Ejecutar un Galera Cluster en una nube híbrida debe constar de al menos dos sitios geográficos diferentes, conectando hosts en las instalaciones o en la nube privada con los de la nube pública. Ya sea que utilice una nube privada inquebrantable o plataformas de nube pública, la recuperación ante desastres (DR) es sin duda un tema clave. No se trata de copiar sus datos en un sitio de respaldo y poder restaurarlos, se trata de la continuidad del negocio y qué tan rápido puede recuperar los servicios cuando ocurre un desastre.
En esta publicación de blog, analizaremos diferentes formas de diseñar sus clústeres de Galera para la tolerancia a fallas en un entorno de nube híbrida.
Configuración activa-activa
Galera Cluster debe ejecutarse con un número impar de nodos en un clúster y, por lo general, comienza con 3 nodos. Esto se debe a que Galera Cluster utiliza el quórum para determinar automáticamente el componente principal, donde la mayoría de los nodos conectados deberían poder atender el clúster a la vez, en caso de que se produzca una partición del clúster.
Para una configuración de nube híbrida de configuración activa-activa, Galera requiere al menos 3 sitios diferentes, formando un clúster de Galera a través de WAN. Por lo general, necesitaría un tercer sitio para actuar como árbitro, votando por el quórum y preservando el "componente principal" si alguno de los sitios no está disponible. Esto se puede configurar como un mínimo de un clúster de 3 nodos en 3 sitios diferentes (1 nodo por sitio), similar al siguiente diagrama:
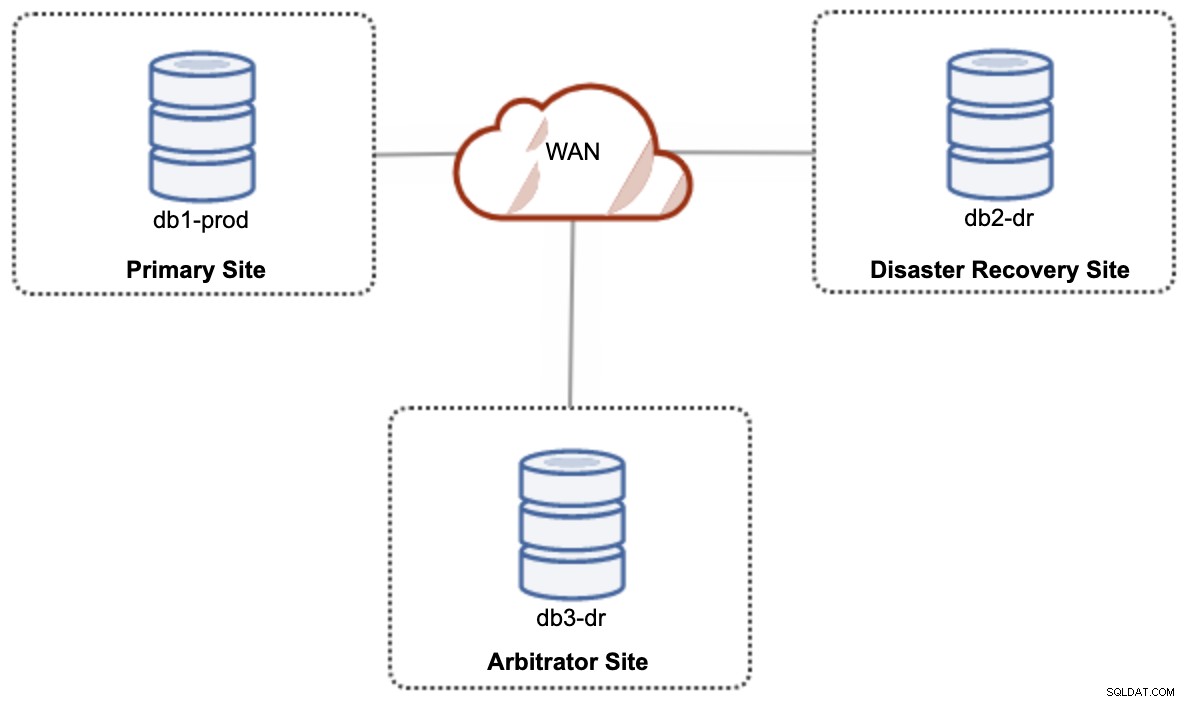
Sin embargo, por razones de rendimiento y confiabilidad, se recomienda tener un 7 -clúster de nodos, como se muestra en el siguiente diagrama:
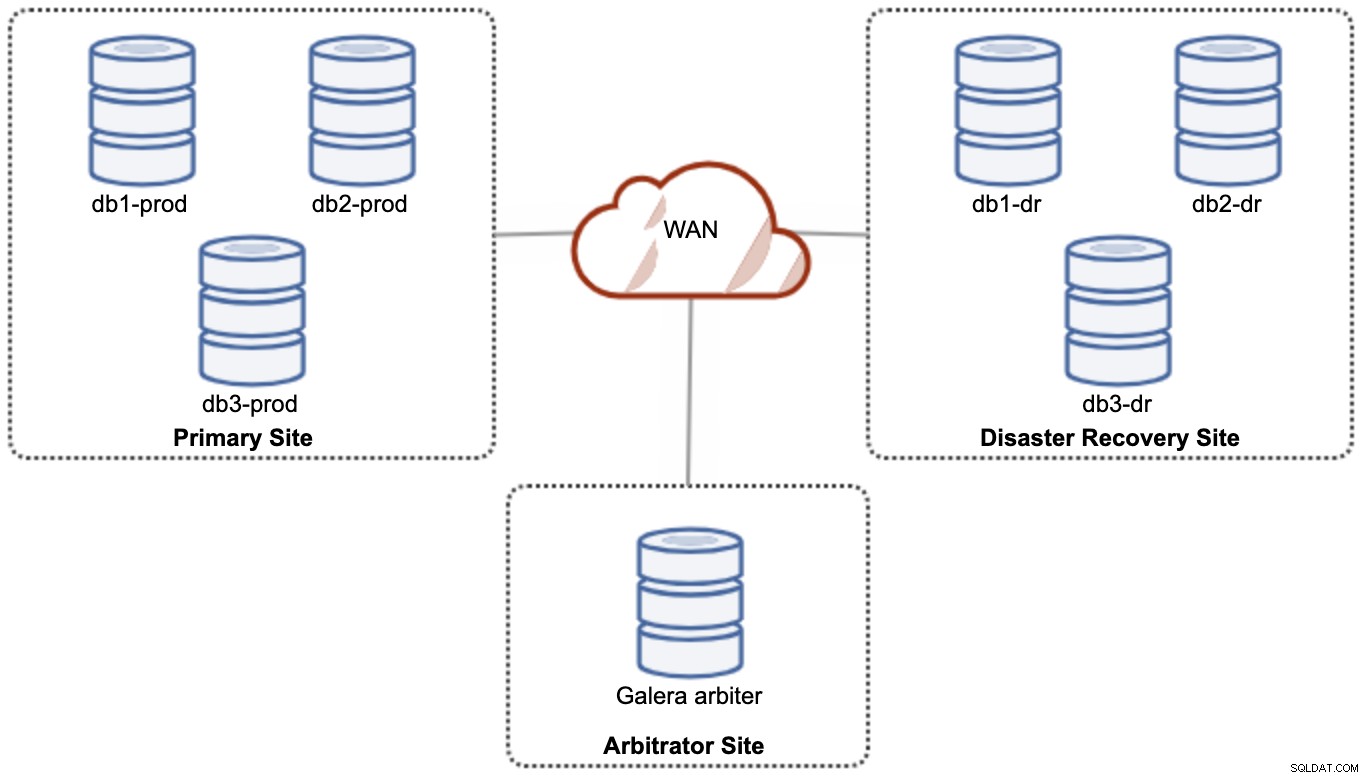
Esta se considera la mejor topología para admitir una configuración activa-activa, donde el sitio DR debería estar disponible casi de inmediato, sin ninguna intervención. Ambos sitios pueden recibir lecturas/escrituras en cualquier momento siempre que el clúster esté en el quórum.
Sin embargo, es muy costoso tener 3 sitios y 7 nodos de base de datos (el 7.º nodo se puede reemplazar con un garbd ya que es muy poco probable que se use para entregar datos a los clientes/aplicaciones). Por lo general, esta no es una implementación popular al comienzo del proyecto debido al enorme costo inicial y a la sensibilidad de la comunicación y replicación del grupo Galera a la latencia de la red.
Configuración activa-pasiva
En una configuración activo-pasivo, se requieren al menos 2 sitios y solo un sitio está activo a la vez, conocido como el sitio principal y los nodos en el sitio secundario solo replican los datos que provienen del principal servidor/clúster. Para Galera Cluster, podemos usar la replicación asíncrona de MySQL (replicación maestro-esclavo) o también podemos usar la replicación virtualmente síncrona de Galera con algunos ajustes para atenuar su replicación del conjunto de escritura para que actúe como replicación asíncrona.
El sitio secundario debe estar protegido contra escrituras accidentales mediante el uso de la marca de solo lectura, el firewall de la aplicación, el proxy inverso o cualquier otro medio, ya que el flujo de datos siempre proviene del sitio principal al secundario, a menos que una conmutación por error ha iniciado y promovido el sitio secundario como principal.
Uso de replicación asíncrona
Lo bueno de la replicación asincrónica es que la replicación no afecta al servidor/clúster de origen, pero se permite que se retrase con respecto al maestro. Esta configuración hará que el sitio primario y DR sean independientes entre sí, conectados de forma flexible con la replicación asíncrona. Esto se puede configurar como un mínimo de un clúster de 4 nodos en 2 sitios diferentes, similar al siguiente diagrama:
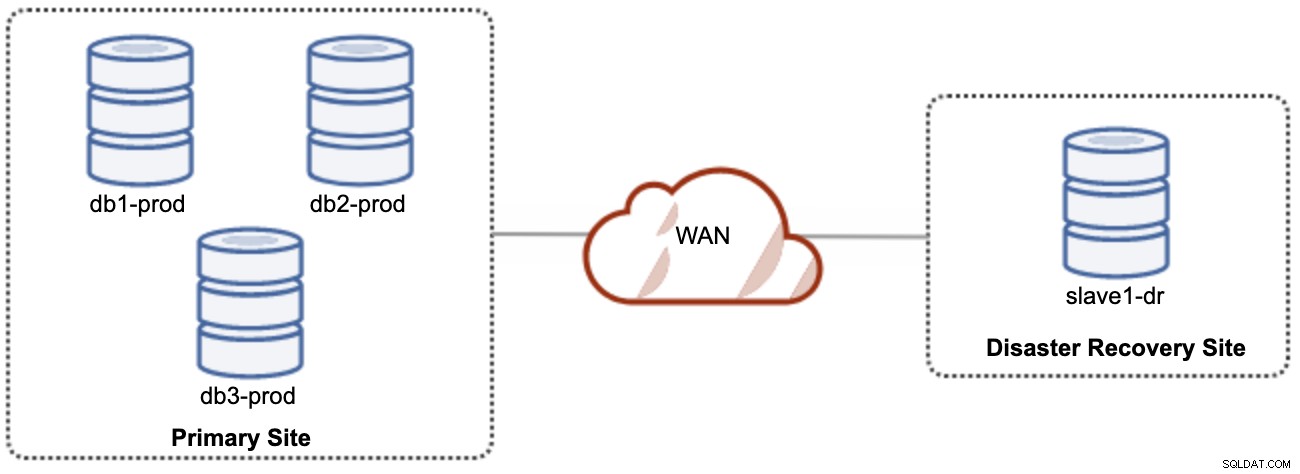
Uno de los nodos Galera en el sitio DR será un esclavo, que replica desde uno de los nodos Galera (maestro) en el sitio primario. Ambos sitios deben producir registros binarios con GTID y log_slave_updates habilitados; las actualizaciones que provienen del flujo de replicación asíncrona se aplicarán a los otros nodos del clúster. Sin embargo, para el uso de producción, recomendamos tener dos conjuntos de clústeres en ambos sitios, como se muestra en el siguiente diagrama:
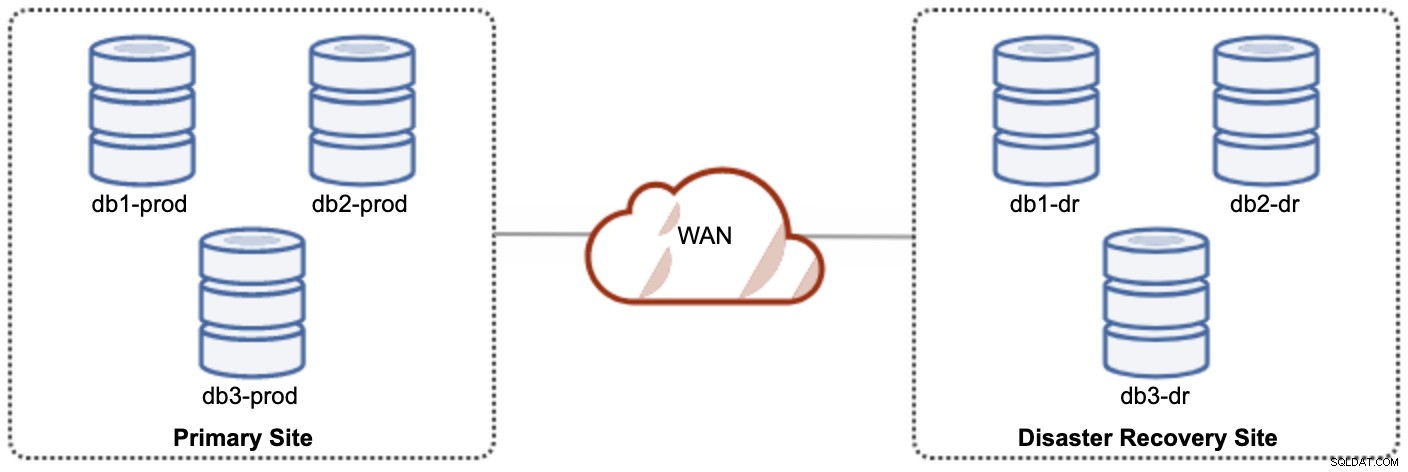
Al tener dos clústeres separados, estarán débilmente acoplados y no se impactarán entre sí, p. una falla de clúster en el sitio principal no afectará el sitio DR. En cuanto al rendimiento, la latencia de la WAN no afectará las actualizaciones en el clúster activo. Estos se envían de forma asíncrona al sitio de copia de seguridad. El clúster DR podría ejecutarse potencialmente en instancias más pequeñas en un entorno de nube pública, siempre que puedan mantenerse al día con el clúster principal. Las instancias se pueden actualizar si es necesario. Las aplicaciones deben enviar escrituras al sitio principal y el sitio secundario debe configurarse para ejecutarse en modo de solo lectura. El sitio de recuperación ante desastres se puede utilizar para otros fines, como la copia de seguridad de la base de datos, la copia de seguridad de los registros binarios y la creación de informes o el procesamiento de consultas analíticas (OLAP).
En el lado negativo, existe la posibilidad de pérdida de datos durante la conmutación por error/retroceso si el esclavo estaba retrasado. Por lo tanto, se recomienda habilitar la replicación semisincrónica para reducir el riesgo de pérdida de datos. Tenga en cuenta que el uso de la replicación semisíncrona aún no proporciona garantías sólidas contra la pérdida de datos, en comparación con la replicación virtualmente síncrona de Galera. Lea atentamente este manual de MySQL, por ejemplo, estas frases:
"Con la replicación semisíncrona, si la fuente falla y se realiza una conmutación por error a una réplica, la fuente fallida no debe reutilizarse como fuente de replicación y debe descartarse. Podría tener transacciones que fueron no reconocido por ninguna réplica, que por lo tanto no se confirmaron antes de la conmutación por error".
El proceso de conmutación por error es bastante sencillo. Para promocionar el sitio de recuperación ante desastres, simplemente desactive la marca de solo lectura y comience a dirigir la aplicación a los nodos de la base de datos en el sitio DR. Sin embargo, la estrategia alternativa es un poco complicada y requiere algo de experiencia en organizar los datos en ambos sitios, cambiar el rol maestro/esclavo de un clúster y redirigir el flujo de replicación esclavo en la dirección opuesta.
Uso de la replicación de Galera
Para la configuración activa-pasiva, podemos colocar la mayoría de los nodos ubicados en el sitio principal mientras que la minoría de los nodos ubicados en el sitio de recuperación ante desastres, como se muestra en la siguiente captura de pantalla para un 3- nodo Galera Clúster:
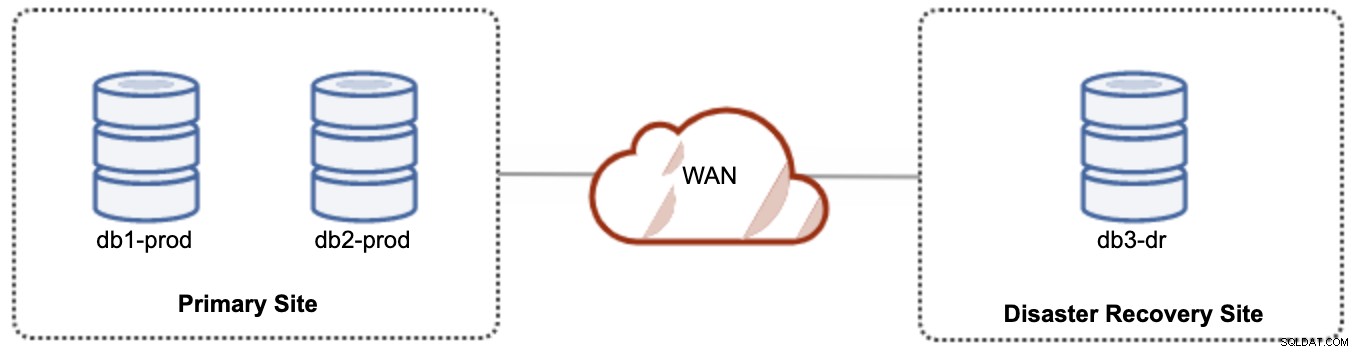
Si el sitio principal está inactivo, el clúster fallará porque no tiene quórum. El nodo de Galera en el sitio de recuperación de desastres (db3-dr) deberá reiniciarse manualmente como un componente principal de un solo nodo. Una vez que el sitio principal vuelve a funcionar, ambos nodos en el sitio principal (db1-prod y db2-prod) deben volver a unirse a galera3 para sincronizarse. Tener un gcache bastante grande debería ayudar a reducir el riesgo de SST a través de WAN. Esta arquitectura es fácil de configurar y administrar y muy rentable.
La conmutación por error es manual, ya que el administrador debe promocionar el nodo único como componente principal (bootstrap db3-dr o use set pc.bootstrap=1 en el parámetro wsrep_provider_options). Mientras tanto, habrá tiempo de inactividad . El rendimiento puede ser un problema, ya que el sitio de recuperación ante desastres se ejecutará con una cantidad menor de nodos (ya que el sitio de recuperación ante desastres siempre es la minoría) para ejecutar toda la carga. Es posible escalar horizontalmente con más nodos después de cambiar al sitio DR, pero tenga cuidado con la carga adicional.
Tenga en cuenta que Galera Cluster es sensible a la red debido a su naturaleza virtualmente síncrona. Cuanto más lejos estén los nodos de Galera en un clúster determinado, mayor será la latencia y su capacidad de escritura para distribuir y certificar los conjuntos de escritura. Además, si la conectividad no es estable, la partición del clúster puede ocurrir fácilmente, lo que podría desencadenar la sincronización del clúster en los nodos de unión. En algunos casos, esto puede introducir inestabilidad en el clúster. Esto requiere un poco de ajuste en los parámetros de Galera, como se muestra en esta publicación de blog, Implementación de un entorno de infraestructura híbrida para Percona XtraDB Cluster.
Reflexiones finales
Galera Cluster es una gran tecnología que se puede implementar de diferentes maneras:un clúster extendido en múltiples sitios, múltiples clústeres sincronizados a través de la replicación asíncrona, una combinación de replicación síncrona y asíncrona, etc. La solución real estará determinada por factores como la latencia de la WAN, la consistencia de los datos eventuales frente a los sólidos y el presupuesto.