Con la introducción de Azure SQL Database y la incorporación de más funcionalidades en v12, los administradores de bases de datos están comenzando a ver que sus organizaciones están más interesadas en trasladar las bases de datos a esta plataforma.
Recientemente comencé a sumergirme más en Azure SQL Database para ver qué es radicalmente diferente de admitir la versión en caja en los centros de datos de todo el mundo y Azure SQL Database. En mi artículo anterior, "Tuning:un buen lugar para comenzar", cubrí mi enfoque para comenzar con el ajuste de SQL Server. Decidí revisar esto con Azure SQL Database para descubrir las principales diferencias.
En mi artículo original, comencé con configuraciones comunes a nivel de instancia que veo ignoradas o dejadas como predeterminadas, así como elementos de mantenimiento. Estos incluyen memoria, maxdop, umbral de costo para paralelismo, habilitación de optimización para cargas de trabajo ad hoc y configuración de tempdb. Con Azure SQL Database, usted no es responsable de la instancia y no puede modificar esa configuración. Azure SQL Database es una plataforma como servicio (PaaS), lo que significa que Microsoft administra la instancia por usted; usted es simplemente un inquilino con su base de datos o bases de datos.
Sin embargo, usted es responsable del mantenimiento, por lo que debe actualizar las estadísticas y manejar la fragmentación del índice como lo hace con el producto de caja. Para esas tareas, descubrí que la mayoría de los clientes administran esos procesos con una VM de Azure dedicada que ejecuta SQL Server y usa el Agente SQL Server con trabajos programados.
Siguiendo los pasos de mi artículo, las siguientes áreas en las que empiezo a investigar son las estadísticas de archivo y espera y las consultas de alto costo. Si se pregunta si este aspecto de su trabajo como administrador de base de datos de producción con bases de datos locales cambiará cuando trabaje con Azure SQL Database, la respuesta es no realmente. . Las estadísticas de archivo y espera todavía están ahí, pero tenemos que llegar a ellas de una manera ligeramente diferente. Si está acostumbrado a usar los scripts de Paul Randal para estadísticas de archivos y estadísticas de espera (o las consultas de estadísticas de archivos por un período de tiempo y estadísticas de espera por un período de tiempo), tendrá que hacer algunos cambios para que esos scripts para trabajar con Azure SQL Database.
Cuando probé por primera vez el script de estadísticas de archivos de Paul, falló debido a que Azure SQL Database no admitía sys.master_files :
Nombre de objeto no válido 'sys.master_files'.
Pude modificar el script para usar sys.databases en la unión para obtener el nombre de la base de datos y elimine la parte del script para obtener los nombres de los archivos individuales, ya que solo trataremos con un solo archivo de datos y de registro. Puedes ver los cambios que tuve que hacer en la siguiente imagen:
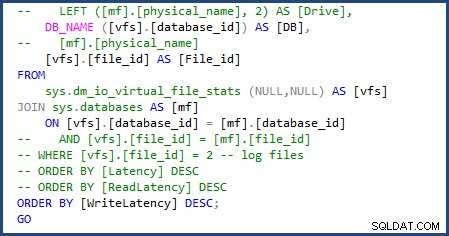
Cuando ejecuté el script file-stats-over-a-period-of-time después, hice el mismo cambio en sys.databases y eliminando las referencias a file_id en la combinación, falló debido a que Azure SQL Database v12 no admite tablas temporales ## globales.
Una vez que cambié todas las tablas temporales ## globales a locales, tuve otro problema con la secuencia de comandos que no podía descartar las tablas temporales existentes que se usaban, porque no se puede hacer referencia directamente a las tablas temporales ## locales por nombre de la misma manera que se puede hacer con las tablas temporales ## globales, pero esto fue fácil de superar cambiando dichas comprobaciones a OBJECT_ID('tempdb..#SQLskillsStats1') . Hice el mismo cambio para la segunda tabla temporal y actualicé el bloque de código al principio y al final del script.
Tuve que hacer un cambio más y quitar [mf].[type_desc] y LEFT ([mf].[physical_name], 2) AS [Drive] ya que dependen de sys.master_files . Luego, el script estaba completo y listo para usar con Azure SQL Database.
Uso el archivo-stats-over-a-period-of-time regularmente cuando soluciono problemas de rendimiento. Los datos acumulativos tienen su propósito, pero me interesan más los segmentos de tiempo específicos en los que se ejecutan las cargas de trabajo de los usuarios.
Con las estadísticas de archivos, nos preocupa nuestra latencia por archivo de base de datos y cómo podemos ajustar para ayudar a reducir la E/S general. El enfoque es el mismo que el de SQL Server, donde debe ajustar sus consultas correctamente y tener los índices correctos. Si la carga de trabajo es demasiado grande, debe pasar a un nivel de base de datos de DTU de rendimiento más rápido. Para mí, esto es genial:simplemente le arrojas hardware; pero no es realmente hardware en el sentido tradicional. Con Azure SQL Database, puede comenzar con un nivel menos costoso y escalar a medida que su negocio y las demandas de E/S crecen, esencialmente con solo activar un interruptor.
Tratar de encontrar el mejor método para obtener estadísticas de espera fue más fácil. El script estándar que muchos de nosotros usamos todavía funciona, sin embargo, obtiene estadísticas de espera para el contenedor en el que se ejecuta su base de datos. Esas esperas aún se aplican a su sistema, pero pueden incluir esperas incurridas por otras bases de datos en el mismo contenedor. Azure SQL Database contiene un nuevo DMV, sys.dm_db_wait_stats , que filtra a la base de datos actual. Si es como yo y usa principalmente el script de estadísticas de espera de Paul que omite todas las esperas benignas, simplemente cambie sys.dm_os_wait_stats a sys.dm_db_wait_stats . El mismo cambio también funciona para el script de espera durante un período de tiempo, pero también debe realizar el cambio de variables globales a locales.
Cuando se trata de encontrar consultas de alto costo, uno de mis scripts favoritos para ejecutar encuentra los planes de ejecución más utilizados. En mi experiencia, ajustar una consulta que se llama 100 000 veces al día suele ser una ganancia mayor que ajustar una consulta que tiene el IO más alto pero que solo se ejecuta una vez por semana. La siguiente consulta es la que utilizo para encontrar los planes más utilizados:
SELECT usecounts ,
cacheobjtype ,
objtype ,
[text]
FROM sys.dm_exec_cached_plans
CROSS APPLY sys.dm_exec_sql_text(plan_handle)
WHERE usecounts > 1
AND objtype IN ( N'Adhoc', N'Prepared' )
ORDER BY usecounts DESC;
Cuando uso esta consulta en demostraciones, siempre descargo la memoria caché de mi plan para restablecer los valores. Cuando intenté ejecutar DBCC FREEPROCCACHE en Azure SQL Database, recibí el siguiente error:
Resulta que DBCC FREEPROCCACHE no se admite en Azure SQL Database. Esto me preocupaba, ¿qué pasa si estoy en producción y tengo algunos planes malos y quiero borrar el caché de procedimientos como puedo con la versión de caja? Un poco de investigación de Google/Bing me llevó a encontrar el artículo de Microsoft, "Comprensión de la memoria caché de procedimientos en SQL Azure", que dice:
Al discutir esto con Kimberly Tripp después de no ver el comportamiento descrito, no se vacía el plan de la memoria caché, pero sí se invalida el plan (y luego el plan eventualmente se eliminará de la memoria caché). Si bien esto es útil en ciertas situaciones, esto no era lo que necesitaba. Para mi demostración, quería restablecer los contadores en sys.dm_exec_cached_plans. Generar un nuevo plan no me daría los resultados deseados. Me comuniqué con mi equipo y Glenn Berry me dijo que probara el siguiente script:
ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE;
Este comando funcionó; Pude borrar el caché de procedimientos para la base de datos específica. Configuraciones de ámbito de base de datos es una característica nueva agregada en SQL Server 2016 RC0; Glenn publicó un blog sobre esto aquí:Uso de ALTER DATABASE SCOPED CONFIGURATION en SQL Server 2016.
Estoy emocionado de mover varias de mis propias bases de datos a Azure SQL Database y de seguir aprendiendo sobre las nuevas características y opciones de escalabilidad. También tengo muchas ganas de trabajar con SentryOne DB Sentry, una incorporación reciente a la plataforma SentryOne. Estoy más interesado en experimentar con el panel Uso de DTU, que Mike Wood describió en su publicación reciente.



