interesante. Tampoco es realmente parte de lo que nos interesa. Ni siquiera nos hemos conectado a las bases de datos que queremos usar. Resolveremos eso ahora:
import sqlalchemy
from sqlalchemy.engine import create_engine
engine_live = sqlalchemy.create_engine('mysql+pymysql://:@localhost:3306/subscription_live')
connection_live = engine_live.connect()
print(engine_live.table_names())
Usando el script anterior, estableceremos una conexión a la base de datos ubicada en nuestro servidor local, el subscription_live base de datos.
(Nota: Reemplace
Repasemos el guión, comando por comando.
import sqlalchemy from sqlalchemy.engine import create_engine
Estas dos líneas importan nuestro módulo y el create_engine función.
A continuación, estableceremos una conexión con la base de datos ubicada en nuestro servidor.
engine_live = sqlalchemy.create_engine('mysql+pymysql:// :@localhost:3306/subscription_live')
connection_live = engine_live.connect()
La función create_engine crea el motor y usa .connect() , se conecta a la base de datos. El create_engine función utiliza estos parámetros:
dialect+driver://username:password@host:port/database
En nuestro caso, el dialecto es mysql , el controlador es pymysql (previamente instalado) y las variables restantes son específicas para el servidor y la(s) base(s) de datos a las que queremos conectarnos.
(Nota: Si te estás conectando localmente, usa localhost en lugar de su dirección IP "local", 127.0.0.1 y el puerto apropiado :3306 .)

El resultado del comando print(engine_live.table_names()) se muestra en la imagen de arriba. Como era de esperar, obtuvimos la lista de todas las tablas de nuestra base de datos operativa/en vivo.
3. Ejecutar comandos SQL usando SQLAlchemy
En esta sección, analizaremos los comandos SQL más importantes, examinaremos la estructura de la tabla y ejecutaremos los cuatro comandos DML:SELECCIONAR, INSERTAR, ACTUALIZAR y ELIMINAR.
Discutiremos las declaraciones utilizadas en este script por separado. Tenga en cuenta que ya hemos pasado por la parte de conexión de este script y ya hemos enumerado los nombres de las tablas. Hay cambios menores en esta línea:
from sqlalchemy import create_engine, select, MetaData, Table, asc
Acabamos de importar todo lo que usaremos de SQLAlchemy.
Tablas y Estructura
Ejecutaremos el script escribiendo el siguiente comando en Python Shell:
import os
file_path = 'D://python_scripts'
os.chdir(file_path)
exec(open("queries.py").read())
El resultado es el script ejecutado. Ahora analicemos el resto del guión.
SQLAlchemy importa información relacionada con tablas, estructura y relaciones. Para trabajar con esa información, podría ser útil revisar la lista de tablas (y sus columnas) en la base de datos:
#print connected tables
print("\n -- Tables from _live database -- ")
print (engine_live.table_names())

Esto simplemente devuelve una lista de todas las tablas de la base de datos conectada.
Nota: Los table_names() El método devuelve una lista de nombres de tablas para el motor dado. Puede imprimir la lista completa o iterar a través de ella usando un bucle (como podría hacer con cualquier otra lista).
A continuación, devolveremos una lista de todos los atributos de la tabla seleccionada. La parte relevante del script y el resultado se muestran a continuación:
#SELECT
metadata = MetaData(bind=None)
table_city = Table('city', metadata, autoload = True, autoload_with = engine_live)
# print table columns
print("\n -- Tables columns for table 'city' --")
for column in table_city.c:
print(column.name)
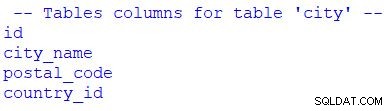
Puedes ver que he usado for para recorrer el conjunto de resultados. Podríamos reemplazar table_city.c con table_city.columns .
Nota: El proceso de cargar la descripción de la base de datos y crear metadatos en SQLAlchemy se llama reflexión.
Nota: MetaData es el objeto que guarda información sobre los objetos en la base de datos, por lo que las tablas de la base de datos también están vinculadas a este objeto. En general, este objeto almacena información sobre el aspecto del esquema de la base de datos. Lo usará como un único punto de contacto cuando desee realizar cambios u obtener información sobre el esquema de base de datos.
Nota: Los atributos autoload = True y autoload_with = engine_live debe usarse para garantizar que los atributos de la tabla se carguen (si aún no lo han hecho).
SELECCIONAR
No creo que necesite explicar cuán importante es la declaración SELECT :) Entonces, digamos que puede usar SQLAlchemy para escribir declaraciones SELECT. Si está acostumbrado a la sintaxis de MySQL, le llevará algún tiempo adaptarse; Aún así, todo es bastante lógico. Para decirlo de la manera más simple posible, diría que la declaración SELECT se divide y se omiten algunas partes, pero todo sigue en el mismo orden.
Probemos algunas declaraciones SELECT ahora.
# simple select
print("\n -- SIMPLE SELECT -- ")
stmt = select([table_city])
print(stmt)
print(connection_live.execute(stmt).fetchall())
# loop through results
results = connection_live.execute(stmt).fetchall()
for result in results:
print(result)
El primero es una instrucción SELECT simple devolviendo todos los valores de la tabla dada. La sintaxis de esta declaración es muy simple:he colocado el nombre de la tabla en select() . Tenga en cuenta que he:
- Preparé la declaración -
stmt = select([table_city]. - Imprimió la declaración usando
print(stmt), lo que nos da una buena idea sobre la instrucción que acaba de ejecutarse. Esto también podría usarse para la depuración. - Imprimí el resultado con
print(connection_live.execute(stmt).fetchall()). - Revisó el resultado e imprimió cada registro individual.
Nota: Debido a que también cargamos restricciones de clave primaria y externa en SQLAlchemy, la declaración SELECT toma una lista de objetos de tabla como argumentos y establece relaciones automáticamente cuando es necesario.
El resultado se muestra en la siguiente imagen:

Python obtendrá todos los atributos de la tabla y los almacenará en el objeto. Como se muestra, podemos usar este objeto para realizar operaciones adicionales. El resultado final de nuestra declaración es una lista de todas las ciudades de la city mesa.
Ahora, estamos listos para una consulta más compleja. Acabo de agregar una cláusula ORDER BY .
# simple select
# simple select, using order by
print("\n -- SIMPLE SELECT, USING ORDER BY")
stmt = select([table_city]).order_by(asc(table_city.columns.id))
print(stmt)
print(connection_live.execute(stmt).fetchall())

Nota: El asc() El método realiza una ordenación ascendente contra el objeto principal, utilizando columnas definidas como parámetros.
La lista devuelta es la misma, pero ahora está ordenada por el valor de identificación, en orden ascendente. Es importante tener en cuenta que simplemente agregamos .order_by( a la consulta SELECT anterior. El .order_by(...) El método nos permite cambiar el orden del conjunto de resultados devuelto, de la misma manera que lo haríamos en una consulta SQL. Por lo tanto, los parámetros deben seguir la lógica SQL, usando nombres de columnas u orden de columnas y ASC o DESC.
A continuación, agregaremos DONDE a nuestra sentencia SELECT.
# select with WHERE
print("\n -- SELECT WITH WHERE --")
stmt = select([table_city]).where(table_city.columns.city_name == 'London')
print(stmt)
print(connection_live.execute(stmt).fetchall())

Nota: El .where() El método se usa para probar una condición que hemos usado como argumento. También podríamos usar el .filter() método, que es mejor para filtrar condiciones más complejas.
Una vez más, el .where part simplemente se concatena a nuestra instrucción SELECT. Observe que hemos puesto la condición dentro de los corchetes. Cualquier condición que esté entre paréntesis se prueba de la misma manera que se probaría en la parte WHERE de una instrucción SELECT. La condición de igualdad se prueba usando ==en lugar de =.
Lo último que intentaremos con SELECT es unir dos tablas. Echemos un vistazo al código y su resultado primero.
# select with JOIN
print("\n -- SELECT WITH JOIN --")
table_country = Table('country', metadata, autoload = True, autoload_with = engine_live)
stmt = select([table_city.columns.city_name, table_country.columns.country_name]).select_from(table_city.join(table_country))
print(stmt)
print(connection_live.execute(stmt).fetchall())

Hay dos partes importantes en la declaración anterior:
select([table_city.columns.city_name, table_country.columns.country_name])define qué columnas se devolverán en nuestro resultado..select_from(table_city.join(table_country))define la condición/tabla de unión. Tenga en cuenta que no tuvimos que escribir la condición de unión completa, incluidas las claves. Esto se debe a que SQLAlchemy "sabe" cómo se unen estas dos tablas, ya que las claves principales y las reglas de claves externas se importan en segundo plano.
INSERTAR / ACTUALIZAR / ELIMINAR
Estos son los tres comandos DML restantes que cubriremos en este artículo. Si bien su estructura puede volverse muy compleja, estos comandos suelen ser mucho más simples. El código utilizado se presenta a continuación.
# INSERT
print("\n -- INSERT --")
stmt = table_country.insert().values(country_name='USA')
print(stmt)
connection_live.execute(stmt)
# check & print changes
stmt = select([table_country]).order_by(asc(table_country.columns.id))
print(connection_live.execute(stmt).fetchall())
# UPDATE
print("\n -- UPDATE --")
stmt = table_country.update().where(table_country.columns.country_name == 'USA').values(country_name = 'United States of America')
print(stmt)
connection_live.execute(stmt)
# check & print changes
stmt = select([table_country]).order_by(asc(table_country.columns.id))
print(connection_live.execute(stmt).fetchall())
# DELETE
print("\n -- DELETE --")
stmt = table_country.delete().where(table_country.columns.country_name == 'United States of America')
print(stmt)
connection_live.execute(stmt)
# check & print changes
stmt = select([table_country]).order_by(asc(table_country.columns.id))
print(connection_live.execute(stmt).fetchall())
Se usa el mismo patrón para las tres declaraciones:preparar la declaración, imprimirla y ejecutarla, e imprimir el resultado después de cada declaración para que podamos ver lo que realmente sucedió en la base de datos. Observe una vez más que partes de la instrucción se trataron como objetos (.valores(), .dónde()).

Usaremos este conocimiento en el próximo artículo para construir un script ETL completo usando SQLAlchemy.
Siguiente:SQLAlchemy en el proceso ETL
Hoy hemos analizado cómo configurar SQLAlchemy y cómo ejecutar comandos DML simples. En el próximo artículo, usaremos este conocimiento para escribir el proceso ETL completo usando SQLAlchemy.
Puede descargar el script completo, utilizado en este artículo aquí.